字符函数和字符串函数(下)- 暴力匹配算法

字符函数和字符串函数(下)- 暴力匹配算法

云泽808
发布于 2025-12-30 17:24:01
发布于 2025-12-30 17:24:01
一、strcmp
在平时登录一些信息账号的时候需要输入账号密码,输入后会根据库里存的账号密码进行比较,相等了才能进入,strcmp函数的作用就和这个比较类似。
int strcmp( const char* str1,const char* str2 );功能:用来比较str1和str2指向的字符串,从两个字符串的第一个字符开始比较,如果两个字符串的ASCII码值相等,就比较下一个字符。直到遇到不相等的两个字符,或者字符串结束(任何一方的\0比较完之后就结束)。
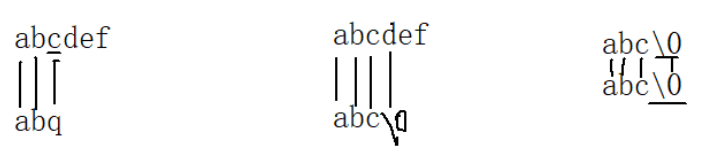
在这里插入图片描述
第一个c的ASCII码值<q的ASCII码值,所以c所在的字符串小于q所在的字符串,后面的比较类似
参数: str1:指针,指向要比较的第一个字符串 str2:指针,指向要比较的第二个字符串
返回值:
- 第一个字符串大于第二个字符串,则返回大于0的数字
- 第一个字符串等于第二个字符串,则返回0
- 第一个字符串小于第二个字符串,则返回小于0的数字
1.1 代码演示
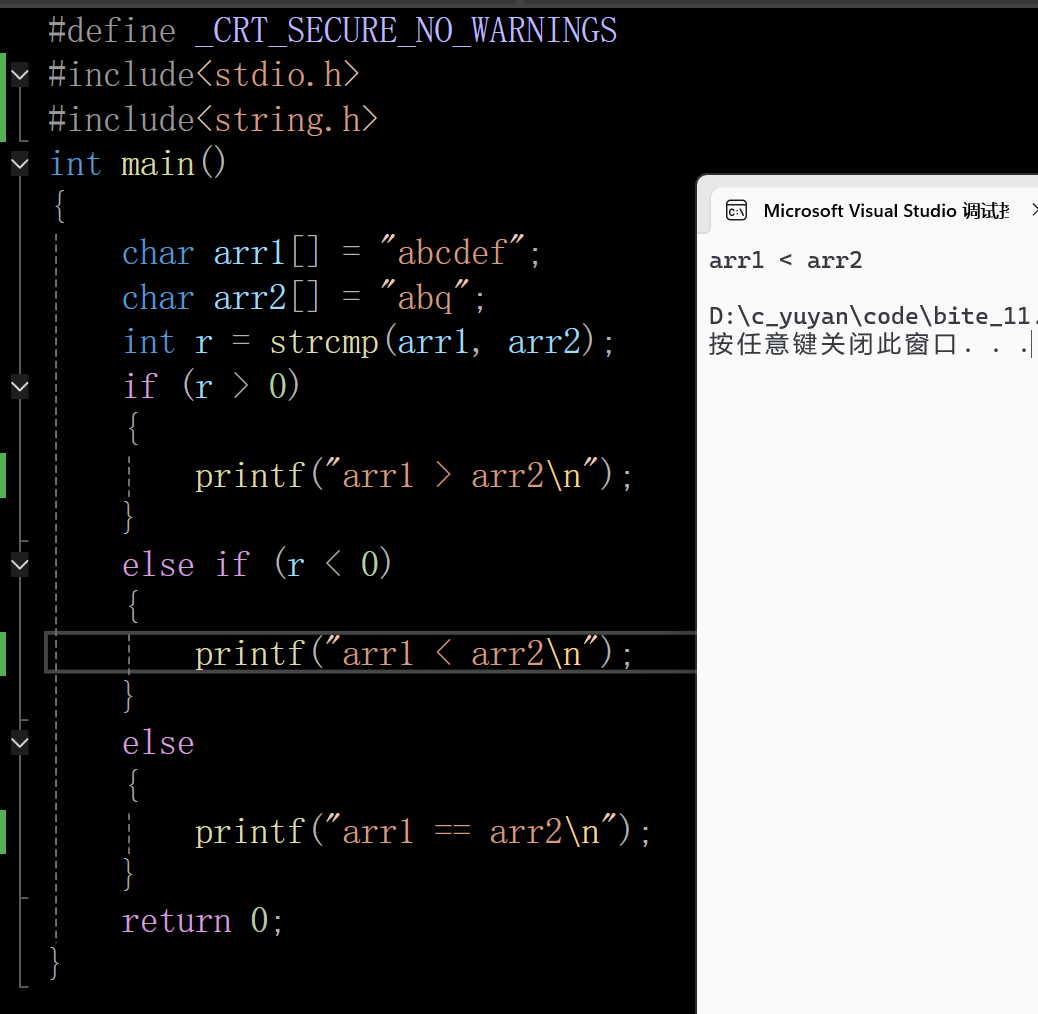
在这里插入图片描述
这里不把字符串放到数组里也可以
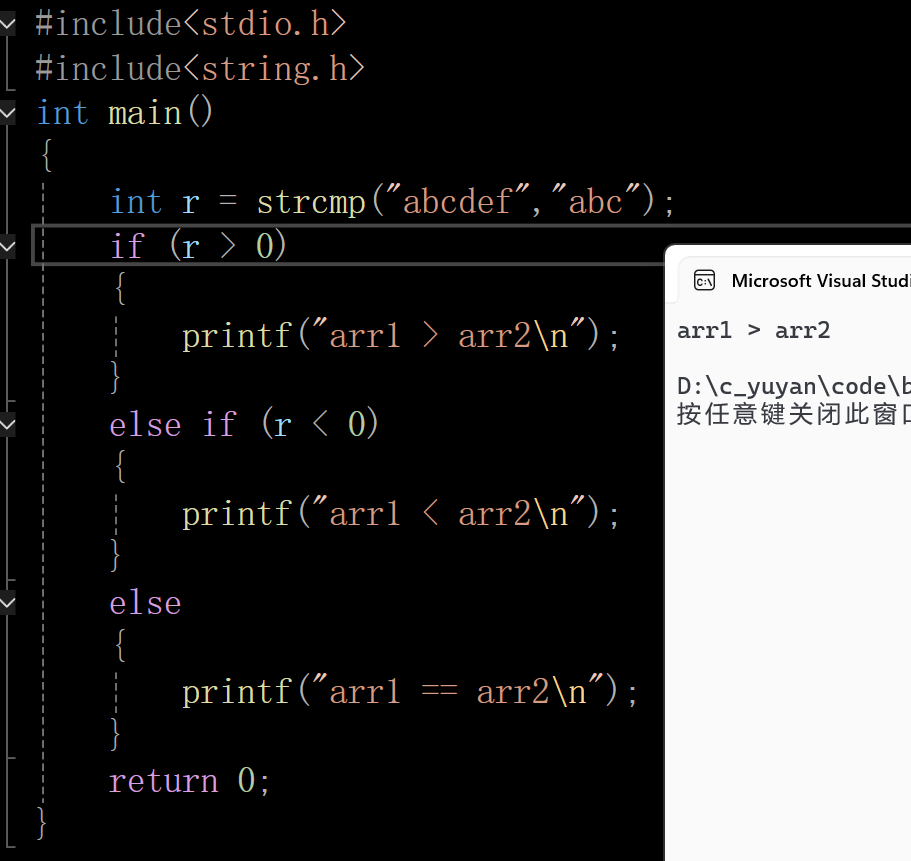
在这里插入图片描述
1.2 strcmp的模拟实现
#include<stdio.h>
#include<string.h>
#include<assert.h>
int my_strcmp(const char* arr1, const char* arr2)
{
assert(arr1 && arr2);
while (*arr1 == *arr2)
{
if (*arr1 == '\0')
{
return 0;
}
arr1++;
arr2++;
}
if (*arr1 > *arr2)
{
return 1;
}
else
{
return -1;
}
}
int main()
{
char arr1[] = "abcdef";
char arr2[] = "abq";
int r = my_strcmp(arr1, arr2);
if (r > 0)
{
printf("arr1 > arr2\n");
}
else if (r < 0)
{
printf("arr1 < arr2\n");
}
else
{
printf("arr1 == arr2\n");
}
return 0;
}这串代码中,函数内部的return 0会让my_strcmp函数立即终止执行,并且把控制权交还给调用它的main函数,而不是直接结束整个程序。
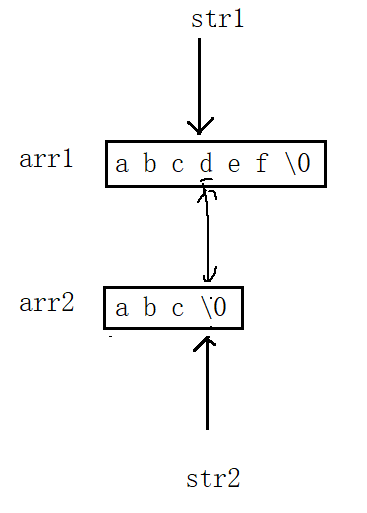
在这里插入图片描述
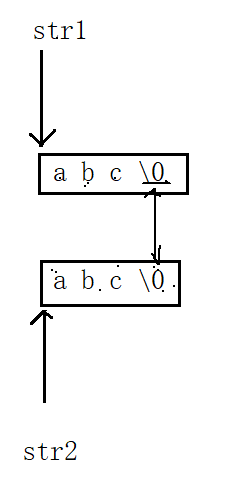
在这里插入图片描述
strcpy
strcat
strcmpC语言中这几个字符串叫长度不受限制的字符串函数,无论是拷贝,追加,比较都是一次到\0,拷贝,追加,比较都在这一篇文章里
strncpy
strncat
strncmp这几个是长度受限制的字符串函数,同上面函数的区别就是多了一个n。
二、strncpy
char* strncpy( char* destination,const char* source,size_t num );功能:字符串拷贝,将source指向的字符串拷贝到destination指向的空间中,最多拷贝num个字符。
参数: destination:指针,指向目的地空间 source:指针,指向源头数据 num:从source指向的字符串中最多拷贝的字符个数
返回值: strncpy 函数返回的目标空间的起始地址
2.2 代码演示
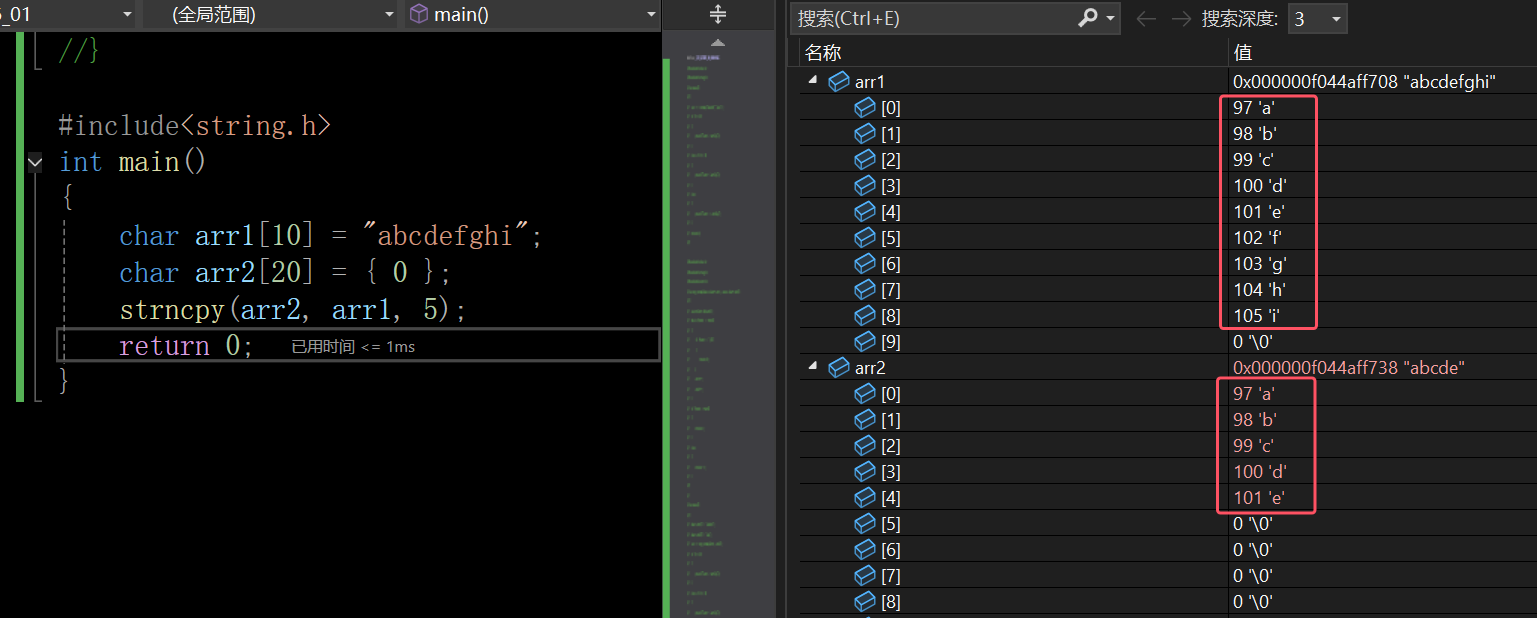
在这里插入图片描述
当遇到\0的时候,源头数据就已经拷贝结束了,能拷贝的已经拷贝完了,如果这里还不够5个,会补够5个,即补两个\0,补的\0并不来自源头数据,如下图:
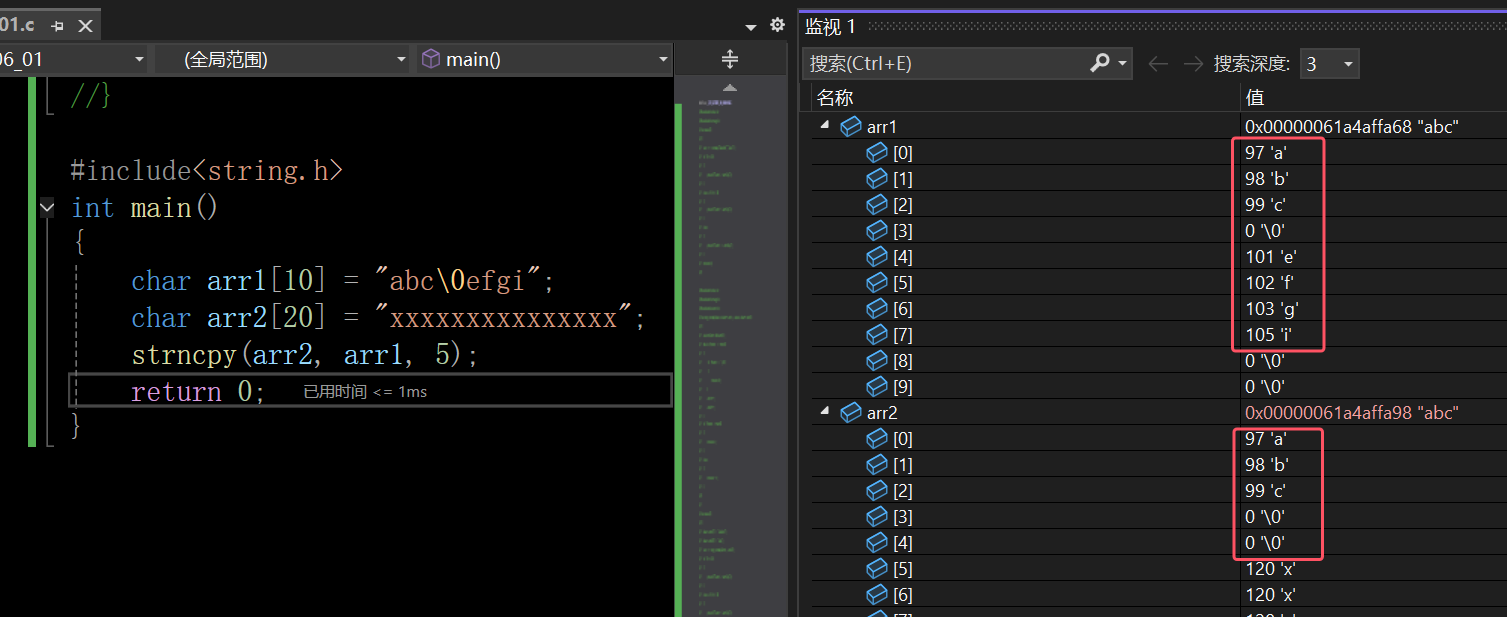
在这里插入图片描述
2.3 比较strcpy和strncpy
- strcpy函数拷贝到\0为止,如果目标空间不够的话,容易出现越界行为
- strncpy函数指定了拷贝的长度,源字符串不一定要有\0,同时在设计参数的时候,就会多一层思考:目标空间的大小是否够用,strncpy相对strcpy函数更加安全灵活。
三、strncat
char* strncat( char* destination,const char* source,size_t num );基本和strcat是一样的,多一个num,表示最多追加num个字符。
3.1 代码演示
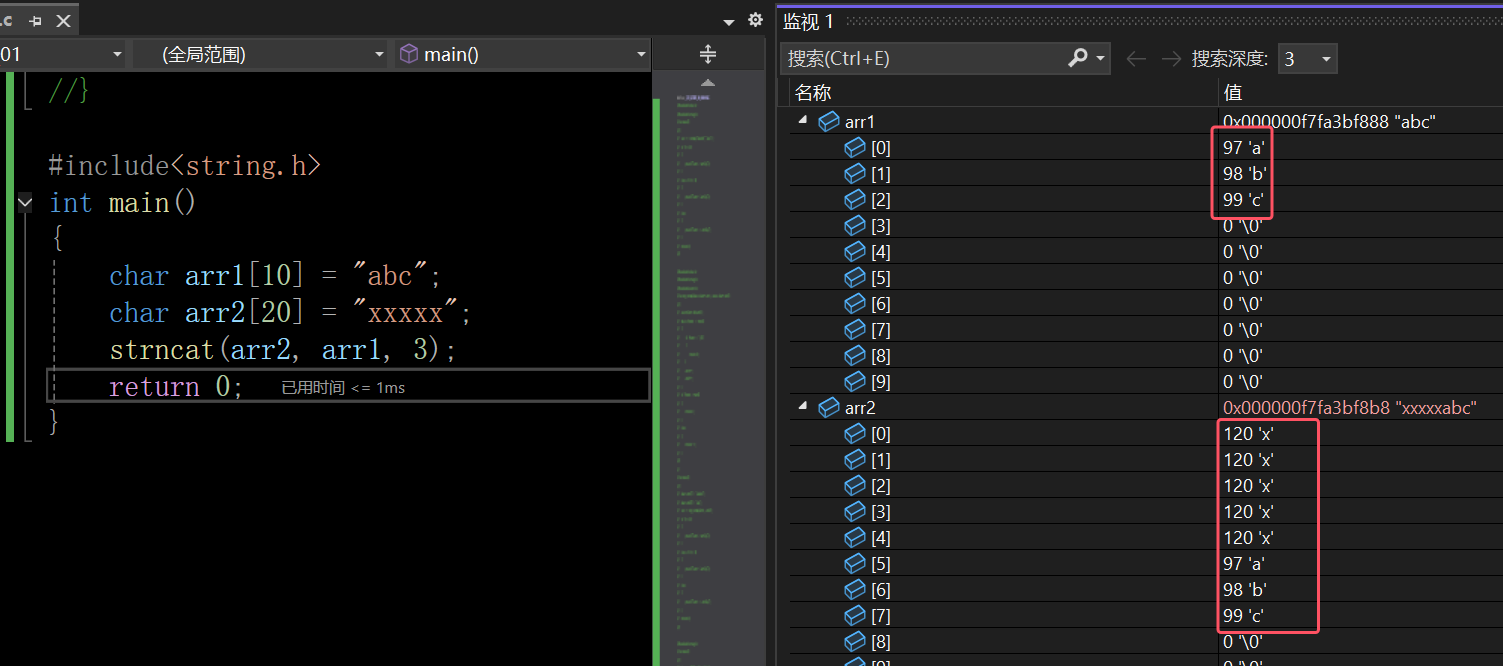
在这里插入图片描述
那么这里的\0是源头数据的字符串追加过来的呢?还是自动补的呢?
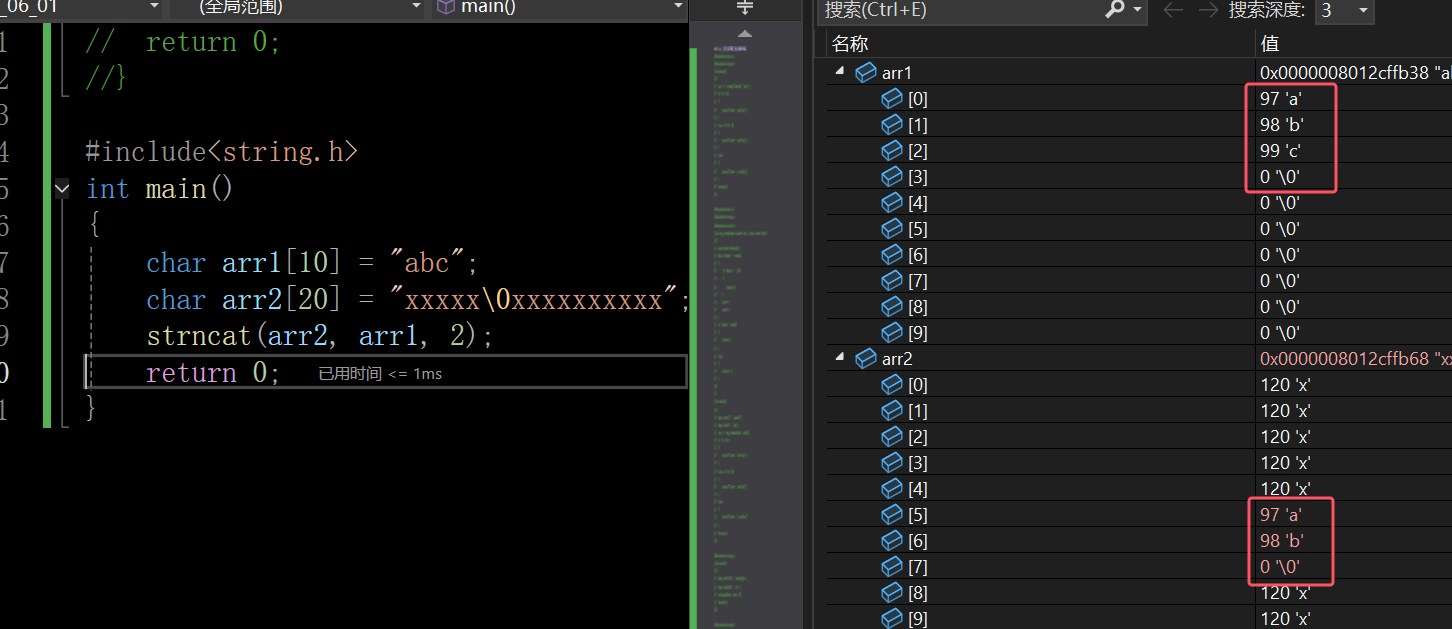
在这里插入图片描述
可以看出,这里只追加了两个字符,却在后面补了\0,说明追加的时候\0是自动补的,不是从源头数据追加的。
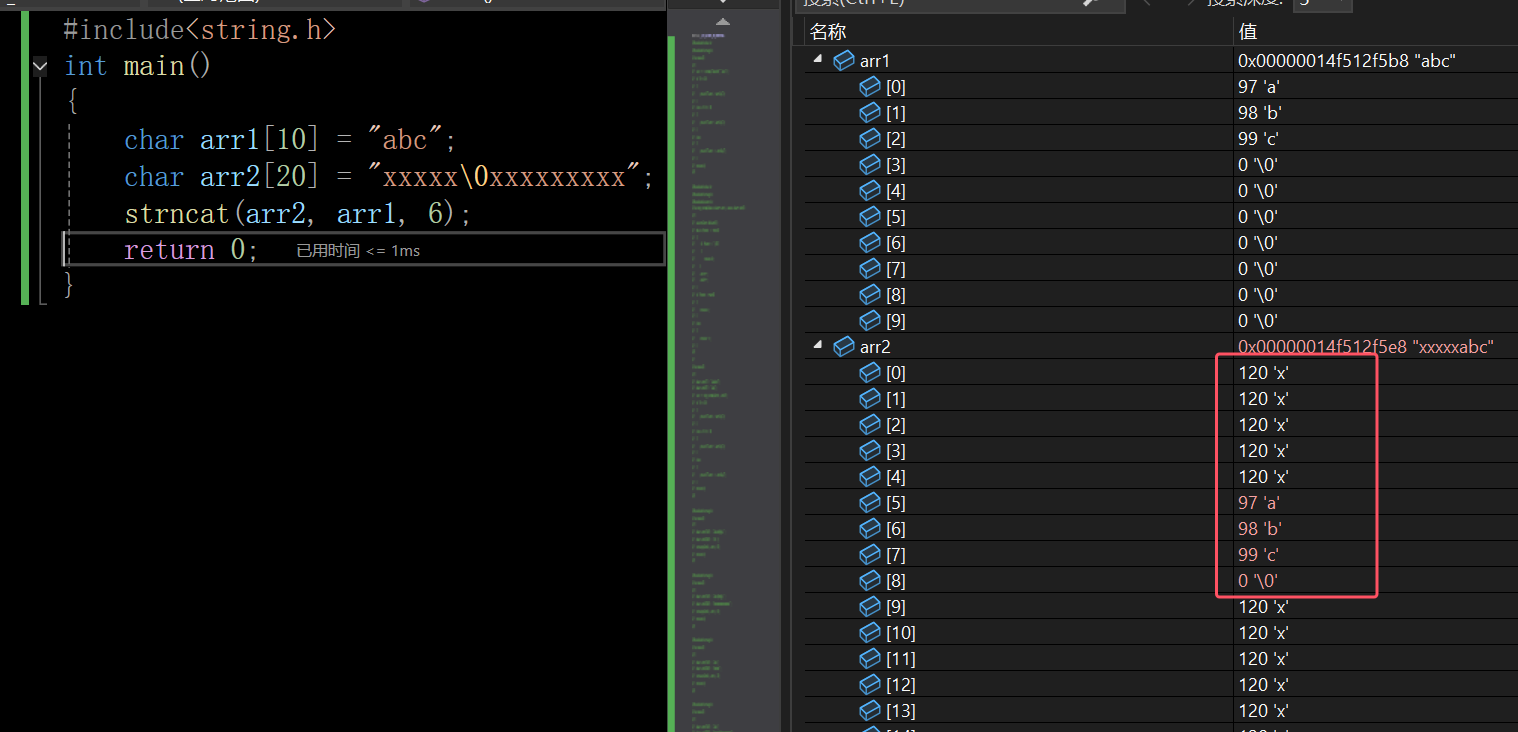
在这里插入图片描述
strnact追加6个字符的时候不会补3个\0,而是能追加的字符追加完后,补了一个\0,这就是strnact与strncpy的区别。
3.2 strcat和strncat对比
- 参数不同,strncat多了一个参数
- strcat函数在追加的时候要将源字符串的所有内容,包括\0都追加过去,但是strncat函数指定了追加的长度,追加过去后会自动补一个\0。
- strncat函数中源字符串中不一定要有\0了。
- strncat更加灵活,也更加安全
四、strncmp
int strncmp( const char* str1,const char* str2,size_t num );该函数与strcmp的区别就是多了一个参数num,意为比较两个字符串中前num个字符,即在num的范围内比较两个字符串谁大谁小。
4.1 代码演示
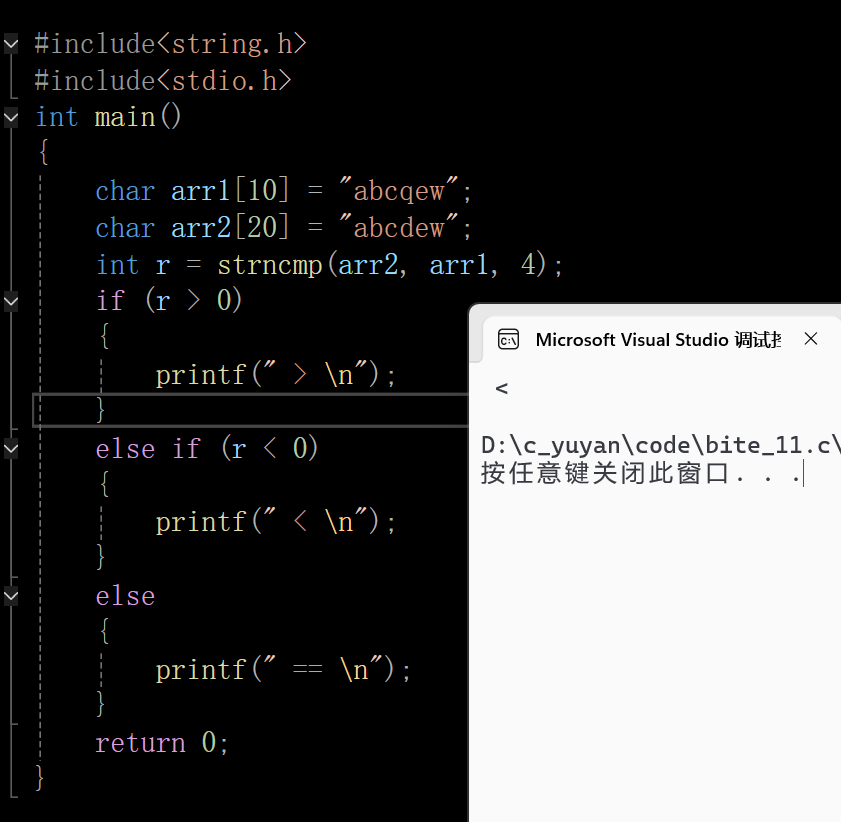
在这里插入图片描述
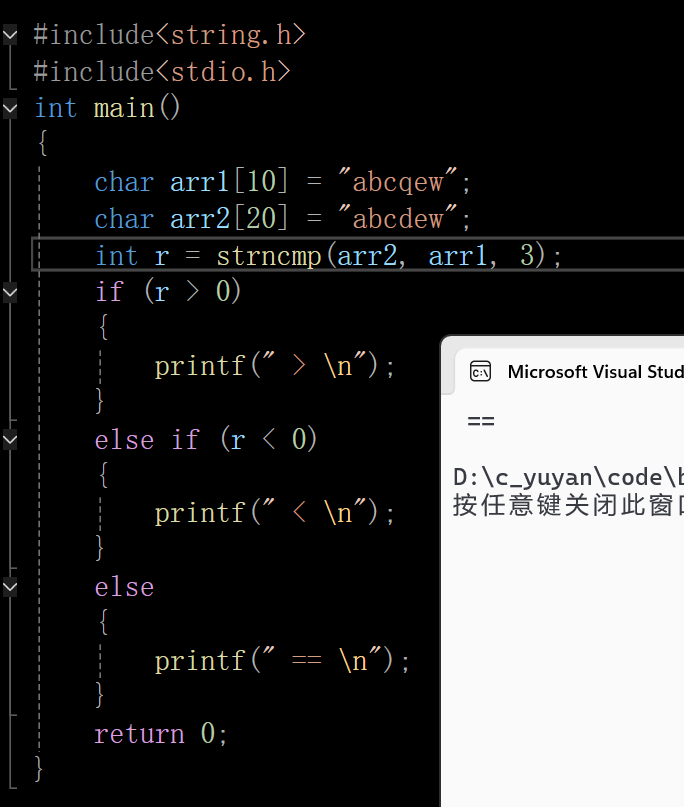
在这里插入图片描述
4.2 strcmp和strncmp比较
- 参数不同
- strncmp可以比较任意长度了
- strncmp函数更加灵活,更加安全。
五、strstr
char* strstr( const char* str1,const char* str2);功能: strstr函数,查找str2指向的字符串在str1指向的字符串中第一次出现的位置。
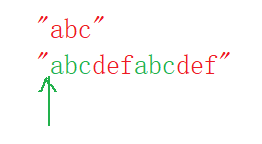
在这里插入图片描述
简而言之:在一个字符串中查找子字符串。 strstr的使用得包含<string.h>
参数: str1:指针,指向了被查找的字符串。 str2:指针,指向了要查找的字符串
返回值:
- 如果str1指向的字符串中存在str2指向的字符串,那么返回第一次出现位置的指针。
- 如果str1指向的字符串中不存在str2指向的字符串,那么返回NULL。
5.1 代码演示
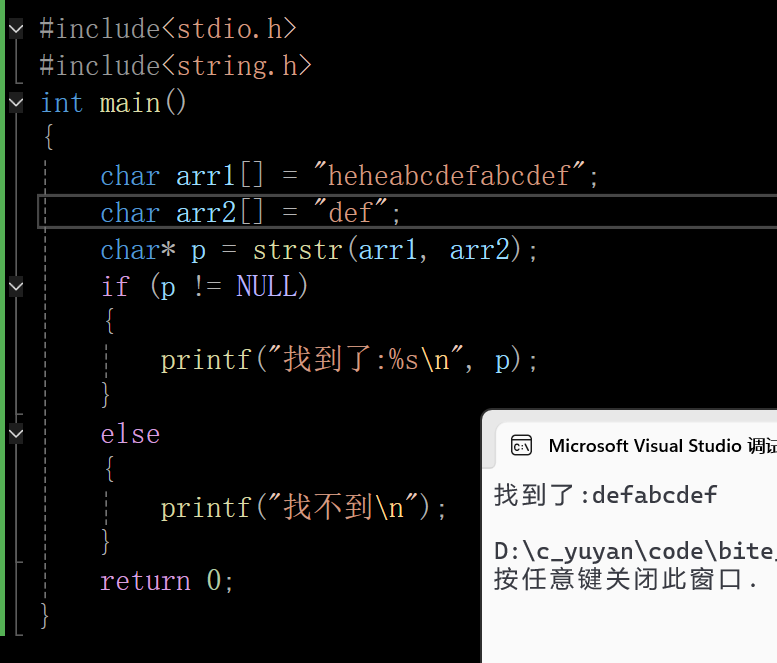
在这里插入图片描述
5.2 strstr的模拟实现(暴力匹配算法)
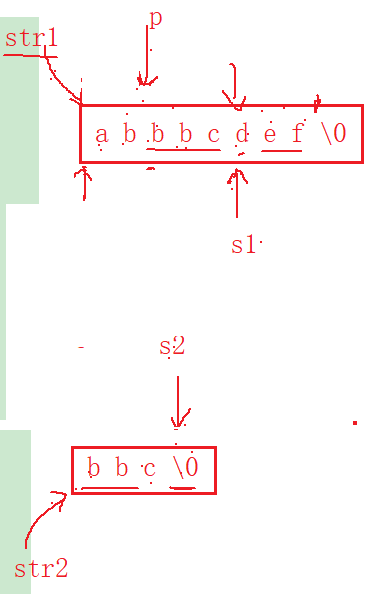
在这里插入图片描述
该模拟需要借助这张图理解,而且由于应用场景复杂,接下来我会把该逻辑覆盖到的场景一一列出来。
#include<stdio.h>
#include<assert.h>
//暴力匹配算法
char* my_strstr(const char* str1, const char* str2)
{
assert(str1 && str2);
const char* p = str1;
const char* s1 = NULL;
const char* s2 = NULL;
//特殊场景,空字符串作为子串
if (*str2 == '\0')
return (char*)str1;
//枚举查找的次数
while (*p)
{
s1 = p;
s2 = str2;
//找一次的匹配过程
while (*s1 && *s2 && (*s1 == *s2))
{
s1++;
s2++;
}
if (*s2 == '\0')
return (char*)p;
p++;
}
return NULL;
}
int main()
{
/*char arr1[] = "heheabcdefabcdef";
char arr2[] = "def";*/
char arr1[] = "abbbcdef";
char arr2[] = "bbc";
char* p = my_strstr(arr1, arr2);
//arr1被查找的字符串 arr2要查找的字符串
if (p != NULL)
{
printf("找到了:%s\n", p);
}
else
{
printf("没找到\n");
}
return 0;
}场景一:完全匹配
char arr1[] = "abcdef";
char arr2[] = "abc";第一次尝试(p = ‘a’): s1: ‘a’ → ‘b’ → ‘c’ s2: ‘a’ → ‘b’ → ‘c’ → ‘\0’ 循环结束时,*s2 == ‘\0’,匹配成功,返回 p。
场景二:部分匹配但最终失败(重叠字符)
char arr1[] = "abbbcdef";
char arr2[] = "bbc";第一次尝试(p = ‘a’): *s1 = ‘a’,*s2 = ‘b’,不相等,循环终止。 *s2 != ‘\0’,失败,p++。 第二次尝试(p = ‘b’): s1: ‘b’ → ‘b’ → ‘b’ s2: ‘b’ → ‘b’ → ‘c’ *s1 = ‘b’,*s2 = ‘c’,不相等,循环终止。 *s2 != ‘\0’,失败,p++。 第三次尝试(p = ‘b’): s1: ‘b’ → ‘b’ → ‘c’ s2: ‘b’ → ‘b’ → ‘c’ → ‘\0’ 循环结束时,*s2 == ‘\0’,匹配成功,返回 p。
场景三:子串长度超过主串
char arr1[] = "abc";
char arr2[] = "abcd";第一次尝试(p = ‘a’): s1: ‘a’ → ‘b’ → ‘c’ → ‘\0’ s2: ‘a’ → ‘b’ → ‘c’ → ‘d’ *s1 = = ‘\0’ 且 *s2 = = ‘d’,循环终止。 *s2 != ‘\0’,失败,p++。 后续尝试(p = ‘b’, ‘c’): 每次比较第一个字符就失败。 最终:p 指向 ‘\0’,外层循环结束,返回 NULL。
场景四:空字符串作为子串 特殊处理: 代码开头检查 *str2 == ‘\0’,直接返回 str1。
场景五:子串包含 ‘\0’
char arr1[] = "abc\0def"; // 实际内容: "abc"
char arr2[] = "abc\0"; // 实际内容: "abc" + '\0'第一次尝试(p = ‘a’): s1: ‘a’ → ‘b’ → ‘c’ → ‘\0’ s2: ‘a’ → ‘b’ → ‘c’ → ‘\0’ 循环结束时,*s2 == ‘\0’,匹配成功,返回 p。
第二次while循环跳出来的三种情况:
- 字符不相等(最常见的情况) 条件:*s1 != *s2,且 *s1 和 *s2 均不为 '\0
- str1 提前结束(主串长度不足) 条件:*s1 == ‘\0’,且 *s2 != ‘\0’
- str2 完全匹配(成功找到子串) 条件:*s2 == ‘\0’,此时无论 *s1 是否为 ‘\0’,均说明 str2 已全部匹配
补充1:空字符串(" ")是任何字符串的子串,返回主串起始地址(str1)符合 “子串在主串中首次出现的位置” 的定义 —— 空串的位置可以视为从主串第一个字符之前开始。类似于数学中的”空集是任何集合的子集“。
补充2:return (char*)p; 和 return (char*)str1; 这两处强制类型转换的目的是将 const char* 类型转换为 char* 类型,以满足函数返回类型的要求。
六、strtok
char* strtok( char* str,const char* delim );功能:
- 分割字符串:根据delim参数中指定的分隔符,将输入字符串str拆分成多个子字符串。
- 修改原始字符串:strtok会直接在原始字符串中插入’\0’终止符,替换分隔符的位置,因此原始字符串会被修改。
参数:
- str:首次调用时传入待分割的字符串;后续调用传入NULL,表示继续分割同一个字符串
- delim:包含所有可能分隔符的字符串(每个字符均视为独立的分隔符)。
返回值:
- 成功时返回指向当前子字符串的指针。
- 没有更多子字符串时返回NULL。
使用步骤:
- 首次调用:传入待分割字符串和分隔符
- 后续调用:传入NULL和相同的分隔符,继续分割。
- 结束条件:当返回NULL时,表示分割完成。
6.1 代码演示
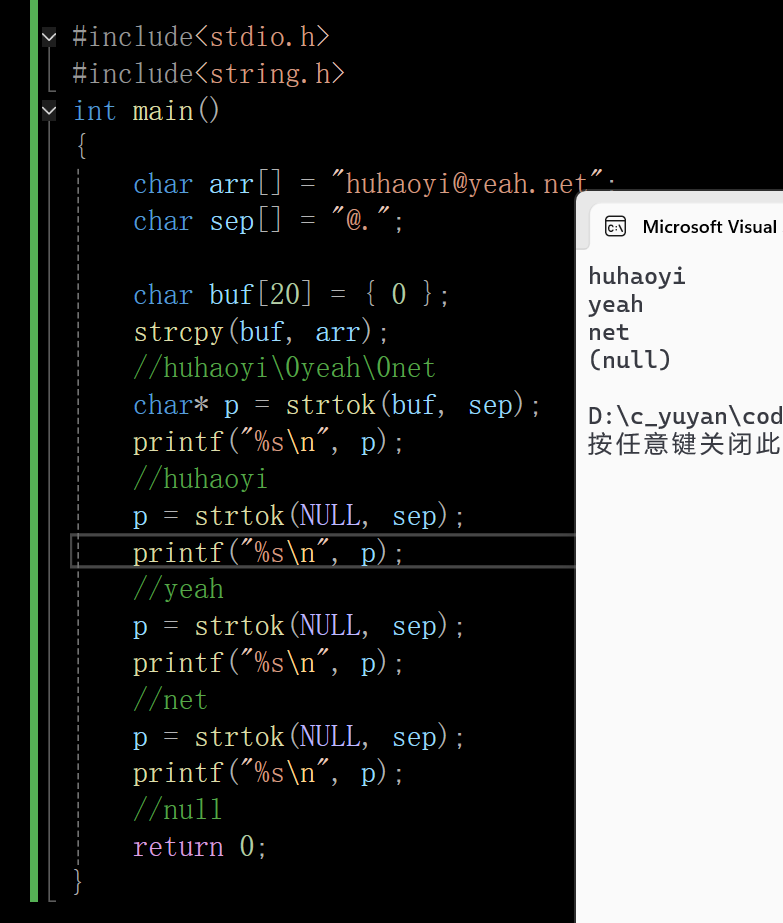
在这里插入图片描述
第一次调用时,会从arr里从头找分隔符,会把字符串里的@符号改为\0,同时返回h的地址。
一般不会真的想改变原字符串的内容,就会提前拷贝一份,把arr里的内容拷贝给buf,做改动的时候只有buf改动。
这里为什么在第二次调用的时候传空指针还能切割原来的字符串呢?它是怎么找到地址的呢? 说明在上一次调用的时候会记住y的地址,这个函数在设计的时候,内部会放一个静态变量,此变量即使在外部函数调用结束后也不会销毁,下一次传空指针的时候会从记住的地址继续向后找,找到最后一个\0时,返回n的地址。再往后找返回一个空指针。
这样的写法显得太过笨重,想切割还要提前知道切几段,接下来再提供一种写法:
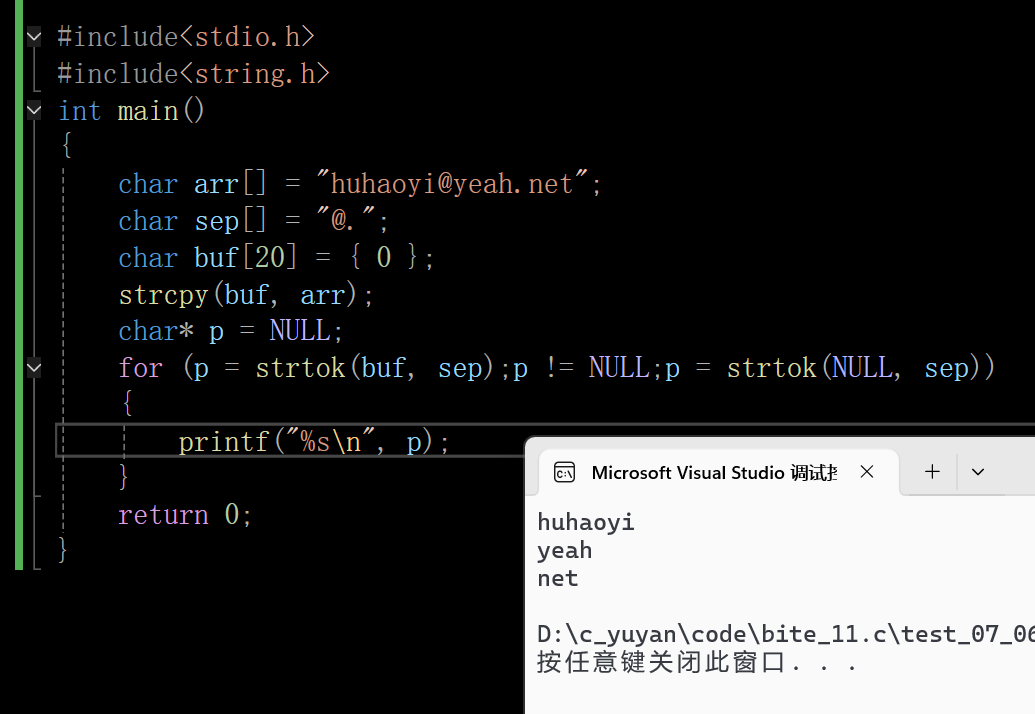
在这里插入图片描述
6.2 strtok的注意事项
- 破坏性操作:strtok会直接修改原始字符串,将其中的分隔符替换为’\0’。如果需要保留原字符串,应先拷贝一份。
- 连续分隔符:多个连续的分隔符会被视为单个分隔符,不会返回空字符串。
- 空指针处理:如果输入的str为NULL且没有前序调用,行为未定义(即第一次调用strtok就直接传空指针,程序会崩溃。
七、strerror函数的使用
char* strerror( int errnum );功能:
- strerror函数可以通过参数部分的errnum表示错误码,得到对应的错误信息,并且返回这个错误信息字符串首字符的地址。
- strerror函数只针对标准库中的函数发生错误后设置的错误码的转换。
- strerror的使用需要包含<string.h> 在不同的系统和C语言标准库的实现中都规定了一些错误码,一般是放在errno.h这个头文件中说明的,C语言程序启动的时候就会使用一个全局的变量errno来记录程序的当前错误码,只不过程序启动的时候errno是0,表示没有错误,当我们在使用标准库中的函数的时候发生了某种错误,就会将对应的错误码,存放在errno中,而一个错误码的数字是整数,很难理解是什么意思,所以每一个错误码都是有对应的错误信息的。strerror函数就可以将错误码对应的错误信息字符串的地址返回。
参数: errnum:表示错误码 这个错误码一般传递的是errno这个变量的值,在C语言有一个全局的变量叫:errno,当库函数的调用发生错误的时候,就会将本次错误的错误码存放在errno这个变量中,使用这个全局变量需要包含一个头文件errno.h。
在这之前要知道错误码是什么

在这里插入图片描述
网页在访问不到资源的时候,就会弹出一个404出来,404的意思就是无法访问此页面。
而上面所说的函数就能把对应的错误码转换为对应的错误信息。
7.1 代码演示
这里把一些错误码对应的错误信息打印出来
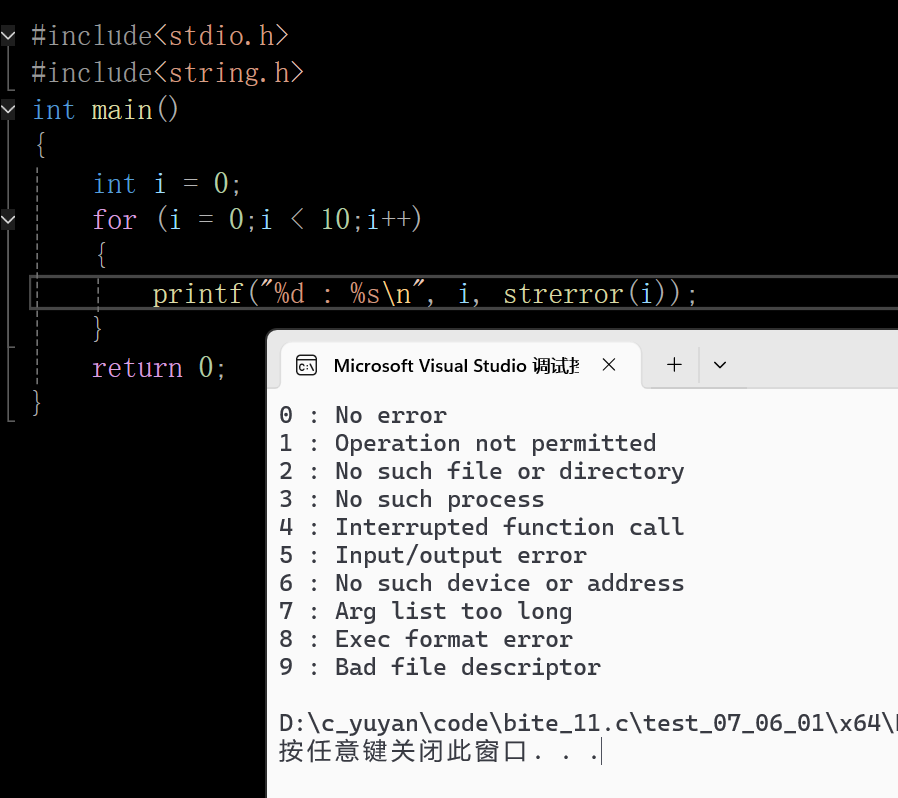
在这里插入图片描述
0:无错误 1:不允许的操作 2:没有那个文件或目录 3:没有那个进程 4:中断的函数调用 5:输入 / 输出错误 6:没有那个设备或地址 7:参数列表过长 8:可执行文件格式错误 9:错误的文件描述符
在一个真实的错误中,该函数是怎么使用的呢?这里手搓一个错误:
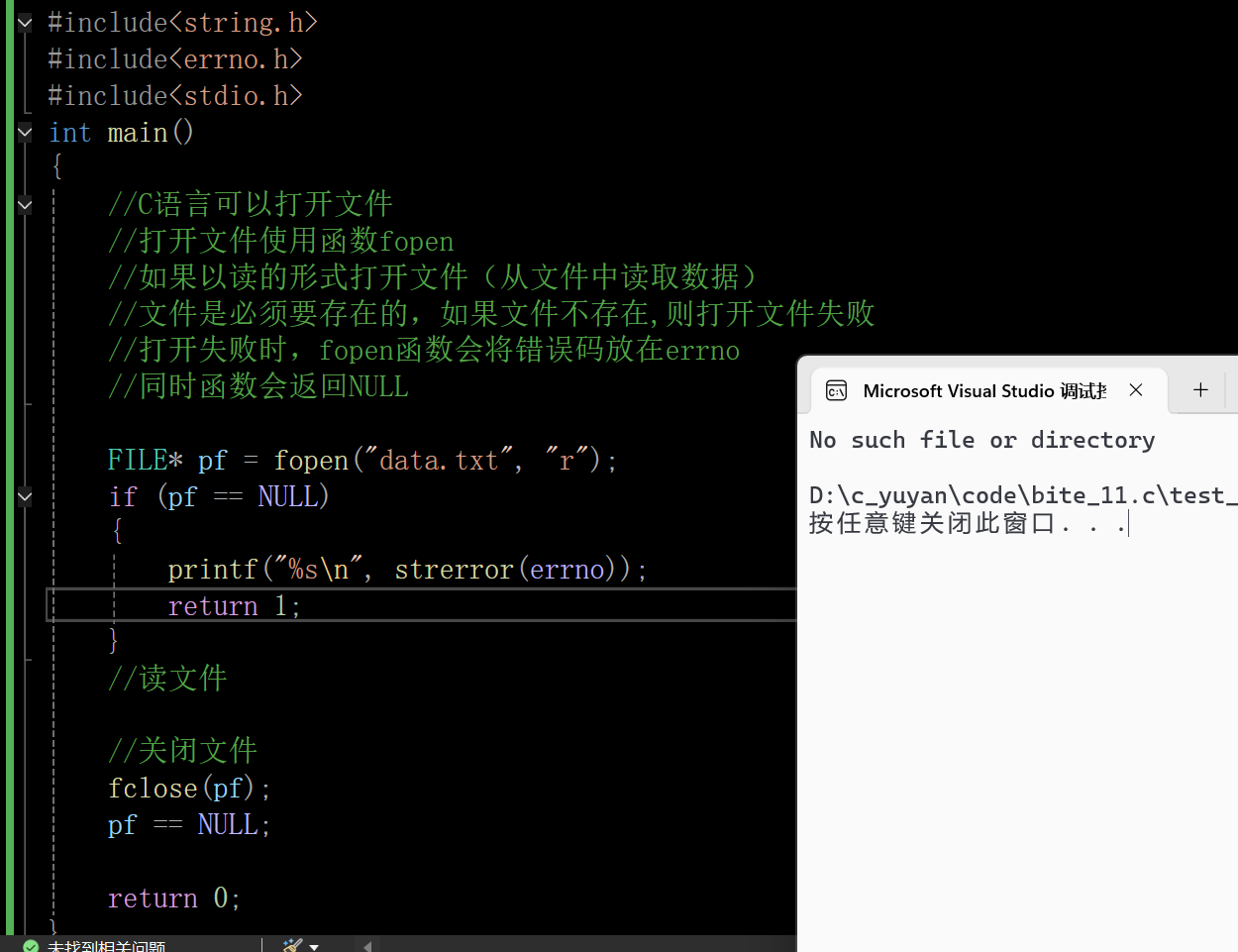
在这里插入图片描述
这里打开了一个根本不存在的文件,"r"的意思是以读的形式打开文件,该函数在打开文件之后会返回一个FILE类型的指针。
返回 1 表示打开文件失败
最后pf==NULL,防止其成为野指针。 创建了该文件就不会报错了。
7.2 perror
void perror( const char* str );perror相当于printf+strerror,它会自己去找错误码,并且将错误码代表的错误信息打印出来。perror函数打印完参数部分的字符后,再打印一个冒号和一个空格,再打印错误信息。
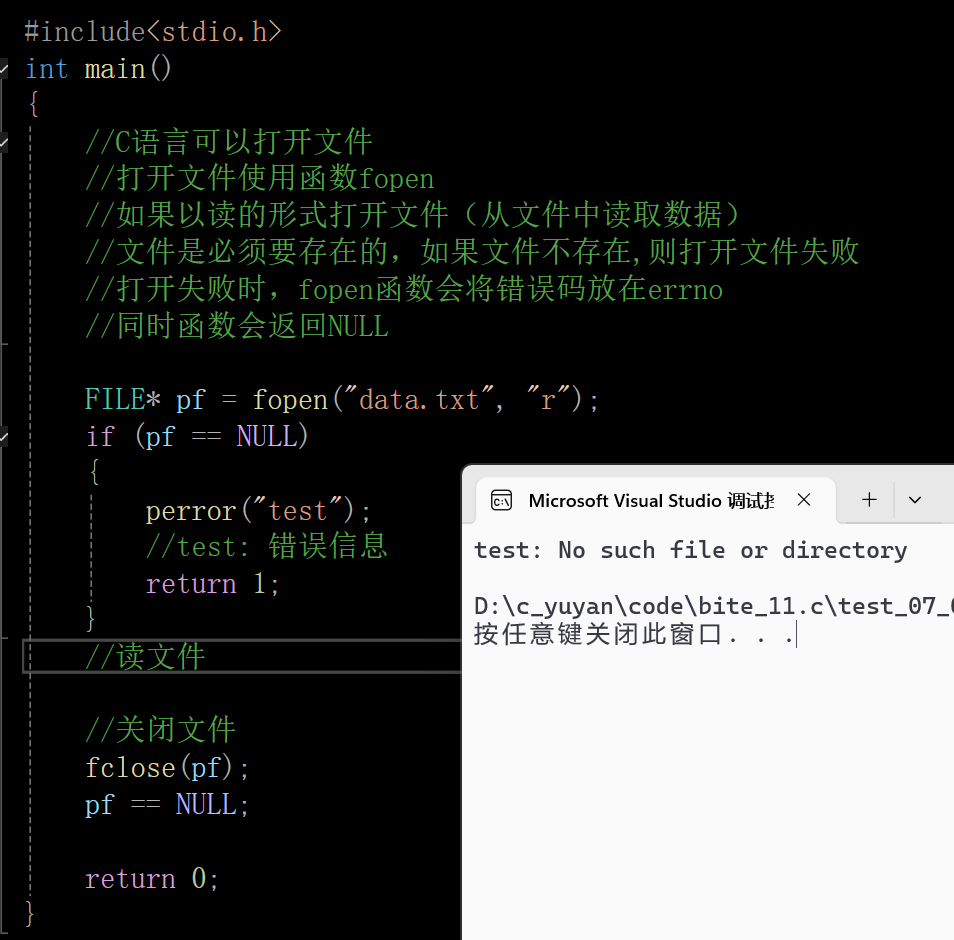
可以直观的看出,这个函数很方便,既不用包含头文件,也不需要printf,但也有其对应的缺点,strerror能自定义的部分实则更多,更加灵活。
总结
以上就是这部分内容的全部了,有时候不得不说,永远保持谦逊,小编一直觉得自己C语言其实学的还可以,很扎实,但是越学到后面越是感觉,路还很远。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-07-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号