NVMe协议浅析:演进历程、性能与扩展

NVMe协议浅析:演进历程、性能与扩展

霞姐聊IT
发布于 2025-12-30 19:57:44
发布于 2025-12-30 19:57:44
NVMe协议结构性地颠覆了传统存储协议栈,既是固态存储的绝对主流标准,更是AI时代实现算力突破的关键基础。本文将简要且系统地梳理NVMe的发展脉络、核心技术机制,以及NVMe over Fabric的相关实现。
一、NVMe的历史
NVMe的前身是NVMHCI。NVMHCI工作组成立于2007年,由Intel主持,Dell和Microsoft核心参与。
为什么2007年Intel要做这么一件事情?下面一起看一下当时的历史背景吧!
1.Intel的破局之道
21世纪后,首先,消费电子设备需要GB级别的存储来存放音乐、照片和应用数据,而NAND存储密度高、单位成本低、写入擦除速度快,能匹配这庞大的市场需求。另外基于闪存将替代机械硬盘的技术预判,可以预见NAND将会被大规模应用于数据中心。基于市场和技术的考虑,Intel决定将战略方向从NOR转向NAND。
但05年Intel决定进入NAND市场时,三星、东芝等厂家已经占了70%左右的市场份额了,那么Intel作为后来者该如何破局呢?当时各 NAND 厂商的芯片存在引脚定义、通信协议不统一,导致上游主控设计商需为不同厂商芯片单独开发方案,下游主板、SSD等设备厂商研发成本高、周期长。
这让Intel 看到了以标准破局的机会:通过主导统一接口,快速切入NAND生态。
2.ONFI标准
2006年,Intel拉拢了美光、海力士、索尼等同样受制于三星和东芝这两大巨头的非头部厂商,牵头成立了ONFI(开放NAND闪存接口)工作组。
ONFI通过制定开放的、统一的闪存芯片与主控间接口标准,简化设计、降低成本,构建了一个能与三星/东芝阵营抗衡的生态系统。
ONFI自2006年12月发布首个协议以来,至今已发布数十个更新版本,最新版本是22年的5.1。
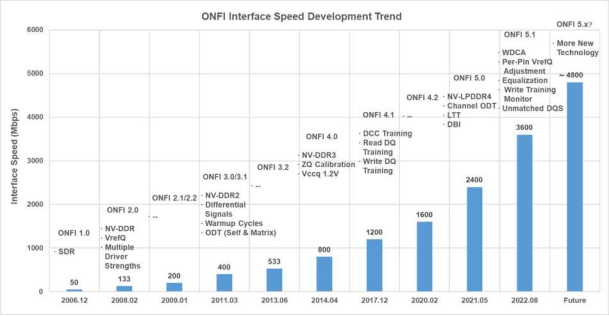
3.NVMe标准
ONFI标准化了闪存控制器与NAND之间的接口,那么下一步自然是标准化闪存控制器与OS驱动之间的寄存器级接口了。
因此NVMHCI工作组顺理成章地就成立了。它的目标是为OS驱动程序使用非易失性内存子系统提供标准的软件编程接口。2008 年 4 月,工作组完成了NVMHCI 1.0 规范,并在Intel官网公开。规范中首次明确了寄存器编程接口、低延迟数据传输等核心定义,但它仅聚焦于主机控制器与存储介质的底层交互,功能较单一,未覆盖企业级场景。
2009年,NVMHCI工作组吸纳三星、戴尔、EMC 等更多厂商,启动了规范升级工作。
升级后的规范不再沿用 NVMHCI 名称,而是以NVMe 1.0名义在2011年3月公开。
这一版本不仅继承了NVMHCI的PCIe 原生设计、低延迟特性,还新增了多核架构支持、64K命令队列、企业级数据保护等功能,标志着技术体系从单一控制器接口升级为全场景适配的存储协议标准。
同时NVMe这个新名称摆脱了Intel专属标准的标签,强化了开放、中立的生态属性。
现今,NVMe规范已经演变成了一个包含基础规范、命令集规范、传输规范、启动规范、管理接口规范的规范集,它的最新版本发布于25年8月份。
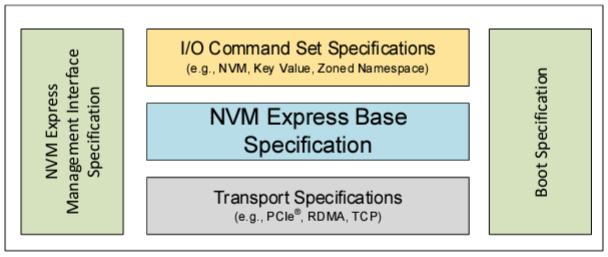
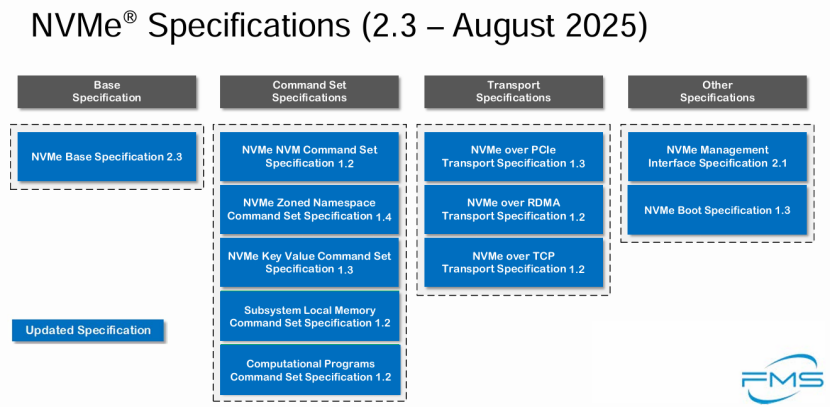
4.三点有趣的小细节
(1)三星和东芝对ONFI和NVMe的一拒一迎”
ONFI意图打破这两大巨头对NAND市场的垄断,所以三星和东芝结成Toggle-Mode联盟对抗ONFI,以此守护自己的技术壁垒,避免核心利润被稀释。
而NVMe标准可解决PCIe SSD协议碎片化问题,是全行业的共性需求,能推动全行业的增长,这种不削弱自身优势还能扩大市场的标准,三星和东芝乐于参加。
(2)Amber Huffman两大组织一肩挑
Amber Huffman作为存储行业的权威专家与核心领导者,一肩挑起NVMe和ONFI两大关键标准的发展重任,她不仅牵头创立并长期担任两大工作组的主席,更是两项标准核心规范的主导编写者与编辑,同时推动两大标准持续迭代并拓展至数据中心、汽车、云计算等多场景。
(3)为什么NVMe仍然活跃
NVMe非常活跃,根据其Roadmap,15岁的它在2026年仍然打算继续在协议中添加新的特性,这很罕见,背后的动因是:
第一、新兴场景的性能刚需
消费电子行业中,NVMe 协议的队列调度机制无法匹配游戏场景的需求,可能导致加载卡顿。
汽车行业中,NVMe 的电源管理仅支持基础休眠模式,且缺乏车规级错误冗余机制。
数据中心中,NVMe 协议缺乏分层存储调度能力,无法将热数据自动分配至高性能 SSD、冷数据迁移至低成本 QLC 存储,导致资源浪费。
第二、存储介质、计算架构的持续演进。
PLC(5bit/cell)、PCM、STT-MRAM等新技术需要协议层加以适配;
现有NVMe-oF协议在以太网环境下的延迟仍比本地连接高10-20微秒,需将网络延迟降低以满足 AI 训练、高频交易等低延迟场景。
第三、NVMe组织的高效性。
生态中任何一方的新痛点都会快速被提出,而NVMe组织敏捷性高,能保证“需求-规范-硅片”同速迭代。
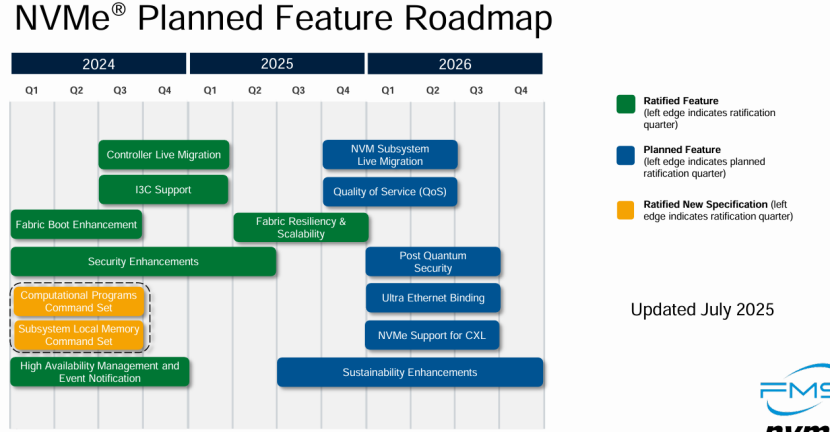
二、NVMe如何释放性能
首先,我们来看下NVMe命令处理流程:
①主机将命令(1条或者多条)写入提交队列。②主机更新队列对应的门铃寄存器。
③控制器从提交队列取走命令。④控制器处理命令。⑤控制器将完成状态写入完成队列。⑥控制器产生中断通知主机。
⑦主机处理完成队列中的条目。⑧主机更新完成队列门铃寄存器。
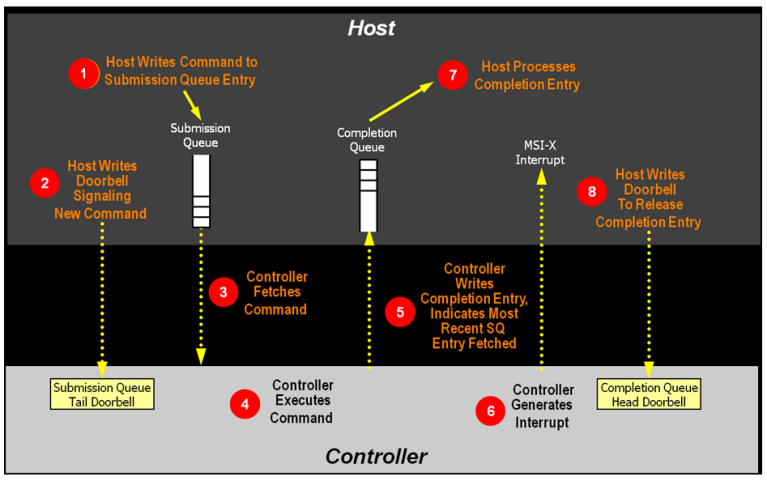
在这个过程中,命令读取、结果写入均通过DMA直接在主机内存与控制器间传输,无需 CPU 干预;命令下发只用1次 SQ Tail Doorbell寄存器写入;命令完成无需读取寄存器,这样的处理方式大大降低了处理开销,提升了性能。
然后,我们来看下NVMe的超大规模并行队列的的设计:
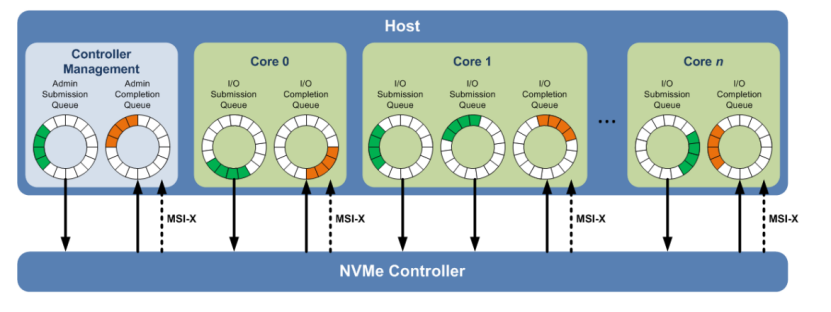
NVMe最多可支持64K个独立队列,每个队列可容纳64K条命令,可直接为每个CPU Core分配专属队列。因此NVMe可通过“无锁并行”,让多Core的 I/O 请求直接下发至不同队列。
提交队列(SQ)与完成队列(CQ)可解耦命令的下发与反馈流程。主机将命令写入SQ 后,无需等待执行结果即可继续下发新命令;控制器执行完成后,将结果独立写入对应的CQ。这种解耦设计,配合控制器的乱序执行能力,可大大提升闪存的多通道利用率。
NVMe支持 2048个MSI-X 中断向量。可将不同 CQ 的中断动态绑定至对应CPU Core提升中断处理效率。
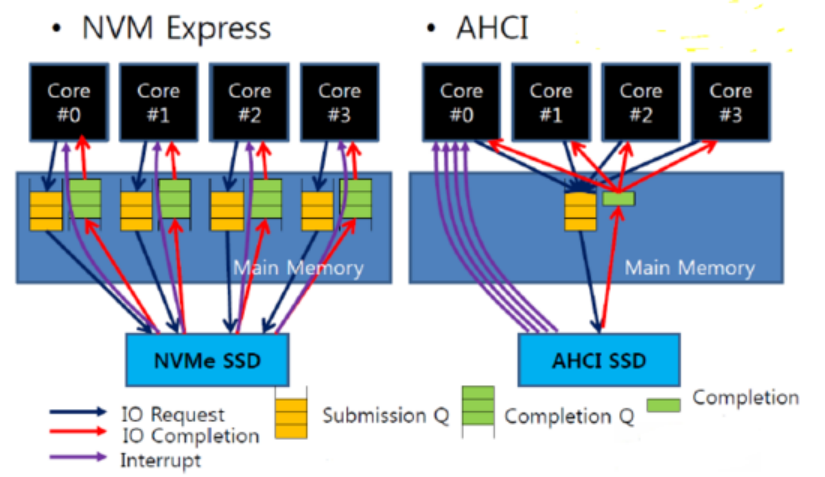
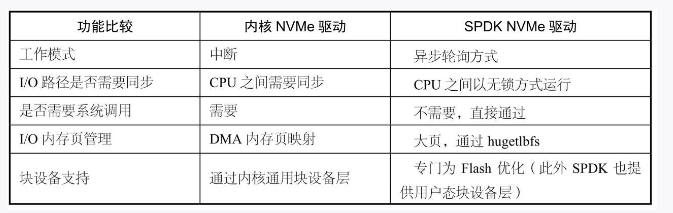
另外,在协议的实现上,软件工程师们还想到了将内核态驱动在用户空间加以实现,进一步减小了软件的开销。下图是Intel写的书中,关于两者的对比:
三、NVMe over Fabric从本地到全域
NVMe协议解决了本地存储的瓶颈之后,出现了幸福的烦恼。单台服务器内NVMe SSD性能太强,而无法被本地CPU完全消耗,这样就造成了资源的浪费。
一个自然的想法,就是将NVMe SSD拉远,将其存储能力释放给远程机器使用。
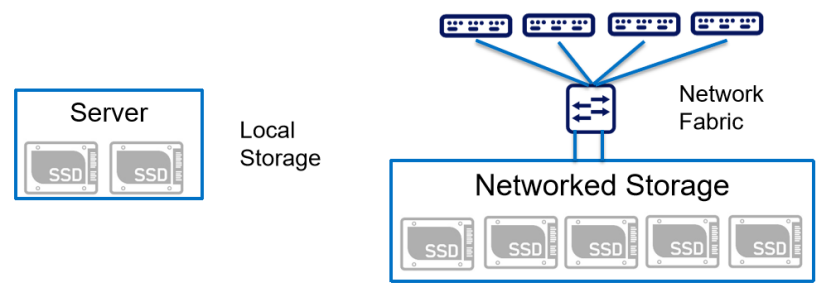
那么,怎么拉远呢?
原生的NVMe协议是为PCIe总线设计的本地存储协议,其核心机制与PCIe深度耦合,无法直接用于网络传输;若直接复用iSCSI、FC-SCSI 等传统网络存储协议承载NVMe流量,会引入协议转换开销并丢失 NVMe 核心优势。
所以,NVMe组织在2016年制定了NVMe Over Fabric规范,定义了一个通用的架构,在保留 NVMe 高性能语义的前提下,支持在FC、RDMA、TCP/IP等不同的传输网络上访问NVMe块存储设备,将本地存储协议扩展为网络存储协议:
1.连接与会话管理:新增Discover、Connect、Disconnect 等命令,支持多主机与存储目标(Target)的动态连接建立与断开,适配网络拓扑变化。
2.命名与发现机制:引入NQN作为存储目标的全局唯一标识,配合 Discovery Service 实现跨网络的存储资源自动发现,解决多节点寻址问题。
3.传输层适配:定义统一的Capsule 封装格式,支持 RDMA(RoCE/InfiniBand)、FC、TCP 等多种 Fabrics 承载,同时屏蔽不同传输层的差异,保证 NVMe 命令的一致性。
4.安全与可靠性:新增Authentication Send/Receive 等命令,支持 TLS 加密、访问控制等安全机制,弥补网络传输中的数据泄露与篡改风险。
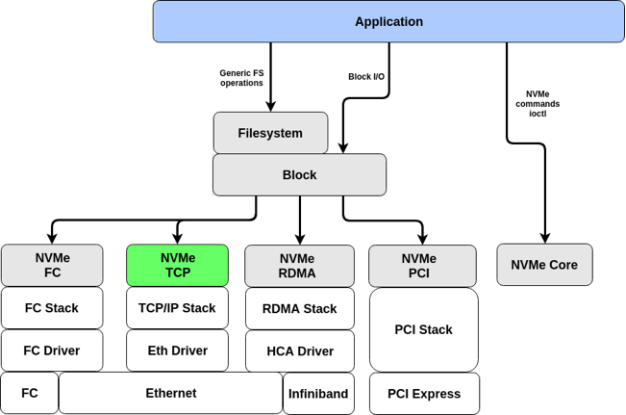
不过现在已经没有独立的NVMe over Fabric规范了,该规范已经被收纳进Base规范了。

现今,NVMe over Fabric技术已经成为现代高性能数据中心,特别是AI/GPU计算集群和公有云存储服务的标准配置和核心基础设施。例如:NVIDIA DGX SuperPOD 参考架构中,其存储节点通过它向DGX计算节点提供数据;Meta在其数据中心内部,使用它支撑其社交图谱数据库、消息服务;公有云通过它将高性能存储资源池化,并以云服务的形式售卖;传统和新兴的企业存储厂商,已将它作为其全闪存阵列的标配前端接口。
NVMe 自荒芜中拓荒,建立起统一高效的存储标准;十五年深耕演进,衍生出十多项子规范,囊括全主流传输协议、多套命令集,完成存储领域多维度标准化。这不仅得益于闪存技术的迭代升级,更源于行业场景持续演进的强力推动。在 AI 与高性能计算的浪潮下,NVMe 的创新之路永无止境,它将继续打破存储性能边界,成为连接数据与算力的关键纽带,引领下一代存储生态的变革浪潮。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号