实验室里的 大象 :生成式小分子设计中的可合成性

实验室里的 大象 :生成式小分子设计中的可合成性

DrugIntel
发布于 2025-12-30 20:22:53
发布于 2025-12-30 20:22:53

作者:Sven M. Papidocha等人(原载《Curr. Opin. Chem. Eng.》2025年)
摘要
小分子的定制化设计是化学与材料科学的核心目标。机器学习的近期进展为加速发现进程提供了强大工具。其中,生成模型通过为多种优化任务提出新颖候选分子,成为一种颇具前景的加速路径。尽管潜力巨大,但这些方法通常仅通过计算基准进行评估,且许多研究未能将提出的候选分子推进至湿实验室的实验验证阶段。这一差距的关键原因(即“房间里的大象”)在于生成分子的可合成性有限。为此,学界近期开发了多种策略,将可合成性纳入生成式设计工作流。本文综述了明确应对分子可合成性挑战的最新成果,重点介绍了显著进展,并讨论了当前方法的局限性,展望了未来研究的潜力方向。
引言
近年来,基于机器学习的生成模型在分子设计中的应用显著增长。变分自编码器、生成对抗网络等深度学习架构已被应用于药物发现和材料科学等领域的小分子定向设计。与传统虚拟筛选不同,生成方法能够从学习到的表征或专家定义规则所编码的庞大隐式化学空间中采样,从而避免对显式分子库的逐一筛选。因此,人们普遍期望它们能通过快速提出新颖、高质量的候选结构进行实验验证,加速闭环发现。然而,实验研究的一个基本前提是设计分子的可合成性。值得注意的是,Gao 等人证明,基于深度学习模型生成的分子中,有相当一部分实际上是不可合成的(通过逆合成工具 ASKCOS 分析确定)。
实验室里的“大象”在于:无论生成模型多么复杂,若其推荐的分子无法合成,则该模型实际上无用武之地。

本文总结了将可合成性整合到生成式分子设计中的最新进展,进而讨论当前局限性并强调未来工作的机遇。我们特别关注那些明确考虑可合成性的方法,并探讨其对实验可行性的更广泛影响。
设计具有特定性质的分子是化学研究的核心,计算方法长期被用于加速这一过程。鉴于复杂化学系统中可微的结构-性质关系很少以函数形式已知,常见策略是对预定义的候选分子库进行虚拟筛选。这些分子库通常由已报道的化合物构建,或使用有限的构建块和反应规则设计以确保合成可行性。随后,基于规则模型或基于机器学习的性质预测器进行性质优化。然而,对于超大化学空间,这种基于分子库的模式效率低下。相比之下,深度生成模型可以从学习到的化学分布中采样新颖分子,并可与评估器无缝集成于闭环优化框架中。这种设置天然支持遗传算法、贝叶斯优化或强化学习等高级搜索策略,以引导分子生成朝向目标性质。
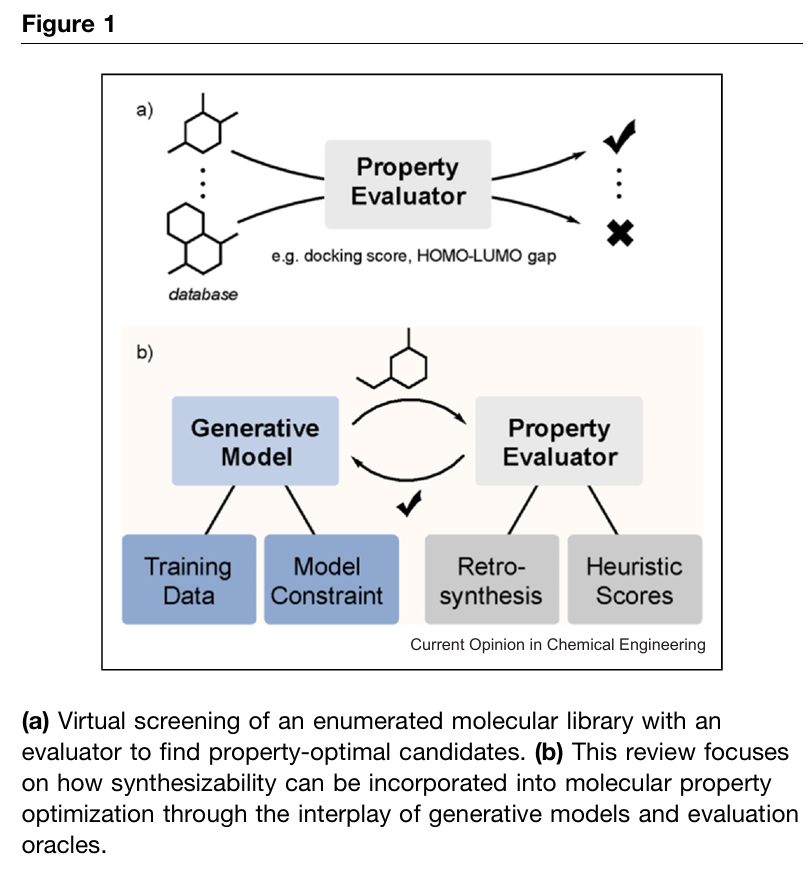
在此类工作流中,可合成性可在不同阶段被纳入。在生成端,一种策略是使用为合成可及性而策划的数据集训练模型。另一种方法是通过使用商业构建块和预定义反应模板来显式约束生成。在评估端,可合成性可作为额外的优化目标,融入多目标优化框架。评估可合成性最准确的方法仍是逆合成路线预测,但先进逆合成工具的高计算成本常限制其在迭代优化循环中的使用。因此,基于启发式的代理评分常被用作替代,以牺牲一定置信度换取更快的评估。后续章节将按可合成性如何融入生成式分子设计的方式对近期工作进行分类,并重点介绍文献中的代表性例子。
训练数据
基于深度学习的分子生成的首要考虑之一是训练数据的选择。训练数据的质量和组成强烈影响生成分子的可合成性。虽然通用分子生成研究常使用 QM9、SPICE 和 GEOM 等数据集,但药物发现应用通常依赖 ChEMBL 或 ZINC,这些数据集聚焦于生物相关化合物,并通过实验验证或商业可得性强调可合成性。通过仅在合成可及的化合物上训练生成模型,训练集选择是提高可合成性的关键策略。早期研究表明,在易于合成的分子库上训练的模型,其生成分子的可合成性显著高于在更复杂数据集上训练的模型。按需定制的分子库由于其商业可得性和可靠的合成可及性,被广泛用于生成式设计工作流。
另一种策略是将可合成性视为分子属性,并在训练期间以其为条件进行生成。与此相关,Vost 等人使用基于畸变的标签表示分子的物理合理性,这些标签用于训练条件扩散模型,展示了如何将结构质量信号融入生成建模。
受限分子生成
在计算小分子设计中,约束生成过程以考虑可合成性是一种成熟策略。常见方法是同时生成可合成分子及其对应的合成路径。这通常通过使用预定义反应模板和化学构建块进一步离散化化学空间来实现,从而将分子生成重新表述为合成树搜索问题。在此类树中,节点对应构建块,边代表反应规则。生成任务被重构为构建有效的反应模板和构建块序列,而非逐原子或逐字符组装分子,这简化了问题并提高了化学有效性。这种方法高度可定制,取决于所选模板和构建块库,某些模型甚至支持无需重新训练的库定制。
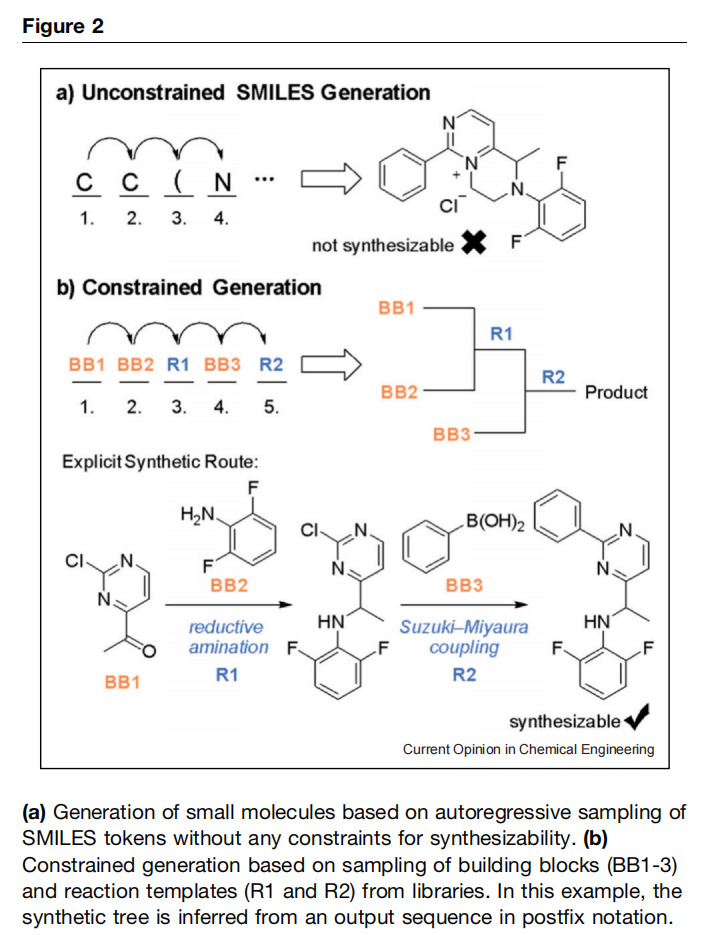
近年来,越来越多基于深度学习的模型采用此方法在分子生成过程中控制可合成性。许多模型嵌入采用遗传算法或强化学习的目标导向优化框架中。一些近期工作基于生成流网络框架,将分子设计视为学习一种随机策略,通过动作序列生成合成树。与传统强化学习相比,该框架既优化奖励又促进输出多样性。例如,RxnFlow 和 3DSynthFlow 通过从超过百万化合物的构建块库中采样,在针对不同酶靶点的口袋特异性优化任务中实现高性能。
使用构建块和反应模板本质上约束了生成模型可访问的化学空间,使许多潜在目标分子无法被生成。当这种情况发生时,模型要么无法生成合成树,要么通过将目标结构投影到受限化学空间中来近似它,产生最接近的可及类似物。这一特性已被近期模型积极利用。这些方法以目标分子为条件构建合成树,并通过在构建块级别进行最近邻匹配,将不可合成的输入投影到可合成的类似物上。这些模型在由兼容反应模板和构建块组合产生的人工合成树上进行训练。尽管这种方法支持非线性合成树构建并允许汇聚式合成规划,但以捕获真实实验报道的合成路线结构为代价。
迄今为止,只有少数生成模型通过湿实验室合成和生物学评估得到验证。例如,将基于流网络的 LambdaZero 与分子对接结合,发现了针对可溶性环氧化物水解酶 2 的新型抑制剂。在合成和测试的 25 个候选物中,有 8 个化合物在 10 μM 浓度下显示出活性。ClickGen 将其反应空间限制于 (3+2)-叠氮-炔环加成和酰胺形成,用于从头发现抗增殖剂,其生成的若干化合物对一组人类癌细胞系显示出效力。基于蒙特卡洛树搜索的模型 SyntheMol 用于生成针对鲍曼不动杆菌的新型抗生素,在合成的 58 个候选物中,有 6 个表现出良好的抗菌活性。其更新版 SyntheMol-RL 用强化学习替代蒙特卡洛树搜索,实现了多目标优化和改进的构建块空间导航。
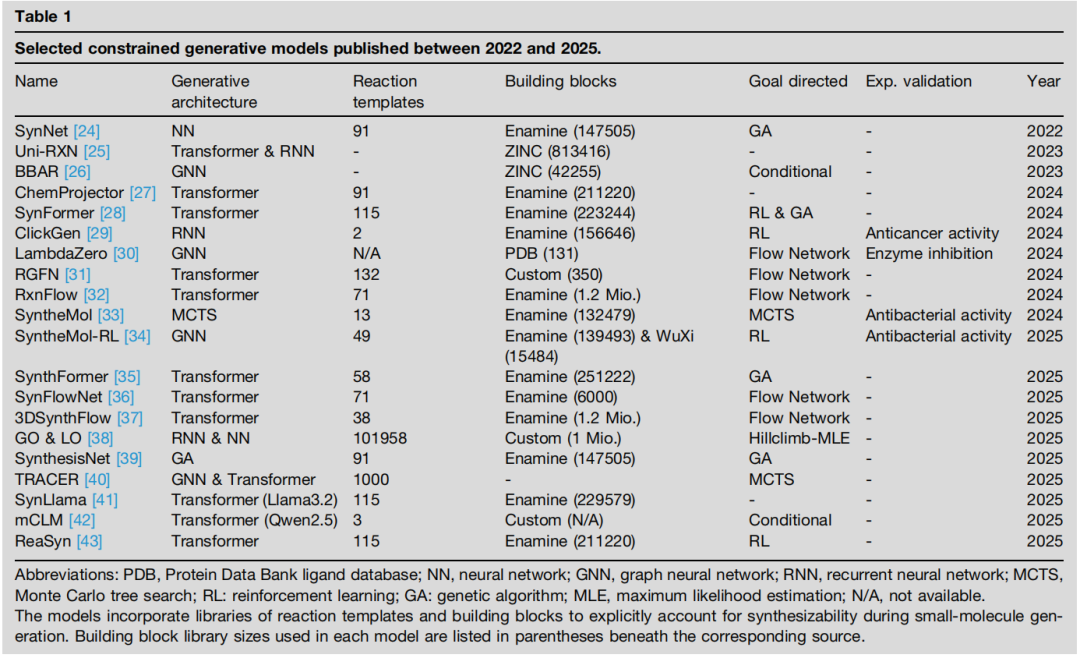
近期,使用包含合成约束的自然语言提示对大型语言模型进行微调也引起了兴趣。SynLlama 对 Meta 的 Llama3.2 模型进行微调,以基于定义的反应模板和构建块集输出合成路线的结构化 JSON 表示。与其他基于模板的模型不同,SynLlama 还能在字符标记级别操作,生成预定义库之外的分子和构建块,提供了更大灵活性。与 SynFormer 类似,该模型使用通过采样兼容反应模板-构建块对产生的人工合成树进行训练。值得注意的是,SynLlama 的微调方法只需少得多的训练样本就能在分子重建中达到有竞争力的性能。
使用逆合成和启发式方法引导生成
基于模板的方法通过预定义反应规则严格强制执行可合成性,而引导生成技术则在训练或推理期间通过额外奖励来引导生成模型。评估合成可行性的黄金标准仍是计算机辅助合成规划,但其计算成本通常阻碍其与生成模型在闭环优化中集成。SPARROW 框架将成本感知决策与计算机辅助合成规划结合,将财务约束作为可合成性考量的一部分。
为解决计算机辅助合成规划的计算成本问题,已开发了各种快速启发式代理指标。最广泛使用的是 SAscore,它基于片段在 PubChem 中的频率量化合成可及性。此方法启发了 BR-SAScore 的开发,该指标将可用的构建块信息和来自合成规划程序的反应知识纳入评分过程。作为纯可行性指标的补充,Routescore 考虑了劳动力成本、货币成本以及消耗的材料质量。这些因素在可合成性讨论中常被忽视,却在化学过程研究中扮演重要角色。
可合成性启发式方法已被用于在闭环优化中引导生成式分子设计。例如,MOLRL 首先训练变分自编码器,然后使用强化学习代理修改潜在向量以优化 QED 和 SAscore。其他方法在推理时引导生成,无需重新训练生成模型。例如,DrugDiff使用带有预测器引导的潜在扩散模型,以 SAscore 等属性偏置生成。类似地,TGF-Flow 应用免训练引导以优化结合亲和力、QED 和 SAscore 的组合。
由于启发式指标在新骨架上可能表现不佳,近期工作转向基于机器学习的可合成性预测器。这些模型通常可微,因此与基于梯度的引导方法兼容。例如,SCScore 使用 Reaxys 的反应数据估计合成步骤数,而 RAscore 预测通过计算机辅助合成规划进行逆合成分析成功的可能性。近期研究提出了几种扩散模型的推理时方法,但其在可合成性方面的应用仍 很大程度上未被探索,这预示了一个有前景的未来研究方向。
结论与展望
尽管小分子的合成感知生成设计的最新进展显著提升了各种优化任务的性能,但本节概述了反复出现的局限性并强调了未来发展的关键机遇。
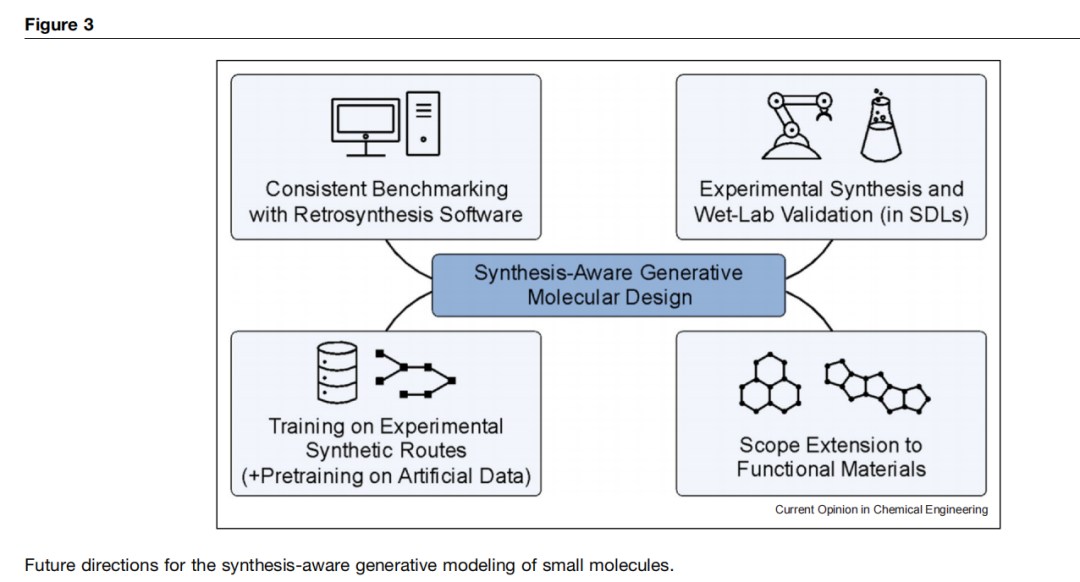
标准化的计算评估对于确保生成式分子设计的透明度和可比性十分重要。虽然 GuacaMol 等基准已被广泛用于药物发现任务,但它们未提供对可合成性的专门评估。因此,许多研究依赖自定义指标和参考模型,这阻碍了不同方法间的直接比较。一致使用开源逆合成工具如 AiZynthFinder 或 ASKCOS 可弥补这一差距。逆合成解决率和预测的平均合成步骤数等指标为量化可合成性提供了有意义的方法。
将可合成性纳入生成式分子设计的最终目标应是弥合计算方法与实验验证之间的差距。然而,湿实验室确认仍然相对罕见,且仅限于选定的案例研究。虽然实验验证显著增强了生成模型的影响力,但它应被视为一种机遇而非严格要求。在缺乏常规实验室测试的情况下,稳健的计算基准变得更为重要以确保透明度和可比性。
许多基于模板的生成模型在由简化反应模板构建的人工合成路线上训练。这些路线通常未能捕捉真实实验路线的复杂性,缺乏官能团兼容性、选择性和立体化学考量。人工路线还忽略了战略方面,如汇聚式合成或保护基的使用。未来模型应在如 Reaxys 等数据库中的多步骤实验路线上训练。在人造数据上预训练,然后用实验路线微调的联合策略,可能有助于解决获取大型机器可读数据集的挑战。另一个有前景的方向是实现灵活的构建块库而无需模型重新训练,如 RxnFlow 和 GO & LO 所示。
可合成性的挑战也必须在设计自动合成实验室和自主多智能体系统中得到解决。自动合成实验室有助于克服当前与生成模型输出的标准化湿实验室合成和评估相关的实验负担,同时提供必要的通量。在此背景下,可合成性必须与机器人基础设施的有限能力相匹配。在没有专家监督的情况下,智能体还必须考虑所提出分子及其合成路线的安全性。一些程序虽然对训练有素的化学家是常规操作,但可能涉及危险试剂。例如,四氧化锇介导的双羟基化是有效的,但由于其毒性和处理要求,对于由非专家操作的智能体驱动实验室仍然具有挑战性。
总之,将可合成性整合到分子生成设计中对于在化学发现和优化中创造现实世界价值非常重要。计算合成预测的进展,结合更具样本效率的生成模型,很可能推动该领域向前发展。机器学习当前的势头有潜力加速这一转变。
参考文献:Sven M Papidocha, Andreas Burger, Varinia Bernales, Alán Aspuru-Guzik,The elephant in the lab: synthesizability in generative small-molecule design, Current Opinion in Chemical Engineering.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号