CPO供应链双轨演进:英伟达私有总线封锁,与博通/MediaTek的标准化终局

CPO供应链双轨演进:英伟达私有总线封锁,与博通/MediaTek的标准化终局

AGI小咖
发布于 2025-12-30 20:27:27
发布于 2025-12-30 20:27:27
AGI小咖 本文深度复盘CPO 供应链双轨演进:英伟达通过深度绑定台积电COUPE工艺与收购 Groq(一群Google TPU工程师组建),构建起私有总线封锁;而博通与联发科则依托UEC联盟,以通用标准化接口及直驱技术构筑开放阵营。在制造工艺上台积电凭借 3D 堆叠技术将光引擎制造环节降维“收编”进晶圆厂,迫使日月光等传统封测厂转向高性价比的2.5D封装,同时Intel与SK强力押注玻璃基板,锚定承载102.4T芯片的物理底座。结合Meta在OCP 2025峰会上披露了“百万小时零故障”数据验证了CPO交换机具备电信级可靠性,而Marvell更借助CXL协议将GPU与HBM的互连延迟压缩至135ns,预判标准化终局将从底层重构智算集群IO边界。
1、CPO为何成为不可绕开的选择?
大模型的算力需求正以每年10倍的速度飙升,而物理接口带宽却只能按传统节奏每两年翻一番。这一快一慢之间拉开的巨大“剪刀差”,让互连带宽成了吉瓦级智算集群中最紧的瓶颈——再多的GPU,也卡在数据进不来、出不去的困局里。
随着单通道SerDes速率逼近224Gbps,电信号在PCB上的有效传输距离已被压缩到10–12厘米以内,再远信号就严重劣化。这意味着传统铜互连方案不仅布线复杂到难以实现,系统级功耗也高得难以承受。
据Hyperscaler 实测数据显示,基于DSP 的传统 1.6T 可插拔光模块端到端功耗已接近 25 pJ/bit。在当前架构下,一台满配1.6T可插拔光模块的102.4T交换机,仅光互连部分功耗就超过3500W,整机功耗几乎把风冷机柜的散热能力榨干。相比之下,CPO(共封装光学)通过2.5D/3D先进封装,把电互连路径从厘米级压缩到毫米级,成功把每比特功耗压到5pJ 以下。——这不是渐进优化,而是系统级能效的跃迁。
2、两条路线:封闭VS开发
2.1 英伟达:深度绑定台积电工艺与收购Groq
从Blackwell Ultra到下一代Rubin架构,英伟达致力于将光互连技术从“外置配件”重构为GPU集群内部的“私有高速总线”,要实现这一转型,仅靠芯片设计远远不够——必须深度掌控底层制造工艺。因此,英伟达深度绑定台积电的COUPE(Compact Universal Photonic Engine)平台,借助其3D堆叠能力,攻克了微环调制器在纳米尺度下的热稳定性难题。英伟达在2025年GTC大会上展示其搭载CPO技术的Spectrum-X交换机实现了单端口1.6Tbps的吞吐量,相比传统方案能效提升3.5倍,网络弹性提升10倍。换句话说,光通信最核心的环节牢牢攥在英伟达和台积电联手筑起的生态高墙之内。
更关键的一步发生在2025年12月25日,英伟达宣布以200亿美元现金拿下潜在竞争对手、芯片初创公司Groq(有意思的是Groq的创始人乔纳森·罗斯是前谷歌工程师,曾主导谷歌的TPU芯片项目)的核心班底和推理技术授权,将Groq的确定性调度IP融入英伟达的CPO光网络编排中,让数据流在物理层之上也实现“零不确定性”。至此,底层靠台积电COUPE搞定晶圆级光电封装,中间是自研的Switch ASIC和Optical-NVLink协议栈,顶层再用Groq的调度算法打通全局资源,英伟达成功的将物理连接到逻辑控制的全栈价值链纳管在自身构建的“AI工厂”护城河 里。当别人还在拼模块、调参数,英伟达已经把游戏规则都改写了——这大概就是它在智算基础设施领域越来越难以撼动的原因。
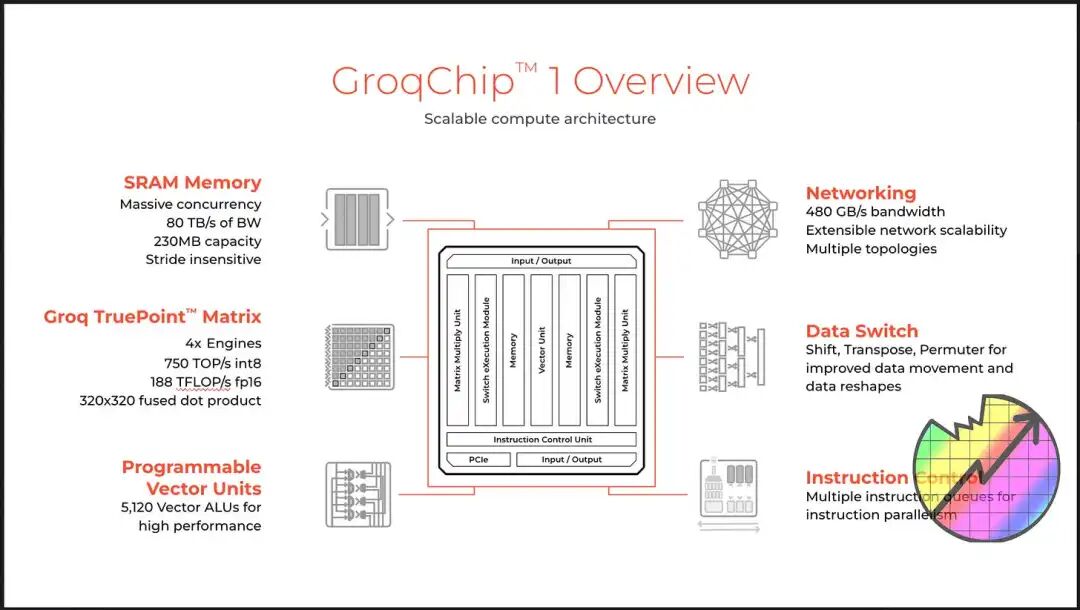
图 1: Groq LPU (TSP) 架构全景
2.2 博通:以太网CPO标准体系与通用化路径
博通选择了与英伟达垂直封闭截然不同的生态路径,其战略核心在于利用在DSP、交换芯片(Switch ASIC)及硅光技术上的全栈自研能力,悄悄把CPO的“通用接口”变成了自家说了算的游戏规则。如果说51.2T CPO交换机只是验证了工程可行性,那么博通在2025年下半年向Meta、字节跳动等头部客户交付的“Davisson”系统,则真正把CPO带进了单芯片102.4T的时代。如图2 博通 "Davisson" 平台不仅实现了单芯片 102.4 Tbps 的吞吐能力,更实现了功耗降低了70%以上。这一举措不仅大幅降低了超大规模云厂商(Hyperscaler)的部署门槛,更为行业提供了一条不依赖英伟达生态的、可标准化扩展的替代路径。

图 2: 博通102.4T CPO 交换机实物架构与关键指标
博通在Davisson平台上最核心的工程创新在于“外置激光源”(External Laser Source,简称ELS)的标准化。早期CPO方案最大的诟病在于:一旦激光器(故障率最高的部件)失效,整个昂贵的交换机就必须返厂。博通推出的ELSFP模块采用了前面板可插拔设计,将连续波(CW)激光器与高热的交换芯片物理隔离。这不仅使激光器工作在更舒适的温度区间(延长寿命),更使得运维人员可以像更换传统光模块一样,在数秒内完成激光源的现场更换,彻底消除了超大规模数据中心对于CPO“不可维护”的恐惧,赋予了CPO设备真正的电信级可靠性。
博通凭借着掌握从DSP数字信号处理、Switch逻辑设计到硅光流片的全链条技术,实际上正在将光互连转化为某种形式的“通用组件”。对于Meta和字节跳动等Hyperscaler而言,采用Davisson意味着可以站在以太网巨人的肩膀之上,直接继承超以太网联盟UEC的生态红利。通过在Tomahawk 6硬件层面原生集成UEC-Transport (UEC-T)协议,博通赋予了标准以太网媲美InfiniBand的无损传输与确定性低延迟能力。博通强大的生态号召力吸引InnoLight等传统头部模块厂商适配自己的参考设计框架,加速了供应链向半导体级的标准化制造转型。
2.3 MediaTekk:基于先进制程的定制化ASIC解决方案
在英伟达与博通的双头垄断之外,厚积薄发的MediaTek(联发科)试图利用深厚SerDes IP的极致运用与先进封装工艺优势构建CPO产业的第三极。外界常将其误读为单纯的消费电子芯片商,实则MediaTek已悄然蜕变为全球顶级的定制化ASIC巨头。不同于博通专注于通用标准交换芯片,MediaTek将战略重心聚焦于服务Google、Meta等Hyperscaler的自研芯片提供基于CPO的高带宽互连底座。
MediaTek明确宣布采用台积电N3P及N2P(3nm/2nm)工艺节点,开发集成了224G SerDes的定制化ASIC。在OCP 2025上MediaTek展示了基于台积电先进制程的成功实现了112Gbps/224Gbps SerDes的直驱架构,通过剥离传统光模块高功耗DSP和支持“6.4T光+6.4T铜”互连的混合I/O配置,完美融合Scale-up域的低成本与Scale-out域的长距离传输需求。
为了打破技术壁垒,MediaTek在2025年完成了对NVLink Fusion互连协议及Intel EMIB先进封装等异构标准的物理层兼容性验证,使其能够灵活嵌入各类封闭或半封闭的高性能计算HPC集群。此外,为了消除Hyperscaler对CPO维护性的顾虑,MediaTek更是推出了插槽式方案即光引擎采用了可拆卸连接器设计,这意味着即便在高度集成的CPO架构下,光器件依然具备独立更换与维护的能力,如图3,MediaTek计划于2026年实现大规模量产CPO ASIC成为了兼具先进制程性能与电信级运维弹性的“第三极”选择。
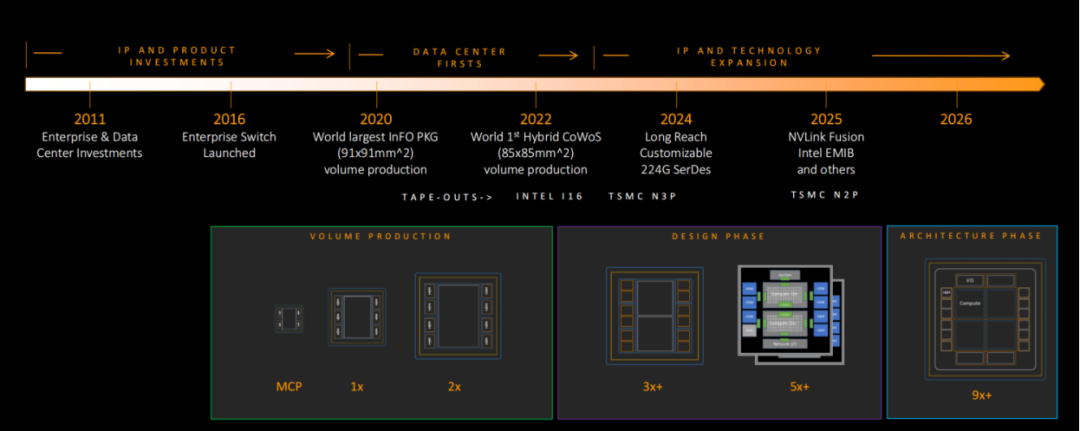
图3: MediaTek 2025-2026 CPO工艺演进路标
3、制造工艺变革:从后道封装向晶圆级集成转型
CPO技术演进也一定程度上推动着光模块产业从劳动密集型的后端封装测试向资本与技术密集型的前道晶圆代工转型与产业升级。
3.1 封测技术对比:台积电3D堆叠 VS 月光 FOCoS-Bridge
台积电(TSMC)已不再仅仅是芯片制造商,而是成为了CPO架构的底层定义者,其核心的COUPE (Compact Universal Photonic Engine)平台已然成为了高性能光互连的产业基准。
不同于传统的2.5D平面封装,COUPE的技术壁垒在于利用SoIC-X先进封装技术,实现了EIC(电驱动芯片)与PIC(光子芯片)的3D堆叠垂直键合。这样一来光互连的核心制造环节被台积电(TSMC)彻底“收编”进晶圆厂的洁净室,传统光模块厂商一下子就被“挤”到了边缘,只能做外置光源、光纤耦合这些外围活儿。
对NVIDIA、博通这类芯片设计大厂来说,目前只有台积电的COUPE平台能在102.4T这样的超高带宽下,稳定做到每比特功耗大幅降低至5pJ以下。这也解释了为什么台积电今年专门划出了一部分CoWoS产能给硅光子项目——标志着在晶圆代工巨头的战略版图中,光互连技术已上升至与AI逻辑芯片同等关键的战略地位。
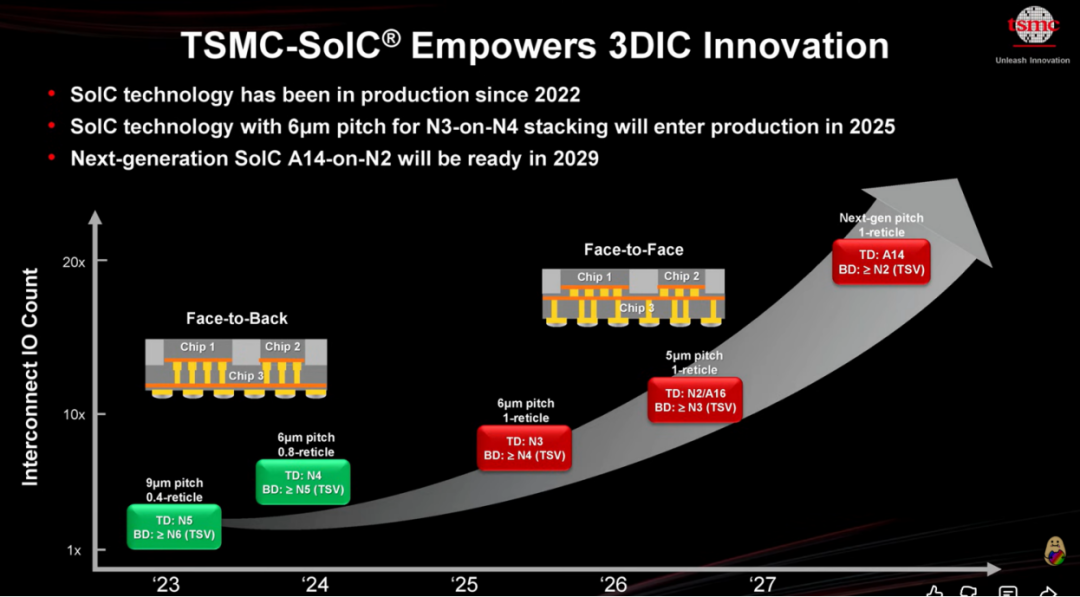
图4:TSMC SoIC 路线演进图
当然,也不是所有人都跟着台积电走高端路线,封测龙头日月光(ASE)就在另辟蹊径选择了更具量产性价比的技术路线。在今年ECTC大会上,他们主推的是FOCoS-Bridge技术,用扇出型封装里的嵌入式桥接,解决了ASIC和光引擎之间的高密度互连难题,既改善了信号质量,又控制了成本。靠着FOCoS前道工艺和VIPack后道封装的组合拳,ASE为像Marvell、联发科这类不用台积电CPO方案的客户,提供了一个更务实、更容易量产的选择。
3.2 材料科学革新:玻璃基板在超大尺寸封装中的应用
随着单芯片交换容量迈向102.4T,芯片封装后的物理尺寸已逼近传统材料的承载极限,而现有有机基板在大尺寸芯片封装过程中极易发生翘曲问题,已成为制约良率的核心瓶颈。
为此,英特尔代工(Intel Foundry)与SK Absolics正大力推动玻璃基板(Glass Core Substrate)的技术革新,利用TGV(Through-Glass Via,玻璃通孔)技术实现了比有机基板高出10倍的互连密度,使其成为承载集成数十个光引擎的超大规模CPO封装的唯一物理基础。在100T乃至200T的后摩尔时代,玻璃基板将演进为取代有机基板、承载智算网络核心算力的物理底座。
4、工程化落地验证:不同技术路线的实践评估
4.1 OCP 2025实测数据:Meta CPO百万小时压测零故障
长期以来业界对CPO最大的顾虑在于可靠性,然而Meta在OCP 2025发布的《Evaluation of CPO Performance and Pluggable Optics Health for Reliable AI Infrastructure》报告中却给出了不一样的实测数据结果——在基于Broadcom Bailly 51.2T CPO交换机的规模部署实测中,累计运行超过100万端口小时,实现了零链路翻转的完美记录。如图5所示,左下角的LTR实测数据显示,CPO系统(CPO标注曲线)的发射功率在长时间压力测试下保持了极高的稳定性,曲线平滑无抖动。与之相反,同期测试的传统可插拔光模块则出现了明显的信号衰减与波动。这一数据有力证明了在超大规模集群中,CPO的原子级集成设计反而消除了因物理插拔、连接器磨损及散热不均带来的不可靠因素,使其成为Scale-up核心域的首选。
图5: Meta实测数据:CPO光功率稳定性 VS 传统模块
4.2 Arista与Samtec理性声音:液冷与CPX铜缆的韧性
面对CPO的攻势,Arista Networks在2025年德意志银行技术大会上重申了其务实主义路线。Arista管理层明确指出,通过引入DLC(Direct Liquid Cooling,直接液冷)技术,传统可插拔模块的散热瓶颈可以被有效缓解,从而将可插拔形态的生命周期延长至1.6T乃至3.2T时代。Arista主张的LPO(线性驱动可插拔光学)配合液冷可以在成本与性能之间取得最佳平衡点。
与此同时,Samtec在OCP 2025上提出的CPX(Co-Packaged Copper)架构给出了另一个维度的答案:CPO不一定非要是“光”的天下。
对于机柜内的短距离互连,Samtec主张使用共封装铜缆解决方案,跳过主板上高损耗的PCB走线,直接从芯片封装内部引出高速线缆飞线至面板,实现了类似CPO的信号完整性,CPX方案凭借着性价比优势成为机内短距互连的强力竞争者。

图6:Samtec 2025 CPX架构:共封装铜缆实现Scale-up互连
4.3 其他国内外CPO产品
在工程落地层面国内也有不少CPO交换机产——Micas Networks(锐捷)推出的M2-W6940-128X1-FR4交换机在4RU的紧凑机箱内实现了51.2T的交换容量,并将整机功耗控制在1300W以下,刷新了同类产品的能效纪录。与此同时,H3C也在2025年联合Spirent完成了大规模800G端口(CPO及LPO混合组网环境)的高密度压力测试的稳定性测试。此外,NTT在OCP 2024/2025上分享了SONiC操作系统的更新,引入了标准化的光引擎状态机,标志着CPO正式进入了软硬解耦的成熟期。
5、展望
正如Marvell副总裁Mark Kuemerle所言:“Memory is almost the only thing that matters.”随着CXL(Compute Express Link)协议的普及,CPO的应用边界将不再局限于Switch互连,而是将被大规模用于GPU到HBM池、GPU到CXL内存池的超低延迟互连。
如图7 Marvell的最新技术路线显示:HBM与计算单元之间借助CPO互连总延迟可降低至135ns,这是传统电气(通常需375ns以上)互连无法企及的物理极限。这一技术突破将彻底打破制约大模型训练的“显存墙”,使万亿参数模型的推理成本呈指数级下降。
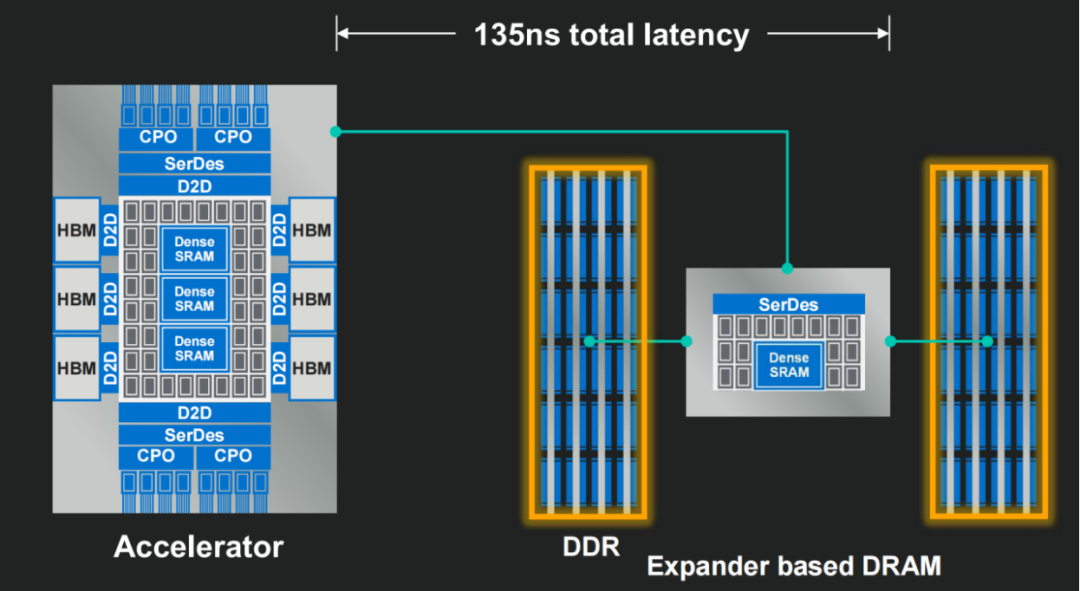
图7: Marvell 2025端到端135ns测试结果
未来的光互联产业与目前GPU产业的英伟达阵营与反英伟达联盟差别不大:
- 英伟达阵营的“深度绑定台积电COUPE工艺+自研Switch ASIC逻辑内核和Optical-NVLink协议栈+Groq确定性算力调度算法”的组合拳光互联解决方案将终端用户牢牢掌控在自身构建的“AI工厂”护城河内。
- 以Broadcom、MediaTek与UEC(超以太网联盟)为主导的开放联盟,致力于推动CPO Socket的标准化与玻璃基板的普及,试图为Google、Meta等Hyperscaler提供一个模块化、可插拔、多供应商兼容的开放生态。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号