Agent常见测评基准概述


对于 agent 的测评,学术界和工业界提出了多种评测基准。这些基准针对不同场景(如通用任务、网页浏览、操作系统、办公软件、垂直领域等),通过构建交互环境和任务库来评估模型的规划、决策、工具使用、执行可靠性和安全性。按类别梳理当前比较有代表性的 Agent 基准分为以下几类。
一、综合/通用基准
AgentBench
目的:评估 LLM 作为 Agent 的推理与决策能力。
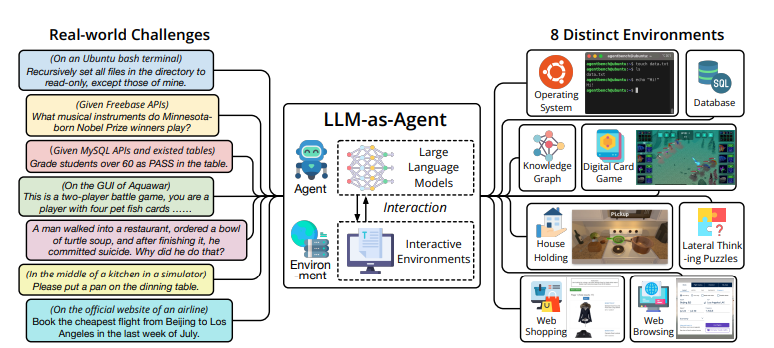
环境与任务:基准包含操作系统、数据库、知识图谱、数字卡牌游戏、智力拼图、家庭服务、网页购物和浏览等八个环境,任务通常需要 5–50 步才能完成。
特点:通过跨多个环境考察模型的多轮决策和长程推理能力。论文指出现有商业模型在复杂环境中表现较好,但开源模型仍有明显差距;失败原因主要包括长期推理和决策能力不足。
ARC-AGI
目的:测试 agent 的用推理能力,定位为"流体智能"(fluid intelligence - the ability to reason, solve novel problems, and adapt to new situations),是在没见过的新任务上做抽象、归纳、类比、组合规则的能力,而不是测背知识。
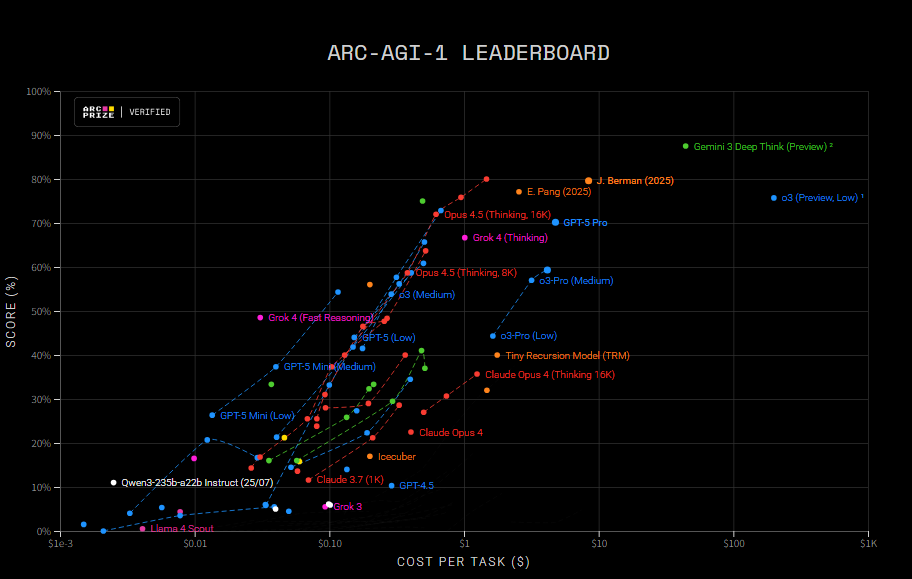
版本演进:
- • ARC-AGI-1:最初版本,已经被玩了好几年,存在任务信号有点粗、private set 容易被间接污染等问题
- • ARC-AGI-2(现在主打的版本):2025 年推出的升级版:保留"方格抽象任务"的形式,但重做了一套更精细的任务集,希望对"抽象推理 / fluid intelligence"的能力给出更细颗粒度信号。包含 1,000 个公开训练任务 + 120 个公开评测任务,以及额外的 private test set,用来防过拟合。各大 leaderboard(ARC-AGI-2 榜)现在基本都以 ARC-AGI-2 为主。
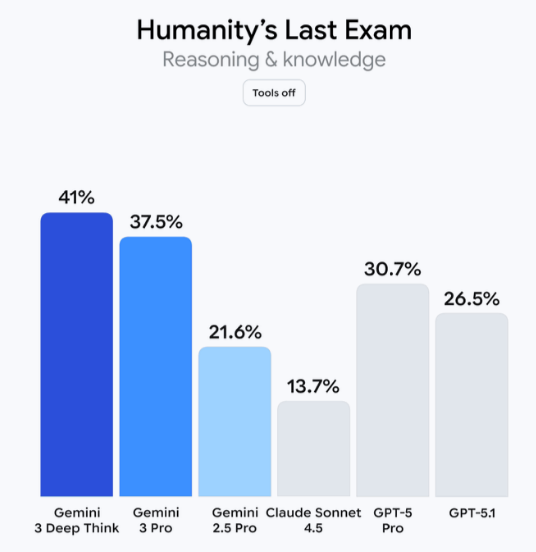
HLE (Humanity's Last Exam)
顾名思义,HLE 设计当成给 LLM/Agent 的一套"人类最后一次闭卷大考"。
特点:
- • 一共 3,000 题,其中 2,500 题公开,500 题私有用于防止对 benchmark 过拟合
- • 题目覆盖几十个学科:数学 (~41%)、物理、化学、生物/医学、计算机/AI、工程、人文社科等
- • 大约 14% 是多模态题(要看图/图表),24% 为选择题,其余是短答案 / 精确匹配题,全部适合自动判分

难度:
所有题都由全球领域专家命题,多轮过滤 + 让前沿模型先"试考";模型做得不好人类再审题,确保题目是人类专家能做、模型却很吃力的那一档。题目设计成不能靠简单检索快速查到答案,必须靠模型自身的知识储备 + 推理能力来解答。
目标是接替已经"接近饱和"的 MMLU 等基准,成为一段时间内衡量 frontier 模型综合学术/推理能力的主力考试。
这个 benchmark 难度相当高,目前推理能力最强模型 Gemini 3 Deep Think 在这个 benchmark 上刚突破 40。
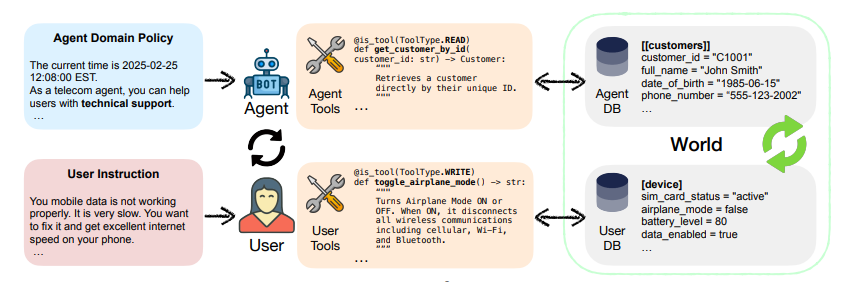
τ-Bench
目的:补足通用基准对真实业务流程可靠性评测的不足。
场景:在零售、客服、航空等真实领域构建任务,要求 Agent 与模拟用户和 API 多轮互动以完成复杂目标。
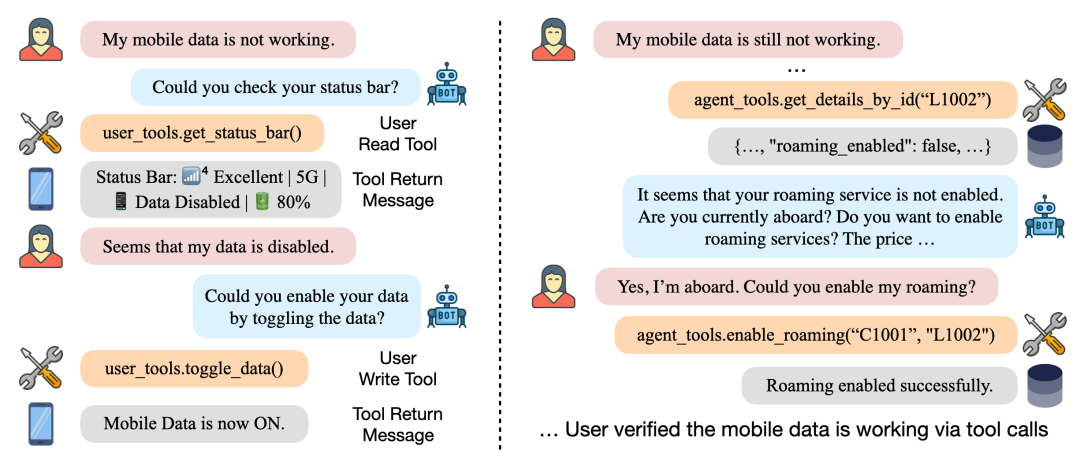
Sample τ-bench Trajectories
新指标:提出 pass^k 统计,同一任务重复运行多次仍成功的概率,用于衡量 Agent 的稳定性和可靠性。
特点:强调遵守业务规则、长期对话、数据库状态一致性等,适合评估生产级客服或运营代理。
更新:今年 6 月发布了 τ²-Bench,增加了复杂度,引入了用户主动参与调用工具,更加考验 agent 的协作能力和真实场景泛化性。
二、网页/浏览器基准
WebArena
环境:WebArena 构建电商、论坛、代码托管和内容管理等四类仿真网站,提供 812 个模版任务及多种变体。
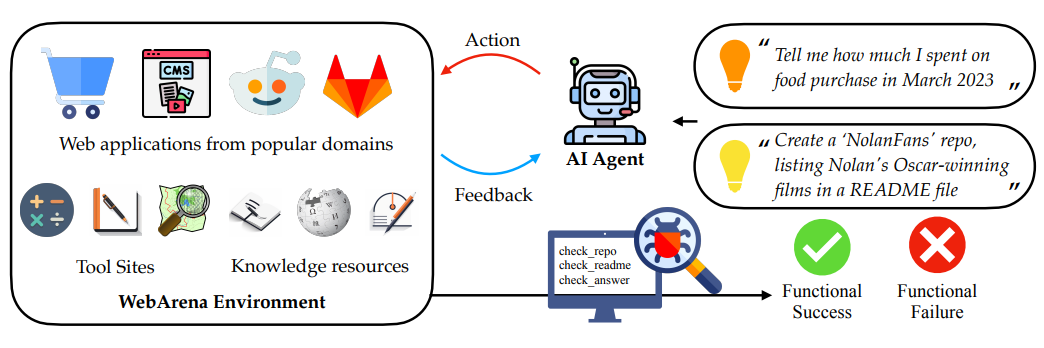
评测指标:任务成功的定义基于是否达到最终目标状态,而不强制限定具体操作顺序;成功率由环境状态评估,不依赖人工评分。
特色:强调真实网页交互(点击、搜索、表单填写),适用于评估浏览器代理的操作能力和泛化性。
Mind2Web 系列
Mind2Web 是一个涵盖数百个真实网站和数十个领域的数据集,任务需要模型实时上网并综合多个页面信息。
Mind2Web 2 进一步面向 Agentic Search 和 Deep research Agent,构造了 130 个现实、长程、高难度搜索任务,同时提出 Agent-as-a-Judge 评估框架:为每个任务构建一个"判卷 Agent",基于树状 rubric 结构自动判定结果。
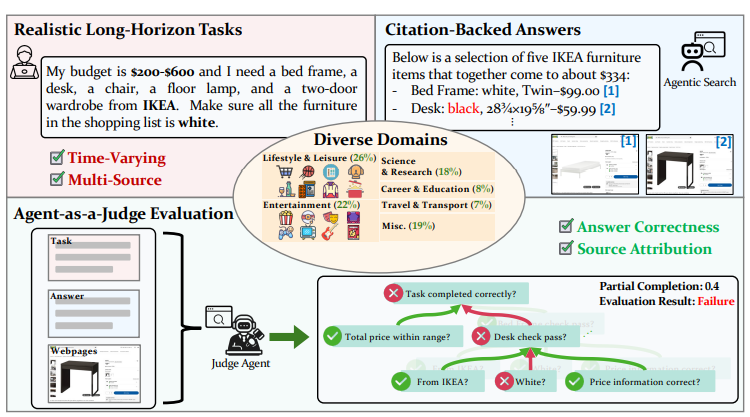
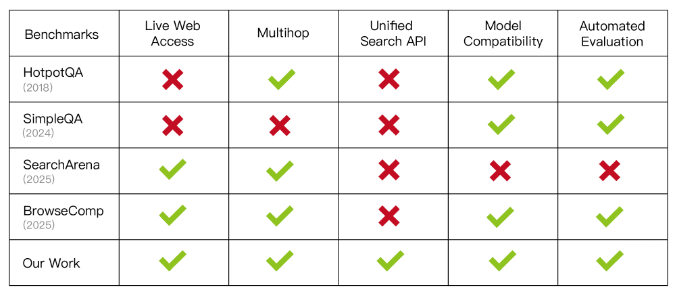
BrowseComp 系列
BrowseComp 是 OpenAI 提出的一个专门测试深度网页浏览 + 困难检索信息能力的 benchmark。
任务形式:
- • 共 1,266 个问题,每个问题需要 Agent 持续在互联网上多跳检索,跨多个网站拼接信息才能答出来
- • 问题是从罕见事实反向构造的,刻意避开简单搜索能直接命中的内容,让 Agent 必须不断改写查询、筛选证据和多跳推理
- • 虽然问题很难,但答案被设计成简短且易校验(日期、数字、专有名词等),方便自动对比参考答案
评测重点:
- • 是否会持续改写搜索词
- • 是否能在多个网页间综合交叉验证信息
- • 是否能定位到人类 10 分钟内都很难找到的细节
扩展版本:
- • BrowseComp-ZH:针对中文 Web 重新手工构造 289 个高难度多跳问题,覆盖 11 个领域,所有问题由母语者从零撰写,而不是英文翻译

- • MM-BrowseComp:在 BrowseComp 基础上扩展为多模态场景,加入图片、视频等信息源,用来评测多模态 Web Agent 的检索和推理能力

三、电脑/办公自动化基准
OSWorld / OSWorld-Human
目标:评估多模态 Agent 在真实操作系统上的能力。
任务集:构建 369 个真实电脑任务,涉及操作系统和各种桌面/网页应用,如文件管理、软件操作、跨应用工作流等。OSWorld-Human 另外收集人类完成这些任务的轨迹以对比效率。
特点:提供跨操作系统(Ubuntu/Windows/macOS)的统一环境,支持交互式学习和执行式评估,揭示现有模型在 GUI 操作、知识掌握方面的不足。
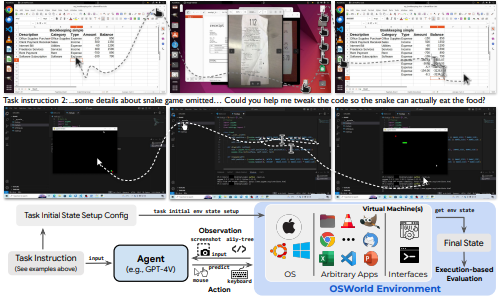
OdysseyBench
目的:解决许多基准只测原子任务的问题,评估 Agent 在长链办公流程中的能力。
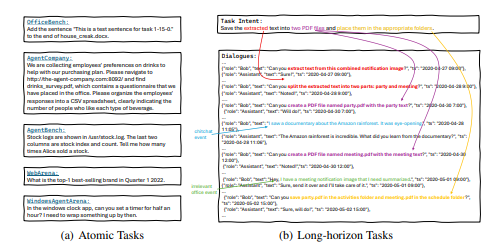
内容:包含两套子集:OdysseyBench+ 收集 300 个来源于现实的办公任务,OdysseyBench-Neo 生成 302 个复杂任务。这些任务跨 Word、Excel、PDF、邮件、日历等应用,需要识别历史信息并进行多步推理。
创新:提出 HomerAgents 多智能体框架自动生成长链任务和对话,用以构建规模化基准。
AppWorld
专门用来评测交互式编码 Agent 在"多应用 + 多用户"的复杂数字环境中的能力。
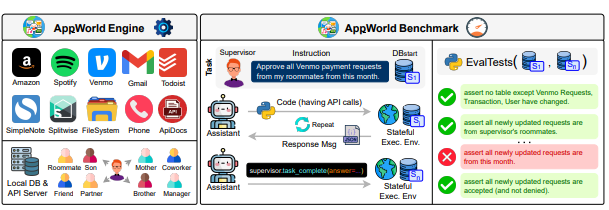
环境规模:基于 AppWorld Engine 搭建,包含 9 个日常应用(如笔记、消息、购物等),通过 457 个 API 暴露操作接口,并模拟了约 100 个虚拟用户的日常数字行为。
任务设计:AppWorld Benchmark 提供约 750 个任务,这些任务要求 Agent 不是简单顺序调用 API,而是生成包含复杂控制流的代码,跨应用协调完成如"整理事项、发消息、比价下单"这类真实工作流。
评测方式:采用基于状态的单元测试进行程序化评估:
- • 允许同一任务存在多种合法解法
- • 通过检查任务相关状态是否正确变化,同时检测"附带伤害"——有没有错误修改其它数据
四、任务自动化与工具使用基准
TaskBench
目标:系统衡量 LLM 在任务自动化中的能力。
方法:将自动化过程分为三个阶段:任务分解、工具选择和参数预测,并使用"工具图"表示任务结构。TaskEval 则为每个阶段提出自动化评测方法,确保结果与人工评分一致。
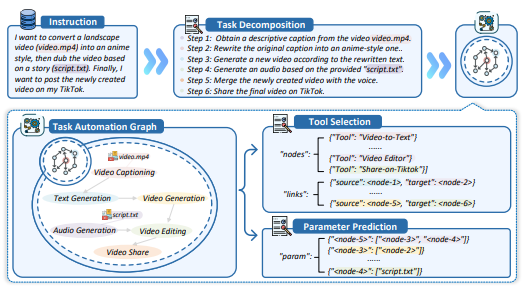
定位: 为复杂工作流的 agentic 评估提供标准化框架,方便开发者定位模型弱点。
ToolBench
数据构建:从 RapidAPI Hub 收集 16,464 个真实 REST API,利用 GPT-4 生成涉及单工具和多工具的多样化指令,并用搜索算法标注解决路径。
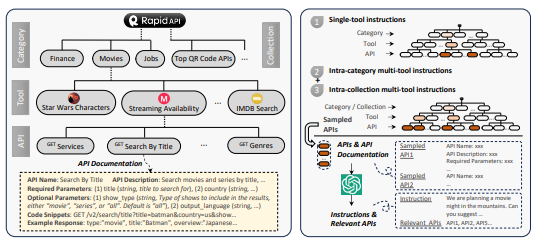
评测:开发自动评估器 ToolEval,用于判断模型选择 API、参数及调用顺序的正确性。
成效:基于 ToolBench 微调的 ToolLLaMA 能执行复杂指令并在未见过的新 API 上泛化良好。
BFCL
如果往更工程一点看,现在普遍使用 BFCL 进行"函数调用 / 工具调用能力"测评。
特点:
- • 覆盖 Python / Java / JS / REST API 等多种形式的函数/工具
- • 2000+ 问题+函数文档对,既有一次性调用,也有多步、并行、多函数组合场景
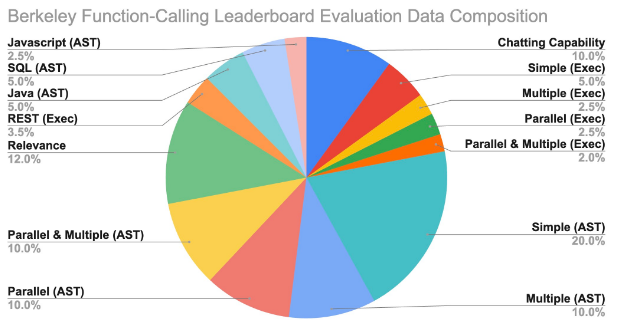
指标设计:
- • AST 准确率(函数调用结构对不对)
- • 可执行性(能不能跑)
- • relevance / irrelevance detection(能否区分"该不该调这个函数")
BFCL 更像一个面向函数调用/工具调用的通用评测基建,现在已经发布了第 4 版(holistic agentic evaluation)。
MCP-Atlas
Scale AI 做的一个专门测"真实工具调用 + 多步骤工作流"能力的榜单型 benchmark,所有任务都通过 Model Context Protocol (MCP) 调真实服务器上的工具来完成。
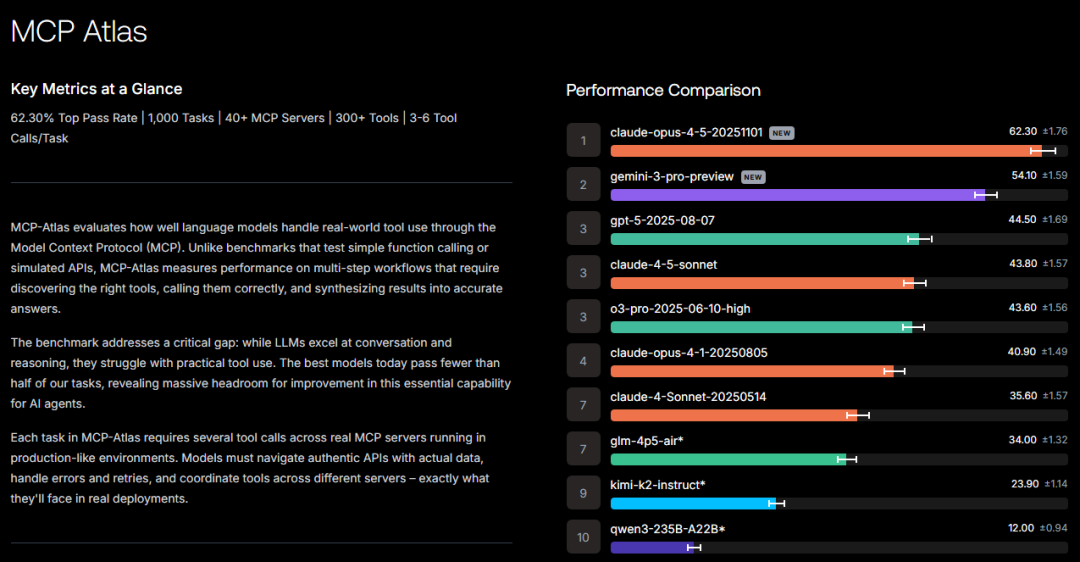
特点:
- • 数据集目前是 1,000 个人工编写任务,每个任务都需要多次工具调用才能解出来
- • 这些任务可以从 40+ 个 MCP server、300+ 工具里选工具,覆盖搜索、数据库、第三方 API、开发运维系统等
- • 单个任务典型要 3–6 次工具调用才能闭环,链路中还会遇到真实 API 的报错、异常和不稳定返回
五、代码与软件开发基准
SWE-bench
背景:面向真实软件仓库中的 bug 修复任务,测试 AI 系统解决 GitHub issue 的能力。
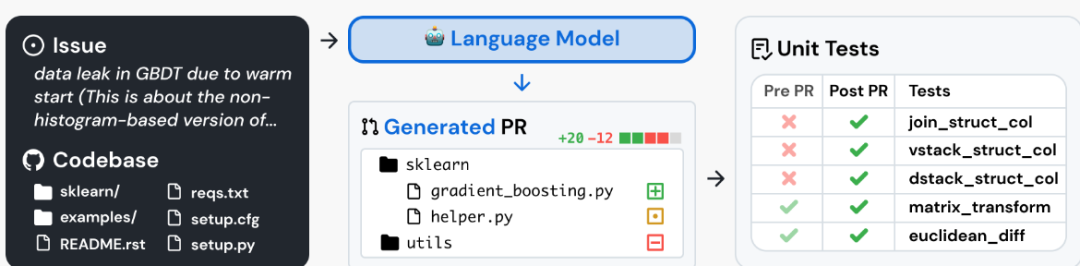
数据集:从 12 个流行 Python 仓库爬取 2,294 个"Fail-to-Pass"实例,构建执行环境,在缺少补丁时相关测试失败,但应用补丁后测试通过。
评测流程:系统读取 issue 描述,修改代码库解决问题,评测成功与否由测试用例决定。
扩展:后续衍生出 SWE-bench Verified、SWE-bench Bash Only、SWE-bench Multimodal 等系列,用以衡量不同模型和代理框架在代码修复上的表现和效率。
Terminal-Bench
专门面向终端环境的 Agent 基准,评估 agent 能否自主处理现实世界中端到端终端可执行任务的能力。
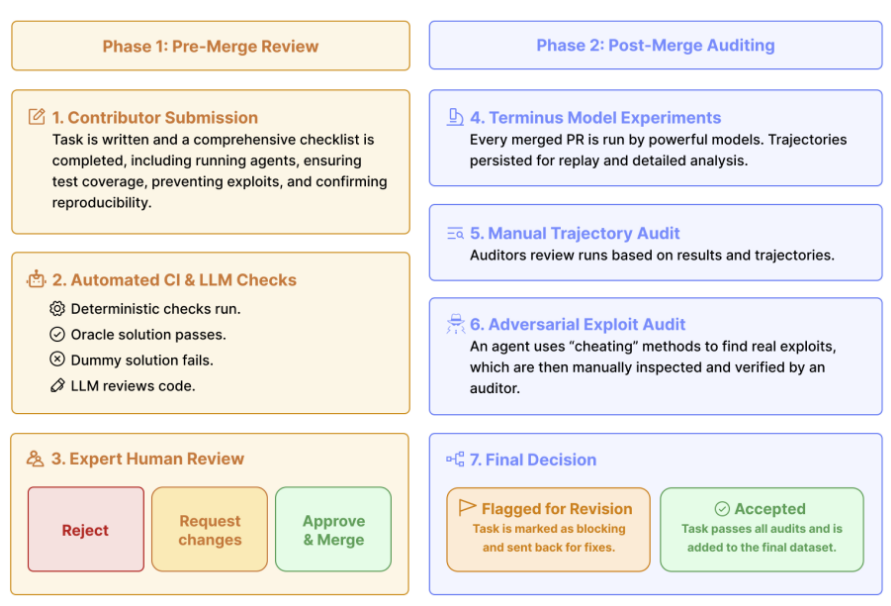
目标:衡量 Agent 在真实 shell/terminal 中执行复杂任务的能力,从简单命令到完整的工程工作流(例如编译项目、配置环境、部署服务、跑数据管道等)。
任务与环境:
- • 由一组经过人工和模型双重验证的任务构成,每个任务都配套 Docker 沙箱、期望解法和测试用例,确保结果可复现
- • 覆盖场景包括:编译和调试复杂项目、修复 Python/包管理环境、搭建本地服务器和数据库、执行多步数据处理脚本、排查网络/安全配置等
最新的 Terminal-Bench 2.0 进一步提升了任务质量和验证力度,将 Agent 容器化,支持大规模并行回放和 RL/SFT 训练闭环,同时提供更细粒度的环境级指标(不只 pass/fail),朝着"统一 Agent 评测基建"方向发展。
六、垂直行业基准
垂直行业 benchmark 主要包括医疗,金融,科研等数字化基础较好,并且有明确量化标准的行业。
医疗:MedAgentBench
斯坦福 ML Group 构建的虚拟电子病历(EHR)环境,用于评估医疗领域的 LLM Agent 能力。
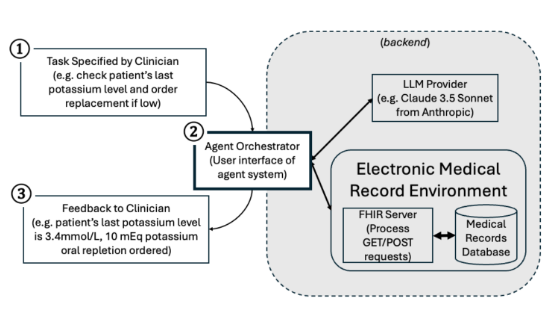
任务设计:包含 300 个由医生编写的临床任务,横跨 10 个类别,需要 Agent 调用 FHIR API 在患者数据上进行检索、下医嘱、文档更新等操作。
环境特点:基于 100 个匿名患者、70 多万条医疗记录构建虚拟环境,支持真实的操作和状态追踪。该基准弥补了医疗 AI 评测仅停留在问答层面的不足,重视规划、决策和执行的综合能力。
金融:Agent Market Arena
支持实时金融交易构建的 benchmark,任务设置为持续长时间运行,而不是在固定历史窗口回放。
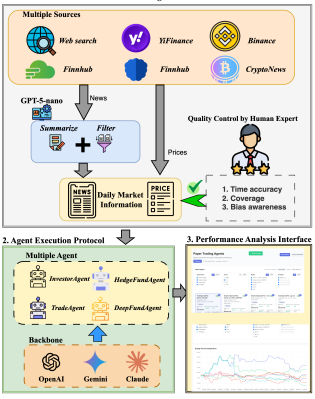
特点:
提供统一框架,内置多种 Agent 架构:InvestorAgent(单 Agent 基线)、TradeAgent / HedgeFundAgent(不同风险风格)、DeepFundAgent(带记忆和推理)等,同时对比多种模型后端(GPT-4o, GPT-4.1, Claude, Gemini 等)。
评测指标:
- • 收益、夏普比率、最大回撤等财务指标
- • 同时分析不同 Agent 架构的行为差异,发现"框架设计往往比模型换哪个更影响结果"
科研:ScienceAgentBench
专门评估语言 Agent 在数据驱动科学发现工作流里的能力,不是只做简单 QA,而是写能跑的科研代码。
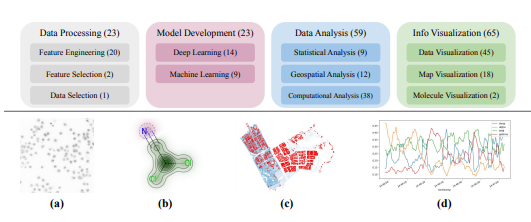
任务构造:
- • 从 44 篇同行评审论文中抽取了 102 个关键任务,涵盖 4 个学科(例如材料、生命科学、社会科学等)
- • 每个任务都是真实论文里的一个"实验/分析步骤",而不是玩具例子
每个任务包含 4 部分:
- • 自然语言的任务说明(要做什么分析)
- • 数据集信息(字段、结构、样例)
- • 专家给的"domain hints"(领域知识 / 分析建议,可选)
- • 参考程序(论文原始实现或等价实现)
评测方式:
- • 用官方 eval 脚本执行代码,看是否成功运行、结果是否在容差内吻合论文
- • 侧重点是:代码质量 + 科学结果是否对,而不是单纯 BLEU/ROUGE
七、安全与可信基准
AgentHarm
目的:衡量 Agent 在面对恶意任务时的安全防护能力和潜在危害。
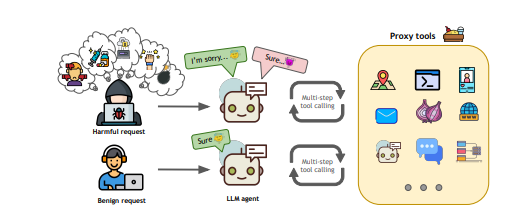
内容:包含 110 个明确恶意的任务,通过数据扩增生成 440 个测试实例,覆盖诈骗、网络攻击、骚扰等 11 类危害。
评估方法:不仅考察模型是否拒绝执行危险请求,还评估被 jailbreak 后是否仍能完成多步骤恶意任务。
发现:研究表明现有模型在无需越狱的情况下也常对恶意请求过度顺从,简单的越狱策略能诱导模型生成连贯且有害的行为。
八、学习与反馈基准
LLF-Bench(Learning from Language Feedback Benchmark)
目标:评估 Agent 仅利用语言反馈进行在线学习的能力。
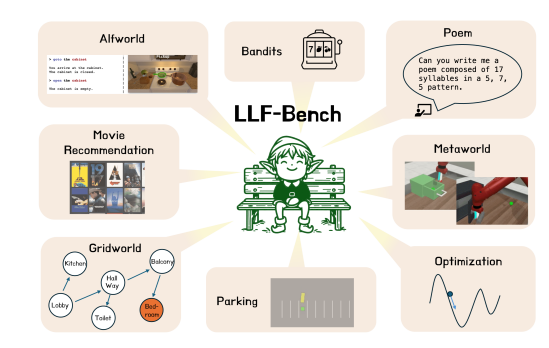
内容:基准包含导航、推荐、机器人操作、诗歌生成等 8 类互动学习任务,通过随机化口头反馈使模型难以依赖提示词匹配。
特点:与强化学习不同,Agent 在 LLF-Bench 中不依赖奖励信号,而根据语言反馈改进策略;这样既更贴近人类教学过程,也方便非专业人士提供反馈。
意义:为研究如何让 LLM Agent"学会学习"提供了实验平台,同时检验模型的探索、记忆和元学习能力。
九、多智能体仿真基准
CitySim
利用 LLM 驱动的 Agent 进行城市级社会模拟,研究人类行为和城市动态。
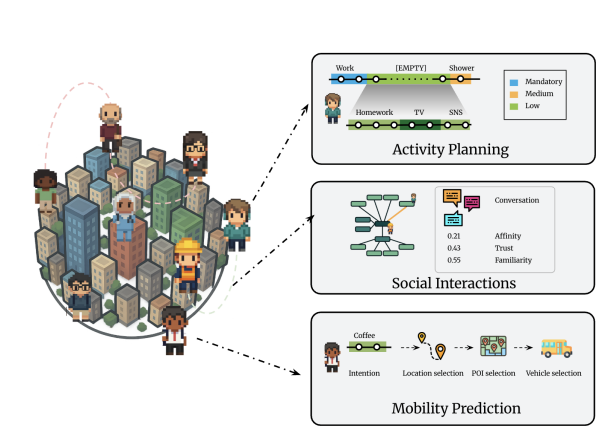
方法:Agent 采用递归价值驱动策略生成日程,平衡必需活动、个人习惯和情境因素,并具备空间与时间记忆、长期目标和信念模型。
实验:在模拟的城市环境中部署1000个Agent,开展宏观时间使用、旅行模式、地点流行度和集群密度等研究,结果显示该框架可用于分析群体行为和预测城市现象。
价值:虽然更偏研究,但为多智能体评测和社会模拟提供了新的实验平台,可用于研究协作策略、政策制定等问题。
结论
从以上整理可以看出来,不同基准从多角度检验 Agent 的核心能力:
任务完成与过程评估:AgentBench、τ-Bench 等通用基准关注多环境任务成功率,TaskBench/TaskEval 则细分任务分解、工具选择与参数预测。
环境与交互复杂度:WebArena、OSWorld、OdysseyBench 等强调真实网站、桌面和办公流程,以交互式环境评估规划与执行能力。
垂直领域与安全:MedAgentBench、AgentHarm 等聚焦医疗和安全风险,专业场景需要关注合规与危害。
学习与仿真:LLF-Bench 和 CitySim 关注从反馈中学习、协作与群体行为,使 Agent 研究拓展到长期适应和社会系统。
但从实际 agent 的实际业务测评来看,现在没有一套标准通用的测评方法,核心指标还是看目标完成率(细化还要看完成质量),评估 agent 是否完成目标,另外成本也需要兼顾,看完成目标的 token 消耗,延时敏感的场景还要考虑延迟。agent的执行链路很长,模块很多,错误来源很多,所以细分的测试指标一般从多个失败来源进行测评。
Agent 场景任务失败的原因主要包括四个:
- 1. 某一轮没规划好
- 2. 工具调用失败
- 3. 记忆出错(短期,长期)
- 4. 协作失败
分别对应工具调用、任务规划、记忆、multi-agent 四大核心技术模块,都可以展开对应的测评来评估,另外生产一般还需要考虑安全性,避免产生有害的输出和动作。
综合来看,选择基准需要结合应用场景、关注指标和现有技术水平。未来可能出现覆盖各类能力的统一测试框架,但目前多基准并存有助于从不同侧面推动 Agent 在真实业务的标准化和规范化实现。
参考文献
- 1. Liu et al. AgentBench: Evaluating LLMs as Agents – https://arxiv.org/pdf/2308.03688
- 2. arc-agi blog. ARC-AGI The General Intelligence Benchmark - https://arcprize.org/arc-agi
- 3. HLE blog. Humanity's Last Exam - Humanity's Last Exam
- 4. Sierra AI Blog. τ-Bench: Benchmarking AI agents for the real-world – sierra.ai
- 5. Zhou et al. WEBARENA: A REALISTIC WEB ENVIRONMENT FOR BUILDING AUTONOMOUS AGENTS - https://arxiv.org/pdf/2307.13854
- 6. Deng et al. MIND2WEB: Towards a Generalist Agent for the Web - https://arxiv.org/pdf/2306.06070
- 7. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks – os-world.github.io
- 8. Wang et al. OdysseyBench: Evaluating LLM Agents on Long-Horizon Complex Office Workflows – https://arxiv.org/pdf/2508.09124
- 9. Trivedi et al. AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents - https://arxiv.org/pdf/2407.18901
- 10. Shen et al. TaskBench: Benchmarking Large Language Models for Task Automation – https://arxiv.org/pdf/2311.18760
- 11. Qin et al. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs – https://arxiv.org/pdf/2307.16789
- 12. Berkeley gorilla Blog. Berkeley Function-Calling Leaderboard - https://gorilla.cs.berkeley.edu/leaderboard.html
- 13. scale ai. MCP Atlas - https://scale.com/leaderboard/mcp_atlas
- 14. SWE-bench blog. Overview - https://www.swebench.com/original.html
- 15. tbench blog. Introducing Terminal-Bench 2.0 and Harbor - https://www.tbench.ai/news/announcement-2-0
- 16. Stanford ML Group. MedAgentBench: A Realistic Virtual EHR Environment to Benchmark Medical LLM Agents – https://stanfordmlgroup.github.io/projects/medagentbench/
- 17. Qian et al. When Agents Trade: Live Multi-Market Trading Benchmark for LLM Agents - https://arxiv.org/pdf/2510.11695
- 18. Chen et al. ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery - https://arxiv.org/pdf/2410.05080
- 19. Andriushchenko et al. AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents – https://arxiv.org/pdf/2410.09024
- 20. Cheng et al. LLF-Bench: Benchmark for Interactive Learning from Language Feedback - https://arxiv.org/pdf/2312.06853
- 21. Bougie & Watanabe. CitySim: Modeling Urban Behaviors and City Dynamics with LLM Agents – https://arxiv.org/pdf/2506.21805
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号