【瑞吉外卖】-day02

【瑞吉外卖】-day02

@VON
发布于 2025-12-21 11:48:26
发布于 2025-12-21 11:48:26

前言
昨天由于事情比较多就没有做,今天主要学习的内容是登录功能的完善和对员工的处理。目前是学习的第二天,因为是第一次做企业级项目有许多不懂的地方,希望大家能够多多包涵,毕竟是小白一个,同时也希望大佬们能够加以指点。
登录功能的完善
正确输入账号密码
直接输入正确的账号和密码,可以完成跳转功能

直接进入到主页
直接通过主页的url进入
登录的时候会进行拦截。,导致无法直接进入,必须要通过登录页面才能进入。当然如果已经登录过的话可以直接进行访问。

登录失败
登录失败的时候也会进行相应的拦截。

代码及其注释部分
为了更便于大家的理解,在代码的基础上加了许多的注释来进一步帮助大家更好的去理解代码。
package com.von.ruiji_take_out.filter;
import com.alibaba.fastjson.JSON;
import com.von.ruiji_take_out.common.R;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.AntPathMatcher;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@WebFilter(filterName = "loginCheckFilter",urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter {
/**
* 执行过滤操作的方法
* 该方法拦截客户端请求,并在请求处理前或后执行特定逻辑
* 主要用于日志记录请求信息,然后将请求传递给过滤链中的下一个过滤器或目标资源
*
* @param servletRequest Servlet请求对象,用于获取请求信息
* @param servletResponse Servlet响应对象,用于向客户端发送响应
* @param filterChain 过滤链对象,用于将请求传递给下一个过滤器或目标资源
* @throws IOException 如果在过滤过程中发生I/O错误
* @throws ServletException 如果在过滤过程中发生Servlet异常
*/
// 路径匹配器,支持通配符
public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher();
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
// 将ServletRequest和ServletResponse转换为HttpServletRequest和HttpServletResponse
// 以便获取更多HTTP协议相关的操作和信息
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
// 1.获取本次请求的URI
String requestURI = request.getRequestURI();
log.info("拦截到请求:{}",requestURI);
// 定义不需要处理的请求路径
String[] urls = new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/front/**"
};
// 2.判断本次请求是否需要处理
boolean check = check(urls,requestURI);
// 3.如果不需要处理则直接放行
if(check){
log.info("本次请求{}不需要处理",requestURI);
filterChain.doFilter(request,response);
return;
}
// 4.判断登录状态,如果已经登录则直接放行
if(request.getSession().getAttribute("employee") != null){
log.info("用户已登录,用户id为:{}",request.getSession().getAttribute("employee"));
filterChain.doFilter(request,response);
return;
}
log.info("用户未登录");
// 5.如果未登录则返回未登录结果,通过输出流方式向客户端页面响应数据
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
return;
}
/**
* 判断本次请求是否需要处理
*
* @param urls 需要检查的URL模式数组
* @param requestURI 请求的URI
* @return 如果请求需要处理则返回true,否则返回false
*/
public boolean check(String[] urls,String requestURI){
// 遍历URL模式数组
for (String url : urls) {
// 使用PATH_MATCHER匹配URL模式和请求URI
boolean match = PATH_MATCHER.match(url, requestURI);
// 如果匹配成功,表明本次请求需要处理
if (match){
return true;
}
}
// 如果没有匹配的URL模式,表明本次请求不需要处理
return false;
}
}新增员工
添加新员工
根据前端页面所给出的提示信息进行员工的录入。
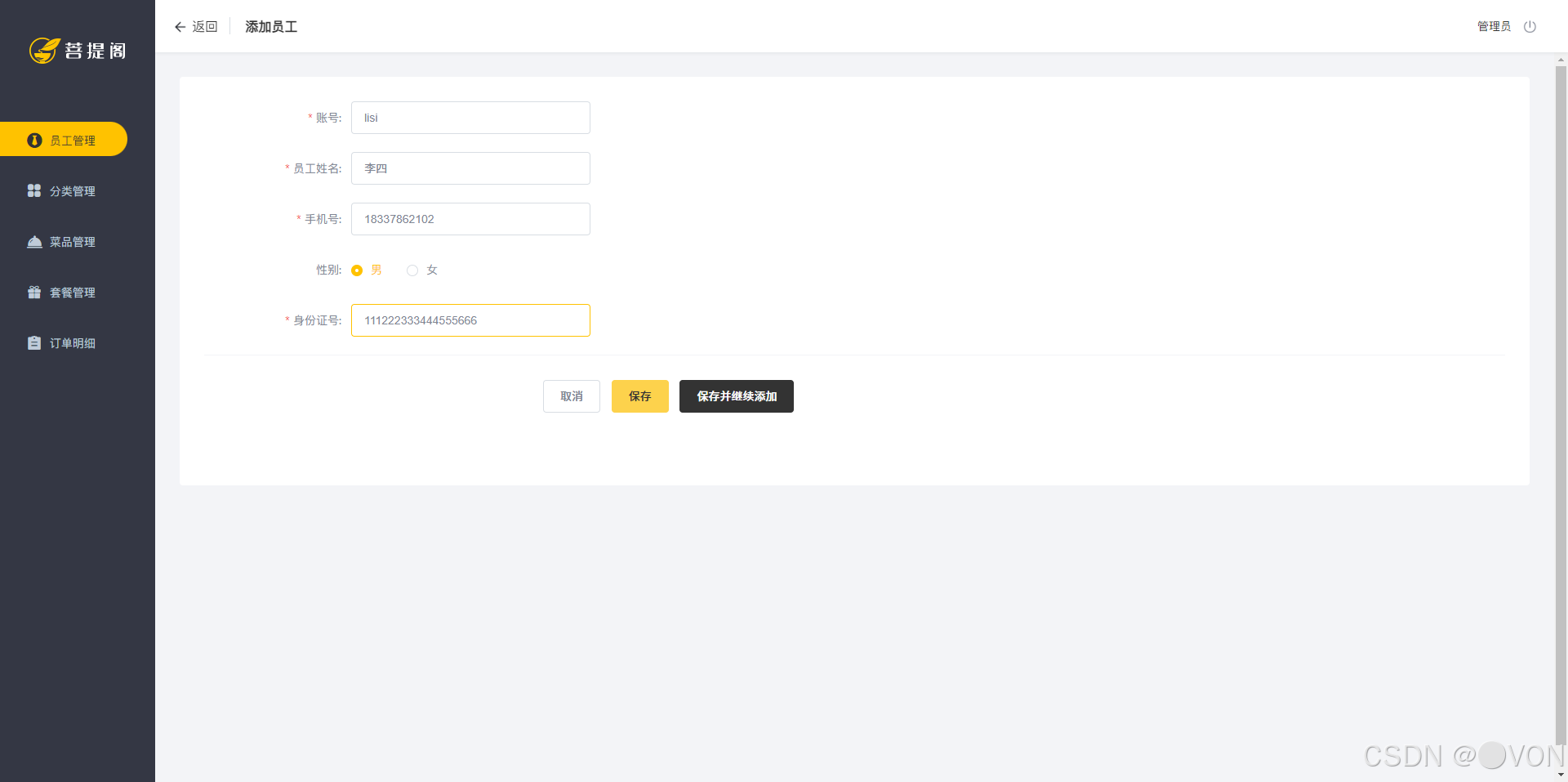
如果成功录入员工信息就会显示如图所示的信息。
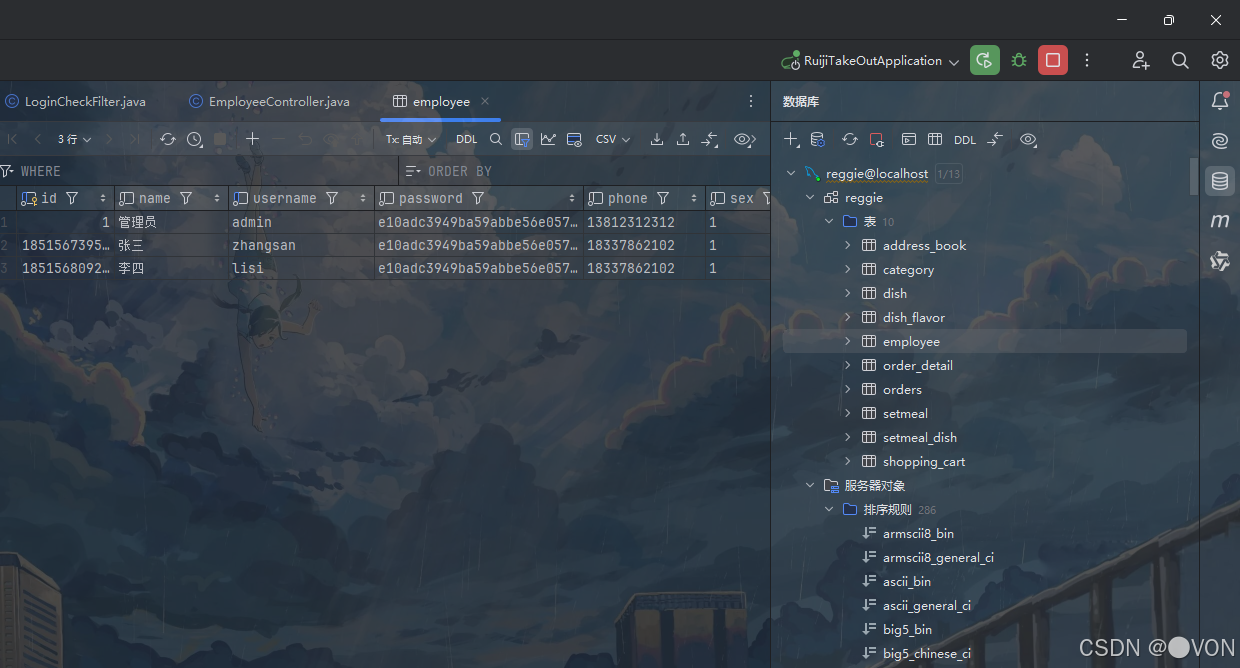
数据库中会对所录入的信息进行存储。
当新增员工时输入的账号已经存在,由于employee表中对该字段加入了唯一约束,因此程序会抛出异常。
新增员工代码及其注释
// 新增员工
@PostMapping
public R<String> save(HttpServletRequest request,@RequestBody Employee employee){
// 打印新增员工的信息
log.info("新增员工,员工信息:{}",employee.toString());
// 设置初始密码123456,需要进行md5加密处理
employee.setPassword(DigestUtils.md5DigestAsHex("123456".getBytes()));
// 设置创建时间和更新时间为当前时间
employee.setCreateTime(LocalDateTime.now());
employee.setUpdateTime(LocalDateTime.now());
// 获取当前登录用户的id
Long empId = (Long) request.getSession().getAttribute("employee");
// 设置更新者和创建者为当前登录用户
employee.setUpdateUser(empId);
employee.setCreateUser(empId);
// 保存员工信息到数据库
employeeService.save(employee);
// 返回成功提示信息
return R.success("新增员工成功");
}异常处理
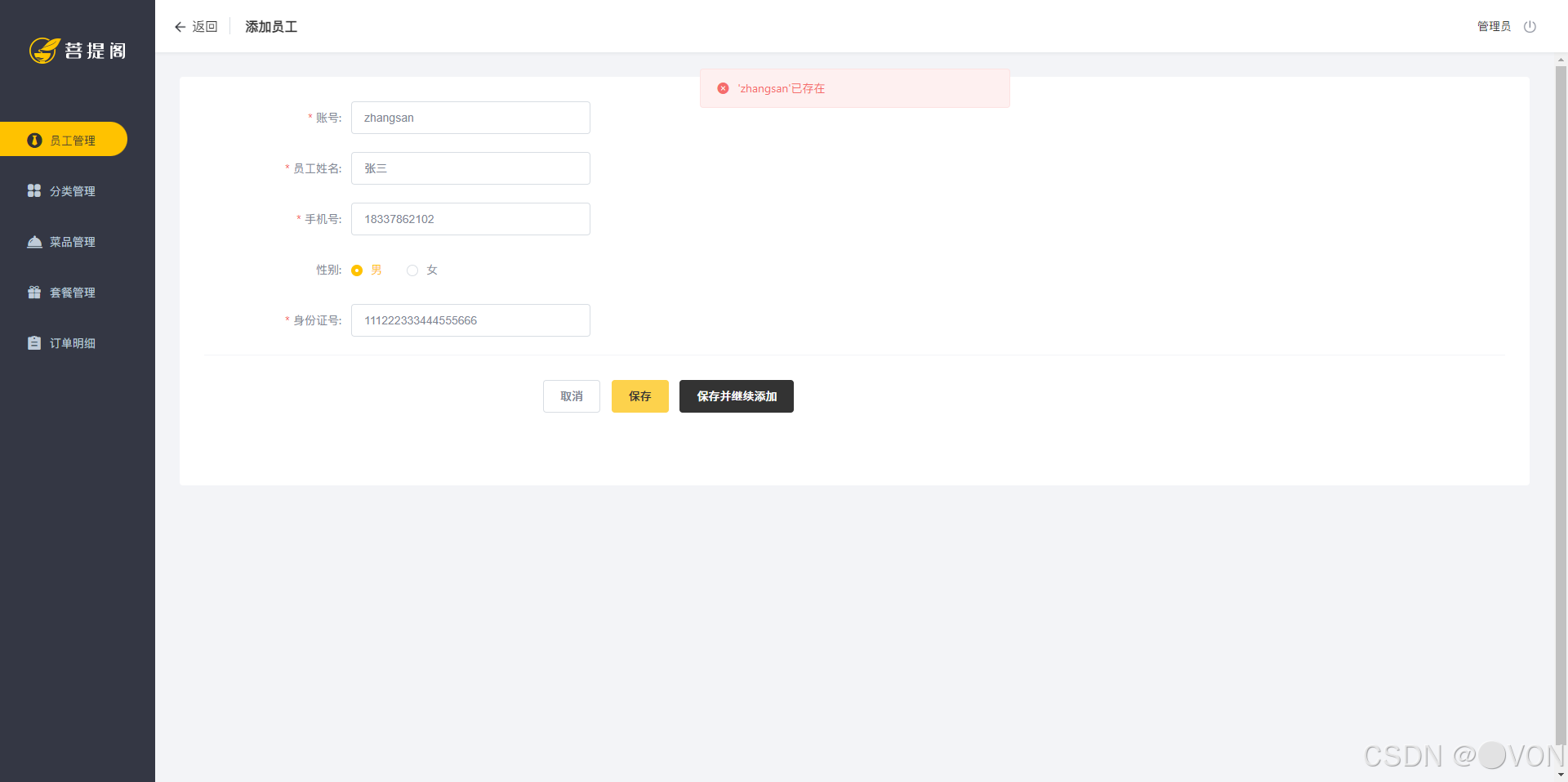
如果账号重复会抛出账号重复的错误。
代码部分及其注释
package com.von.ruiji_take_out.common;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.stereotype.Controller; // 导入正确的注解
import java.sql.SQLIntegrityConstraintViolationException;
/**
* 全局异常处理类,用于统一处理控制器中的异常。
* 该类使用了@ControllerAdvice注解,能够捕获所有被@RestController或@Controller注解的控制器中的异常。
*/
@ControllerAdvice(annotations = {RestController.class, Controller.class})
@ResponseBody
@Slf4j
public class GlobalExceptionHandler {
/**
* 处理SQL完整性约束违反异常(如主键冲突、外键约束等)。
*
* @param ex SQLIntegrityConstraintViolationException 异常对象
* @return R<String> 返回错误信息
*/
@ExceptionHandler(SQLIntegrityConstraintViolationException.class)
public R<String> exceptionHandler(SQLIntegrityConstraintViolationException ex){
log.error(ex.getMessage());
if(ex.getMessage().contains("Duplicate")){
String[] split = ex.getMessage().split(" ");
String msg = split[2] + "已存在";
return R.error(msg);
}
return R.error("未知错误");
}
}员工信息分页查询
根据时间进行排序,在前端页面展示的时候也是根据这一条件进行的排序。

数据库中的updatetime展示
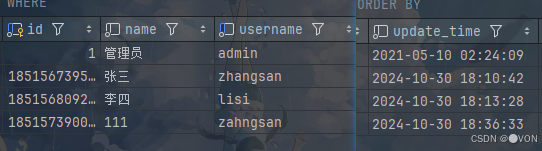
前端页面效果展示
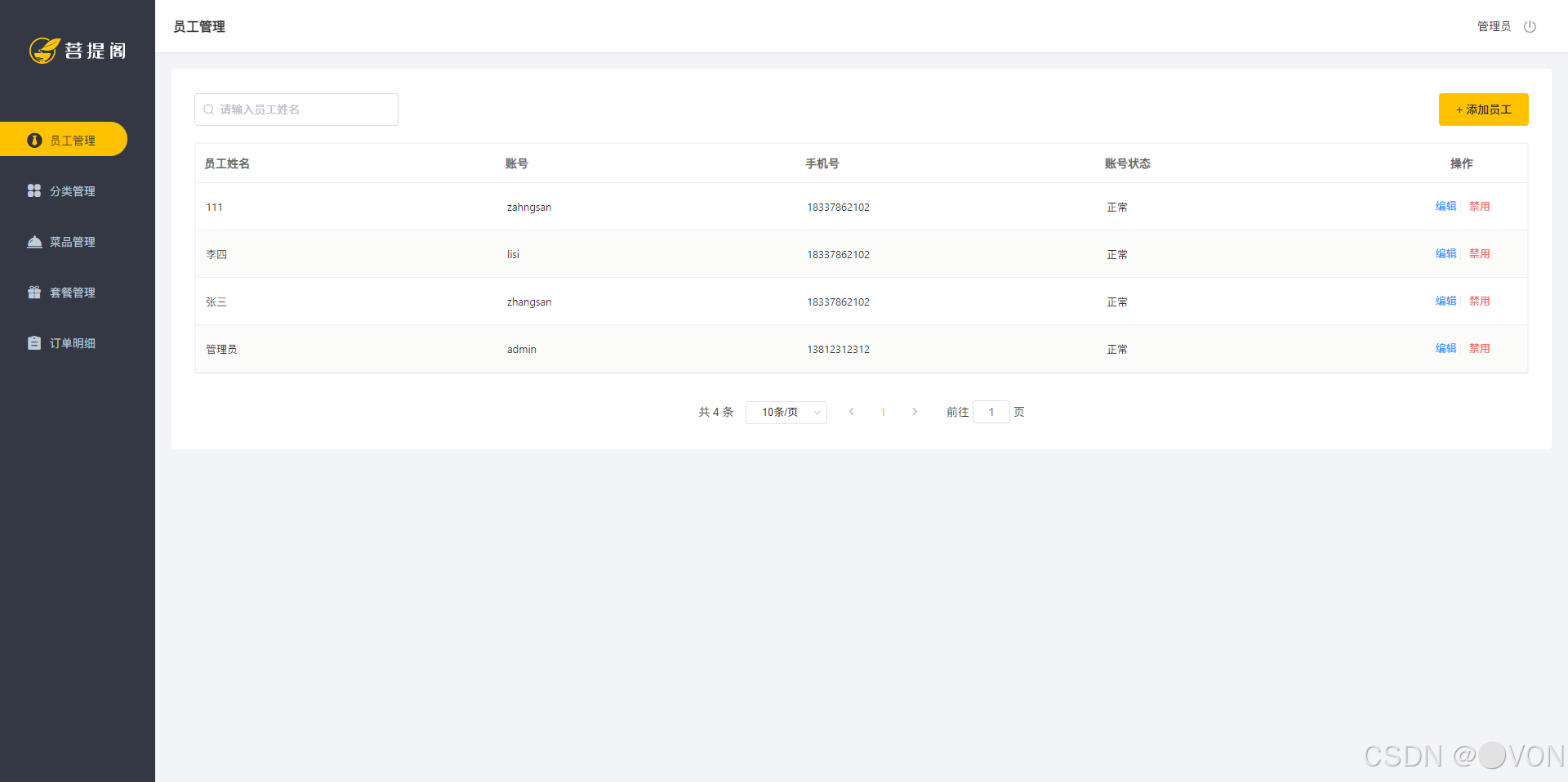
代码部分及其解析
/**
* 根据页码、页面大小和名称查询员工信息
* 此方法用于处理分页查询请求,可以根据员工名称进行模糊搜索,并按照更新时间降序排序
*
* @param page 页码,用于指定查询的页数
* @param pageSize 页面大小,用于指定每页显示的记录数
* @param name 员工名称,用于进行模糊搜索
* @return 返回分页查询结果,包括当前页的员工信息
*/
@GetMapping("/page")
public R<Page> page(int page, int pageSize, String name) {
// 记录日志,输出传入的页码、页面大小和名称参数
log.info("page = {},pageSize = {},name = {}", page, pageSize, name);
// 构造分页构造器,用于设置查询的页码和页面大小
Page pageInfo = new Page(page, pageSize);
// 构造条件构造器,用于设置查询条件和排序
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
// 添加过滤条件,如果名称不为空,则进行模糊搜索
queryWrapper.like(name != null, Employee::getName, name);
// 添加条件排序,按照更新时间降序排序
queryWrapper.orderByDesc(Employee::getUpdateTime);
// 执行查询,使用分页构造器和条件构造器进行分页查询
employeeService.page(pageInfo, queryWrapper);
// 返回查询结果,包括当前页的员工信息
return R.success(pageInfo);
}本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号