四、神经网络的学习(上半部分)


神经网络的学习。这里所说的“学习”是指从训练数据中自动获取最优权重参数的过程。本章中,为了使神经网络能进行学习,将导入损失函数这一指标。而学习的目的就是以该损失函数为基准,找出能使它 的值达到最小的权重参数。为了找出尽可能小的损失函数的值,本章我们将介绍利用了函数斜率的梯度法。
4.1 从数据中学习
4.1.1 数据驱动
神经网络的特征就是可以从数据中学习。所谓“从数据中学习”,是指可以由数据自动决定权重参数的值。这是非常了不起的事情!因为如果所有的参数都需要人工决定的话,工作量就太大了。在介绍的感知机的例子中,我们对照着真值表,人工设定了参数的值,但是那时的参数只有3个。 而在实际的神经网络中,参数的数量成千上万,在层数更深的深度学习中,参数的数量甚至可以上亿,想要人工决定这些参数的值是不可能的。 现在我们来思考一个具体的问题,比如如何实现数字“5”的识别。

image.png
如果让我们自己来设计一个能将5正确分类的程序,就会意外地发现这是一个很难的问题。人可以简单地识别出5,但却很难明确说出是基于何种规律而识别出了5 因此,与其绞尽脑汁,从零开始想出一个可以识别5的算法,不如考虑通过有效利用数据来解决这个问题。一种方案是,先从图像中提取特征量,再用机器学习技术学习这些特征量的模式。这里所说的“特征量”是指可以从输入数据(输入图像)中准确地提取本质数据(重要的数据)的转换器。图像的特征量通常表示为向量的形式。在计算机视觉领域,常用的特征量包括SIFT、SURF和HOG等。使用这些特征量将图像数据转换为向量,然后对转换后的向量使用机器学习中的SVM、KNN等分类器进行学习。 如图4-2所示,神经网络直接学习图像本身。在第2个方法,即利用特征量和机器学习的方法中,特征量仍是由人工设计的,而在神经网络中,连图像中包含的重要特征量也都是由机器来学习的。
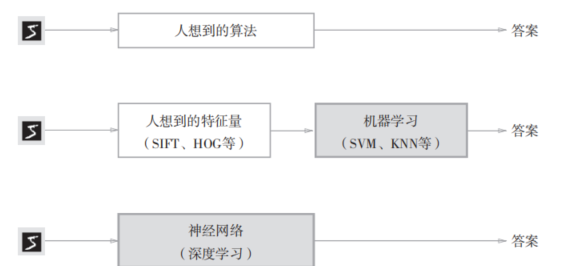
image.png
深 度 学 习 有 时 也 称 为 端 到 端 机 器 学 习(end-to-end machine learning)。这里所说的端到端是指从一端到另一端的意思,也就是从原始数据(输入)中获得目标结果(输出)的意思。
4.1.2 训练数据和测试数据
我们先来介绍一下机器学习中有关数据处理的一些注意事项。 机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和实验等。 首先,使用训练数据进行学习,寻找最优的参数;然后,使用测试数据评价训练得到的模型的实际能力。 为什么需要将数据分为训练数据和测试数据呢? 因为我们追求的是模型的泛化能力。为了正确评价模型的泛化能力,就必须划分训练数据和测试数据。另外,训练数据也可以称为监督数据。 泛化能力是指处理未被观察过的数据(不包含在训练数据中的数据)的能力。获得泛化能力是机器学习的最终目标。比如,在识别手写数字的问题中,泛化能力可能会被用在自动读取明信片的邮政编码的系统上。此时,手写数字识别就必须具备较高的识别“某个人”写的字的能力。注意这里不是“特定的某个人写的特定的文字”,而是“任意一个人写的任意文字”。如果系统只能正确识别已有的训练数据,那有可能是只学习到了训练数据中的个人的习惯写法。 因此,仅仅用一个数据集去学习和评价参数,是无法进行正确评价的。这样会导致可以顺利地处理某个数据集,但无法处理其他数据集的情况。顺便说一下,只对某个数据集过度拟合的状态称为过拟合 避免过拟合也是机器学习的一个重要课题。
4.2 损失函数
神经网络的学习通过某个指标表示现在的状态。然后,以这个指标为基准,寻找最优权重参数。
神经网络的学习中所用的指标称为损失函数(loss function)。这个损失函数可以使用任意函数, 但一般用均方误差和交叉熵误差等。
4.2.1 均方误差
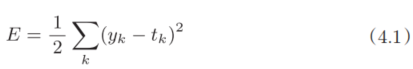
image.png
这里,yk是表示神经网络的输出,tk表示监督数据,k表示数据的维数。 比如,在3.6节手写数字识别的例子中,yk、tk是由如下10个元素构成的数据。

image.png
数组元素的索引从第一个开始依次对应数字“0”“1”“2”…… 这里,神经网络的输出y是softmax函数的输出。由于softmax函数的输出可以理解为概率,因此上例表示“0”的概率是0.1,“1”的概率是0.05,“2”的概率是0.6 等。t是监督数据,将正确解标签设为1,其他均设为0。这里,标签“2”为1, 表示正确解是“2”。将正确解标签表示为1,其他标签表示为0的表示方法称为one-hot表示。 如式(4.1)所示,均方误差会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和。现在,我们用Python来实现这个均方误差,实现方式如下所示。

image.png
现在,我们使用这个函数,来实际地计算一下。

image.png
这里举了两个例子。第一个例子中,正确解是“2”,神经网络的输出的最大值是“2”;第二个例子中,正确解是“2”,神经网络的输出的最大值是“7”。如实验结果所示,我们发现第一个例子的损失函数的值更小,和监督数据之间的误差较小。也就是说,均方误差显示第一个例子的输出结果与监督数据更加吻合。
4.2.2 交叉熵误差
交叉熵误差(cross entropy error)也经常被用作损失函数。交叉熵误差如下式所示。

image.png
这里,log表示以e为底数的自然对数(log e )。yk是神经网络的输出,tk是正确解标签。并且,tk中只有正确解标签的索引为1,其他均为0(one-hot表示)。 因此,式(4.2)实际上只计算对应正确解标签的输出的自然对数。比如,假设正确解标签的索引是“2”,与之对应的神经网络的输出是0.6,则交叉熵误差是−log 0.6 = 0.51;若“2”对应的输出是0.1,则交叉熵误差为−log 0.1 = 2.30。 也就是说,交叉熵误差的值是由正确解标签所对应的输出结果决定的。 自然对数的图像如下图所示:
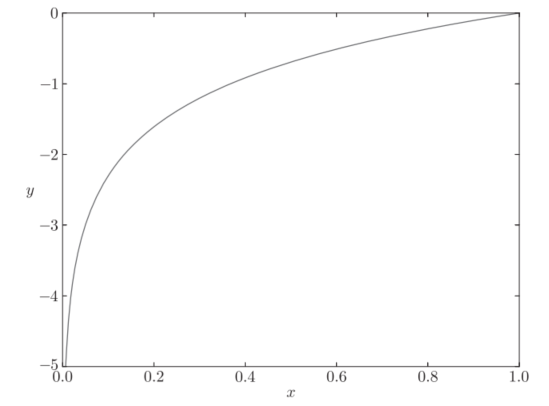
image.png
x等于1时,y为0;随着x向0靠近,y逐渐变小。因此,正确解标签对应的输出越大,式(4.2)的值越接近0;当输出为1时,交叉熵误差为0。此外,如果正确解标签对应的输出较小,则式(4.2)的值较大 下面,我们来用代码实现交叉熵误差。
def cross_entropy_error(y, t):
delta = 1e-7 # 1. 引入一个极小的小量 delta
return -np.sum(t * np.log(y + delta)) # 2. 计算为什么要加上 delta?(这是转换的关键)
- 对数函数 log(x)在 x=0时是未定义的(负无穷,-inf)。在训练过程中,模型的预测输出 y有可能非常接近 0(例如 1e-15甚至 0)。一旦 y等于 0,np.log(0)就会计算为负无穷 (-inf)。
- 即使 y只是一个极小的正数(如 1e-15),np.log(1e-15)也是一个非常大的负数(约 -34.5)。在后续的优化计算中,这样的大数值可能会导致梯度不稳定或计算溢出。
解决方案:通过给 y加上一个非常小的常数 delta(这里取 1e-7),我们确保了 y + delta的值永远大于 0
- np.log(1e-7)是一个有限的、可计算的数值(约 -16.1)。
- 这有效地防止了计算出现 -inf或巨大负值的情况,保证了计算的稳定性和程序的健壮性。

image.png
第一个例子中,正确解标签对应的输出为0.6,此时的交叉熵误差大约为0.51。第二个例子中,正确解标签对应的输出为0.1的低值,此时的交叉熵误差大约为2.3。由此可以看出,这些结果与我们前面讨论的内容是一致的。
4.2.3 mini-batch学习
机器学习使用训练数据进行学习。使用训练数据进行学习,严格来说,就是针对训练数据计算损失函数的值,找出使该值尽可能小的参数。因此,计算损失函数时必须将所有的训练数据作为对象。也就是说,如果训练数据有100个的话,我们就要把这100个损失函数的总和作为学习的指标。 前面介绍的损失函数的例子中考虑的都是针对单个数据的损失函数。如果要求所有训练数据的损失函数的总和,以交叉熵误差为例,可以写成下面的式(4.3)。
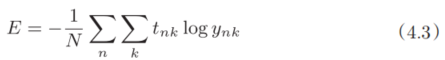
image.png
这里,假设数据有N个,tnk表示第n个数据的第k个元素的值(ynk是神经网络的输出,tnk是监督数据)。式子虽然看起来有一些复杂,其实只是把求单个数据的损失函数的式(4.2)扩大到了N份数据,不过最后还要除以N进行正规化。通过除以N,可以求单个数据的“平均损失函数”。通过这样的平均化,可以获得和训练数据的数量无关的统一指标。比如,即便训练数据有1000个或10000个,也可以求得单个数据的平均损失函数。 另外,MNIST数据集的训练数据有60000个,如果以全部数据为对象求损失函数的和,则计算过程需要花费较长的时间。再者,如果遇到大数据,数据量会有几百万、几千万之多,这种情况下以全部数据为对象计算损失函数是不现实的。因此,我们从全部数据中选出一部分,作为全部数据的“近似”。神经网络的学习也是从训练数据中选出一批数据(称为mini-batch,小批量),然后对每个mini-batch进行学习。比如,从60000个训练数据中随机选择100笔,再用这100笔数据进行学习。这种学习方式称为mini-batch学习。 下面我们来编写从训练数据中随机选择指定个数的数据的代码,以进行mini-batch学习。在这之前,先来看一下用于读入MNIST数据集的代码。
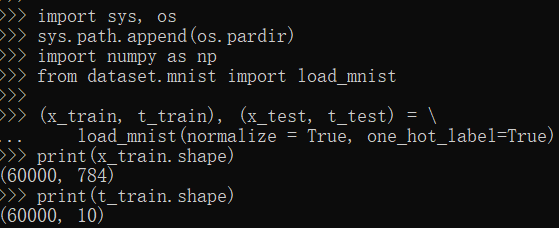
image.png
第3章介绍过,load_mnist函数是用于读入MNIST数据集的函数。这个函数在本书提供的脚本dataset/mnist.py中,它会读入训练数据和测试数据。 读入数据时,通过设定参数one_hot_label=True,可以得到one-hot表示(即仅正确解标签为1,其余为0的数据结构)。 读入上面的MNIST数据后,训练数据有60000个,输入数据是784维(28 × 28)的图像数据,监督数据是10维的数据。因此,上面的x_train、t_train的形状分别是(60000, 784)和(60000, 10)。 那么,如何从这个训练数据中随机抽取10笔数据呢?我们可以使用NumPy的np.random.choice(),写成如下形式。

image.png
使用np.random.choice()可以从指定的数字中随机选择想要的数字。比如,np.random.choice(60000, 10)会从0到59999之间随机选择10个数字。如下面的实际代码所示,我们可以得到一个包含被选数据的索引的数组。

image.png
之后,我们只需指定这些随机选出的索引,取出mini-batch,然后使用这个mini-batch计算损失函数即可。
4.2.4 mini-batch版交叉熵误差的实现
如何实现对应mini-batch的交叉熵误差呢?只要改良一下之前实现的对应单个数据的交叉熵误差就可以了

image.png
- y.ndim == 1:检查输入 y的维度。如果为 1,说明传入的是单个样本的预测值(例如 [0.1, 0.05, 0.6, ..., 0.04])。
- t.reshape(1, t.size)和 y.reshape(1, y.size):为了后续批量计算的统一性,将一维数组重塑(reshape)成二维数组。形状从 (n,)变为 (1, n)。这相当于把单个样本包装成一个批量为 1 的批次。
好处:这样处理之后,无论用户是传入一个样本 [0.1, 0.05, 0.6, ...]还是传入一个批量样本 [[0.1, 0.05, ...], [0.3, 0.1, ...], ...],函数内部的后续代码都无需修改,可以统一处理。
此外,当监督数据是标签形式(非one-hot表示,而是像“2”“7”这样的标签)时,交叉熵误差可通过如下代码实现。

image.png
作为参考,简单介绍一下np.log( y[np.arange(batch_size), t] )。np.arange(batch_size)会生成一个从0到batch_size-1的数组。比如当batch_size为5时,np.arange(batch_size)会生成一个NumPy 数组[0, 1, 2, 3, 4]。因为t中标签是以[2, 7, 0, 9, 4]的形式存储的,所以y[np.arange(batch_size), t]能抽出各个数据的正确解标签对应的神经网络的输出(在这个例子中,y[np.arange(batch_size), t] 会生成 NumPy 数组 [y[0,2], y[1,7], y[2,0], y[3,9], y[4,4]])。
t:就是我们上面提到的标签数组,例如 [2, 7, 0, 9]。这代表了要提取的元素的列号。 y[行索引数组, 列索引数组]: NumPy 会根据提供的行索引和列索引,一对一地从 y中提取元素。 提取 y[0, 2]-> 第一个样本,第 2 类的概率 提取 y[1, 7]-> 第二个样本,第 7 类的概率 提取 y[2, 0]-> 第三个样本,第 0 类的概率 提取 y[3, 9]-> 第四个样本,第 9 类的概率 最终结果:y[np.arange(batch_size), t]返回的是一个一维数组,其内容就是每个样本的真实类别所对应的那个预测概率值。
与 One-Hot 编码版本的对比 假设:t = [2](只有一个样本,标签为 2),y = [0.1, 0.05, 0.6, 0.05, 0.1](5个类别)。

image.png
4.2.5 为何要设定损失函数
对于这一疑问,我们可以根据“导数”在神经网络学习中的作用来回答。下一节中会详细说到,在神经网络的学习中,寻找最优参数(权重和偏置)时,要寻找使损失函数的值尽可能小的参数。为了找到使损失函数的值尽可能小的地方,需要计算参数的导数(确切地讲是梯度),然后以这个导数为指引,逐步更新参数的值。
假设有一个神经网络,现在我们来关注这个神经网络中的某一个权重参数。此时,对该权重参数的损失函数求导,表示的是“如果稍微改变这个权重参数的值,损失函数的值会如何变化”。如果导数的值为负,通过使该权重参数向正方向改变,可以减小损失函数的值;反过来,如果导数的值为正,则通过使该权重参数向负方向改变,可以减小损失函数的值。不过,当导数的值为0时,无论权重参数向哪个方向变化,损失函数的值都不会改变,此时该权重参数的更新会停在此处。
在进行神经网络的学习时,不能将识别精度作为指标。因为如果以 识别精度为指标,则参数的导数在绝大多数地方都会变为0。
假设某个神经网络正确识别出了100笔训练数据中的32笔,此时识别精度为32 %。如果以识别精度为指标,即使稍微改变权重参数的值,识别精度也仍将保持在32 %,不会出现变化。也就是说,仅仅微调参数,是无法改善识别精度的。即便识别精度有所改善,它的值也不会像32.0123 ... %这样连续变化,而是变为33 %、34 %这样的不连续的、离散的值。而如果把损失函数作为指标,则当前损失函数的值可以表示为0.92543 ... 这样的值。并且,如果稍微改变一下参数的值,对应的损失函数也会像0.93432 ... 这样发生连续性的变化。
识别精度对微小的参数变化基本上没有什么反应,即便有反应,它的值也是不连续地、突然地变化。作为激活函数的阶跃函数也有同样的情况。出于相同的原因,如果使用阶跃函数作为激活函数,神经网络的学习将无法进行。
如图4-4所示,阶跃函数的导数在绝大多数地方(除了0以外的地方)均为0。也就是说,如果使用了阶跃函数,那么即便将损失函数作为指标,参数的微小变化也会被阶跃函数抹杀,导致损失函数的值不会产生任何变化。
阶跃函数就像“竹筒敲石”一样,只在某个瞬间产生变化。而sigmoid函数,如图4-4所示,不仅函数的输出(竖轴的值)是连续变化的,曲线的斜率(导数)也是连续变化的。也就是说,sigmoid函数的导数在任何地方都不为0。这对神经网络的学习非常重要。得益于这个斜率不会为0的性质,神经网络的学习得以正确进行。
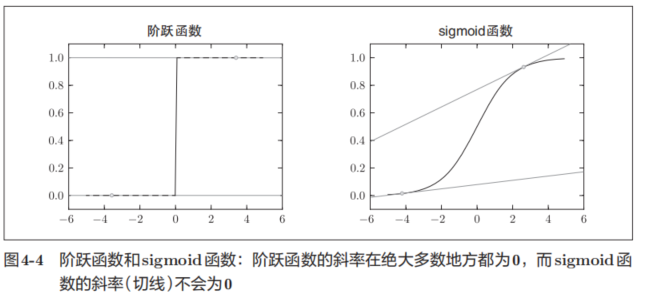
image.png
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-09-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号