万字长文带你从0到实战,全面吃透八大排序算法

万字长文带你从0到实战,全面吃透八大排序算法

Vect_
发布于 2025-12-18 17:49:58
发布于 2025-12-18 17:49:58
1. 排序的稳定性
排序算法(sorting algorithm)用于对一组数据按照特定顺序进行排列。排序算法有着广泛的应用,因为有序数据通常能够被更高效地查找、分析和处理。
以下是常见的八种经典排序算法:
- 冒泡排序
- 选择排序
- 插入排序
- 希尔排序
- 快速排序
- 归并排序
- 堆排序
- 基数排序
而在掌握这些算法之前,我们需要明确排序稳定性的概念
排序的稳定性指的是在排序算法中,如果两个元素的键值相等,排序后它们的相对顺序是否会保持不变
- 如果排序算法是稳定的,那么在排序之前和之后,相同值元素的相对顺序是不变的
- 如果排序算法是不稳定的,那么在排序后相同值的元素相对顺序可能会发生变化
假设有一组待排序的对象,每个对象有两个属性:编号和值 ,按照升序排列值
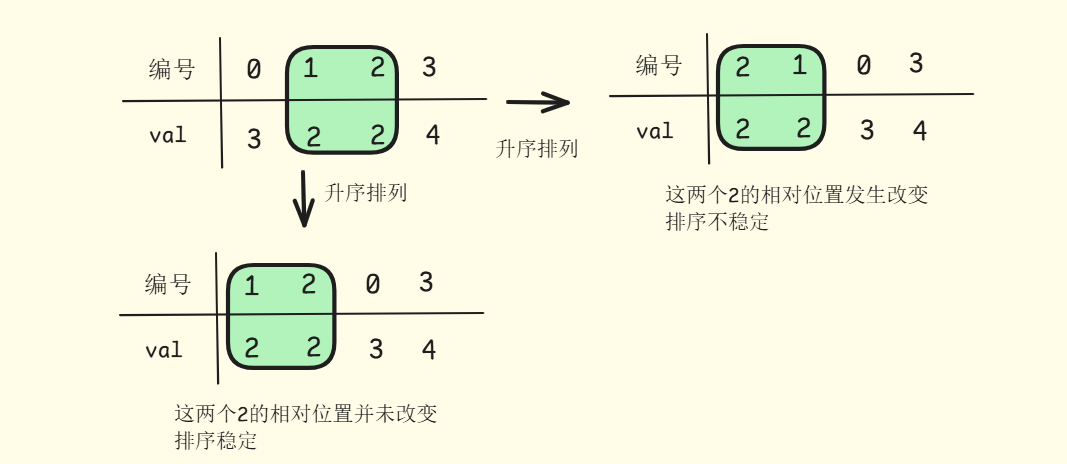
在这里插入图片描述
如上述图片所展示,这便是排序的稳定性
排序的稳定性在某些情况下非常重要,特别是在需要多次排序的情况下。例如,当我们需要先按照某个属性排序,再按照另一个属性排序时,稳定性可以确保第一次排序的结果不会被第二次排序打乱。
在选择排序算法时,了解排序的稳定性有助于根据具体需求选择合适的算法。如果稳定性很重要,应该选择稳定的排序算法;如果稳定性不重要,可以选择更高效但不稳定的排序算法。
2. 冒泡排序
冒泡排序(Bubble Sort)是一种简单且直观的排序算法。通过重复遍历需要排序的列表,依次比较两个相邻的元素并交换它们的位置来排序。以下是具体步骤:
- 从列表第一个元素开始,依次比较相邻的两个元素
- 如果前一个元素比后一个元素大,交换二者位置
- 继续向后比较,直到列表的末尾。这时,最大的元素就像泡泡一样,被放到了末尾
- 重新从列表的第一个元素开始,重复步骤1-2-3,但不处理已经排好序的元素
- 重复步骤1-2-3-4,直到没有需要交换的元素,排序完成
具体过程如图所示:
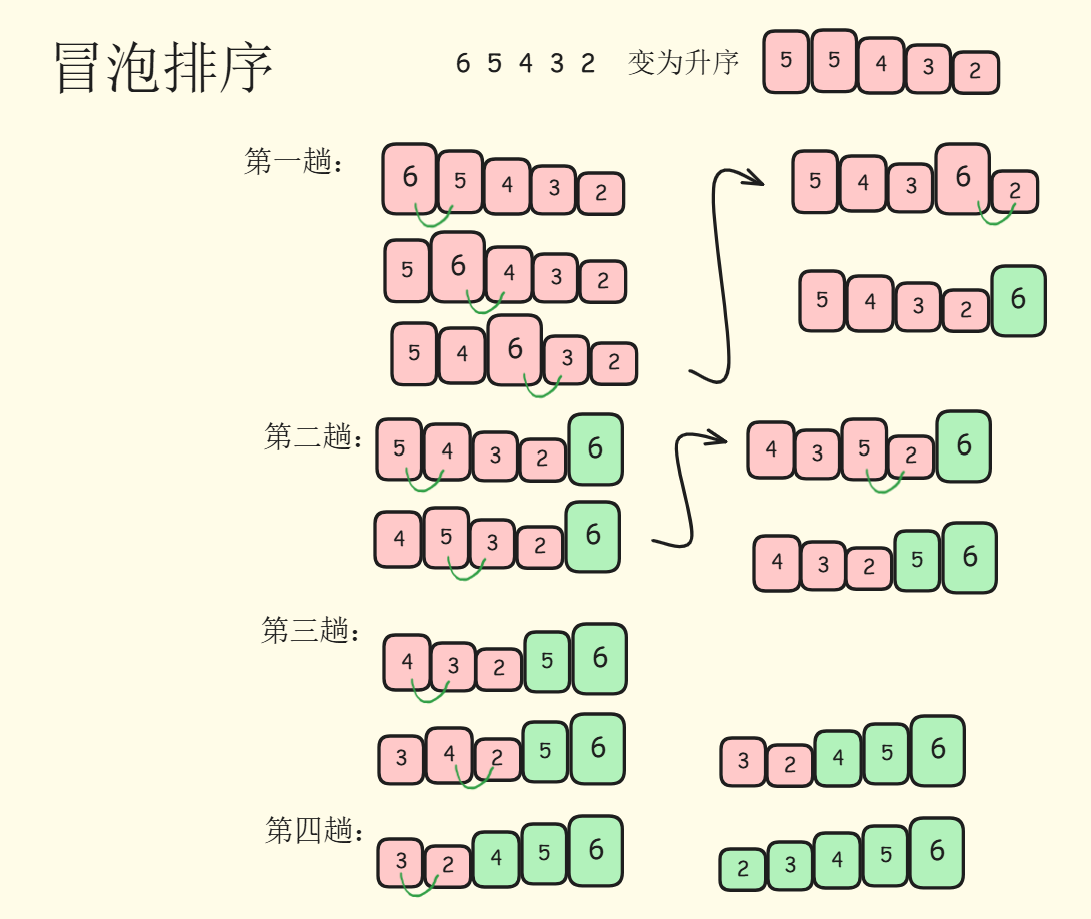
在这里插入图片描述
代码实现:
// 1. 冒泡排序
void BubbleSort(vector<int>& data) {
size_t size = data.size();
bool swapped = false;
// 外层循环 size - 趟
for (size_t i = 0; i < size - 1; i++)
{
// 如果不交换 说明有序了 不用比较 直接break
swapped = false;
// 内层循环 相邻元素比较
// 排好序的元素就不必继续比较 比较次数 = size - 1 - i
for (size_t j = 0; j < size - 1 - i; j++)
{
if (data[j] > data[j + 1]) {
swapped = true;
swap(data[j], data[j + 1]);
}
}
if (swapped == false) break;
}
}冒泡排序是一种稳定的排序算法,相等的元素在排序后不会改变相对顺序:当两个相邻元素相等时,冒泡排序不会交换他们的位置,维持了相对稳定性,如下图:
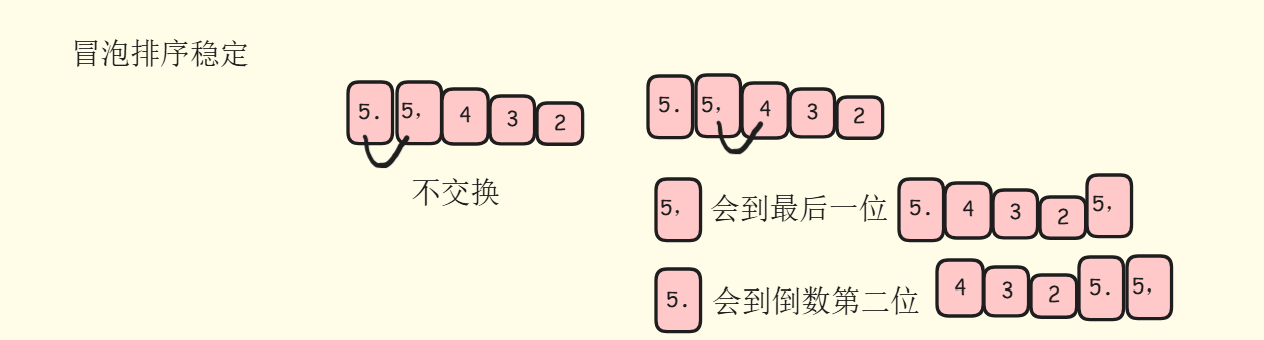
在这里插入图片描述
3. 选择排序
选择排序(Seleciton Sort)的基本思想是每一次从待排序列中选出最小(或最大)的一个元素,存放到起始位置,直到全部待排序的数据都排完。
这个思路可以优化:遍历一次就可以选择出最大值和最小值,分别排在末尾和开头,两个指针往中间同时走,效率会比基础思想高一些,步骤如下:
- 初始状态: 将整个序列分为三块,小值有序区间,无序区间,大值有序区间,初始状态有序区间为空,无序区间是整个序列
- 选择最大值和最小值: 在无序区间找到最大值和最小值
- 安置最大值和最小值: 将最大值排在大值有序区间末尾,将最小值排在小值有序区间开头
- 重复步骤: 重复步骤2、3,直到无序序列为空
具体过程如下:
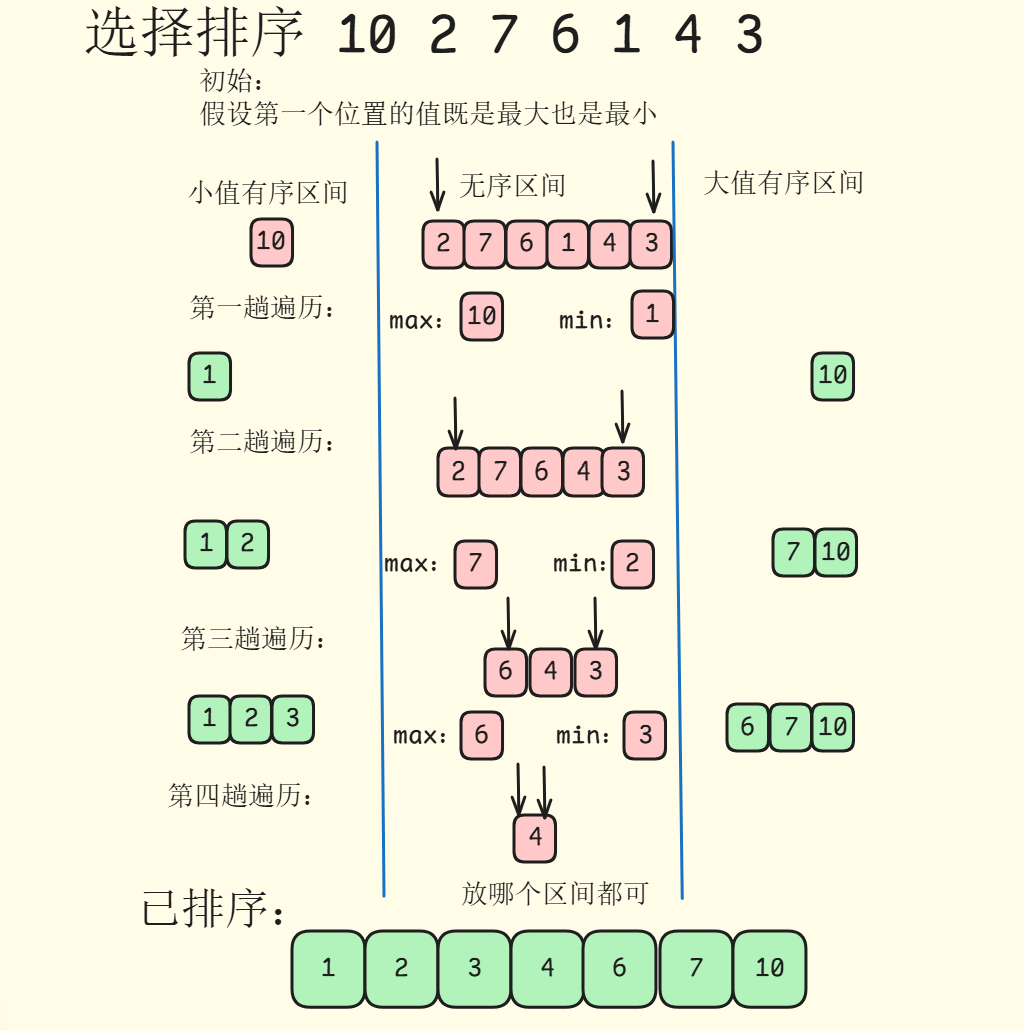
在这里插入图片描述
代码演示:
// 2. 选择排序
void selectSort(vector<int>& data) {
size_t size = data.size();
if (size <= 1) return; // 空数组或单个元素无需排序
size_t left = 0, right = size - 1;
while (left < right) {
// 每次循环初始化最大/最小值索引为当前区间起点left
size_t maxIdx = left, minIdx = left;
// 遍历当前区间[left + 1, right],找到最大和最小值的索引
for (size_t i = left + 1; i <= right; i++)
{
if (data[i] < data[minIdx]) minIdx = i;
if (data[i] > data[maxIdx]) maxIdx = i;
}
// 交换最小值到left位置
swap(data[minIdx], data[left]);
// 如果最大值原本在left位置,交换后已被移到minIdx位置,需更新maxIdx
if (maxIdx == left) {
maxIdx = minIdx;
}
// 交换最大值到right位置
swap(data[maxIdx], data[right]);
// 缩小区间
left++;
right--;
}
}这里尤其需要注意:如果最大值原本在left位置,交换后就被移到minIdx位置,这时候需要更新maxidx
举个例子:
数组 [5,1,2],left=0,right=2
- 找
min=1(索引 1),max=5(索引 0) - 交换
min到left:数组变[1,5,2](此时maxIdx仍为 0,但是对应的值变成了1) - 交换
max到right:用maxIdx=0(值 1)换right=2(值 2)→ 数组[2,5,1]结果错误:最大值 5 没到末尾

在这里插入图片描述
造成这种情况的原因是最大值原本在 left 位置,交换最小值后其位置已变,但 maxIdx 仍指向原 left**,导致后续交换错误值,最大值无法归位。**
选择排序是一种不稳定的排序算法。
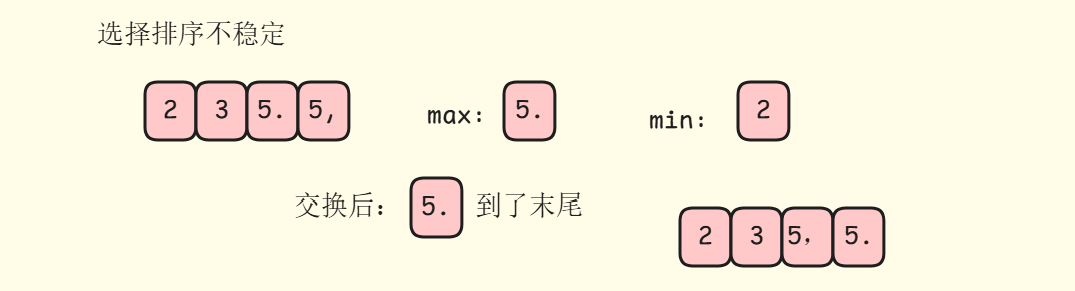
在这里插入图片描述
4. 插入排序
插入排序(Insertion Sort)的基本思想是将未排序部分元素插入到已排序部分的适当位置。插入排序在处理小规模数据效率高,具有稳定性,具体步骤如下:
- 初始化: 从索引为1开始,将其视为待插入元素。默认第一个元素是有序序列
- 遍历无序序列: 从未排序序列第一个元素开始,逐一将元素插入到已排序适当位置
- 插入操作:
- 待插入元素和已排序的部分元素从后向前 进行比较
- 如果已排序的元素大于待插入元素,则将已排序元素右移一位
- 重复比较和移动操作,直到找到一个已排序元素小于等于待插入元素的位置
- 插入待插入元素
- 重复步骤2-3: 直到所有元素都有序
具体过程如下:
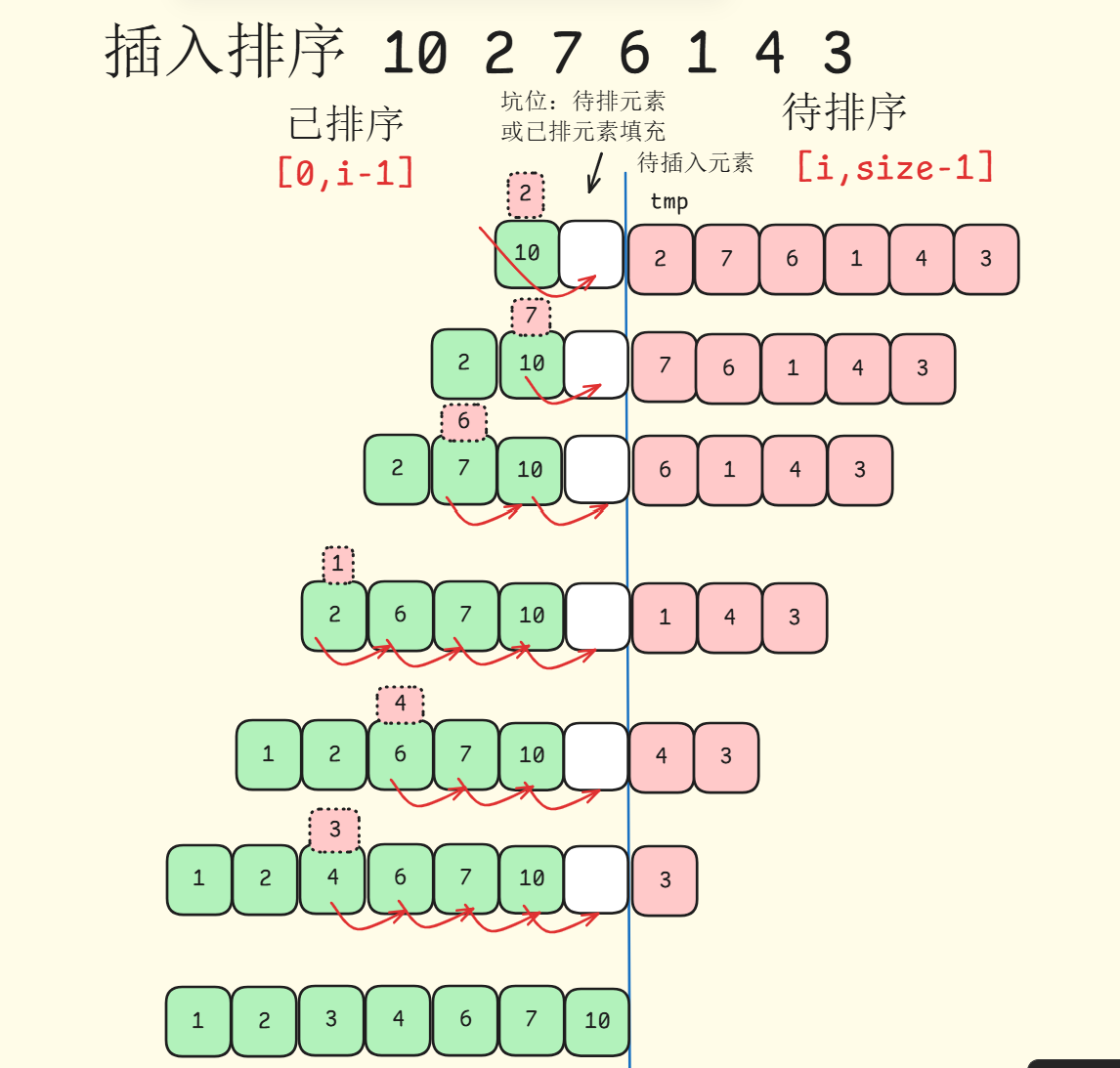
在这里插入图片描述
代码演示:
// 3. 插入排序
void insertSort(vector<int>& data) {
size_t size = data.size();
// 外层 从第二个元素开始 作为待插入元素
for (size_t i = 1; i < size; i++)
{
// 内层 和已排序序列比较 从后往前 把待插入元素放到合适位置
size_t j = i - 1;
int key = data[i];
while (j >= 0 && data[j] > key) {
// 有序序列元素大于key 右移一位
data[j + 1] = data[j];
--j; // 有序序列往前遍历 依次和key比较
}
// 循环结束后,j的位置有两种可能:
// 1. j = -1 → 待插入元素比所有已排序元素都小,应放在索引0
// 2. data[j] <= key → 待插入元素应放在 j 的下一位
data[j + 1] = key;
}
}插入排序是一种稳定的算法,当插入相等的元素时,只需插入到相等元素之后即可,不会改变相对位置
插入排序在处理趋于有序的序列时,效率极高,那有没有什么办法让序列趋于有序呢?希尔排序就做了优化
5. 希尔排序
希尔排序(Shell Sort)是插入排序的优化版本,提高插入排序在处理大规模数据的效率。通过将数据分割成多个子序列分别进行插入排序,逐步减少子序列的间隔,最终在整个序列上进行插入排序,减少了数据移动的次数,提高排序效率,具体步骤如下:
- 选择初始**
gap**: 设置一个gap,常见选择是数组长度的一版,然后逐步减半,直到gap == 1 - 对**
gap**进行排序:- 分组: 将数组分成多个子序列,子序列中的元素间隔是
gap - 对子序列进行插入排序: 对每个子序列进行插入排序,由于
gap较大,子序列的长度较短,插入排序的效率高
- 分组: 将数组分成多个子序列,子序列中的元素间隔是
- 重复步骤2: 减小
gap,继续对减小后的gap进行排序,直到gap == 1,整个数组就是一个整体,最后进行一次标准的插入排序
具体过程如下:
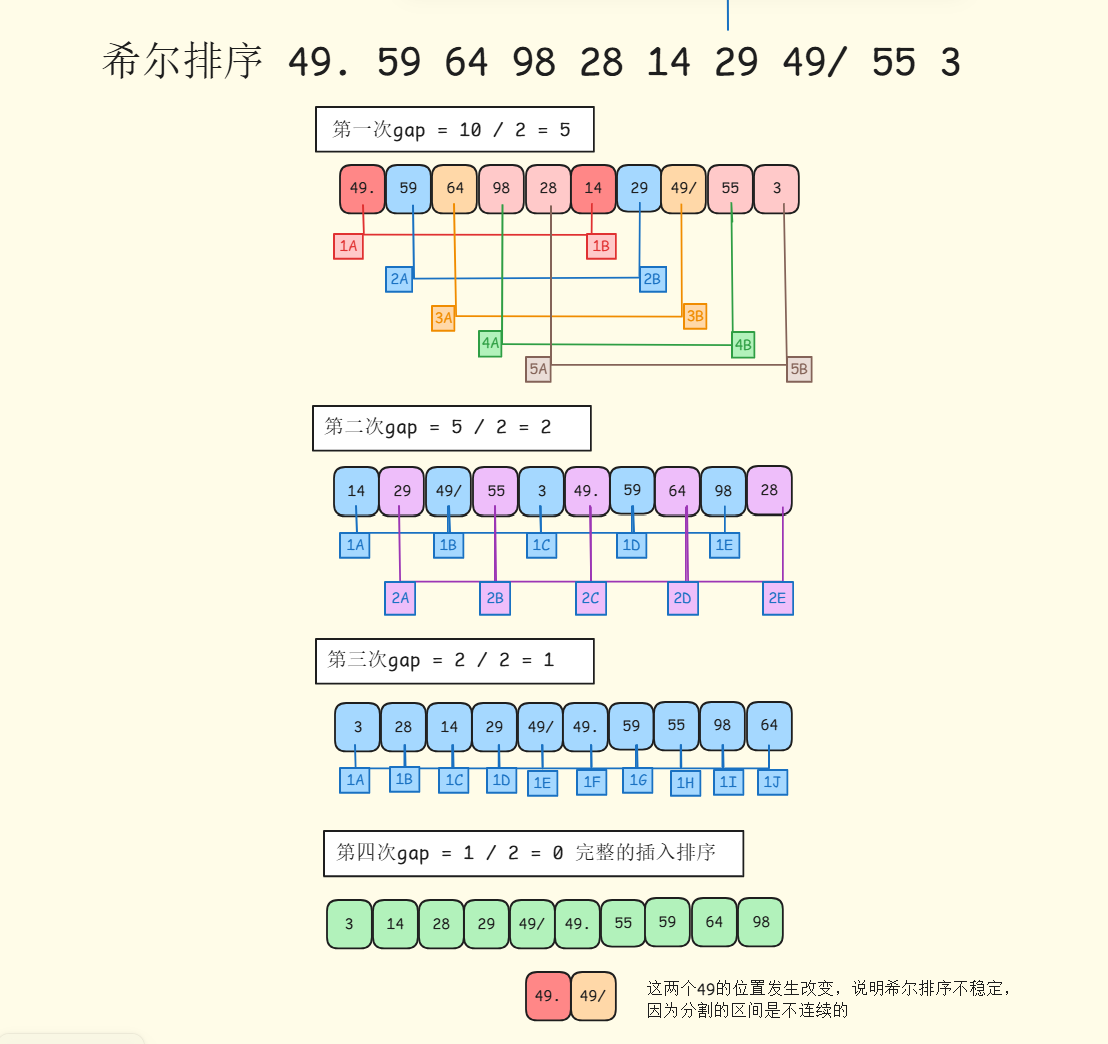
在这里插入图片描述
代码实现:
// 4. 希尔排序
void shellSort(vector<int>& data) {
size_t size = data.size();
// 1.找gap 每次gap/=2 直到gap == 0
int gap = size / 2;
while (gap > 0) {
// 2.分gap组分别插入排序 从每组的gap开始(每组的第二个)
for (int i = gap; i < size; i++)
{
int j = i - gap; // 控制待插入元素
int key = data[i];
while (j >= 0 && data[j] > key) {
data[j + gap] = data[j];
j -= gap;
}
data[j + gap] = key;
}
gap /= 2;
}
}希尔排序是不稳定的算法
6. 快速排序
6.1. Hoare版本
快排是Hoare最早提出的,他的思想我们很有必要学习一下:
- 基准元素选择: 选择数组第一个元素作为基准,记录基准索引keyi`
- 双向指针扫描: 设置两个指针
left和right,left从数组左端begin开始向右扫描,right从右端end开始向左扫描,一定要让右指针先走,这样才能保证较大值右移、较小值左移right指针寻找第一个小于等于基准的元素,找到之后停止不动left指针寻找第一个大于等于基准的元素,找到之后停止不动- 当两指针相遇或交叉时停止扫描
- 元素交换: 当
left < right时,交换arr[left]和arr[right]的值。这个交换操作能使较大值右移、较小值左移 - 分区完成判断: 重复步骤2-3直到
left >= right,此时keyI所指位置即为当前分区的中间点。此时数组被划分为:- 左区间:
[begin,keyi-1] - 右区间:
[keyi+1,end]
- 左区间:
- 递归排序 对左右两个子数组分别递归执行上述过程,直到子数组长度为1时终止递归
注意:本文都是升序排列,如果降序,则让left先走找小,right后走找大
具体过程如下:
- 划分区间:
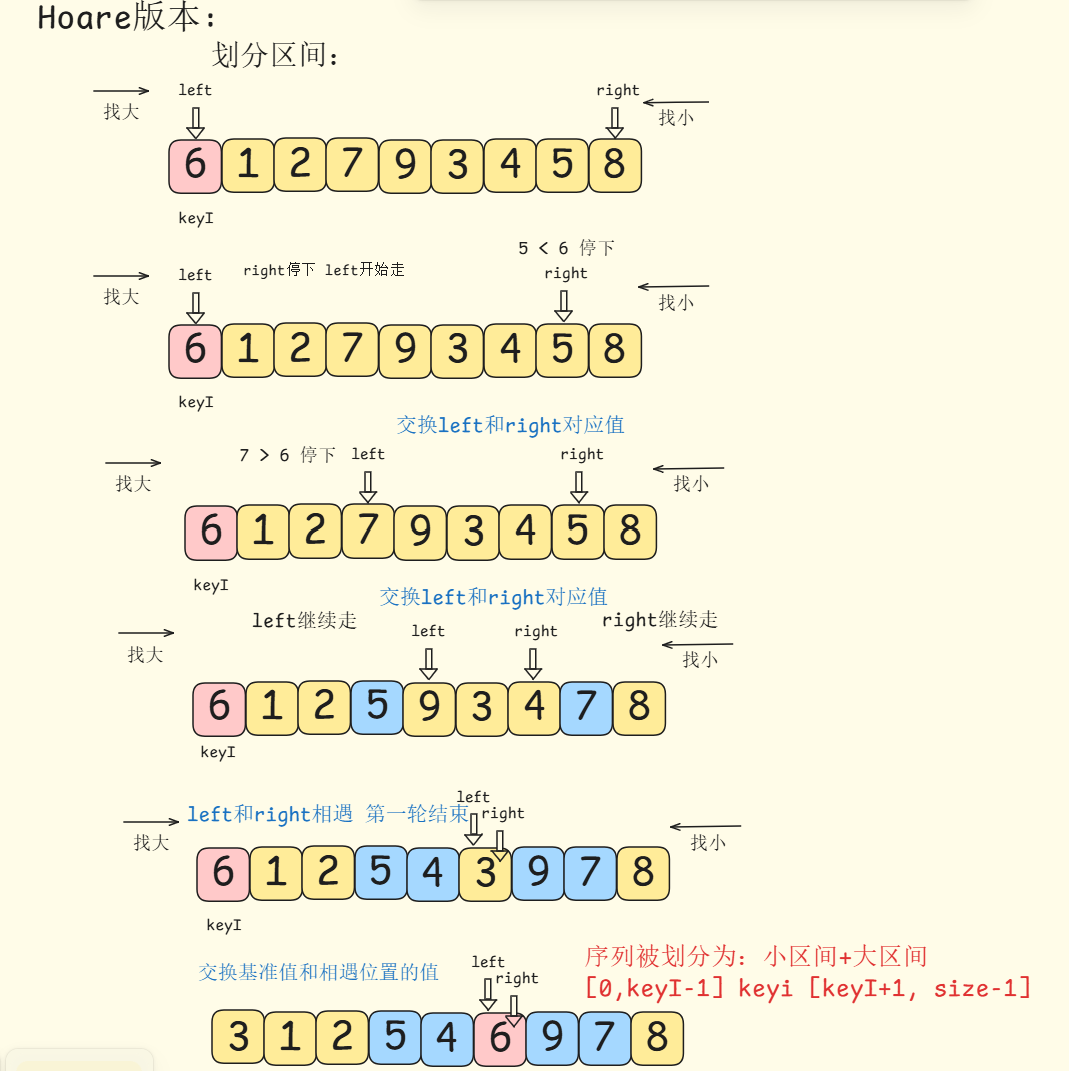
在这里插入图片描述
- 分治:
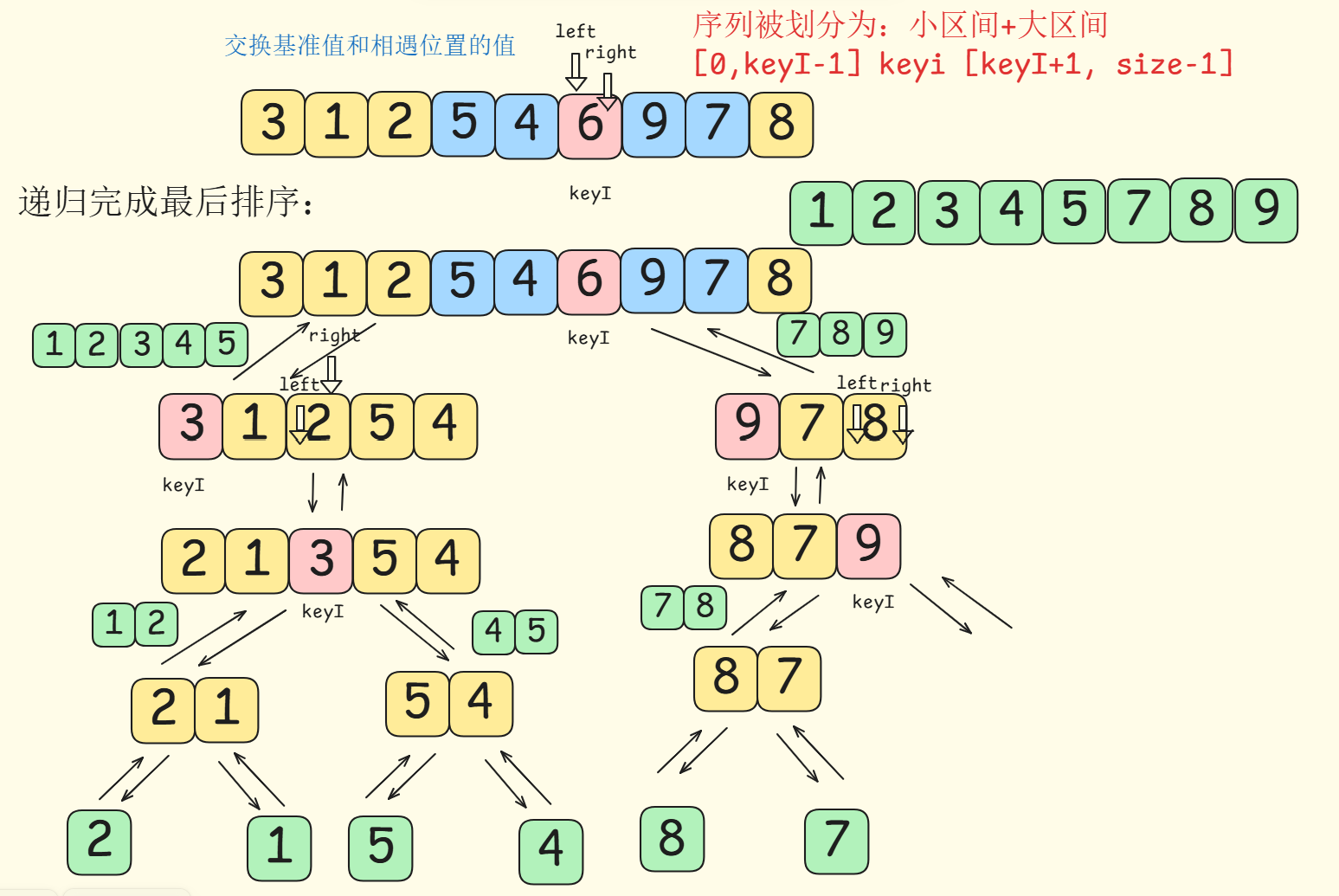
在这里插入图片描述
代码实现:
void quickSortHoare(vector<int>& data,int left, int right) {
if (left >= right) return;
// 1. 划分区间
int begin = left, end = right;
int keyI = left;
while (left < right) {
// right先走 找比基准值小的值
while (left < right && data[keyI] <= data[right]) --right;
// left后走 找比基准值大的值
while (left < right && data[keyI] >= data[left]) ++left;
// 交换left和right索引的值
swap(data[left], data[right]);
}
swap(data[keyI], data[left]);
// 更新基准值索引
keyI = left;
// 2. 分治
// [begin,keyI-1] keyI [keyI+1,end]
quickSortHoare(data, begin, keyI - 1);
quickSortHoare(data,keyI + 1,end);
}
在这里插入图片描述
为什么left和right相遇位置比keyI位置的值小?
是right先走决定的,分析:
left遇到right
right先走,right会在比keyI小的位置停下,left没有找到比keyI位置大的值,就会和right相遇,相遇位置是right停下的位置,当然是比keyI小的位置
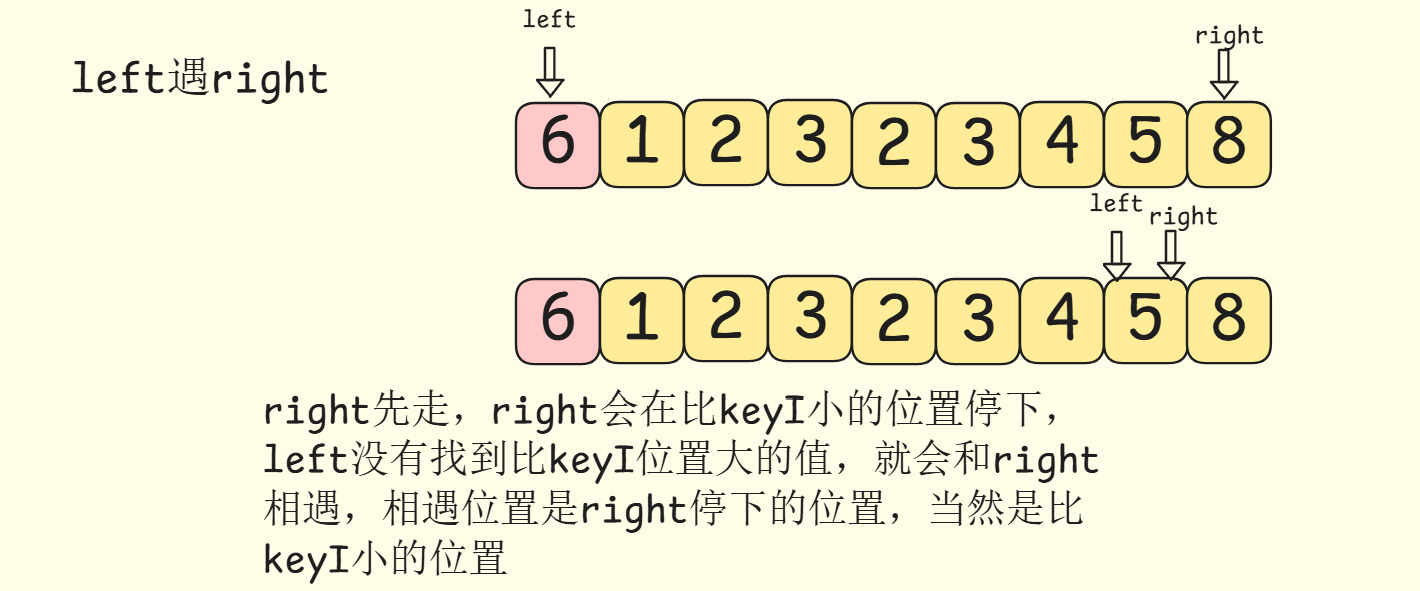
在这里插入图片描述
right遇到left
第一轮结束后,left和right位置的值交换,
此时left位置的值小于keyI位置的值,right位置的值大于keyI位置的值,right继续走,没有找到比keyI位置小的值,直到和left相遇,此时相遇位置
是left所在位置,即比keyI位置的值小
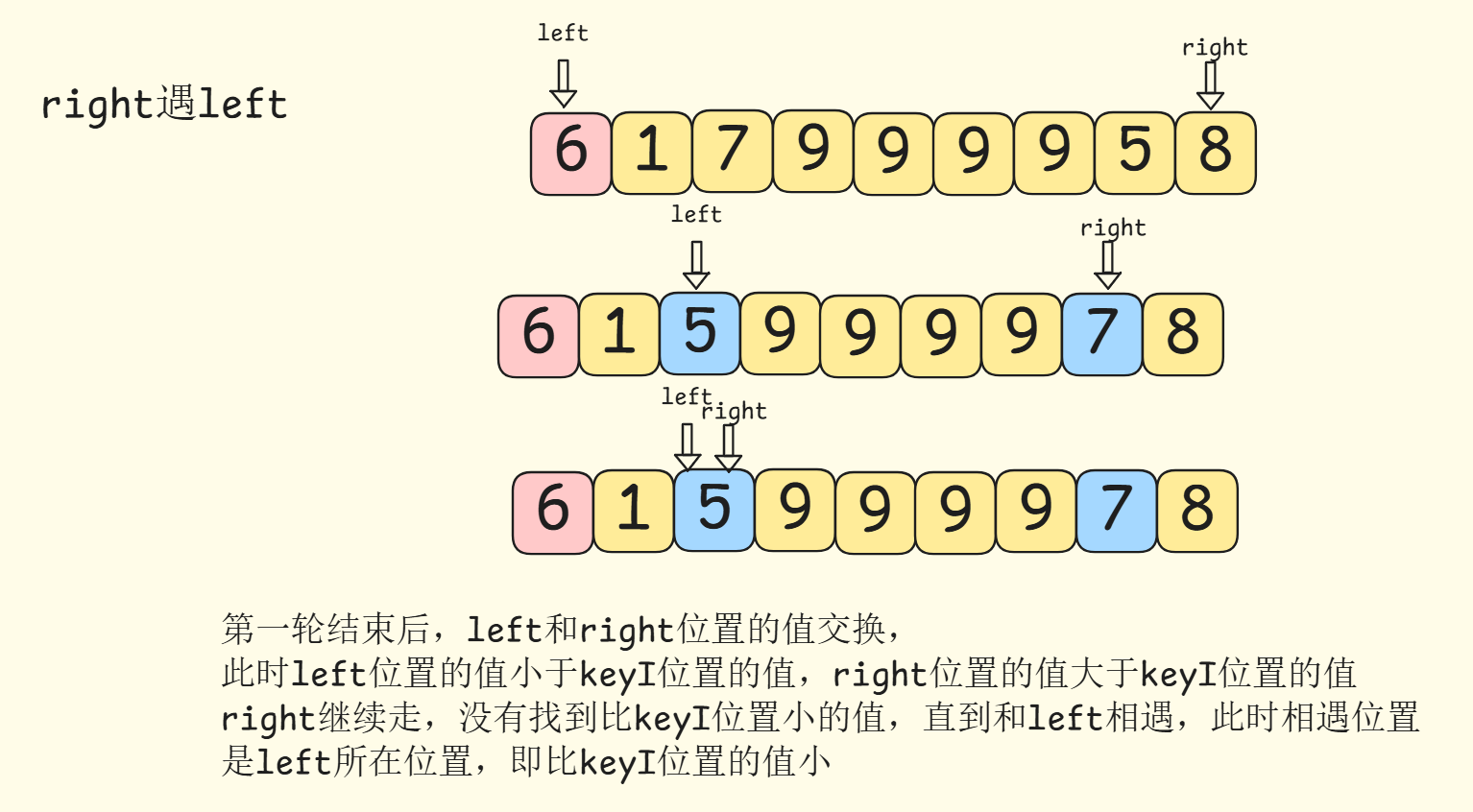
在这里插入图片描述
6.2. 前后指针法
前后指针法的代码很简单,核心思想是通过操控prev和cur两个指针,将小于keyI位置的值前置,将大于keyI位置的值后置,大值夹在两个指针之间被推着走,具体步骤如下:
核心思路:
- 选定最左侧元素为基准值并保存,将
prev设置为left,cur设置为left+1。 cur去寻找当前区间内比基准值小的元素- 如果没找到,说明基准值右侧的元素都是大于基准值的,不需要其他操作,直接跳出循环即可。
- 如果找到了先
prev++,再将prev和cur位置的元素交换,然后cur++。 - 等到
cur越界之后,说明遍历完序列中的所有元素了,将基准值位置的元素和prev位置的元素交换。 - 最后返回
prev即可。
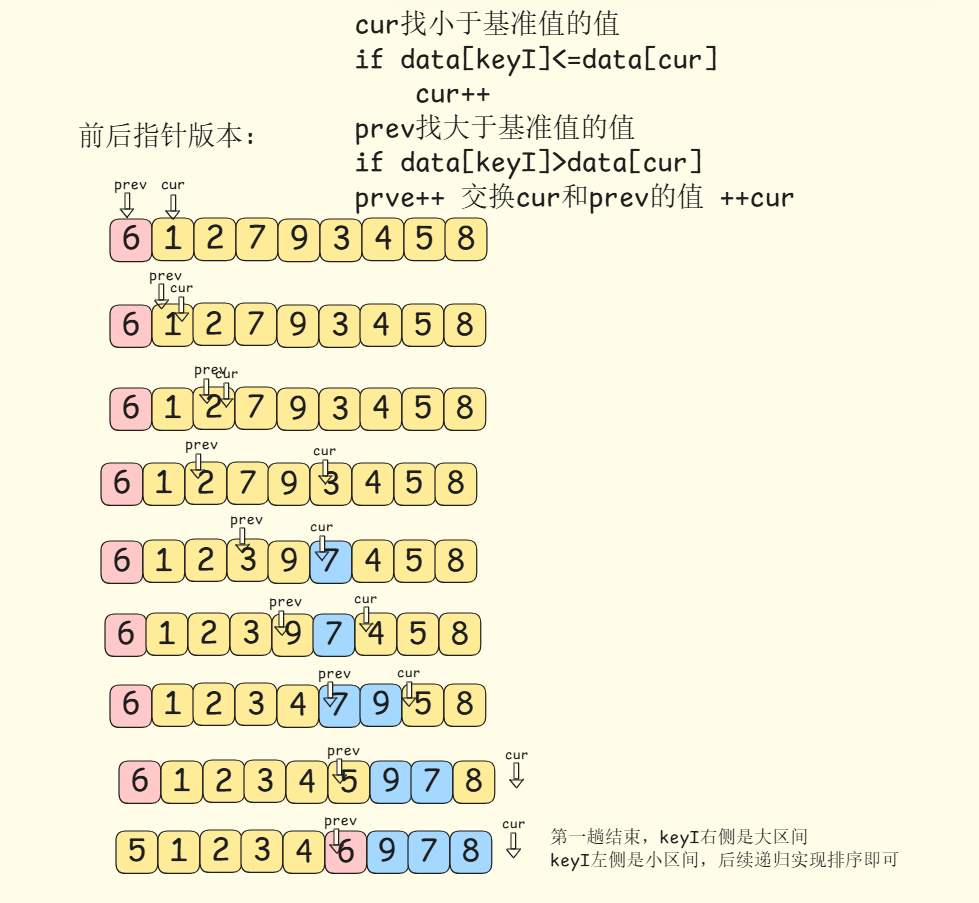
在这里插入图片描述
代码实现:
void quickSortMorden(vector<int>& data, size_t left, size_t right) {
if (left >= right) return;
size_t prev = left;
size_t cur = left + 1;
size_t keyI = left;
while (cur <= right) {
if (data[cur] < data[keyI] && ++prev != cur) {
swap(data[cur], data[prev]);
}
++cur;
}
swap(data[keyI], data[prev]);
keyI = prev;
// 分治
// [left,keyI - 1] keyI [keyI + 1, right]
quickSortMorden(data, left, keyI - 1);
quickSortMorden(data, keyI + 1, right);
}6.3. 三数取中优化
如果遇到有序序列或者是接近有序序列,快排的效率就会接近
,原因是我们每次选择keyi都是区间左值,这样可能选取到极端值(比如最小或最大元素)作为基准,这样会导致分区不平衡。
三数取中,顾名思义:取三个数中第二大的数
代码实现:
// 三数取中
int getMidNum(vector<int>& data, int left, int right) {
int mid = (left + right) / 2;
if (data[mid] < data[right]) {
if (data[mid] > data[left])
return mid;
else if (data[left] > data[right])
return right;
else
return left;
}
else { // data[mid] > data[right]
if (data[right] > data[left])
return right;
else if (data[left] > data[mid])
return mid;
else
return left;
}
}6.4. 快排非递归版本
递归快排本质上依赖系统调用栈管理“待排区间”。非递归版本的思路是:我们自己造一个栈,用来保存未处理的子区间。
核心思想
在快排中,递归函数会自动在系统栈中保存“当前区间 [left, right]” 的信息。
非递归的做法是:
- 手动维护一个栈
stack<pair<int,int>>; - 每次取出一个区间
(left, right); - 对该区间执行分区;
- 再将它的左右子区间入栈;
- 栈空即排序完成。
每个 pair<int,int> 代表一个区间 [left, right]。
压栈出栈全过程
以数组 data = [4, 2, 7, 1] 为例:
- 初始压栈
st: [(0,3)] ← 初始区间- 弹出 (0,3),执行分区
基准值 4 → 经过一轮交换后:
data: [2, 1, 4, 7]
基准位置 pos = 2有效子区间:
- 左:0,1
- 右:3,3
压栈:
st: [(3,3), (0,1)]- 弹出 (0,1)
基准值 2 → 分区后:
data: [1, 2, 4, 7]
pos = 1左:0,0,右:2,1(无效)
压栈:
st: [(3,3), (0,0)]- 弹出 (0,0) → 无需处理
st: [(3,3)]- 弹出 (3,3) → 无需处理
st: []栈空,排序完成!
代码实现
/*===================== 非递归 ===============================*/
// 1. Hoare双指针版非递归快排
void quickSortHoareNonRecursive(vector<int>& data, int left, int right) {
if (left >= right) return;
// 定义栈用于存储待处理的区间
stack<pair<int, int>> st;
// 初始时,将整个数组的区间[left, right]压入栈
st.push({ left, right });
// 循环处理栈中的所有区间,直到栈为空
while (!st.empty()) {
// 从栈顶取出当前要处理的区间
// 注意:这里用first和second获取pair中的左右边界
int curLeft = st.top().first; // 当前区间的左边界(left)
int curRight = st.top().second; // 当前区间的右边界(right)
st.pop(); // 弹出栈顶区间,避免重复处理
// 若当前区间无效(左边界>=右边界),跳过该区间
if (curLeft >= curRight) {
continue;
}
int begin = curLeft;
int end = curRight;
int midI = getMidNum(data, curLeft, curRight);
swap(data[curLeft], data[midI]);
int keyI = curLeft;
// 分区过程
while (curLeft < curRight) {
// right指针左移:找比基准值小的元素
while (curLeft < curRight && data[keyI] <= data[curRight]) {
--curRight;
}
// left指针右移:找比基准值大的元素
while (curLeft < curRight && data[keyI] >= data[curLeft]) {
++curLeft;
}
swap(data[curLeft], data[curRight]);
}
swap(data[keyI], data[curLeft]);
keyI = curLeft;
// 用压栈替代递归调用
// 左子区间[begin, keyI-1]
if (begin < keyI - 1) { // 仅当左区间有效(长度>1)时才压栈
st.push({ begin, keyI - 1 });
}
// 右子区间[keyI+1, end]
if (keyI + 1 < end) { // 仅当右区间有效(长度>1)时才压栈
st.push({ keyI + 1, end });
}
}
}
// 2. 前后指针版非递归快排
void quickSortMordenNonRecursive(vector<int>& data, int left, int right) {
if (left >= right) return;
// 定义栈用于存储待处理的区间
stack<pair<int, int>> st;
// 初始时,将整个数组的区间[left, right]压入栈
st.push({ left, right });
// 循环处理栈中的所有区间,直到栈为空
while (!st.empty()) {
// 从栈顶取出当前要处理的区间
int curLeft = st.top().first; // 当前区间的左边界(left)
int curRight = st.top().second; // 当前区间的右边界(right)
st.pop(); // 弹出栈顶区间,避免重复处理
// 若当前区间无效(左边界>=右边界),跳过该区间
if (curLeft >= curRight) {
continue;
}
int prev = curLeft;
int cur = curLeft + 1;
int midI = getMidNum(data, curLeft, curRight);
swap(data[curLeft], data[midI]);
int keyI = curLeft;
while (cur <= curRight) {
// 若当前元素小于基准值,且前指针后移后不等于后指针,则交换
if (data[cur] < data[keyI] && ++prev != cur) {
swap(data[cur], data[prev]);
}
++cur;
}
swap(data[keyI], data[prev]);
keyI = prev;
// 用压栈替代递归调用
// 左子区间[curLeft, keyI-1]
if (curLeft < keyI - 1) { // 仅当左区间有效(长度>1)时才压栈
st.push({ curLeft, keyI - 1 });
}
// 右子区间[keyI+1, curRight]
if (keyI + 1 < curRight) { // 仅当右区间有效(长度>1)时才压栈
st.push({ keyI + 1, curRight });
}
}
}7. 堆排序
堆排序(Heap Sort)是一种基于堆数据结构的比较排序算法。具体分为建堆和排序两大步骤,具体细节不懂的朋友请移步此文章:
1. 建堆:
升序建立大根堆,降序建立小根堆
2. 排序:
以升序为例,建好大根堆后,堆顶和堆底元素交换,完成一次排序,将最大值排到数组尾部(此时可以将这个最大值不视为堆的元素)
接着,向下调整找到次大值,将次大值和现在的堆底(最大值不视为堆底)交换,完成第二次排序
重复上述步骤直到排序完成
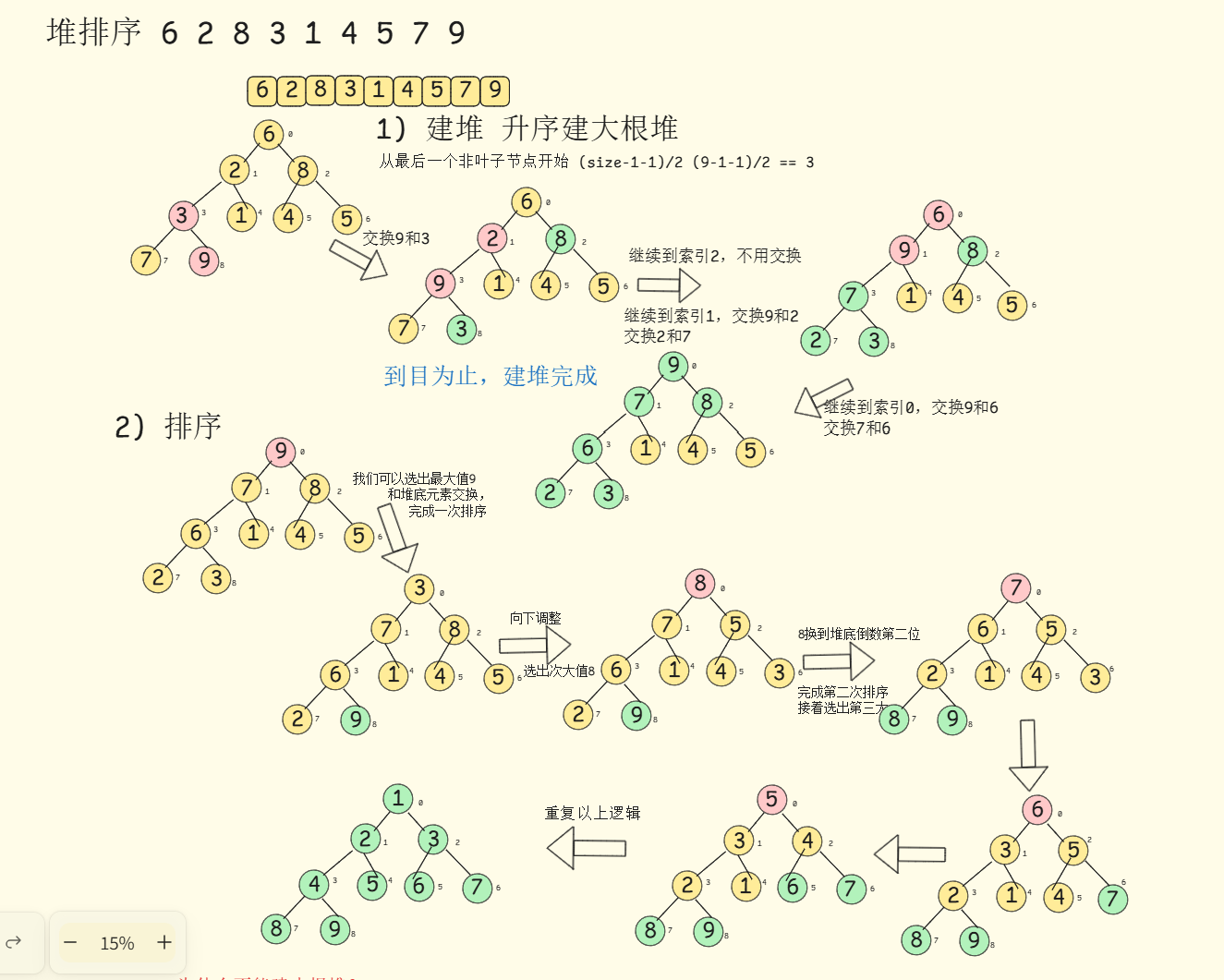
在这里插入图片描述
为什么升序不能建小根堆?
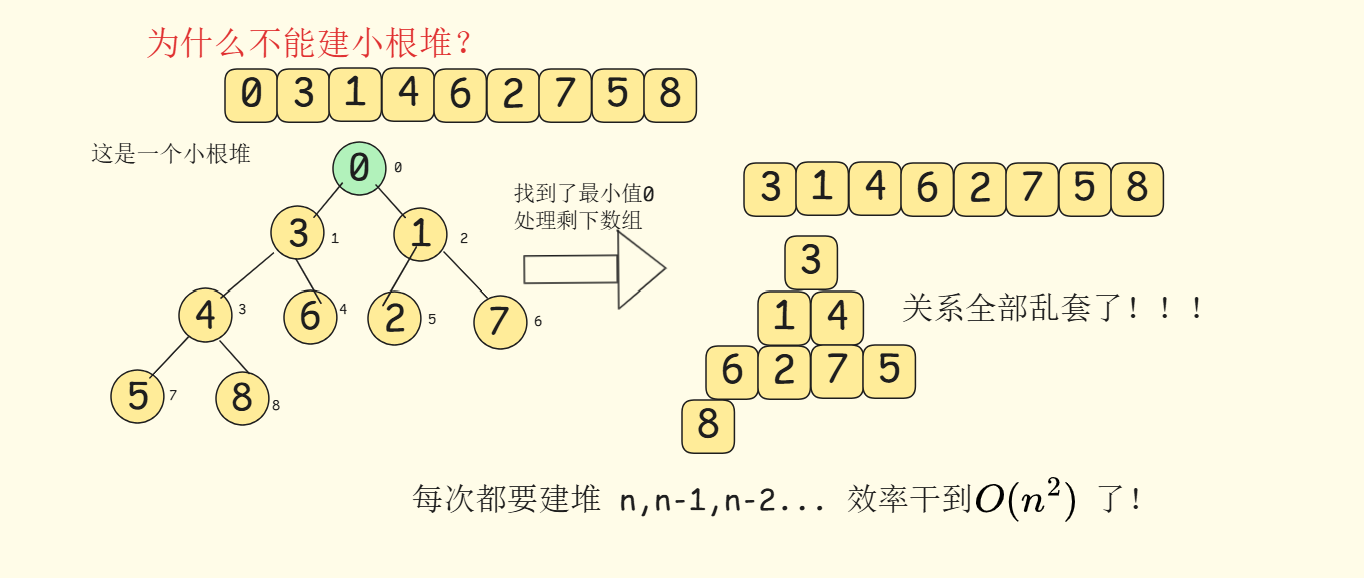
在这里插入图片描述
代码实现:
// 6. 堆排序
// 向下调整算法 建大顶堆的逻辑
void adjustDown(vector<int>& data, int parentIdx, int heapSize) {
// 假设两个孩子中左孩子更大
int maxChild = 2 * parentIdx + 1;
while (maxChild < heapSize) {
// 假设错误 更正索引 这里首先要保证右孩子索引不越界
if (maxChild + 1 < heapSize && data[maxChild] < data[maxChild + 1]) {
++maxChild;
}
// 已经找到两个孩子中值大的那个 和父节点进行比较
if (data[maxChild] > data[parentIdx]) {
swap(data[maxChild], data[parentIdx]);
parentIdx = maxChild; // 父节点索引下移
maxChild = 2 * parentIdx + 1; // 继续找值更大的子节点
}
else {
break; // 如果孩子的值小 这个子堆是大顶堆 直接break
}
}
}
// 建立大顶堆
void bulidMaxHeap(vector<int>& data) {
// 叶子节点不用调整
// 从最后一个非叶子结点开始倒序调整
// 最后一个叶子节点的父节点 (size - 1 - 1) / 2
int heapSize = data.size();
for (int i = (heapSize - 1 - 1) / 2; i >= 0; i--)
{
adjustDown(data,i, heapSize);
}
}
void heapSort(vector<int>& data) {
int heapSize = data.size();
if (heapSize <= 1) return;
// 1. 建大根堆
bulidMaxHeap(data);
// 2. 排序 把堆顶(最大)交换到当前区间末尾,缩小堆,再调整
for (int end = heapSize - 1; end > 0; end--)
{
swap(data[0], data[end]); // 交换元素
adjustDown(data, 0, end); // [0,end)区间调整
}
}堆排序的时间复杂度是
,建堆
,排序时要交换n个元素,同时堆化
,所以最终时间复杂度是
堆排序是一种不稳定的算法,可能会将两个相同的元素位置交换
8. 归并排序
递归版本
归并排序(Merge Sort)是一种基于分治思想的算法,具体分为划分子区间和合并排序这个两大步骤
- 划分子区间: 计算数组中点
mid,递归划分左子区间[left,mid]和右子区间[mid+1,right],递归执行到子区间长度为一,这是递归结束条件 - 合并排序: 合并排序本质是合并两个有序数组,利用
leftPtr左区间指针,rightPtr右区间指针和writePos写入指针,这三个指针控制元素的写入
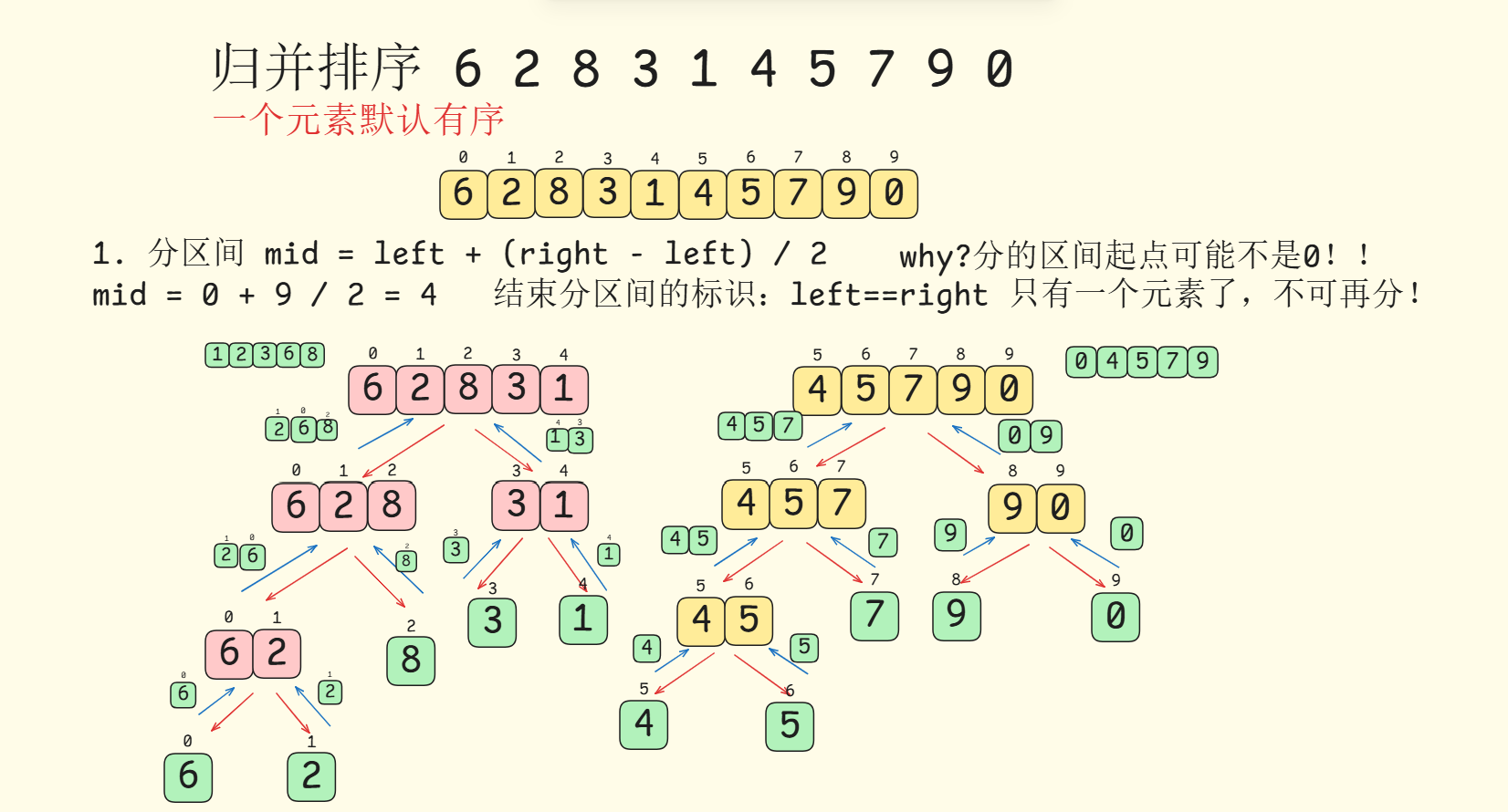
在这里插入图片描述
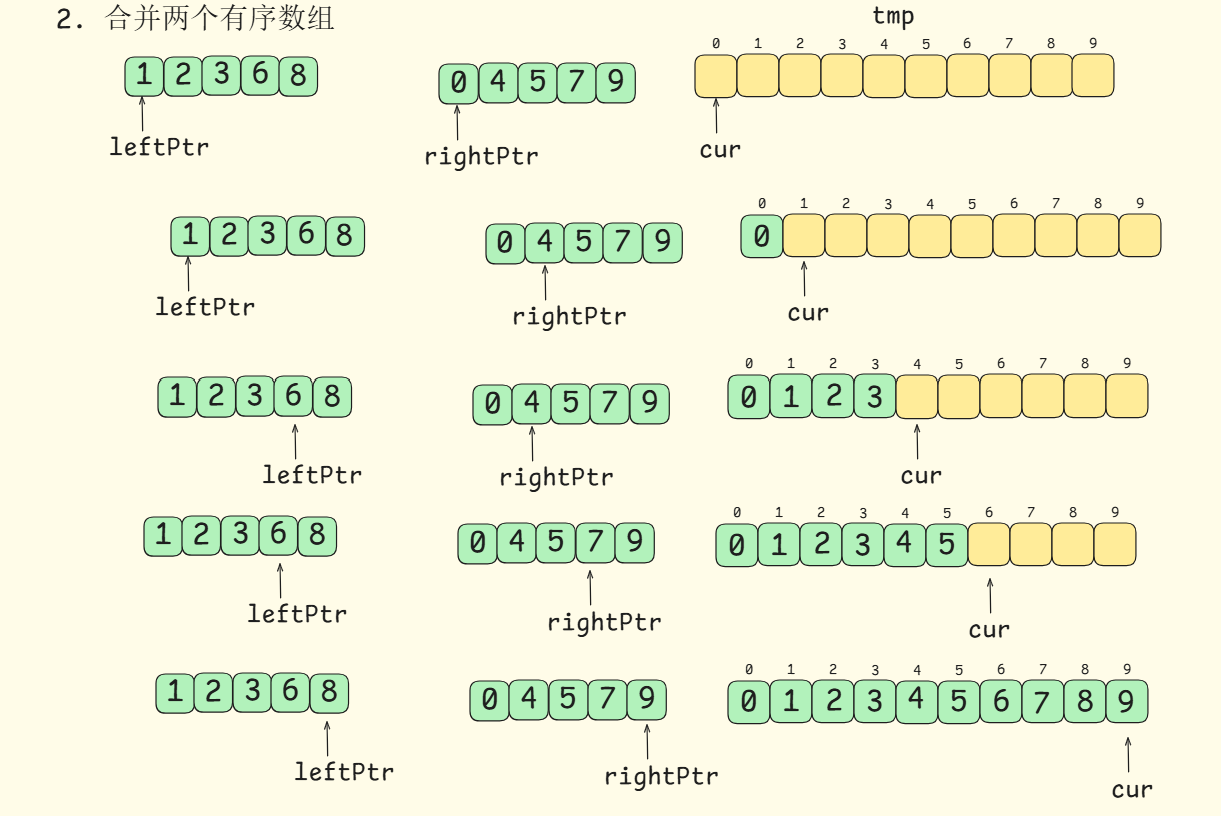
在这里插入图片描述
代码实现:
// 7. 归并排序
// 1) 合并两个有序数组
void _mergeSort(vector<int>& data, int left, int mid, int right, vector<int>& tmp) {
// 如果两个区间有序并且不交叉 直接返回
if (data[mid] <= data[mid + 1]) return;
// 记录左区间指针和右区间指针 别改left和right
int leftPtr = left;
int rightPtr = mid + 1;
int writePos = left;
while (leftPtr <= mid && rightPtr <= right) {
if (data[leftPtr] <= data[rightPtr]) tmp[writePos++] = data[leftPtr++];
else tmp[writePos++] = data[rightPtr++];
}
// 不确定谁先走到尾 都处理就行 走到尾的不会进循环
while (leftPtr <= mid) tmp[writePos++] = data[leftPtr++];
while (rightPtr <= right) tmp[writePos++] = data[rightPtr++];
// 将tmp里的数据拷贝到data里
for (int i = left; i <= right; i++)
{
data[i] = tmp[i];
}
}
// 2) 递归分区间
void _mergeSortDivide(vector<int>& data, int left, int right, vector<int>& tmp) {
// 递归结束条件
if (left == right) return;
int mid = left + (right - left) / 2;
// 先处理左区间 后处理右区间
_mergeSortDivide(data, left, mid, tmp);
_mergeSortDivide(data, mid + 1, right, tmp);
_mergeSort(data, left, mid, right, tmp);
}
// 对外接口
void mergeSort(vector<int>& data) {
int size = data.size();
if (size <= 1) return;
vector<int> tmp(size);
_mergeSortDivide(data, 0, size - 1, tmp);
}归并排序是一种稳定的算法,先处理左区间,后处理右区间,相同值的相对位置不发生变化
非递归版本
思路
把归并排序拆成两层循环:
- 外层(段长翻倍):
merLen = 1, 2, 4, 8, ...,只要merLen < size就继续。 - 内层(扫所有相邻小段):从左往右,每次拿两段长度为
merLen的相邻区间做一次稳定合并。
对每个“合并任务”,下标这样算(闭区间):
- 左段:
[begin1, mid],其中mid = begin1 + merLen - 1 - 右段:
[mid+1, end2],其中理论右端end2 = begin1 + 2*merLen - 1 - 越界裁剪:如果
end2 >= size,就把它截到size - 1 - 是否需要这次合并:内层用
while (begin1 + merLen < size),保证右段的起点存在(右段至少 1 个元素)
过程演示
用这 11 个数(索引 0…10):
data = [5, 1, 5, 3, 3, 2, 9, 0, 8, 8, 7]
轮次 A:**merLen = 1**
内层按步长 2*merLen = 2 扫相邻对(while (begin1 + merLen < size)):
begin1=0→mid=0,end2=1→ 合并[5] + [1]→ 发生合并data = [1, 5, 5, 3, 3, 2, 9, 0, 8, 8, 7]begin1=2→mid=2,end2=3→ 合并[5] + [3]→ 发生合并data = [1, 5, 3, 5, 3, 2, 9, 0, 8, 8, 7]begin1=4→mid=4,end2=5→ 合并[3] + [2]→ 发生合并data = [1, 5, 3, 5, 2, 3, 9, 0, 8, 8, 7]begin1=6→mid=6,end2=7→ 合并[9] + [0]→ 发生合并data = [1, 5, 3, 5, 2, 3, 0, 9, 8, 8, 7]begin1=8→mid=8,end2=9→ 合并[8] + [8]这里满足 已有序停止 条件:data[mid] <= data[mid+1] (8 <= 8)→ 直接跳过data不变:[1, 5, 3, 5, 2, 3, 0, 9, 8, 8, 7]
轮次 B:**merLen = 2**
内层步长 2*merLen = 4:
begin1=0→mid=1,end2=3→ 合并[1,5] + [3,5]→ 发生合并data = [1, 3, 5, 5, 2, 3, 0, 9, 8, 8, 7]begin1=4→mid=5,end2=7→ 合并[2,3] + [0,9]→ 发生合并data = [1, 3, 5, 5, 0, 2, 3, 9, 8, 8, 7]begin1=8→mid=9,end2=11(理论值) 触发右端裁剪:end2 >= size(11)→ 截到10→ 合并[8,8] + [7]→ 发生合并data = [1, 3, 5, 5, 0, 2, 3, 9, 7, 8, 8]
本轮展示了:右端裁剪(
end2被截到size-1)。
轮次 C:**merLen = 4**
内层步长 2*merLen = 8:
begin1=0→mid=3,end2=7→ 合并[1,3,5,5] + [0,2,3,9]→ 发生合并data = [0, 1, 2, 3, 3, 5, 5, 9, 7, 8, 8]
轮次 D:**merLen = 8**
内层步长 16:
begin1=0→mid=7,end2=15(理论值) 再次触发右端裁剪:end2 >= size→ 截到10合并[0,1,2,3,3,5,5,9] + [7,8,8]→ 发生合并data = [0, 1, 2, 3, 3, 5, 5, 7, 8, 8, 9]
外层下一轮 merLen = 16 >= size → 结束。
本轮展示了:最后一对不满两段 + 右端裁剪
代码实现
// 非递归
void mergeSortNonRecursive(vector<int>& data) {
int size = (int)data.size();
if (size <= 1) return;
vector<int> tmp(size);
int merLen = 1; // 段长从 1 开始(每轮把相邻两段长度为 merLen 的小段合并)
while (merLen < size) { // 只要段长还小于数组长度,就继续
int begin1 = 0;
// 关键条件:begin1 + merLen < size
// 右段的起点必须存在(至少有 1 个元素),才有“相邻两段”可合并
while (begin1 + merLen < size) {
// 第一段区间 [begin1, mid],长度 = merLen
// 这里 -1 是因为闭区间下标:起点 + 元素个数 - 1 = 终点下标
int mid = begin1 + merLen - 1;
// 第二段区间 [mid+1, end2],理论上长度也为 merLen
int end2 = begin1 + merLen * 2 - 1;
// 尾巴不满:如果 end2 超过了最后一个合法下标 size-1,就把它截断到 size-1
if (end2 >= size) {
end2 = size - 1;
}
// 合并这两个已排序的小段
_mergeSort(data, begin1, mid, end2, tmp);
// 跳到下一对相邻小段:跨过两段(长度 2*merLen)
begin1 = begin1 + merLen * 2;
}
merLen = merLen * 2;
}
}9. 计数排序
计数排序遵循相对映射的原理:一个值出现几次,映射的位置就加几次。主要适用于数据范围集中的数组排序,局限性较大:只适合整型排序。具体步骤如下:
- 统计每个数据出现的次数: 建立一个计数的数组,统计待排序数组内元素出现次数
- 返回排序: 一个值出现了几次,就往原数组写几次这个值
代码实现:
// 8. 计数排序
void countSort(vector<int>& data) {
// 1. 找待排数组里的最大值和最小值
int max = 0, min = 0;
int size = data.size();
for (size_t i = 0; i < size; i++)
{
if (data[i] < min) min = data[i];
if (data[i] > max) max = data[i];
}
// 得到计数数组范围
int range = max - min + 1;
vector<int> countArr(range, 0); // 创建range个0值的数组
// 2. 相对映射
for (size_t i = 0; i < size; i++)
{
countArr[data[i] - min]++;
}
// 3. 遍历countArr 将值写入原数组
int j = 0; // 控制数据写入原数组
for (size_t i = 0; i < range; i++)
{
while (countArr[i]--) data[j++] = i + min;
}
}10. 总结

在这里插入图片描述
学完这八种排序算法,你会发现没有 “绝对最好” 的算法,只有 “最适合场景” 的选择。
冒泡排序和插入排序适合小规模数据,尤其是接近有序的数据;希尔排序通过分组优化了插入排序,让它能应对更大规模的场景;快速排序凭借平均 O (nlogn) 的高效性,成为实际开发中的常客,但要记得用三数取中规避极端情况;堆排序不需要额外空间,适合对内存敏感的场景;归并排序用空间换稳定和高效,在多关键字排序中优势明显;计数排序则是特殊场景下的 “黑马”,数据范围越集中,它的效率越碾压比较类排序。
排序算法是算法世界的 “入门基石”,理解它们的稳定性、时间 / 空间复杂度,以及背后的分治、贪心等思想,能帮你更轻松地应对复杂算法问题。下次遇到排序需求时,不妨先想清楚数据规模、是否需要稳定排序、内存是否受限,再选择最适配的算法 —— 这才是学习排序算法的核心价值。
完整代码请移步我的GitHub仓库:Vect的GitHub库
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-10-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号