《Linux系统编程之入门基础》【Linux基础 理论+命令】(上)

《Linux系统编程之入门基础》【Linux基础 理论+命令】(上)

序属秋秋秋
发布于 2025-12-18 16:21:55
发布于 2025-12-18 16:21:55
往期《Linux系统编程》回顾:/------------ 入门基础 ------------/ 【Linux的前世今生】 【Linux的环境搭建】
前言:
hi~ 小伙伴们大家好呀!上次教完大家搭建环境,鼠鼠特意隔了好些天才继续更,其实就是想等大家攒够钱、把云服务器准备好,咱们再正式开始学 Linux 嘛~ 怎么样, ~ o( ̄▽ ̄)o对于鼠鼠的狡辩你有什么想要说的吗?
哎,有人问了ପ(๑•̀ㅁ•́ฅ✧)୧:Linux 这趟学习之旅进度好像有点慢,到底啥时候能结束呀? 这个嘛…… 嗯~o ( ̄▽ ̄) o 鼠鼠掐指一算,哎呀,手指头都数不过来啦!˚‧º·(˚ ˃̣̣̥⌓˂̣̣̥ )‧º·˚
---------------前置知识---------------
1. 核心问题怎么CV?
身为CV工程师,第一步当然是得先搞明白在 XShell 里咋进行复制和粘贴啦: 在 XShell 中,复制粘贴的默认快捷键和Windows下常见的
Ctrl + C/Ctrl + V不同,具体如下:
- 复制:使用
ctrl + Insert或者ctrl +Shift + c组合键完成复制- 部分设备需配合
Fn键按Insert才能触发(因键盘布局差异,若直接按Ctrl + Insert无效,可尝试加上Fn键)
- 部分设备需配合
- 粘贴:使用
Shift + Insert或者ctrl +Shift + v组合键完成粘贴
2. 怎么将屏幕全搞黑/白?
按住
Alt + Enter键,就可以将 Xshell 切换进入全屏或者退出全屏啦~ (≧∇≦)ノ 在 Xshell 终端里敲指令、写代码时,纯黑或纯白的界面,是不是还挺有极客范儿的?
3. 命令都长什么样?
Linux 命令的格式有一定的规范性,掌握其基本结构有助于更高效地使用命令。 Linux 命令的核心结构通常可以概括为:
命令 [选项] [参数]
- 其中
命令是必须的 - 然而
[选项]和[参数]是可选的(根据具体命令的功能需求决定是否添加)
1. 命令(Command)
- 含义:是命令的核心,代表要执行的具体操作(如:查看文件、创建目录等)
- 特点:由小写字母组成,通常是英文单词的缩写,便于记忆
- 示例:
ls(list 的缩写,列出目录内容)cd(change directory 的缩写,切换目录)cp(copy 的缩写,复制 文件/目录)
2. 选项(Options)
- 含义:用于调整命令的行为,实现更具体的功能(如:显示详细信息、忽略错误等)
- 格式分类:
- 短选项:由
-加单个字母组成(如:-l、-a) 示例:ls -l(以长格式列出文件) - 长选项:由
--加完整单词组成(更易理解) 示例:ls --all(等同于-a,显示所有文件,包括隐藏文件)
- 短选项:由
- 组合使用:多个短选项可以合并,例如:ls -la 等同于 ls -l -a
3. 参数(Arguments)
- 含义:指定命令操作的对象(如:文件、目录、路径等)
- 数量:根据命令不同,参数数量可分为:
- 0 个参数:如
pwd(显示当前目录,无需参数) - 1 个参数:如
cd /home(参数为目标目录/home) - 多个参数:如
cp file1.txt file2.txt /backup(复制file1.txt和file2.txt到/backup目录,前两个是源文件,最后一个是目标目录)
- 0 个参数:如
- 路径格式:参数可以是绝对路径(如:/usr/local)或相对路径(如:./docs,表示当前目录下的 docs 文件夹)
一、文件夹 VS 目录
在 Linux 系统里,目录和文件夹是同一概念的不同表述,可简单理解为
“目录 ≈ 文件夹”,用于组织和管理文件。
二、绝对路径 VS 相对路径
绝对路径:以 根目录(/) 为起点开始构建的路径
- 不依赖当前所在目录
- 因定位逻辑固定,唯一性稳定,常用于服务配置文件(需精准、固定指向)
- 示例:
/home/user/docs/file.txt
相对路径:以当前用户所处目录为起点开始构建的路径
- 无需写全路径,更简洁
- 因依赖当前位置,灵活性高,常用于命令行操作(手动快速输入)
- 示例:
docs/file.txt(若当前在/home/user)
注意:
- Windows 系统:路径分隔符为反斜杠
\ - Linux 系统:路径分隔符为正斜杠
/
特殊情况与补充:
- 选项参数顺序
- 通常选项在前,参数在后(如:
ls -l /home) - 部分命令允许选项和参数混合(但建议按规范顺序使用,避免混淆)
- 通常选项在前,参数在后(如:
- 帮助信息查看
- 几乎所有命令都支持
--help选项(如:ls --help),用于查看该命令的详细格式、选项和参数说明 - 也可以通过
man 命令(如:man ls)查看更完整的手册页
- 几乎所有命令都支持
- 管道与重定向
- 命令可以通过管道(
|)将输出传递给其他命令(如:ls -l | grep "txt",筛选出.txt文件) - 可以通过重定向符号(
>、>>、<等)处理输入输出(如:ls > filelist.txt,将结果写入文件 filelist.txt)
- 命令可以通过管道(
示例总结:
命令格式 | 说明 |
|---|---|
ls | 无选项、无参数,列出当前目录内容 |
ls -a | 带短选项,显示所有文件(包括隐藏文件) |
ls --long /tmp | 带长选项和参数,以长格式列出 /tmp 目录 |
cp -r src/ dest/ | 短选项(-r 递归复制目录)+ 两个参数(源目录和目标目录) |
4. 我是谁?我在哪?我要干嘛?

在这里插入图片描述
一、whoami
whoami - 英文全称为 “who am I”
核心作用:显示当前登录并正在操作终端的有效用户的用户名,快速确认当前身份
基本用法:
whoami:直接执行,无需参数,输出当前用户的用户名
whoami # 输出当前登录用户的用户名,如:zhangsan使用示例:
whoami # 普通用户登录时,输出如:user1
sudo whoami # 切换到root权限后执行,输出:root
# 在脚本中判断用户身份
if [ "$(whoami)" != "root" ]; then
echo "请使用root用户执行此脚本"
exit 1
fi注意事项:
whoami仅输出当前有效用户的用户名,不包含其他信息(如用户 ID、组信息等)- 与
id -un命令功能完全相同(id -un表示输出用户 ID 对应的用户名) - 区别于
who命令:who 显示系统中所有登录的用户信息,而 whoami 只显示当前操作的用户 - 当使用
sudo切换权限后,whoami会显示切换后的用户(如:sudo su后执行会显示root)
二、pwd
pwd - 英文全称为 “print working directory”
核心作用:显示当前所在的工作目录的绝对路径
基本用法:
pwd:不带任何参数,直接输出当前工作目录的绝对路径
pwd # 显示当前所在目录的绝对路径使用示例:
pwd # 显示当前工作目录的绝对路径三、cd
cd - 英文全称为 “change directory”
核心作用:切换当前工作目录,即从当前目录跳转到指定目录
基本用法:
cd [目录路径]:切换到指定路径的目录(路径可以是绝对路径或相对路径)
cd /home/user/docs # 绝对路径:切换到 /home/user/docs 目录
cd ./downloads # 相对路径:切换到当前目录下的 downloads 子目录cd:不带任何参数时,默认切换到当前用户的家目录(等价于 cd ~)
cd # 切换到当前用户的家目录特殊用法:
cd ~:切换到当前用户的家目录(与cd效果相同)cd ..:切换到当前目录的父目录(上一级目录)cd -:切换到上一次所在的目录(相当于 “返回” 功能)cd ~用户名:切换到指定用户的家目录(需有相应权限)
使用示例:
cd /etc # 切换到 /etc 系统目录
cd .. # 切换到上一级目录
cd - # 切换到上一次所在的目录
cd ~root # 切换到 root 用户的家目录(需权限)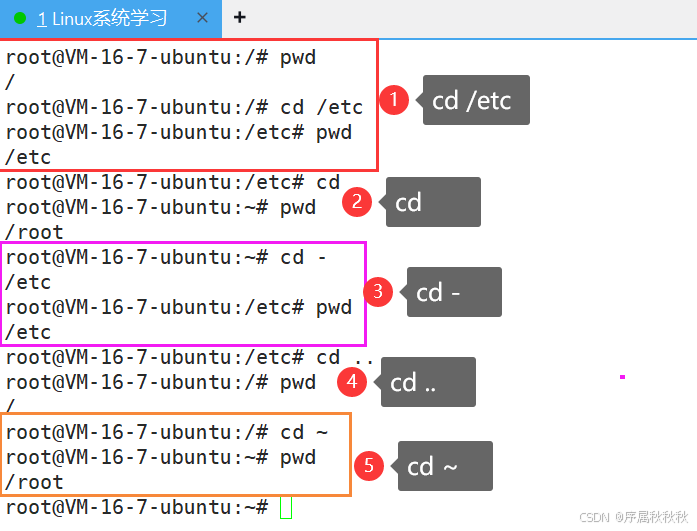
在这里插入图片描述
5. 输出Hello World?
四、echo
echo
核心作用:在终端输出指定的字符串或变量值,是 Shell 脚本中用于打印信息的基础命令
基本用法:
echo [字符串]:直接输出指定的字符串
echo "Hello World" # 输出:Hello World
echo 12345 # 输出:12345(数字无需引号包裹)echo [变量名]:输出变量的值(变量前需加 符号)
name="Linux"
echo $name # 输出:Linux常用选项:
-n:输出内容后不自动换行(默认会在结尾添加换行符)-e:启用转义字符解析(支持\n换行、\t制表符等特殊字符)
使用示例:
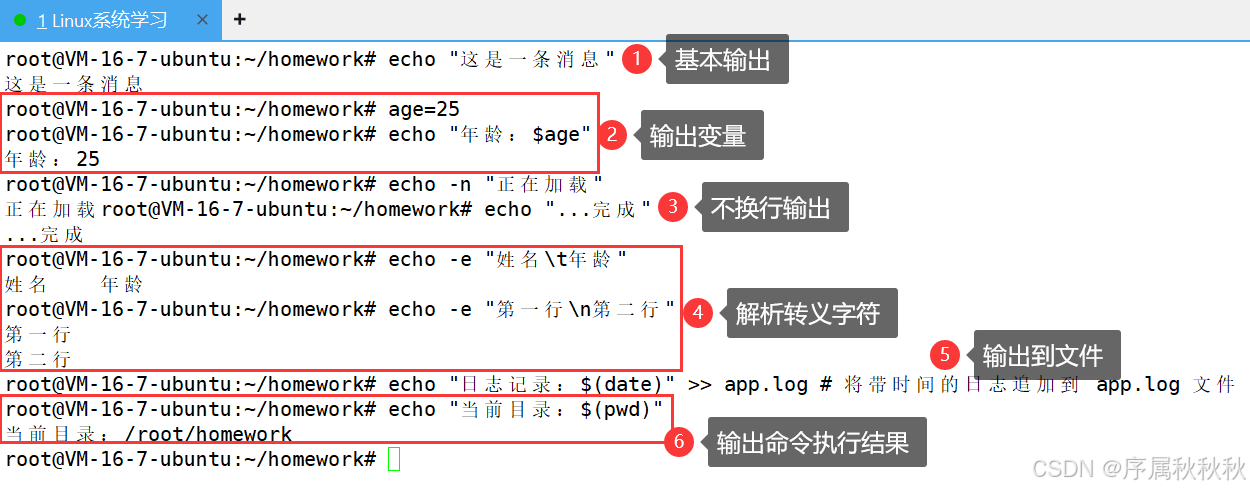
# 基本输出
echo "这是一条消息" # 输出:这是一条消息
# 输出变量
age=25
echo "年龄:$age" # 输出:年龄:25
# 不换行输出
echo -n "正在加载"
echo "...完成" # 输出:正在加载...完成(两行内容在同一行显示)
# 解析转义字符
echo -e "姓名\t年龄" # 输出:姓名 年龄(\t 表示制表符,即Tab键效果)
echo -e "第一行\n第二行" # 输出两行内容(\n 表示换行)
# 输出到文件(配合重定向符号 > 或 >>)
echo "日志记录:$(date)" >> app.log # 将带时间的日志追加到 app.log 文件
# 输出命令执行结果(配合 $() 或 ``)
echo "当前目录:$(pwd)" # 输出:当前目录:/home/user注意事项:
- 字符串中包含空格或特殊字符(如:
$、*)时,需用单引号或双引号包裹 - 单引号 '' 与双引号 "" 的区别: 双引号:会解析变量(如:
- 在脚本中,
echo常用于打印提示信息、变量值或调试内容 - 部分系统(如:BSD 系统)的
echo命令默认不支持-e选项,可使用printf命令替代更复杂的格式化输出
在这里插入图片描述
五、printf
printf - 英文全称为 “print formatted”
核心作用:按照指定格式输出字符串、变量或数据,支持复杂的格式化控制(如对齐、宽度、精度等),功能比 echo 更强大灵活
基本用法:
printf "[格式字符串]" [参数1] [参数2] ...:按格式字符串指定的规则输出参数
printf "姓名:%s,年龄:%d\n" "张三" 25 # 按格式输出字符串和数字常用格式符:
%s:输出字符串%d/%i:输出十进制整数%f:输出浮点数%c:输出单个字符%%:输出百分号本身
格式修饰符:
[数字]:指定输出宽度(不足补空格,正数右对齐,负数左对齐).[数字]:对浮点数指定小数位数(精度)-:左对齐(默认右对齐)0:用 0 填充数字的空位(如:%04d表示输出 4 位数字,不足前补 0)
使用示例:
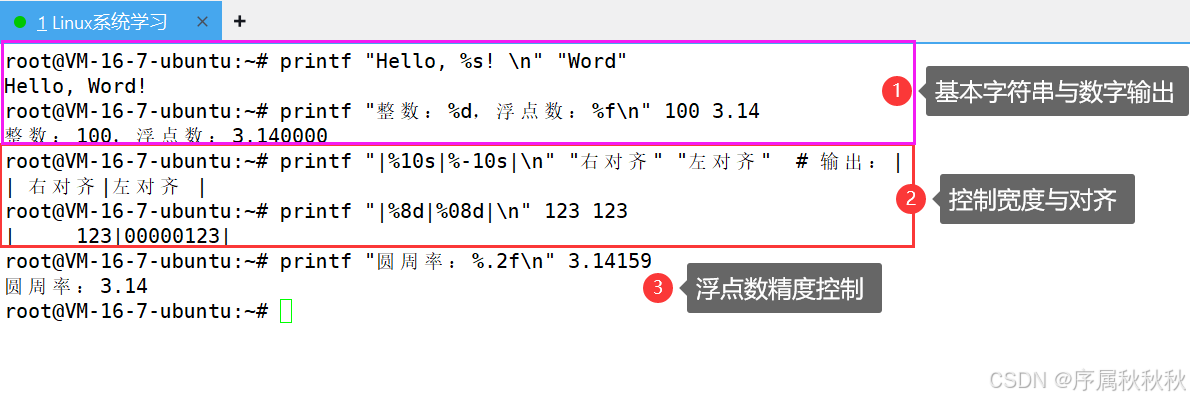
# 基本字符串与数字输出
printf "Hello, %s! \n" "Word" # 输出:Hello, Word!
printf "整数:%d,浮点数:%f\n" 100 3.14 # 输出:整数:100,浮点数:3.140000
# 控制宽度与对齐
printf "|%10s|%-10s|\n" "右对齐" "左对齐" # 输出:| 右对齐|左对齐 |
printf "|%8d|%08d|\n" 123 123 # 输出:| 123|00000123|
# 浮点数精度控制
printf "圆周率:%.2f\n" 3.14159 # 输出:圆周率:3.14(保留2位小数)
# 循环输出(配合Shell变量)
names=("Alice" "Bob" "Charlie")
ages=(22 25 30)
for i in {0..2}; do
printf "第%d人:%-10s 年龄:%d\n" $((i+1)) ${names[i]} ${ages[i]}
done
# 输出:
# 第1人:Alice 年龄:22
# 第2人:Bob 年龄:25
# 第3人:Charlie 年龄:30注意事项:
printf不会像echo那样自动添加换行符,需手动添加\n- 格式字符串中的格式符数量需与后面的参数数量匹配,否则可能出现意外输出
- 跨平台兼容性比
echo更好(不同系统的echo行为可能有差异) - 适合需要精确控制输出格式的场景(如:表格、日志等),简单输出可继续使用
echo
在这里插入图片描述
6. Linux 重定向命令有哪些?
一、输出重定向:>(覆盖写入)
基础命令:
echo "helloworld" > hello.txt
- 执行逻辑:检查hello.txt是否存在:
- 若不存在 → 新建
hello.txt,将echo输出的helloworld写入文件 - 若已存在 → 先清空文件原有内容,再写入
helloworld
- 若不存在 → 新建
- 验证步骤:
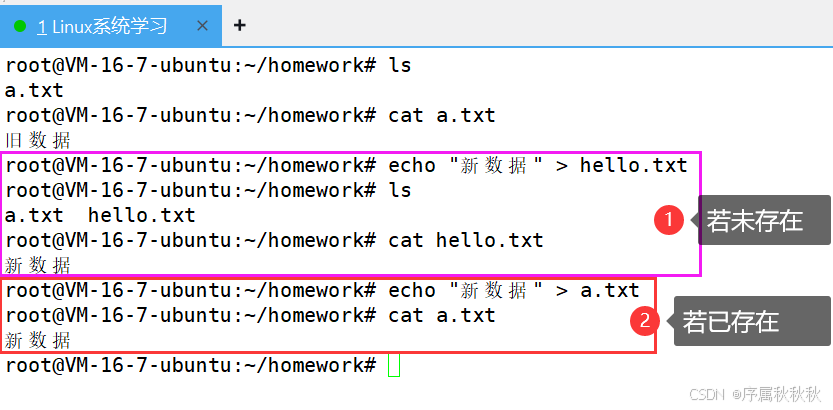
在这里插入图片描述
二、输出重定向:>>(追加写入)
基础命令:
echo "helloworld" >> hello.txt
- 执行逻辑: 无论 hello.txt 是否存在,不会清空原有内容,而是在文件末尾 追加写入新内容。
- 验证步骤:
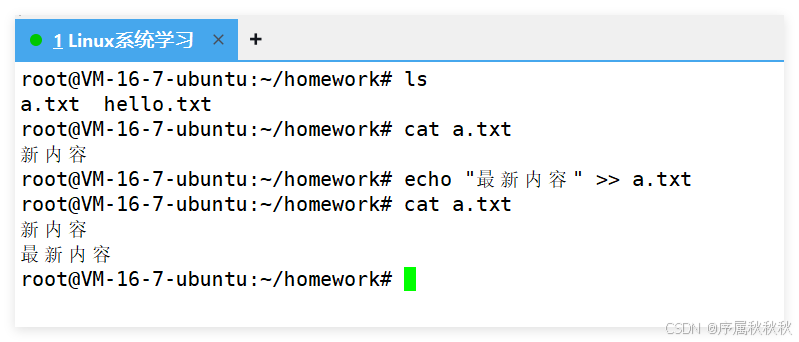
在这里插入图片描述
三、输入重定向:<(从文件读入)
基础命令:
cat < hello.txt
- 执行逻辑:
改变
cat命令的输入源:默认cat从键盘读入,用<后,改为从hello.txt读入内容,并输出到终端。 - 验证步骤:

在这里插入图片描述
重定向总结: 1. 输出重定向(>/>>)
- 本质:将命令的标准输出(stdout)导向文件,而非终端。
>:强制覆盖,会清空文件(类似 “替换文件内容” )>>:追加模式,在文件末尾续写(类似 “在文件最后加内容” )
2. 输入重定向(<)
- 本质:将命令的标准输入(stdin)从默认的 “键盘”,改为 “指定文件”。
- 例如
cat < hello.txt:让cat从hello.txt读内容,而非等待键盘输入
- 例如
---------------理论知识---------------
1. Linux 命令的本质是什么?
在 Linux 系统中,命令的本质,其实就是 “可执行文件” 。 这些可执行文件,和我们用 C/C++(或其他编程语言 )编写、编译后的程序,在逻辑上是同一类东西 —— 它们都是系统能识别、加载并运行的 “程序载体”。
简单说:
- 当你在终端输入
ls、cd这类命令时,背后执行的就是系统里预先存放好的可执行文件 - 从开发视角看,我们自己写的 C/C++ 程序,编译成可执行文件后,也能像系统命令一样被终端调用(只要放在系统能找到的路径,或通过路径指定执行 )
可以这么理解:Linux 命令 ≈ 可执行文件 ≈ 我们编写并编译后的程序,它们都是系统执行 “特定操作逻辑” 的载体,只是命令是系统自带、为基础运维设计的可执行文件,而我们写的程序,是按需求定制功能的可执行文件~
补充说明:
- 当然,Linux 也有 “内置命令”,由 Shell 直接实现,不对应独立文件
- 但绝大多数常用命令(如:
ls、cp等 ),确实是独立的可执行文件,和我们编译的程序逻辑一致
2. 文件的本质是什么?
Linux 中,文件由 “内容” 和 “属性” 两部分构成 :
- 内容:是文件实际存储的数据(如:文本、程序代码等 )
- 属性:包含文件权限(读写执行等 )、所有者、大小、创建时间等元信息
即便创建一个空文件,系统也会为其分配基础属性(如:占用磁盘 inode 等),所以空文件也会占据一定磁盘空间
3. 文件操作操作的是啥?
学习 Linux 文件操作时,核心思路可归纳为:围绕文件的 “内容” 或 “属性” 开展操作 ,比如:
- 对内容操作:用
cat查看文本内容、echo追加内容、vim编辑内容等 - 对属性操作:用
chmod修改权限、chown变更所有者、touch更新文件时间戳等
4. Linux 的文件系统结构长什么样?
Linux 的文件结构,是以根目录
/为起点的多叉树结构,磁盘里的文件与目录共同组成一棵目录树,每个节点仅为目录或文件 :
- 文件:在目录树里一定是叶子节点(无法包含其他节点 )
- 目录:可能是叶子节点(如:空目录,无下属内容 ),也可能是中间节点(包含子文件/子目录 )
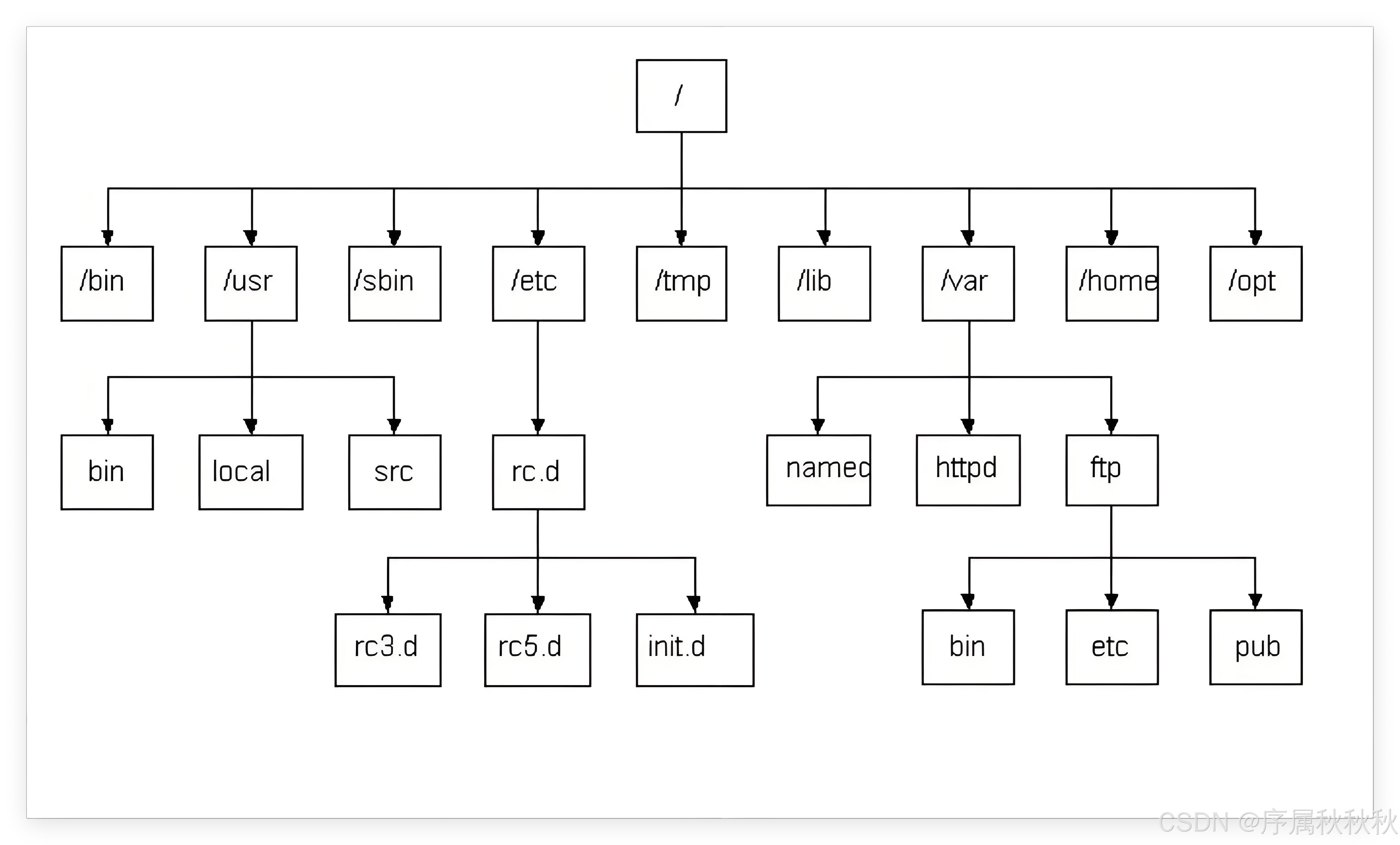
在这里插入图片描述
在这里插入图片描述
5. (.)和(…)到底是什么鬼?
在 Linux 系统里,任何一个目录,哪怕是空目录,系统都会默认自动为其生成两个特殊的目录:
.和..
.:代表当前目录,可用于在路径中指代当前操作所处的这个目录本身,比如:执行cp file.txt ./,就是把file.txt复制到当前目录(当然直接写cp file.txt .更常见 )..:代表父目录(当前目录的上一级目录 ),像执行cd ..,就能从当前目录切换到上一级目录,方便在目录层级间跳转
这两个特殊目录是 Linux 目录结构的基础特性,保障了目录树的层级关联与路径导航的逻辑完整性,让用户和程序能便捷地进行目录相关操作。
6. 为什么cd…能切换到上一级目录?
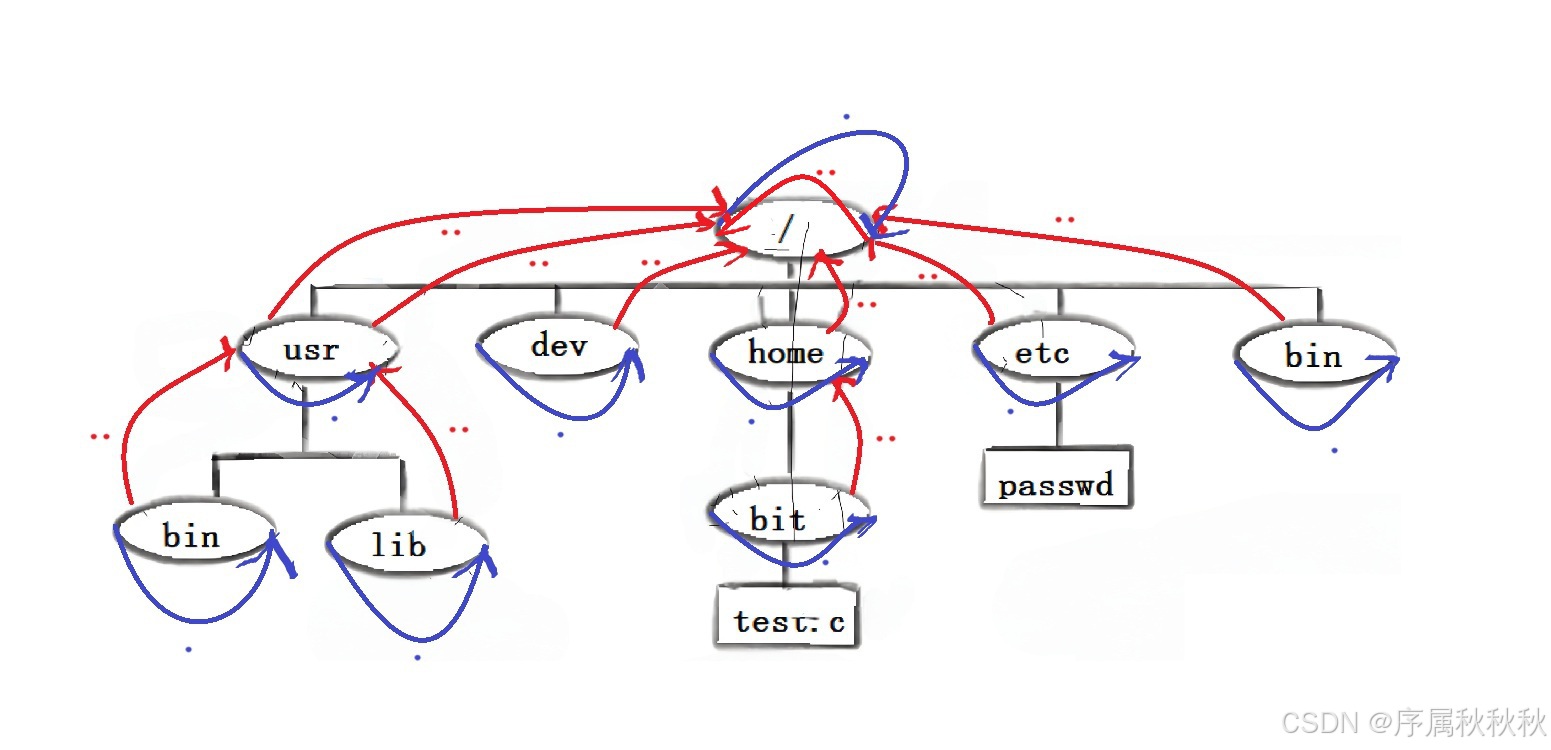
在这里插入图片描述
cd是 Linux 里切换目录的命令,它的核心逻辑是: 接收一个目录路径作为参数,将用户的 “当前工作目录” 切换到该路径。 当执行cd ..时:
..被识别为父目录的路径标识(由系统自动维护 )cd命令会读取当前目录里..指向的 “父目录位置”,并跳转过去
假设当前在 /home/user/docs 目录:
- 这个目录里的
..,指向的是/home/user(父目录 ) - 执行
cd ..,cd 会解析..的指向,把当前工作目录切换到/home/user
简单总结:
cd .. 能切换目录,是因为 Linux 目录里默认有 .. 标识父目录,且 cd 命令会依据 .. 的指向,完成 “跳转到上一级” 的操作~
Linux 文件系统是目录树结构(以
/为根 ),每个目录在树里都有唯一的 “父目录”(除了根目录/,它的..指向自己 ) 所以:不断的执行cd..命令,最终会停留在根目录层级。
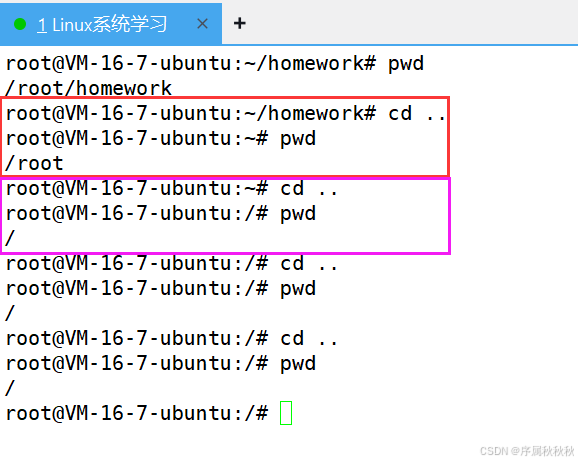
在这里插入图片描述
7. Linux 系统中,一切皆文件!
在 Linux 体系里,文件概念被极大拓展,不仅是你手动创建的普通文本、程序文件,像 键盘、显示器 这类硬件设备,在系统视角中,也以 “文件” 形式存在、被管理。
一、设备文件与文件操作的关联
像 printf/scanf(C 语言标准输入输出函数)、cout/cin(C++ 输入输出流),本质都是 “文件操作” —— 它们背后的逻辑,和用 fopen(C 语言文件打开函数)、fstream(C++ 文件流)操作普通文件,遵循相同的 “文件交互流程” 。
- 对键盘、显示器这些设备文件来说:访问之前,必须先 “打开”
- 只不过在日常编程里,系统默默帮我们做了 “打开设备文件” 这件事,让我们能直接用
printf输出到显示器、用scanf读取键盘输入
二、系统自动 “打开” 设备文件的原理
系统启动后,会自动帮我们 “打开” 最基础的几个设备文件,核心依赖如下:
#include <stdio.h>
// C 标准库函数:手动打开文件时调用,指定路径、打开模式
FILE *fopen(const char *path, const char *mode);
// 系统预先定义的 “标准设备文件指针”
extern FILE *stdin; // 对应键盘(标准输入)
extern FILE *stdout; // 对应显示器(标准输出)
extern FILE *stderr; // 对应显示器(标准错误输出,如:程序报错信息 ) 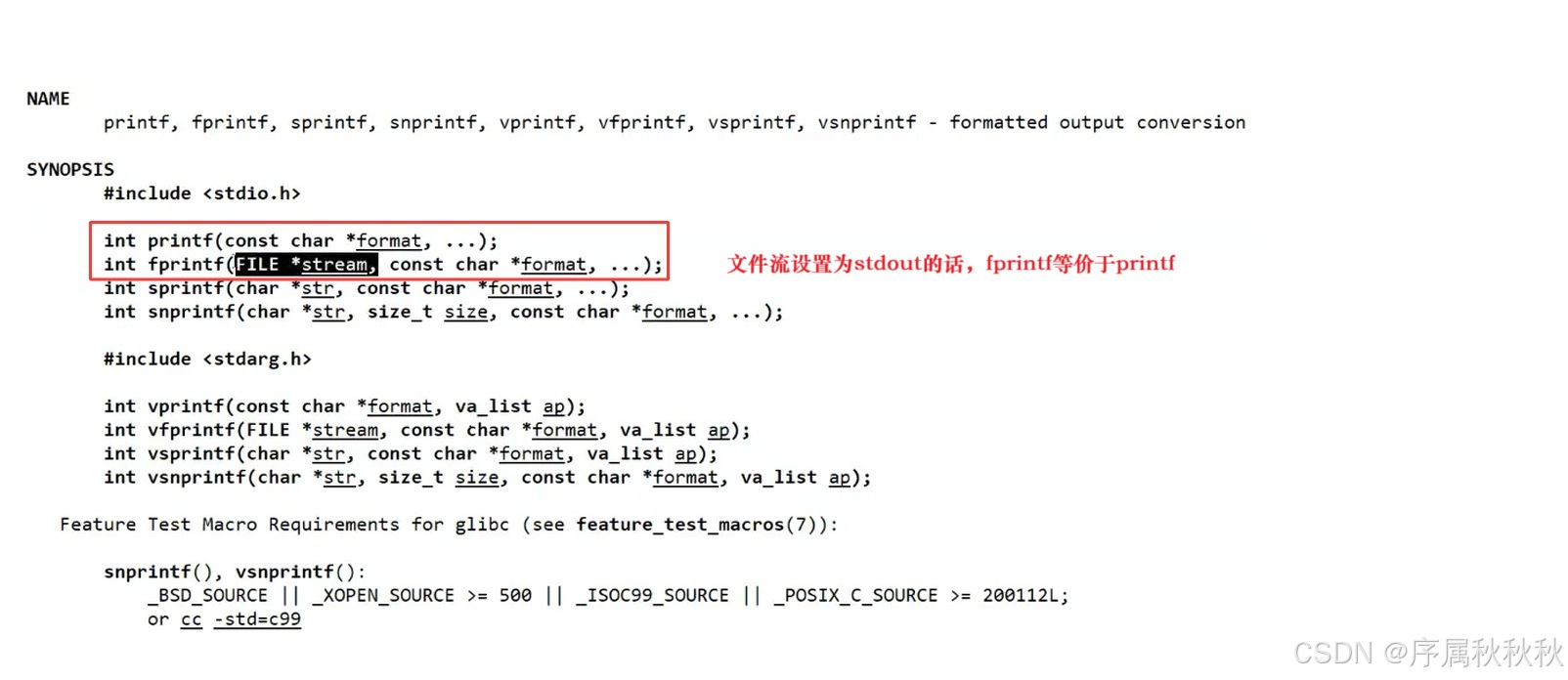
在这里插入图片描述
1. 系统为什么要帮我们打开?
这是为了让编程更简单!
想象一下,如果每次写 printf 前,都要手动 fopen 显示器设备文件,代码会变得繁琐且不通用。
系统预先打开 stdin/stdout/stderr ,相当于提供了 “默认交互通道” :
- 写代码时,直接用
printf/cout就能往显示器输出,无需关心硬件细节 - 用
scanf/cin就能从键盘读入,背后靠stdin这个已打开的 “设备文件” 支撑
2. 为什么只默认打开这几个? stdin(键盘)、stdout(显示器)、stderr(显示器)是 最基础、最通用的交互设备 。
- 几乎所有程序都需要 “输入、输出、报错” 功能,系统预先打通这些通道,能让程序开发 “开箱即用” ,覆盖 99% 的基础场景
- 如果需要操作其他设备(比如:摄像头、自定义硬件),就需要 手动用
fopen等函数打开对应的设备文件 ,并按设备规则读写数据
三、理解 “一切皆文件” 的意义
把设备抽象成 “文件” ,是 Linux 设计的精妙之处:
- 统一操作逻辑:不管是操作普通文件,还是键盘、显示器,都能用一套 “打开 → 读写 → 关闭” 的流程,降低学习和开发成本
- 方便灵活扩展:新硬件接入时,只要按 “文件” 规范实现驱动,就能被系统以统一方式管理,让 Linux 能适配海量设备
简单说:“一切皆文件” 是 Linux 高效、灵活的基石之一 。
系统预先打开标准设备文件,是为了让我们写代码更轻松 —— 而背后的原理,本质是 用 “文件抽象” 简化硬件交互 ,这也是 Linux 体系最核心的思想之一 。
8. 终端也是文件???
这时小伙伴们可能会感到疑惑 (・・?) 啊,“一切皆文件”,那岂不是说——嘿嘿,终端也是文件咯? 芜湖~起飞~~ (ノ≧∀≦)ノ♪✈️
---------------基础命令---------------
------- 文件目录查看 -------
一、ls
ls - 英文全称为 “list”
核心作用:显示当前或指定目录下的文件和子目录
基本用法:
ls:不带任何参数时,默认列出当前目录中可见的文件和子目录(不包括隐藏文件),按字母顺序排列,以空格分隔
ls # 列出当前目录内容ls [目录路径]:指定目录路径时,列出该目录下的内容
ls /home # 列出 /home 目录下的内容
ls ./docs # 列出当前目录下 docs 子目录的内容(相对路径)常用选项:
-l:以长格式显示(包含文件权限、所有者、大小、修改时间等详细信息)-a:显示所有文件和目录(包括隐藏文件,即以.开头的文件)-h:与-l结合使用,以易读格式显示文件大小(如:KB、MB)-t:按修改时间排序(最新的在前)-r:反向排序(默认按字母顺序,反向后从 Z 到 A)
使用示例:
ls # 列出当前目录内容
ls -a # 列出当前目录所有文件(包括隐藏)
ls -lh # 详细列出当前目录内容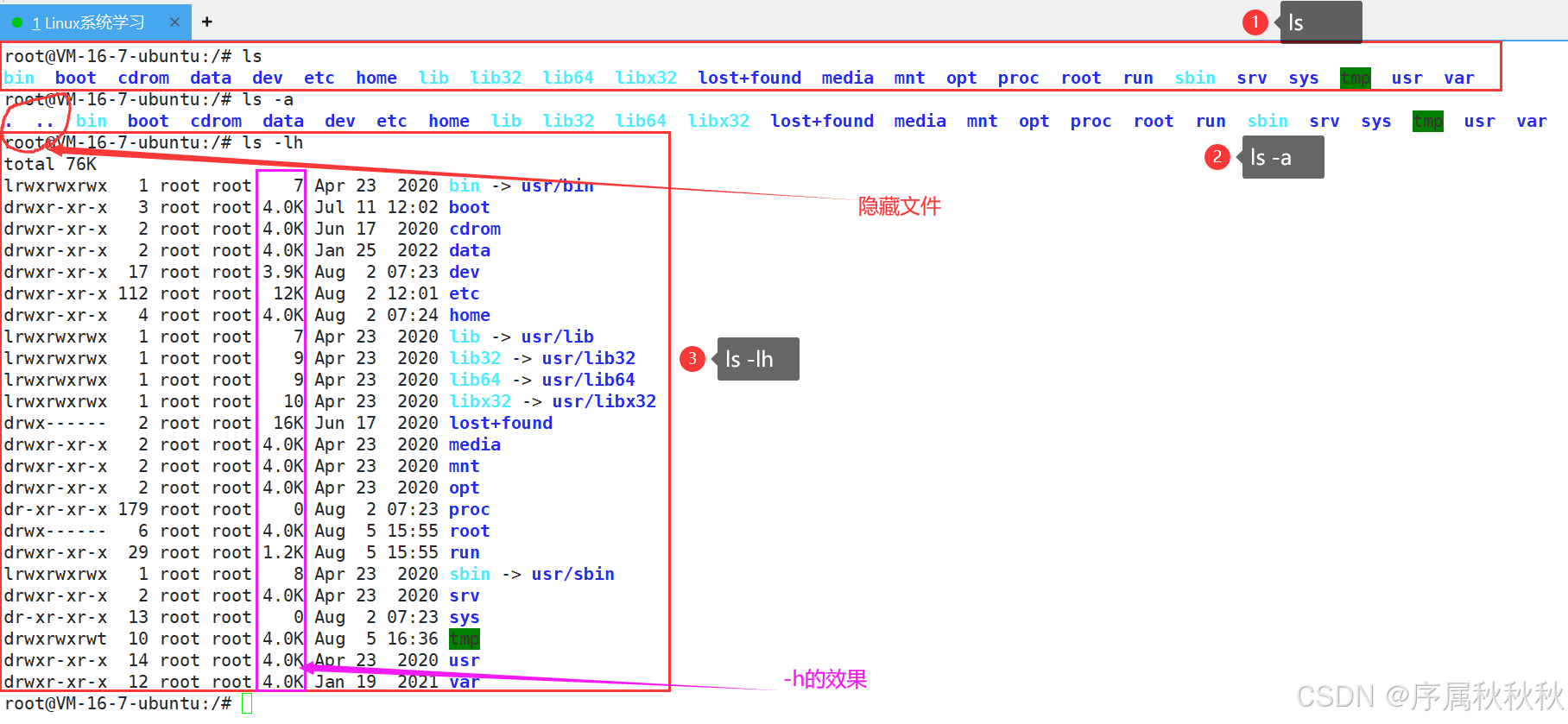
在这里插入图片描述
二、stat
stat - 英文全称为 “status”
核心作用:显示文件或文件系统的详细状态信息,包括权限、大小、创建/修改时间等元数据
基本用法:
stat [文件名/目录名]:显示指定文件或目录的详细状态信息
stat note.txt # 显示 note.txt 文件的详细信息
stat docs/ # 显示 docs 目录的详细信息stat [路径]/[文件/目录名]:显示指定路径下文件或目录的状态(支持绝对路径和相对路径)
stat /home/user/data.csv # 绝对路径:显示 /home/user 下 data.csv 的信息
stat ./logs/error.log # 相对路径:显示当前目录 logs 子目录下 error.log 的信息常用选项:
-f:显示文件所在文件系统的信息(而非文件本身),如:文件系统类型、总容量、可用空间等-t:以简洁的单行格式输出信息(适合脚本中提取数据)-c [格式符]:自定义输出格式,常用格式符包括:%a:八进制权限(如:644)%A:符号权限(如:-rw-r–r–)%s:文件大小(字节数)%U:文件所有者用户名%G:文件所属组名%y:最后修改时间(带时区)
使用示例:
# 显示文件的完整状态信息
stat report.pdf
# 输出示例包含:文件类型、大小、权限、所有者、创建/修改/访问时间等
# 显示文件系统信息(如磁盘空间)
stat -f /home
# 输出可能包含:文件系统类型、总块数、空闲块数、块大小等
# 简洁格式输出文件关键信息
stat -t image.png
# 单行输出:文件名 大小 权限 所有者 时间等精简信息
# 自定义格式输出权限和所有者
stat -c "权限:%A,所有者:%U" config.ini
# 输出如:权限:-rw-r--r--,所有者:admin
在这里插入图片描述
三、tree
tree
核心作用:以树形结构递归显示目录和文件的层级关系,直观展示文件夹的组织结构,便于快速了解目录结构
基本用法:
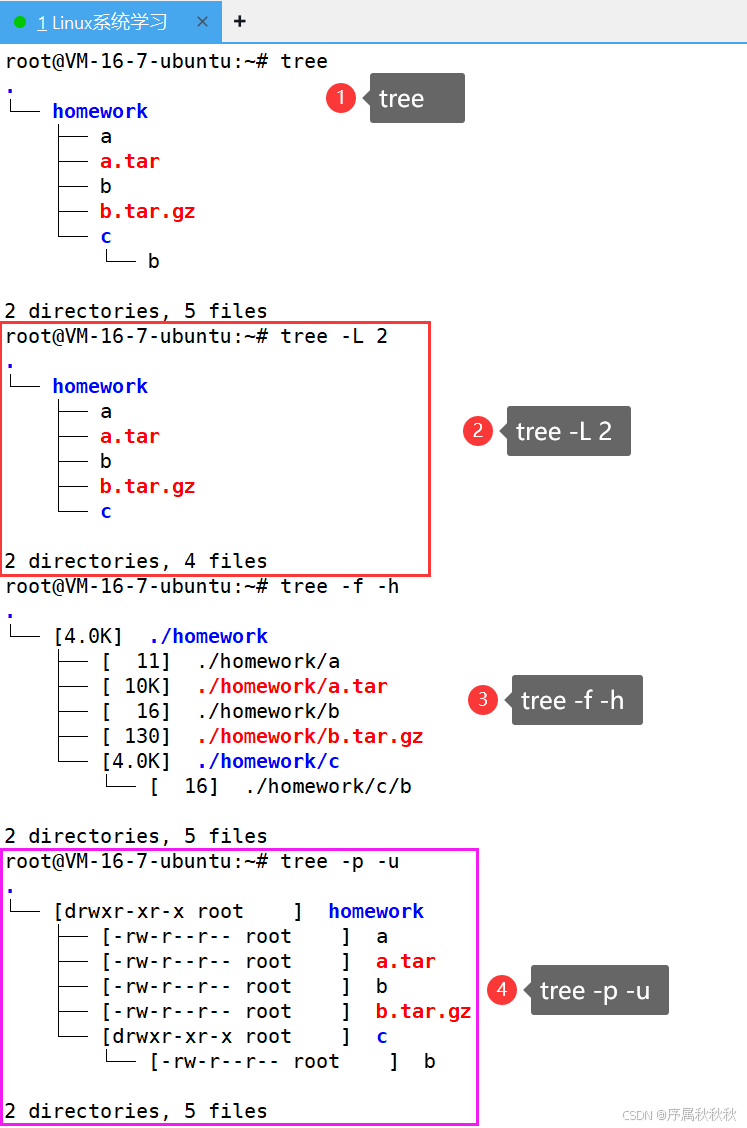
tree:不带参数时,以树形结构显示当前目录下的所有文件和子目录
tree # 显示当前目录的树形结构tree [目录路径]:显示指定目录的树形结构
tree /home/user/docs # 显示 docs 目录的树形结构常用选项:
-L [层数]:限制显示的目录深度(层数),避免层级过深导致输出过长-d:仅显示目录,不显示文件-f:显示每个文件 / 目录的完整路径-p:显示文件 / 目录的权限-u:显示文件 / 目录的所有者-s:显示文件 / 目录的大小-h:以人类可读的格式显示大小(如 K、M、G)-P [模式]:只显示文件名匹配指定模式的文件 / 目录(支持通配符)-I [模式]:排除文件名匹配指定模式的文件 / 目录
使用示例:
tree -L 2 # 只显示当前目录下2层的结构(当前目录为第1层)
tree -d /etc # 仅显示 /etc 目录下的子目录结构
tree -f -h # 显示当前目录所有文件的完整路径和人类可读的大小
tree -P "*.txt" # 只显示所有 .txt 结尾的文件及所在目录
tree -I "node_modules" # 显示当前目录结构,排除 node_modules 目录
tree -p -u # 显示文件权限和所有者信息注意事项:
- 部分 Linux 系统默认未安装
tree,需手动安装(如sudo apt install tree或sudo yum install tree) - 对于包含大量文件的目录,
tree输出可能很长,可结合管道符| less分页查看(如tree /usr | less) - 通配符模式需用引号包裹,避免被 Shell 提前解析
- 使用
-L选项限制层级,可使输出更简洁,适合快速了解目录框架 - 与
ls -R相比,tree的输出更直观,层级关系一目了然
tree 命令可递归以树状结构显示指定目录内容,若未安装需手动部署:
- 若当前是root 用户:
- 直接执行 yum install -y tree(centos系统)
- 直接执行 apt install -y tree (ubuntu系统)
- 若当前是普通用户:需用 sudo yum/apt install -y tree(后续讲完 vim 后,才可将用户加入系统信任列表开启 sudo 权限,当前普通用户暂无法使用 sudo)
在这里插入图片描述
四、which
which
核心作用:在环境变量 $PATH 定义的目录中,查找可执行命令的路径,帮助确认命令是否存在及实际执行的版本
基本用法:
which [命令名]:查找指定命令在系统中的路径
which ls # 查找 ls 命令的路径which [命令名1] [命令名2]:同时查找多个命令的路径
which python3 gcc # 同时查找 python3 和 gcc 命令的路径常用选项:
-a:显示所有匹配的命令路径(默认只显示第一个找到的路径)
使用示例:
which pwd # 查找 pwd 命令的路径,输出如:/bin/pwd
which -a python # 显示所有名为 python 的可执行文件路径
which cd # 若 cd 是内置命令,可能无输出(因 which 只查外部可执行文件)注意事项:
- which 仅搜索环境变量 PATH 包含的目录,若命令在当前目录但未加入 PATH,则无法找到(需用 ./命令 执行)
- 对别名(如:
ll='ls -l'),which通常会显示别名对应的原始命令路径,而非别名本身 - 与
whereis不同,which只关注可执行文件,不包含手册页、源文件等信息 - 内置命令(如:
cd)由 shell 自身提供,which可能无法返回其路径
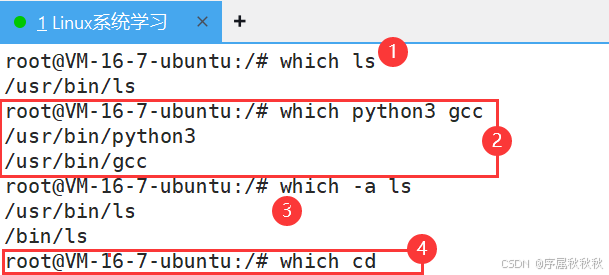
在这里插入图片描述
五、whereis
whereis - 英文全称为 “where is”
核心作用:在系统预设的目录中,快速查找命令对应的可执行文件、源代码文件和手册页文件的位置
基本用法:
whereis [命令名]:查找指定命令相关的文件(可执行文件、源代码、手册页)
whereis ls # 查找与 ls 命令相关的文件whereis [命令名1] [命令名2]:同时查找多个命令相关的文件
whereis gcc python3 # 同时查找 gcc 和 python3 相关的文件常用选项:
-b:仅查找可执行文件(binary)-s:仅查找源代码文件(source)-m:仅查找手册页文件(manual)-u:查找不完整的文件(即缺少可执行文件、源代码或手册页中至少一项的文件)
使用示例:
whereis grep # 查找 grep 相关的所有文件,输出如:grep: /bin/grep /usr/share/man/man1/grep.1.gz
whereis -b python3 # 仅查找 python3 的可执行文件路径
whereis -m ls # 仅查找 ls 命令的手册页文件位置
whereis -s gcc # 仅查找 gcc 的源代码文件(若存在)
whereis -u find # 查找 find 命令中不完整的文件信息注意事项:
whereis仅搜索系统预设的目录(如:/bin、/usr/bin、/usr/share/man等),非标准路径的文件可能无法找到- 相比
which,whereis不仅能找到可执行文件,还能找到手册页和源代码(若存在),但搜索范围更局限于系统默认目录 - 对于没有源代码或手册页的命令,
whereis只会显示其可执行文件路径 - 速度较快,因为它依赖预先生成的数据库(部分系统),而非实时遍历目录
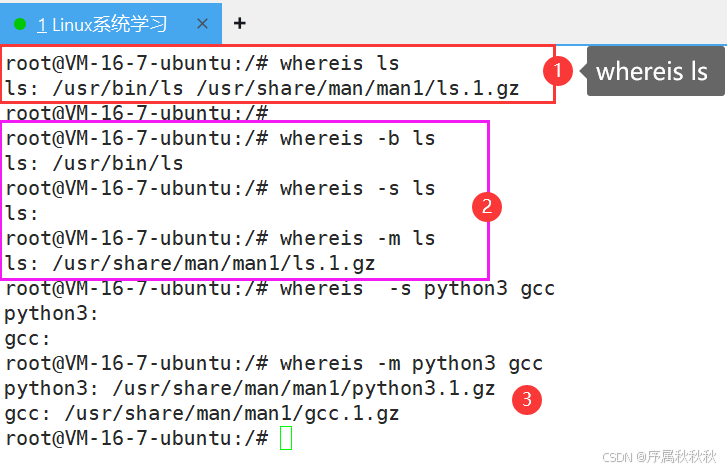
在这里插入图片描述
------- 文件目录操作 -------
一、touch
touch
核心作用:创建新的空文件,或更新已有文件的访问时间和修改时间(不改变文件内容)
基本用法:
touch [文件名]:若文件不存在,则创建指定名称的空文件;若文件已存在,则更新其时间戳
touch note.txt # 创建空文件 note.txt,或更新已有 note.txt 的时间touch [文件1] [文件2] ...:同时处理多个文件,批量创建空文件或更新时间
touch a.txt b.md c.log # 同时创建/更新多个文件常用选项:
-a:仅更新文件的访问时间(不改变修改时间)-m:仅更新文件的修改时间(不改变访问时间)-d "时间字符串":指定更新为特定时间(如:2024-01-01 12:00)-t 时间戳:用数字时间戳指定更新时间(格式:YYYYMMDDhhmm.ss)
使用示例:
touch report.txt # 创建空文件 report.txt
touch -a readme.md # 仅更新 readme.md 的访问时间
touch -d "2025-05-20" data.csv # 将 data.csv 时间改为 2025年5月20日
touch -t 202312312359.59 log.txt # 将 log.txt 时间改为 2023年12月31日23:59:59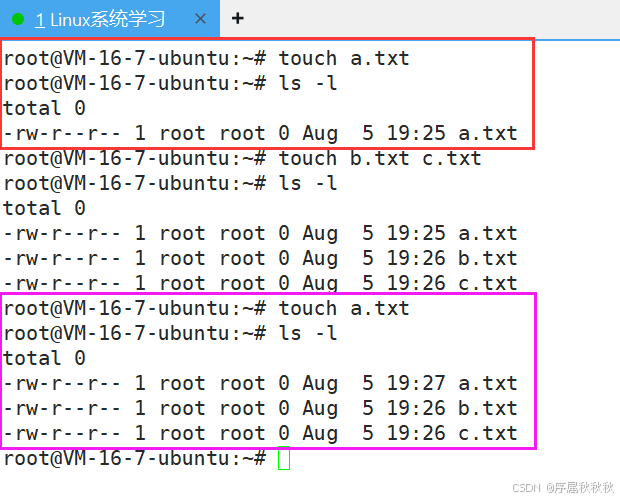
在这里插入图片描述
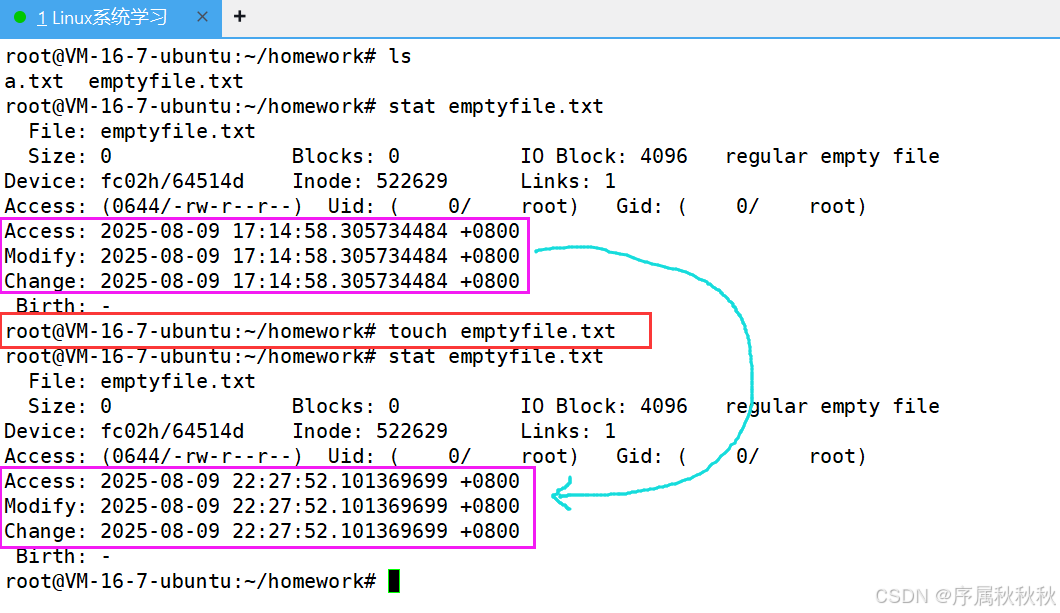
在这里插入图片描述
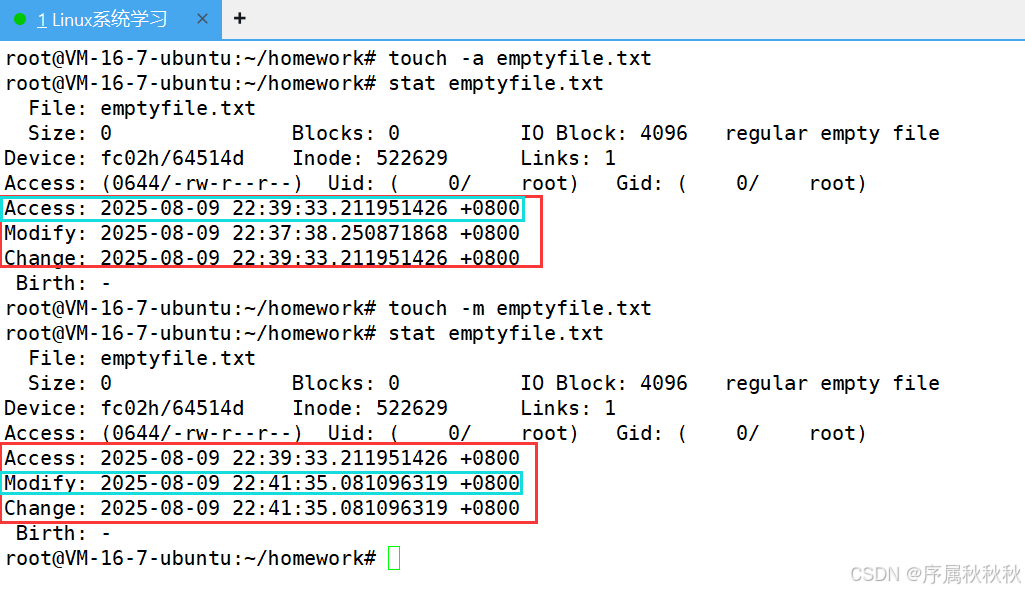
在这里插入图片描述
二、mkdir
mkdir - 英文全称为 “make directory”
核心作用:创建新的目录(文件夹)
基本用法:
mkdir [目录名]:在当前目录下创建指定名称的新目录
mkdir docs # 在当前目录下创建名为 docs 的目录mkdir [路径]/[目录名]:在指定路径下创建新目录(路径可以是绝对路径或相对路径)
mkdir /home/user/downloads # 绝对路径:在 /home/user 下创建 downloads 目录
mkdir ./data/reports # 相对路径:在当前目录的 data 子目录下创建 reports 目录常用选项:
-p:递归创建目录,即当父目录不存在时,自动创建所需的所有父目录
使用示例:
mkdir images # 在当前目录创建 images 目录
mkdir -p project/src/css # 递归创建嵌套目录(若 project 和 src 不存在则自动创建)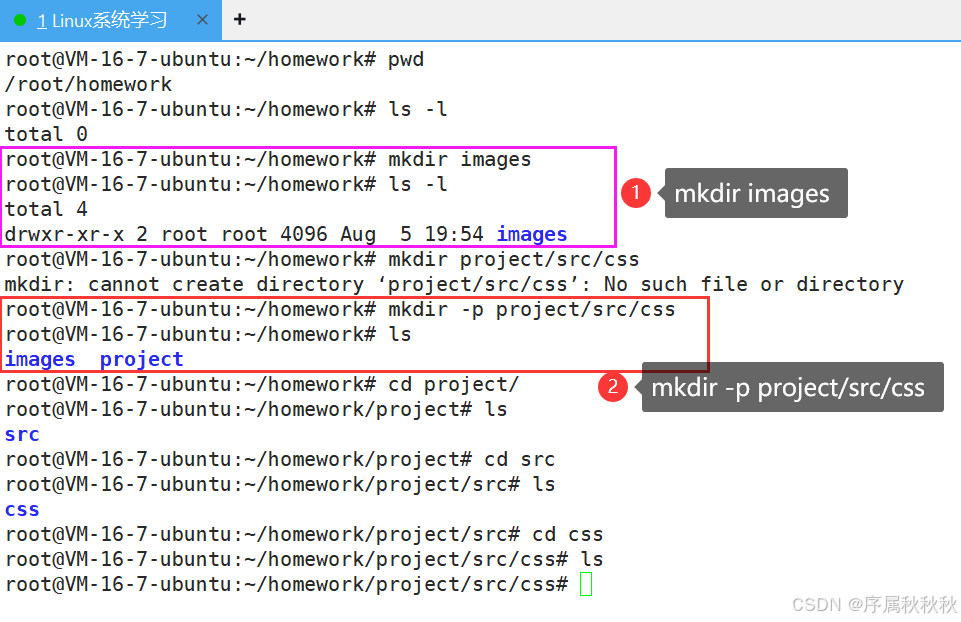
在这里插入图片描述
三、rmdir
rmdir - 英文全称为 “remove directory”
核心作用:删除空目录(只能删除空目录,若目录非空则无法删除)
基本用法:
rmdir [目录名]:删除当前目录下指定的空目录
rmdir temp # 删除当前目录下名为 temp 的空目录rmdir [路径]/[目录名]:删除指定路径下的空目录(路径可以是绝对路径或相对路径)
rmdir /home/user/old # 绝对路径:删除 /home/user 下的 old 空目录
rmdir ./docs/backup # 相对路径:删除当前目录 docs 子目录下的 backup 空目录常用选项:
-p:递归删除空目录,删除子目录后若其父目录也为空,则一并删除
使用示例:
rmdir images # 删除空目录 images
rmdir -p a/b/c # 递归删除空目录 a/b/c,若 b 和 a 也为空则同时删除
rmdir project/src/css # 删除相对路径下的css目录
在这里插入图片描述
四、rm
rm - 英文全称为 “remove”
核心作用:删除文件或目录(可删除非空目录,功能比 rmdir 更灵活,但需谨慎操作,删除后通常无法恢复)
基本用法:
rm [文件名]:删除当前目录下的指定文件
rm note.txt # 删除当前目录下的 note.txt 文件rm [路径]/[文件/目录名]:删除指定路径下的文件或目录(路径可以是绝对路径或相对路径)
rm /home/user/temp.log # 绝对路径:删除 /home/user 下的 temp.log 文件
rm ./docs/old/ # 相对路径:删除当前目录 docs 子目录下的 old 目录(需配合选项)常用选项:
-f:强制删除,不提示确认(即使文件权限为只读也直接删除)-i:删除前提示确认(交互式删除,避免误操作)-r或-R:递归删除,用于删除目录及其包含的所有文件和子目录(包括非空目录)-v:显示删除过程的详细信息(verbose 模式)
使用示例:
rm file1.txt # 删除 file1.txt 文件(默认可能提示确认,视系统配置而定)
rm -f junk.txt # 强制删除 junk.txt,不提示
rm -i important.doc # 删除前提示确认是否删除 important.doc
rm -r docs # 递归删除 docs 目录及其中所有内容
rm -rf old_project # 强制递归删除 old_project 目录(慎用,无法恢复)
rm -v *.log # 删除所有 .log 结尾的文件,并显示删除过程注意事项:
rm命令删除的文件 / 目录不会进入 “回收站”,删除后难以恢复,尤其是rm -rf操作风险极高,使用时务必确认路径和名称正确(建议先用ls查看目录内容再删除)- 避免在根目录(
/)或系统重要目录下使用rm -rf,否则可能导致系统崩溃

在这里插入图片描述
五、cp
cp - 英文全称为 “copy”
核心作用:复制文件或目录,可在不同位置创建 文件/目录 的副本
基本用法:
cp [源文件] [目标路径]:复制单个文件到指定路径
cp file.txt ./backup/ # 复制 file.txt 到当前目录的 backup 子目录
cp document.pdf /home/user/docs/ # 复制 document.pdf 到 /home/user/docs 目录cp [源文件1] [源文件2] ... [目标目录]:复制多个文件到同一目标目录
cp a.txt b.jpg c.csv ./archive/ # 同时复制多个文件到 archive 目录cp -r [源目录] [目标路径]:复制目录(需加 -r 选项递归复制所有内容)
cp -r ./photos/ /media/backup/ # 复制 photos 目录及其中所有内容到 /media/backup常用选项:
-r或-R:递归复制目录(必须用于复制目录,否则会报错)-i:交互式操作,若目标文件已存在则提示是否覆盖-f:强制复制,若目标文件已存在则直接覆盖,不提示-v:显示复制过程的详细信息(verbose 模式)
使用示例:
cp text.txt text_copy.txt # 复制 text.txt 并在当前目录创建副本 text_copy.txt
cp -i data.csv ./backup/ # 复制 data.csv 到 backup 目录,若已存在则提示确认
cp -rv ./docs/ ./backup/ # 递归复制 docs 目录到 backup 并显示复制过程
cp *.txt ./txt_files/ # 复制当前目录所有 .txt 文件到 txt_files 目录注意事项:
- 复制目录时必须使用
-r选项,否则会提示错误 - 若目标路径是文件名,则会创建该名称的副本
- 若目标路径是目录,则会将源文件/目录复制到该目录下
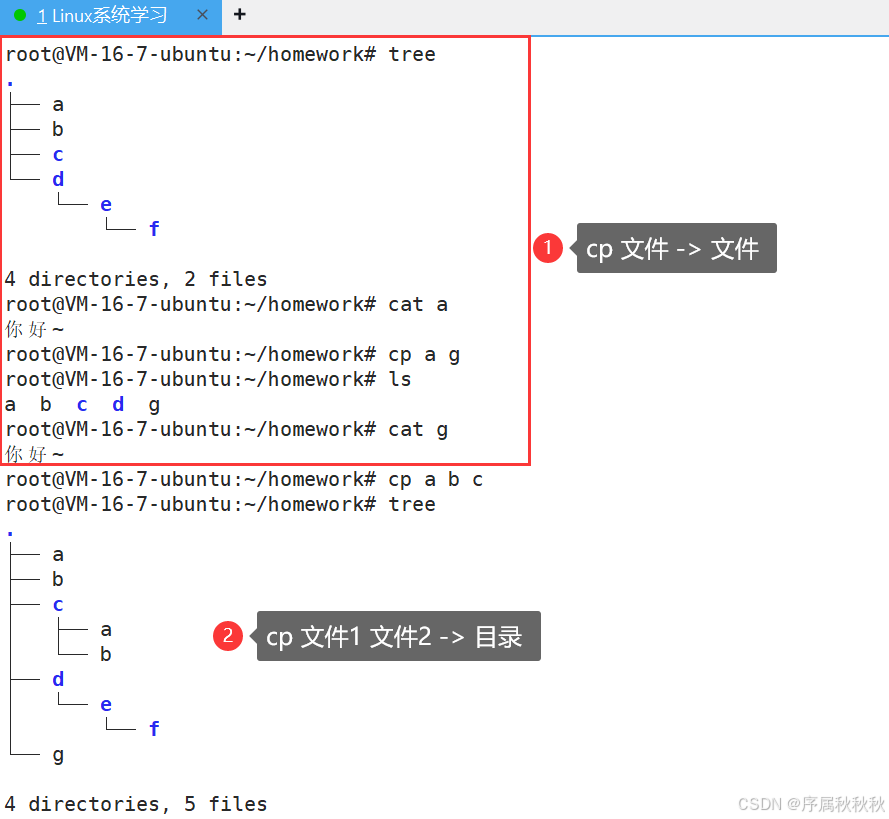
在这里插入图片描述
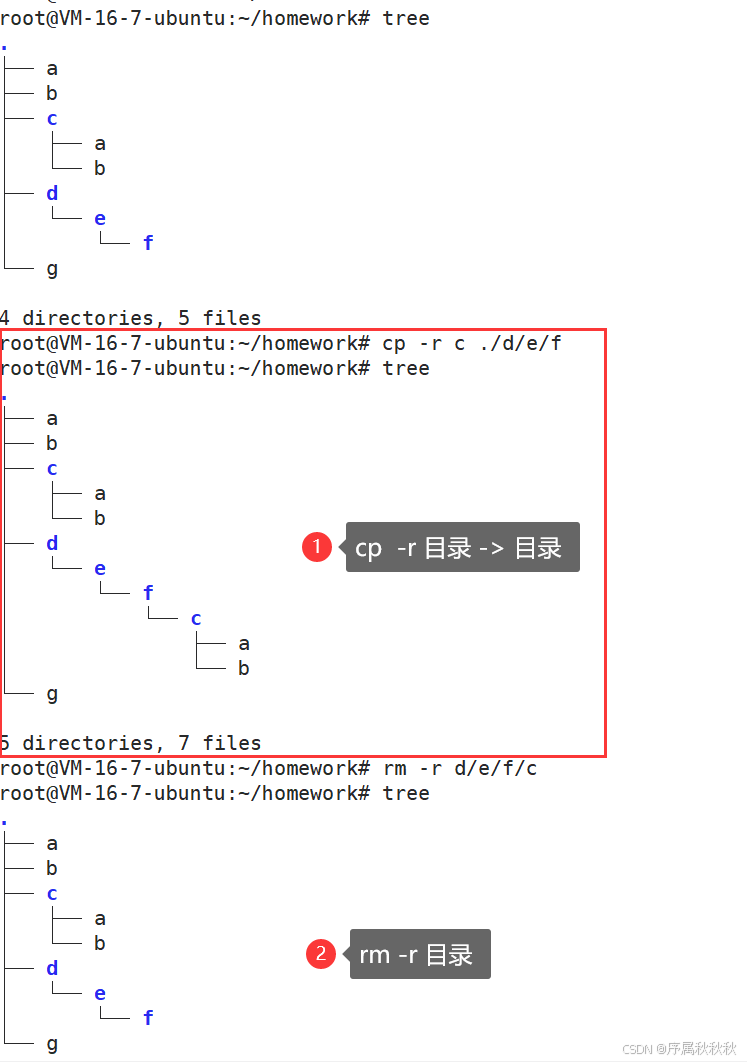
在这里插入图片描述
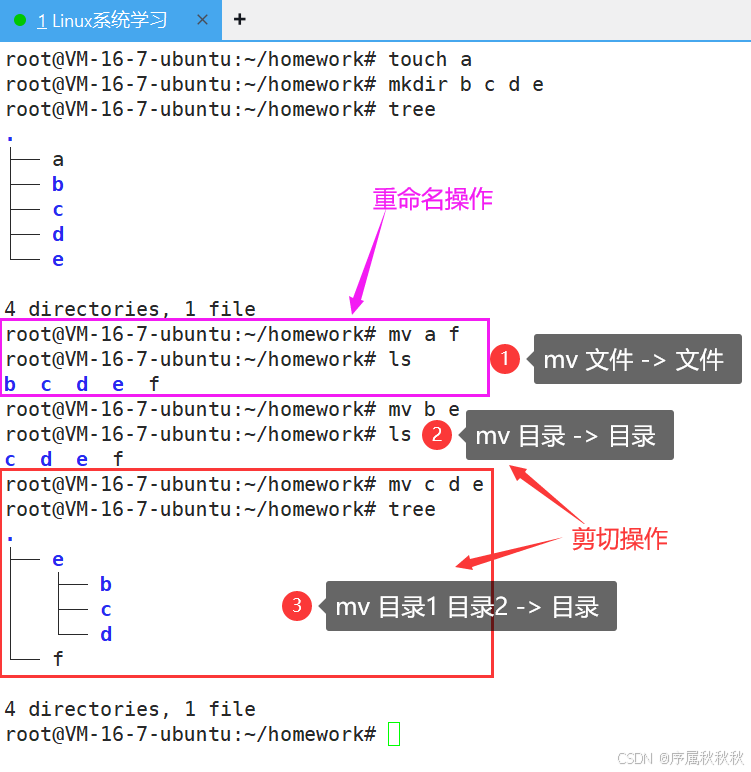
六、mv
mv - 英文全称为 “move”
核心作用:移动文件或目录,也可用于重命名文件或目录(本质是在同一位置移动并改名)
基本用法:
mv [源文件/目录] [目标路径]:将源文件 / 目录移动到指定目标路径
mv file.txt ./docs/ # 将 file.txt 移动到当前目录的 docs 子目录
mv ./images/ /home/user/ # 将 images 目录移动到 /home/user 目录下mv [源1] [源2] ... [目标目录]:将多个文件 / 目录移动到同一目标目录
mv a.txt b.jpg ./archive/ # 同时移动 a.txt 和 b.jpg 到 archive 目录mv [旧名称] [新名称]:重命名文件或目录(在同一目录下移动并改名)
mv old.txt new.txt # 将 old.txt 重命名为 new.txt
mv docs/ documents/ # 将 docs 目录重命名为 documents常用选项:
-i:交互式操作,若目标路径已存在同名文件/目录则提示是否覆盖-f:强制移动,若目标路径存在同名文件/目录则直接覆盖,不提示-v:显示移动过程的详细信息(verbose 模式)
使用示例:
mv report.pdf ./final/ # 将 report.pdf 移动到 final 目录
mv -i data.csv ./backup/ # 移动 data.csv 到 backup 目录,若存在则提示确认
mv -v old_dir/ new_dir/ # 重命名目录并显示操作信息
mv *.log ./logs/ # 将当前目录所有 .log 文件移动到 logs 目录注意事项:
- 移动目录时无需加递归选项(与
cp不同),直接使用即可 - 跨文件系统移动时,
mv实际会执行 “复制 + 删除” 操作,而非单纯移动指针 谨慎使用-f选项,避免误覆盖重要文件
在这里插入图片描述
------- 文件内容处理 -------
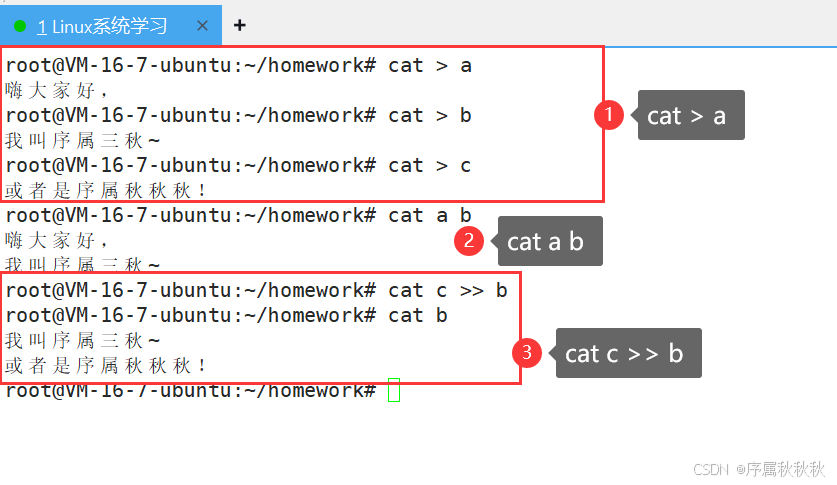
一、cat
cat - 英文全称为 “concatenate”
核心作用:查看文件内容、连接多个文件内容、创建新文件或向文件追加内容
基本用法:
cat [文件名]:显示指定文件的全部内容(适合查看内容较少的文件)
cat note.txt # 显示 note.txt 的内容
cat /etc/hosts # 显示系统 hosts 文件的内容cat [文件1] [文件2] ...:依次显示多个文件的内容,或连接后输出
cat part1.txt part2.txt # 先显示 part1.txt 内容,再显示 part2.txt 内容cat > [文件名]:创建新文件并输入内容(按 Ctrl+D 结束输入)
cat > newfile.txt # 创建 newfile.txt 并开始输入内容cat [文件1] >> [文件2]:将文件 1 的内容追加到文件 2 的末尾(不覆盖原内容)
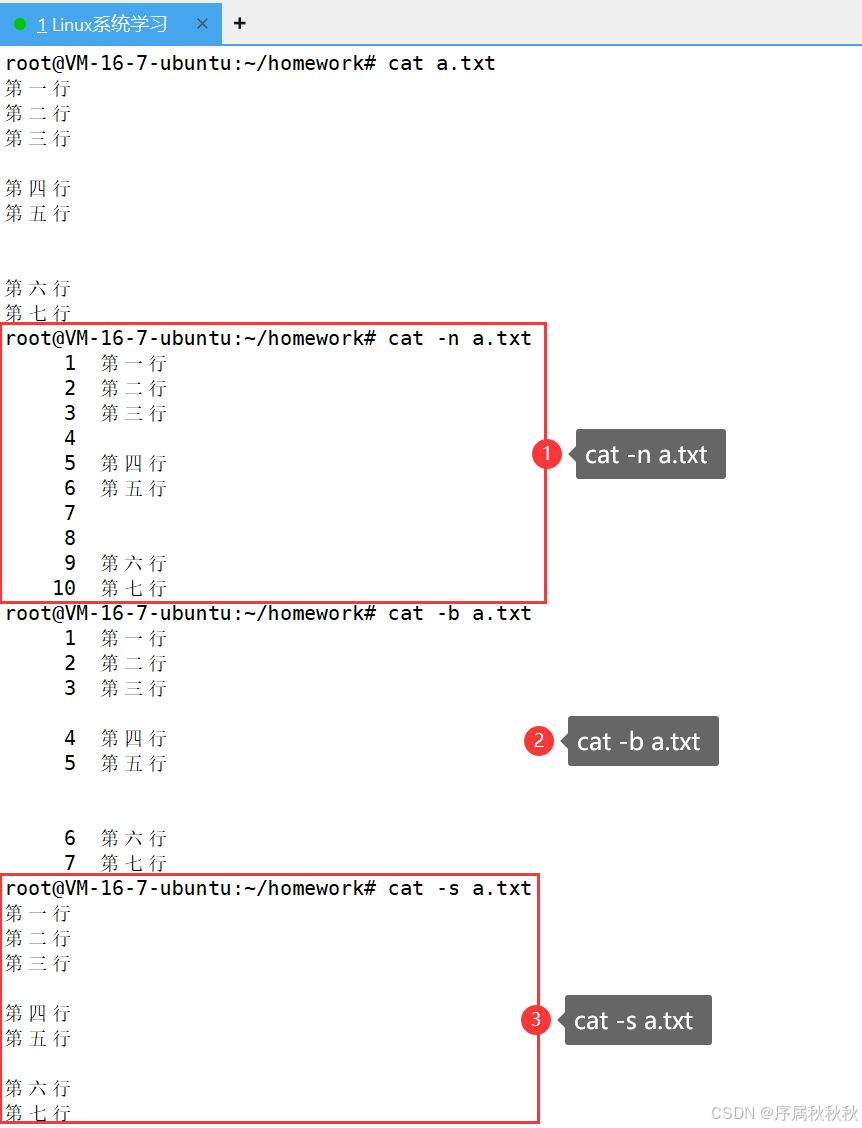
cat log1.txt >> total.log # 把 log1.txt 内容追加到 total.log 中常用选项:
-n:显示内容时为每一行添加行号(包括空行)-b:显示内容时为非空行添加行号(忽略空行)-s:将连续的多个空行压缩为一个空行-v:显示不可见字符(如:制表符、换行符等,除了换行符)
使用示例:
cat README.md # 查看 README.md 的内容
cat -n script.sh # 显示 script.sh 内容并带行号
cat -b data.txt # 为 data.txt 的非空行添加行号
cat file1.txt file2.txt > combined.txt # 合并两个文件内容到 combined.txt
cat >> notes.txt # 向 notes.txt 追加内容(输入后按 Ctrl+D 结束)注意事项:
cat适合查看小型文件,若文件过大(如:日志文件),使用less或more命令更合适(可分页查看)- 使用
cat > 文件名时,若文件已存在,会覆盖原有内容,需谨慎操作
在这里插入图片描述
在这里插入图片描述
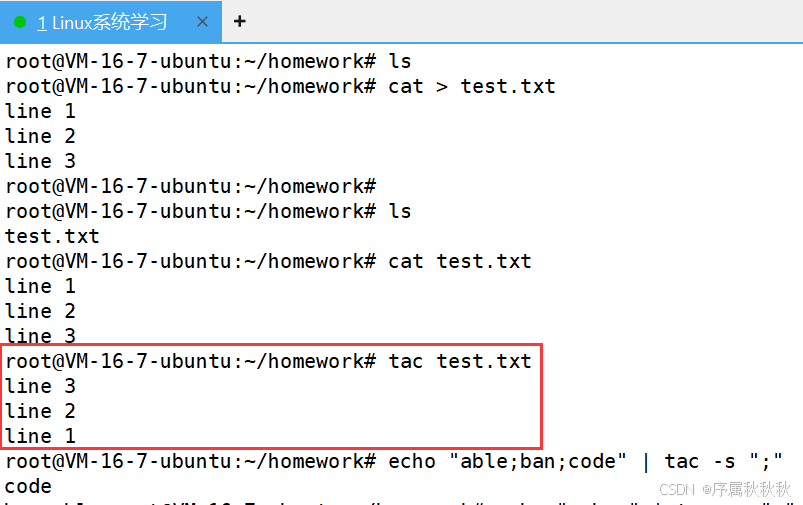
二、tac
tac - 英文可理解为 “cat reversed”
核心作用:按行反向输出文件内容,即从最后一行开始打印到第一行,与 cat 命令的顺序相反
基本用法:
tac [文件名]:反向输出指定文件的内容(从最后一行到第一行)
tac notes.txt # 反向输出 notes.txt 的内容tac [文件1] [文件2]:依次反向输出多个文件的内容(每个文件内部反向,文件之间顺序不变)
tac log1.txt log2.txt # 先反向输出 log1.txt,再反向输出 log2.txt常用选项:
-b:在每行前添加分隔符(默认在每行后添加,与cat -n类似但方向相反)-r:将分隔符视为正则表达式处理-s [字符串]:指定行分隔符(默认以换行符\n为分隔)
使用示例:
# 假设文件 test.txt 内容为:
# line 1
# line 2
# line 3
# 基本反向输出
tac test.txt
# 输出:
# line 3
# line 2
# line 1
# 多文件反向输出
tac a.txt b.txt # 先反向输出 a.txt 所有行,再反向输出 b.txt 所有行
# 结合管道使用(如反向查看日志最新内容)
cat /var/log/syslog | tac | head -5 # 先反向日志内容,再显示前5行(即原日志最后5行)
# 指定分隔符(以 ";" 为分隔反向输出)
echo "a;b;c" | tac -s ";" # 输出:c;b;a注意事项:
tac是cat的反向操作,名字也正好是cat的倒序拼写- 适合查看需要从末尾开始阅读的内容(如:日志文件最新条目、倒序排列的列表等)
- 与
rev命令的区别:tac按行反向(整体顺序颠倒),rev按字符反向(每行内部字符颠倒) - 对于大型文件,
tac效率可能低于cat,但仍能正常工作
在这里插入图片描述
三、more
more
核心作用:分页查看文件内容,是 Linux 中基础的分页工具,适用于内容较长、超出一屏的文件,按页逐步显示内容
基本用法:
more [文件名]:以分页方式显示指定文件的内容,默认从第一页开始
more /var/log/syslog # 分页查看系统日志文件
more long_document.txt # 分页查看长文档命令 | more:通过管道符接收其他命令的输出,并分页显示(常用于处理命令输出过长的情况)
ls -l /usr/bin | more # 分页显示 /usr/bin 目录的详细列表
cat large_file.txt | more # 分页显示 cat 命令输出的大文件内容常用选项:
+n:从文件的第n行开始显示(n为数字)
more +50 data.txt # 从 data.txt 的第 50 行开始查看-n:指定每页显示n行内容(默认根据终端窗口大小自动调整)
more -20 log.txt # 每页显示 20 行查看 log.txt交互操作:(在查看模式中使用)
- 按 空格:向下翻一页
- 按 Enter:向下翻一行
- 按 h:显示帮助信息(列出所有操作键)
- 按 q:退出
more查看模式(直接返回命令行) - 按 / 关键词:向下搜索指定关键词(部分版本支持,找到后按
n查看下一个结果)
使用示例:
more setup guide.txt # 分页查看名为 "setup guide.txt" 的文件(文件名含空格需加引号)
ps -ef | more # 分页查看系统进程列表
more +100 -30 report.txt # 从 report.txt 的第 100 行开始,每页显示 30 行注意事项:
more是早期的分页工具,功能相对简单,仅支持向前滚动(无法向上翻页),适合简单的分页需求- 对于需要频繁上下滚动或复杂搜索的场景,推荐使用功能更强大的
less命令
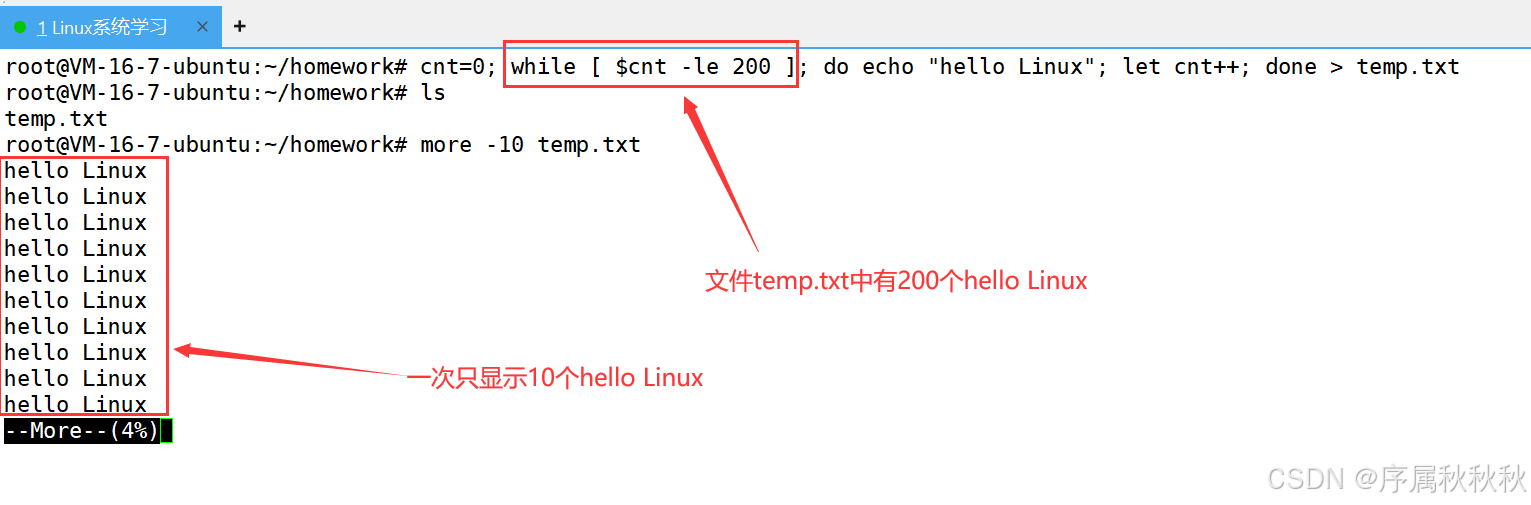
在这里插入图片描述
四、less
less
核心作用:分页查看文件内容,功能比 more 更强大,支持前后滚动、搜索等高级操作,适合查看大型文件
基本用法:
less [文件名]:以分页交互方式显示指定文件内容
less /var/log/messages # 分页查看系统消息日志
less large_document.txt # 分页查看大型文档命令 | less:通过管道接收其他命令输出并分页显示
ps aux | less # 分页查看进程列表
grep "error" *.log | less # 分页查看包含 "error" 的日志内容交互操作:(常用)
- 按 空格:向下翻一页
- 按 b:向上翻一页
- 按 Enter:向下翻一行
- 按 k:向上翻一行
- 按 /关键词:向下搜索关键词(按
n跳至下一个结果,N跳至上一个) - 按 ?关键词:向上搜索关键词
- 按 G:跳至文件末尾
- 按 g:跳至文件开头
- 按 q:退出
less查看模式 - 按 v:在默认编辑器中打开当前文件(需配置编辑器)
使用示例:
less -N bigfile.txt # 显示行号并分页查看 bigfile.txt
less +/ERROR app.log # 打开 app.log 并直接定位到第一个 "ERROR" 位置
history | less # 分页查看命令历史记录注意事项:
- 特点:less 不会一次性加载整个文件,对大型文件的处理效率更高,且支持双向滚动,是查看长文件的首选工具
五、head
head
核心作用:显示文件的开头部分内容,默认显示前 10 行,适合快速查看文件的起始信息
基本用法:
head [文件名]:显示指定文件的前 10 行内容
head log.txt # 显示 log.txt 的前10行
head /etc/passwd # 显示系统用户文件的前10行head [文件1] [文件2] ...:同时显示多个文件的开头部分,每个文件内容前会标注文件名
head file1.txt file2.txt # 分别显示 file1.txt 和 file2.txt 的前10行命令 | head:通过管道接收其他命令的输出,显示前 10 行结果
ls -l /usr/bin | head # 显示 /usr/bin 目录详细列表的前10行常用选项:
-n [数字]:指定显示文件的前n行(n为正整数)
head -n 5 data.txt # 显示 data.txt 的前5行
head -n 20 report.md # 显示 report.md 的前20行-c [数字]:按字节数显示文件开头部分(n为字节数,可加k、m等单位)
head -c 100 config.ini # 显示 config.ini 开头的100个字节
head -c 2k largefile.dat # 显示 largefile.dat 开头的2KB内容使用示例:
head -n 1 README.txt # 只显示 README.txt 的第一行(通常是文件说明)
head -n 0 access.log # 显示0行(实际作用是检查文件是否存在且可读取)
head -c 1024 *.txt # 显示当前目录所有 .txt 文件的前1024字节内容
ps aux | head -n 6 # 查看系统进程列表的前6行(含表头)注意事项:
- 当显示多个文件时,
head会在每个文件内容前添加==> 文件名 <==作为分隔标识 - 若文件行数少于指定的
n,则显示整个文件内容,不会报错 - 与
tail命令(显示文件末尾)配合使用,可灵活查看文件的不同部分

在这里插入图片描述
六、tail
tail
核心作用:显示文件的末尾部分内容,默认显示最后 10 行,常用于查看日志文件的最新记录或文件的结尾信息
基本用法:
tail [文件名]:显示指定文件的最后 10 行内容
tail log.txt # 显示 log.txt 的最后10行
tail /var/log/syslog # 显示系统日志的最后10行tail [文件1] [文件2] ...:同时显示多个文件的末尾部分,每个文件内容前会标注文件名
tail access.log error.log # 分别显示两个日志文件的最后10行命令 | tail:通过管道接收其他命令的输出,显示最后 10 行结果
ls -l /usr/bin | tail # 显示 /usr/bin 目录详细列表的最后10行常用选项:
-
-n [数字]:指定显示文件的最后n行(n为正整数) -
-f:实时跟踪文件内容的更新(常用于监控日志文件,按Ctrl+C退出) -
-F:与-f类似,但当文件被删除并重新创建后仍能继续跟踪(比-f更稳定) -
-c [数字]:按字节数显示文件末尾部分(n为字节数,可加k、m等单位)
使用示例:
tail -n 1 README.txt # 只显示 README.txt 的最后一行
tail -n +100 data.txt # 从第100行开始显示 data.txt 到末尾的内容(+表示从第n行起)
tail -f -n 50 server.log # 实时跟踪 server.log 的最后50行更新
ps aux | tail -n +2 # 查看系统进程列表,排除表头只显示进程信息注意事项:
-f选项非常适合监控实时生成的日志文件(如应用程序运行日志),能即时看到新写入的内容- 当显示多个文件时,
tail会在每个文件内容前添加==> 文件名 <==作为分隔标识 - 与
head命令配合,可灵活提取文件中间部分的内容(如:head -n 20 file.txt | tail -n 10提取第 11-20 行)
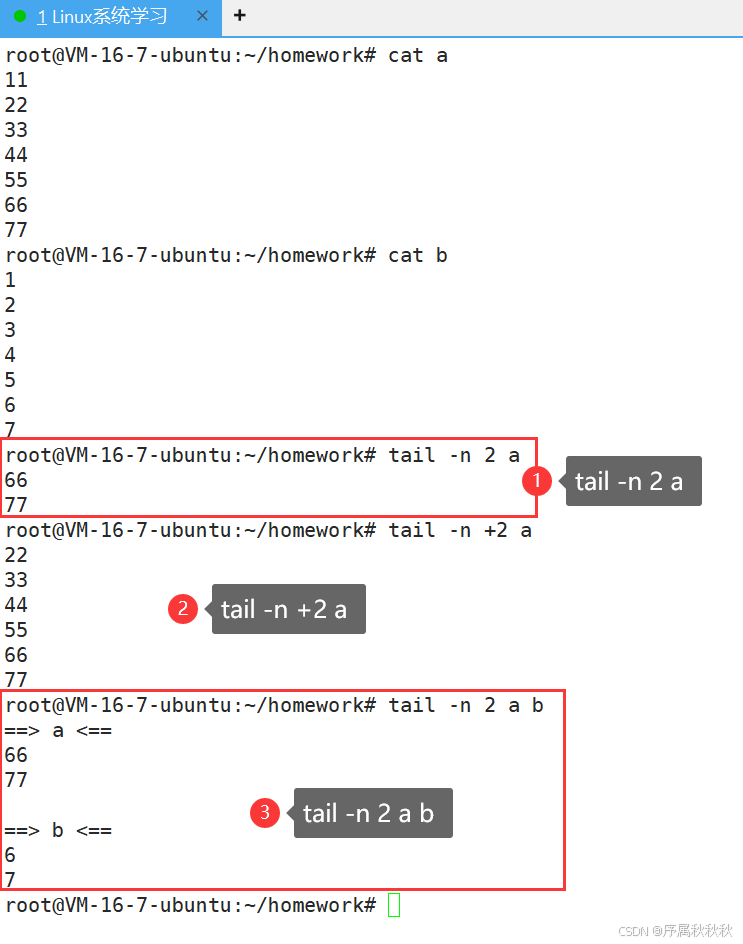
在这里插入图片描述
小技巧: 如何显示文件temp.txt中[180,200] 行的内容?
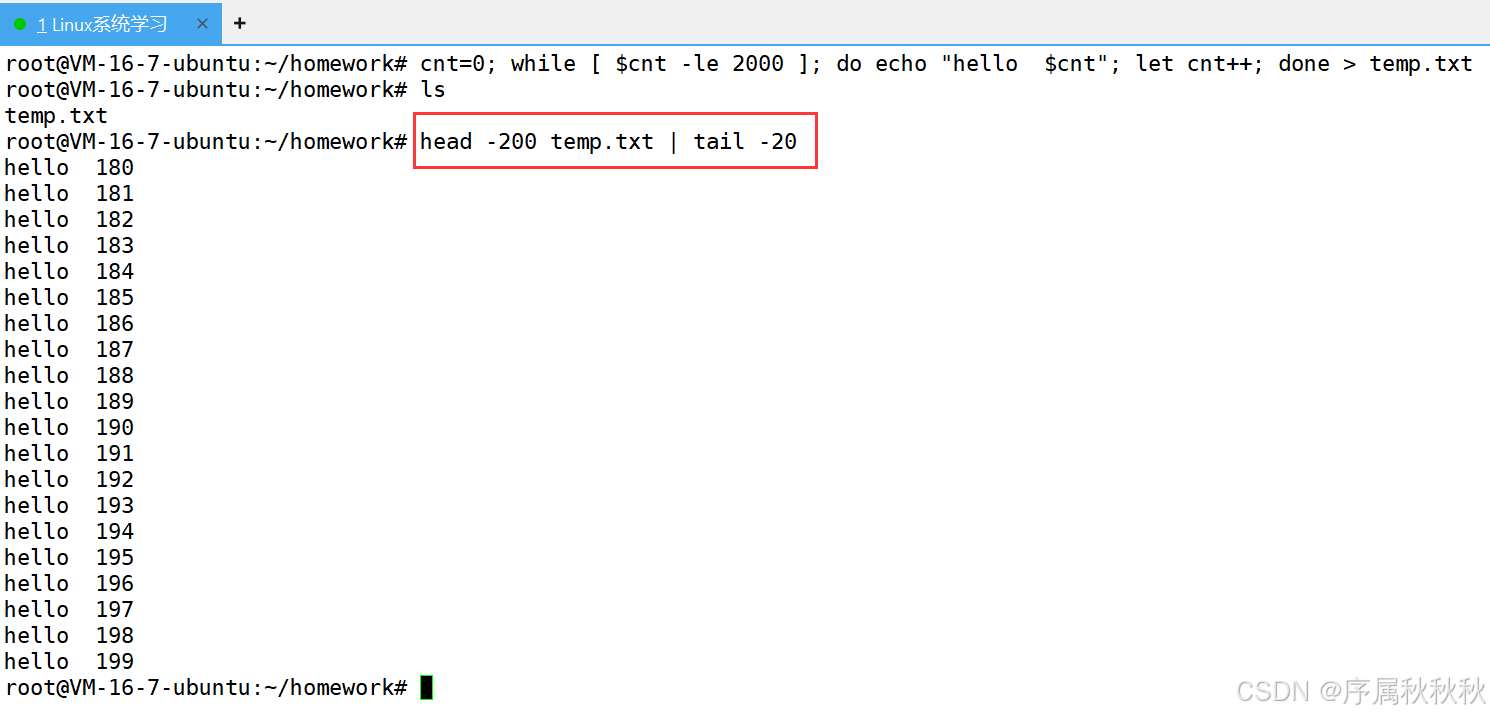
在这里插入图片描述
七、grep
grep - 英文全称为 “Global Regular Expression Print”
核心作用:在文件或命令输出中搜索符合指定模式(字符串或正则表达式)的内容,并打印匹配的行,是文本搜索的核心工具
基本用法:
grep [模式] [文件名]:在指定文件中搜索匹配模式的行
grep "error" app.log # 在 app.log 中搜索包含 "error" 的行命令 | grep [模式]:通过管道接收其他命令的输出,搜索匹配的行
ls -l | grep "txt" # 在 ls -l 的输出中搜索包含 "txt" 的行常用选项:
-i:忽略大小写(不区分大小写匹配)-v:反向匹配,只显示不包含模式的行-n:显示匹配行的行号-r或-R:递归搜索目录下的所有文件-w:匹配完整单词(避免部分匹配,如搜索 “cat” 不会匹配 “category”)-E:启用扩展正则表达式(支持|、()等元字符,等价于egrep)--color=auto:为匹配到的内容添加颜色高亮(多数系统默认开启)
使用示例:
grep -i "warning" system.log # 在 system.log 中搜索包含 "warning" 的行,忽略大小写
grep -nv "debug" app.log # 显示 app.log 中不包含 "debug" 的行,并显示行号
grep -r "config" /etc/ # 递归搜索 /etc 目录下所有文件中包含 "config" 的行
grep -w "user" /etc/passwd # 在 passwd 文件中搜索完整单词 "user"
ps aux | grep -E "nginx|apache" # 在进程列表中搜索包含 nginx 或 apache 的进程
grep "^error" log.txt # 搜索以 "error" 开头的行(^ 表示行首,正则表达式用法)
grep "end$" report.txt # 搜索以 "end" 结尾的行($ 表示行尾,正则表达式用法)注意事项:
- 模式中包含空格或特殊字符(如:
$、*)时,需用单引号或双引号包裹 - 搜索目录时必须使用
-r选项,否则grep会将目录视为普通文件并报错 - 正则表达式中的元字符(如:
.、*、+)需转义(加\)才能当作普通字符匹配,或使用-F选项禁用正则(等价于fgrep) - 对于大型文件或目录,可结合
-m [数字]选项限制匹配的最大行数,提高效率
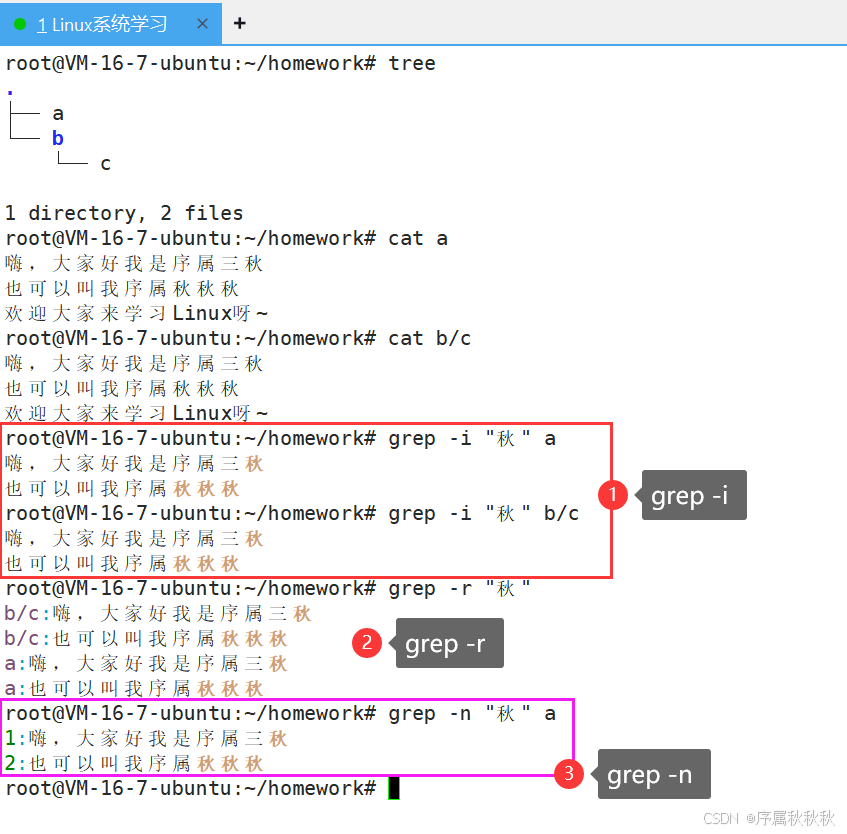
在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-10-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号