超级增强子系列10: bedtools筛选Lost/Gained超级增强子

超级增强子系列10: bedtools筛选Lost/Gained超级增强子

三兔测序学社
发布于 2025-12-29 12:57:08
发布于 2025-12-29 12:57:08
前言
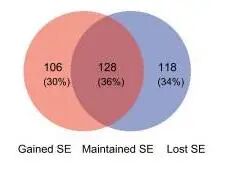
在进行不同组别超级增强子区域的比较,通常会进行交集分析,并根据结果将超级增强子分为Maintained (维持,交集部分),Lost(在实验组丢失),Lost(在实验组获得)这三种类型。用bedtools intersect 语法即可完成。如下图所示。
代码如下:
1.Maintained SE的分析。
bedtools intersect -a KO_SE.bed -b WT_SE.bed -wa -wb >KO_overlap_WT_SE.bed上述代码来实现两组之间SE交集部分具体情况。
bedtools intersect -a KO_SE.bed -b WT_SE.bed -wa >KO_overlap_WT_SE.bed
bedtools intersect -a WT_SE.bed -b WT_SE.bed -wa >WT_overlap_KO_SE.bed这两个代码是输出KO、WT组每组的Miantained SE的文件
2. Gained SE的分析。(以实验组的视角,Gained就是在实验组特有的吗,在对照组没有)
bedtools intersect -a KO_SE.bed -b WT_SE.bed -v > KO_gained_SE.bed3.Lost SE的分析。(以实验组的视角,Lost就是在对照组存在,实验组丢失)
bedtools intersect -a WT_SE.bed -b KO_SE.bed -v > KO_lost_SE.bed4.查看不同类型SE的数量
在linux服务器中。用wc -l *SE.bed 查看每一个文件的行数即可知道SE的数量。
5.最后在绘制软件中绘制两个大小相同的圆形,部分重叠。然后将不同类型的SE数量标记在图形内。
🔬 科研不止于工具,更在于思路。选择正确的工具,才能让数据说话。
【超级增强子系列文章】
超级增强子系列1:super enhancer鉴定-ROSE软件的安装与使用
超级增强子系列2:ROSE准备gff文件:peak 信息文件转化为9列gff格式文件R代码
超级增强子系列3:R语言批量处理ROSE文件生成SE与TE.bed文件
超级增强子系列5:用ChIPseeker进行超级增强子基因注释
超级增强子系列6:GREAT-基因组调控元件专业注释富集工具
超级增强子系列7: 用MEME进行超级增强子转录因子motif 富集分析实战
超级增强子系列8: motif 富集分析工具XSTREME输出文件解释
超级增强子系列9: ggseqlogo进行Motif文件可视化
如果你觉得这篇博文对你有帮助,请点赞、收藏、转发!支持我们持续输出优质内容!
关注“三兔测序学社”,获取更多实用教程与前沿解读。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号