【探索实战】Kurator分布式统一监控:从架构设计实践

【探索实战】Kurator分布式统一监控:从架构设计实践

用户11945645
发布于 2025-12-23 09:14:23
发布于 2025-12-23 09:14:23
1. 引言:为什么需要分布式统一监控?
1.1 云原生时代的监控挑战
在云原生(Cloud Native)架构下,企业通常采用多Kubernetes集群(如生产、测试、预发布环境)和微服务架构,但传统的监控方式存在以下问题:
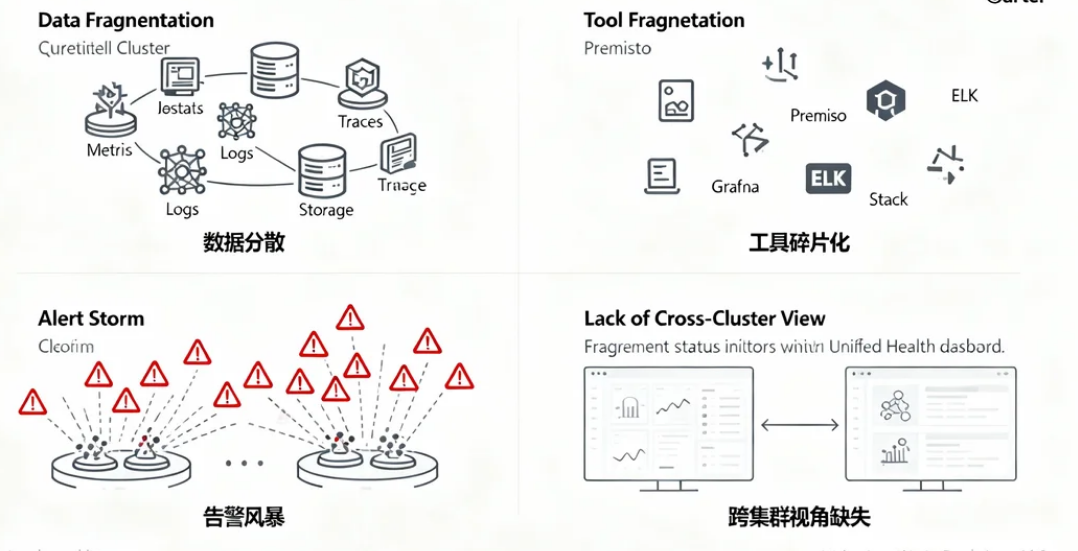
- 数据分散:每个集群、每个服务的监控数据(Metrics、Logs、Traces)独立存储,难以统一分析。
- 工具碎片化:Prometheus、Grafana、ELK等工具各自为政,运维成本高。
- 告警风暴:多集群告警信息分散,难以快速定位根因。
- 跨集群视角缺失:无法从全局视角观察整体系统健康状态。
Kurator 提供了一种分布式统一监控方案,让企业能够:
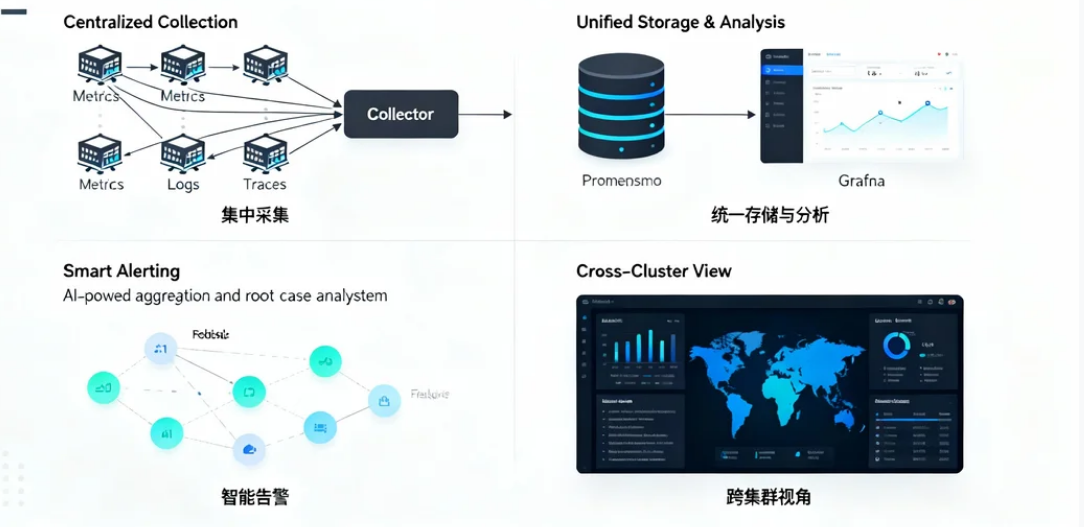
集中采集:统一采集多集群、多服务的Metrics、Logs、Traces数据。 统一存储与分析:通过标准化存储(如时序数据库)和可视化(如Grafana)实现全局监控。 智能告警:基于AI的告警聚合与根因分析,减少误报和漏报。 跨集群视角:从全局视角观察系统健康状态,快速定位问题。
2. Kurator分布式统一监控核心原理
2.1 什么是Kurator统一监控?
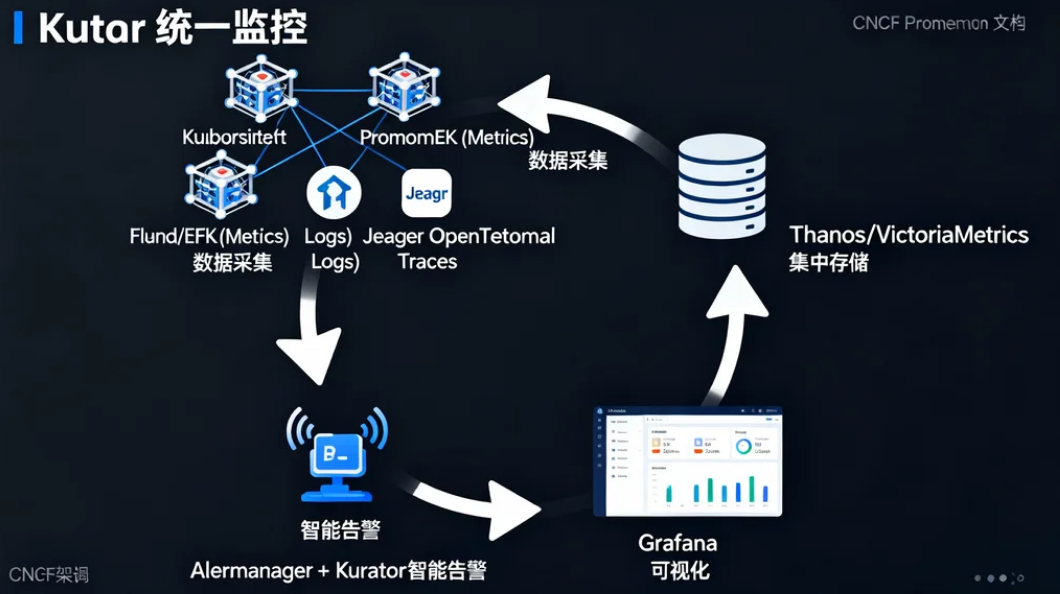
Kurator 的统一监控基于 “数据采集 → 集中存储 → 可视化分析 → 智能告警” 的闭环流程,核心组件包括:
在这里插入图片描述
- Metrics采集(Prometheus/Prometheus Operator)
- Logs采集(Fluentd/EFK)
- Traces采集(Jaeger/OpenTelemetry)
- 集中存储(Thanos/VictoriaMetrics)
- 可视化(Grafana)
- 告警管理(Alertmanager/Kurator智能告警引擎)
2.2 关键技术
技术 | 作用 |
|---|---|
Prometheus | 采集Kubernetes Metrics(CPU、内存、请求延迟等) |
Grafana | 可视化监控数据,支持自定义Dashboard |
Thanos/VictoriaMetrics | 跨集群Metrics存储与查询 |
Fluentd/EFK | 采集应用日志(Logstash/Elasticsearch/Kibana) |
Jaeger/OpenTelemetry | 分布式追踪(Traces) |
Alertmanager | 告警路由与通知(邮件、Slack、钉钉) |
3. 环境搭建:从Kubernetes集群到Kurator监控体系
3.1 环境准备
- 3个Kubernetes集群(生产、测试、预发布)
- Kurator监控控制平面(部署在管理集群)
- Prometheus + Grafana(用于Metrics采集与可视化)
3.2 搭建Kubernetes集群(kubeadm示例)
# 所有节点安装Docker和Kubernetes
yum install -y docker-ce kubelet kubeadm kubectl
systemctl enable --now docker kubelet
# Master节点初始化
kubeadm init --pod-network-cidr=10.244.0.0/16
mkdir -p $HOME/.kube && cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# Worker节点加入集群
kubeadm join <MASTER_IP>:6443 --token <TOKEN>3.3 部署Kurator监控体系
# 部署Prometheus Operator
kubectl apply -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/main/bundle.yaml
# 部署Grafana
kubectl apply -f https://raw.githubusercontent.com/grafana/helm-charts/main/charts/grafana/values.yaml
# 部署Kurator监控控制平面
kubectl apply -f kurator-monitoring.yaml4. Kurator统一监控功能详解
4.1 核心功能
功能 | 说明 |
|---|---|
多集群Metrics采集 | 统一采集所有K8s集群的CPU、内存、请求延迟等数据 |
集中式存储 | 使用Thanos/VictoriaMetrics存储跨集群Metrics |
可视化Dashboard | 通过Grafana展示全局监控视图 |
智能告警 | 基于AI的告警聚合与根因分析 |
日志与追踪 | 集成EFK(日志)和Jaeger(追踪) |
4.2 监控数据流转
- Metrics:Prometheus → Thanos → Grafana
- Logs:Fluentd → Elasticsearch → Kibana
- Traces:Jaeger → 存储 → 可视化
5. 代码实战:从Metrics采集到多集群监控
5.1 部署Prometheus采集K8s Metrics
# prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: k8s-prometheus
spec:
serviceMonitorSelector:
matchLabels:
app: kubernetes
resources:
requests:
memory: 400Mi5.2 部署Grafana Dashboard
# 导入Kubernetes监控Dashboard
kubectl apply -f https://raw.githubusercontent.com/kubernetes-monitoring/kubernetes-mixin/master/dashboards/out/kubernetes-cluster.json5.3 配置跨集群监控
# 使用Thanos Query聚合多个Prometheus数据
kubectl apply -f thanos-query.yaml6. Kurator监控数据流转全流程
6.1 Metrics采集
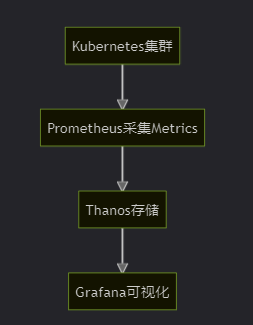
6.2 告警
7.总结
随着云原生技术的持续发展,Kurator的分布式统一监控能力可进一步向以下方向演进:
- AI驱动的预测性运维:通过机器学习模型预测集群资源瓶颈(如提前识别即将耗尽的CPU/内存)、服务故障风险(如基于历史异常模式预测可能的崩溃),实现从“被动响应”到“主动预防”的转变。
- 全栈可观测性深化:加强与应用性能管理(APM)工具(如Datadog、New Relic)的集成,覆盖业务层指标(如订单成功率、支付转化率)与技术层指标(如数据库查询性能、缓存命中率)的关联分析,提供更贴近业务的监控视角。
- 边缘计算场景支持:针对边缘节点(如物联网设备、分支机构服务器)的低带宽、高延迟特性,优化数据采集协议(如使用轻量级的MQTT替代HTTP),并支持边缘侧本地预处理(如过滤无效数据后再上传中心集群),降低网络传输压力。
Kurator分布式统一监控方案通过技术创新与实践沉淀,有效解决了云原生环境下监控数据分散、工具碎片化、告警复杂等行业难题,为企业提供了从“看得见”到“看得清”“管得好”的全栈可观测性能力。其核心价值不仅体现在技术层面的效率提升,更在于通过标准化、智能化的监控体系,支撑业务的快速迭代与稳定运行,是云原生时代企业运维能力升级的关键基础设施。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号