LLM 系列(十六):输出采样

LLM 系列(十六):输出采样

磊叔的技术博客
发布于 2025-11-24 09:06:35
发布于 2025-11-24 09:06:35
上一篇 LLM 系列(十五):Positional Encoding 中我介绍了 Transformer 模型中的位置编码,属于输入端,本文来主要来介绍下输出端的。
一、引言
我们每天都在与大型语言模型交互,观察它们逐字生成回应。这里有一个核心问题,就是在任意时刻,当模型已经生成了 "一只猫坐在" 之后,它是如何从数万个可能的词元(如 "垫子", "椅子", "地板")中选择出下一个词元的?这个选择的动作,就是本文的主题:输出采样(Sampling)。模型的这种概率性,既是其创造力的源泉,也是其不可靠性(幻觉)的根源。
本文将深入探究从模型内部计算到最终词元选择的完整流程,从经典的确定性策略,到构成现代 LLM 基石的随机采样策略。
二、从 Transformer 内部到概率分布
要理解所有采样策略,首先必须理解它们共同的输入,也就是覆盖全词汇表的最终概率分布,是如何在 Transformer 内部诞生的,这个过程可被拆解为一条四步流水线。
1、自注意力机制的上下文“混合”
首先,解码器接收所有已经生成的词元序列作为输入,在自注意力层中,模型会为序列中的每一个词元创建三个关键向量:Query (Q),Key (K) 和 Value (V) 。
- • Q (Query) 向量 代表:为了预测下一个词,我(当前词元)需要寻找什么样的信息?
- • K (Key) 向量 代表:我(这个词元)能提供什么样类型的信息?
- • V (Value) 向量 代表:我(这个词元)实际携带的信息是什么?
通过 Q 和 K 向量的点积计算注意力分数(Attention Scores),这决定了序列中每个词元对其他词元的关注度。这个分数经过 SoftMax 归一化后,再去加权 V 向量,最终这个过程会为序列中的每一个词元,都生成一个上下文感知的输出向量,即 隐藏状态 (Hidden State) 。
2、锁定最后一个词元的隐藏状态
自注意力步骤完成后,模型会得到一个(序列长度 x 隐藏层维度)的矩阵,其中每一行都代表一个词元在该上下文中的最终表示。为了预测下一个(第 N+1 个)词元,模型只需要第 N 个词元(即序列的最后一个词元)的隐藏状态。这是因为在解码器中,自注意力机制(通过 Causal Masking)确保了第 N 个词元的隐藏状态,已经吸收并混合了从第 1 个到第 N-1 个词元的所有上下文信息。无论序列多长,所有用于预测未来的信息都必须流经这个固定大小(例如 1x4096)的向量。这就意味着整个历史序列的语义,都被凝练到了这一个向量中。
3、LM Head 映射
我们现在有了一个处于 抽象语义空间 的向量(例如,维度为 4096),但我们需要的是在“具体词汇表空间”的得分(例如词汇表大小为 50,000);这时 LM Head 登场了,LM Head 本质上只是一个线性层(一个巨大的矩阵)。这个线性层通过一次矩阵乘法,将这个 4096 维的隐藏状态向量,映射到一个 50,000 维的向量上。这个新向量的每一个维度,都对应词汇表中的一个特定词元。
4、Logits 与 SoftMax
这个新生成的、维度等于词汇表大小的向量,就是 Logits。Logits 是模型对每个词元作为“下一个词”的原始、未归一化的分数。分数可正可负,总和不为,因此还不是概率。为了得到一个合法的概率分布,SoftMax 函数登场,它执行两个关键操作:
- 1. 指数化 (Exponentiation):对
Logits向量中的每一个分数取指数(),使得所有分数都变为正数,并且极大地放大了高分(最可能)和低分(不可能)之间的差距。 - 2. 归一化 (Normalization):将所有指数化后的分数相加,得到一个总和,然后用每个分数除以这个总和。
最终的输出是一个维度等于词汇表大小的概率分布,向量中的每个值都在 0 和 1 之间,且所有值的总和恰好为 1,这个概率分布,是后续所有采样策略的唯一输入。
三、 经典的确定性策略
有了概率分布,模型该如何选择?最直观的策略是确定性(Deterministic)策略,即总是试图选出最好的。
Greedy Search
贪心搜索是最简单的策略。在每一步,它都选择当前概率分布中概率最高的那个词元。其决策依据是 。
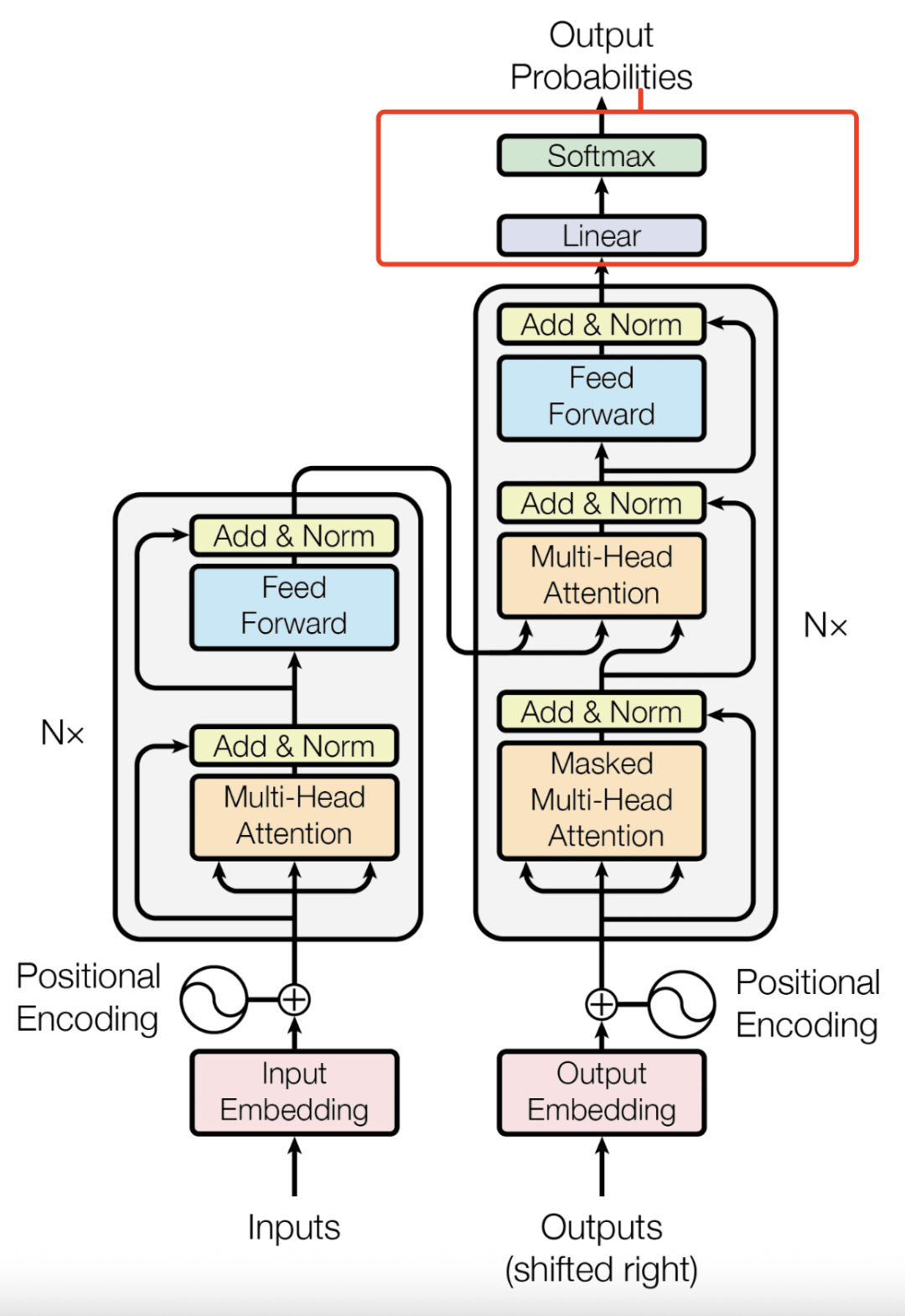
下面是一个示例:
- 1. 起始: 模型已生成 "The"。
- 2. Step 1: 模型预测下一个词元的概率分布为:{"nice": 0.5, "dog": 0.4,...}。
- 3. Greedy 选择: "nice" 的概率 (0.5) 最高。模型选择 "nice"。
- 4. 当前序列: "The nice"。
- 5. Step 2: 模型接收 "The nice",预测下一个词元的概率分布为:{"woman": 0.4, "car": 0.1,...}。
- 6. Greedy 选择: "woman" 的概率 (0.4) 最高。模型选择 "woman"。
- 7. 最终序列: "The nice woman"。
- 8. 序列总概率:。
Beam Search
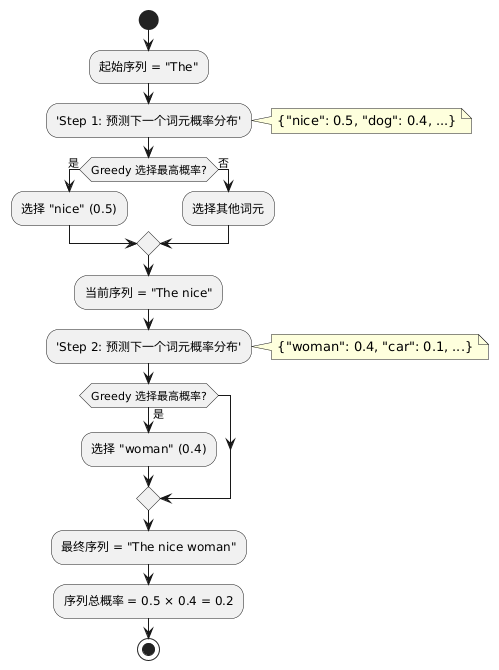
贪心搜索的“短视”在于,一个当前最优的选择(如 "nice" 0.5)可能会导向一个后续很差的路径。Beam Search 试图通过在每一步保留 (即 beam width,束宽)个最可能的序列来缓解这个问题。下面是一个 的 Step-by-Step 示例:
- 1. 起始: 模型已生成 "The"。
- 2. Step 1: 概率分布为:{"nice": 0.5, "dog": 0.4,...}。
- 3. Beam (k=2) 保留: 算法保留 个最高概率的选项。
- • 假设 1 (H1): "The nice" (序列总概率: 0.5)
- • 假设 2 (H2): "The dog" (序列总概率: 0.4)
- 4. Step 2 (扩展): 模型分别为 H1 和 H2 预测下一步:
- • 扩展 H1 ("The nice"): {"woman": 0.4, "car": 0.1,...}
- • "The nice woman" (总概率: )
- • "The nice car" (总概率: )
- • 扩展 H2 ("The dog"): {"has": 0.9, "ran": 0.2,...}
- • "The dog has" (总概率: )
- • "The dog ran" (总概率: )
- • 扩展 H1 ("The nice"): {"woman": 0.4, "car": 0.1,...}
- 5. Step 2 (筛选): 比较所有新生成的 4 个序列,只保留 个总概率最高的:
- • 保留 1: "The dog has" (0.36)
- • 保留 2: "The nice woman" (0.2)
- • ("The dog ran" (0.08) 和 "The nice car" (0.05) 被丢弃)
- 6. 最终序列 (若在此结束): Beam Search 会选择 "The dog has" (0.36),因为它找到了比贪心搜索 (0.2) 更优的全局路径。
经典策略的问题
Beam Search 的发明是为了解决贪心搜索的“短视”问题。它也确实成功地找到了概率更高的序列 ("The dog has" > "The nice woman");然而,这种对最高概率的极致追求,恰恰是其最大的短板。
Beam Search 的目标是最大化序列的联合概率,但在论文 《The Curious Case of Neural Text Degeneration》 中作者提到,在开放式文本生成中,最大化是一个错误的目标,模型(尤其是训练不完美的模型)倾向于给那些乏味、通用、甚至陷入循环的文本赋予极高的概率。
这导致了两个核心问题:
- • 文本退化与重复循环 (Text Degeneration):当 Beam Search (k 值设得很高时) 被要求生成长文本时,它会不可避免地陷入高概率的重复循环。例如,一个模型可能会生成 "...of the world to be a of the world to be a of the world to be a..."。因为它发现 "of the world to be a" 这个序列组合的概率,比任何“有意义”的新词都要高。
- • 缺乏多样性 (Lack of Diversity):Beam Search 本质上是确定性的,给定相同的输入,它几乎总是产生相同的输出,这导致了生成的文本虽然“安全”,但极其“无聊”和“平淡”(Bland)。
Degeneration 论文的核心发现是:人类书写的文本(Natural Language)的平均概率,反而低于 Beam Search 生成的文本。人类倾向于避免“显而易见”的高概率词,因为信息量低,从而选择信息量更高、但概率稍低的词。Beam Search 这种最大化策略,算是直接惩罚了这种人类特有的创造性。
确定性策略的弊端告诉我们:要生成“像人”的文本,我们不能总是选“最好”的,而要开始随机地选合理的。
四、随机采样策略
为了解决“文本退化”问题,业界引入了“随机采样”(Stochastic Sampling)。其核心思想是,不再总是选择最优的,而是根据概率分布,随机地选择一个“合理”的答案。
温度采样 (Temperature Sampling)
温度采样 (Temperature, T) 是一个超参数,它在 Softmax 之前,通过缩放 Logits 来重塑最终的概率分布 。其修改后的 Softmax 公式为:
假设在词汇表中,两个词元的 Logits 为 [1.0, 3.0] 。
- 1. Case 1: T=1 (标准 Softmax)
- •
Logits不变:[1.0, 3.0] - • 概率分布:
[0.12, 0.88](模型非常自信地选择 B)
- •
- 2. Case 2: T=0.5 (低温 -> 锐化)
- •
Scaled Logits:[1.0/0.5, 3.0/0.5] = [2.0, 6.0](高分和低分的差距被拉大) - • 概率分布:
[0.02, 0.98](模型更加自信,分布更“尖锐”,结果更接近 Greedy Search)
- •
- 3. Case 3: T=2.0 (高温 -> 平滑)
- •
Scaled Logits:[1.0/2.0, 3.0/2.0] = [0.5, 1.5](高分和低分的差距被缩小) - • 概率分布:
[0.27, 0.73](分布更“平坦”,A 被选中的机会显著增加,从而增加了“随机性”和“创造性”)
- •
总结: 使模型更保守、更自信; 使模型更大胆、更多样。 等价于 Greedy Search。
Top-K 采样
Top-K 采样不改变概率形状,而是改变候选集。
- 1. 模型生成完整的概率分布。
- 2. 算法对所有词元按概率排序。
- 3. 只保留概率最高的 K 个词元。
- 4. 丢弃词汇表中所有其他词元。
- 5. 对这 K 个词元的概率进行“重新归一化”(Renormalization),使它们的新概率总和为。
- 6. 在这 K 个词元中,根据它们的新概率进行随机采样。
核心问题: K 值是固定的,无法自适应。
- • 当分布“尖锐”时 (Sharp Distribution):如预测 "中国的首都是...","北京" 的概率可能是 0.99。此时 K=40 太大了,候选池里会混入 39 个“垃圾”词元,模型可能会随机选到它们,导致事实性错误。
- • 当分布“平坦”时 (Flat Distribution):如预测 "这部电影是..", "好", "坏", "还行", "糟糕" 的概率可能都很接近。此时 K=40 太小了,可能会截断掉很多同样合理的、有创造力的词元,限制了多样性。
Top-P (Nucleus) 采样
Top-P 采样(又称 Nucleus Sampling,核采样)正是为了解决 Top-K 的上述问题而设计的,它也源自 《The Curious Case of Neural Text Degeneration 》这篇论文。
Top-P 使用一个动态的候选集,其算法如下:
- 1. 模型生成完整的概率分布。
- 2. 算法对所有词元按概率排序(从高到低)。
- 3. 设定一个阈值 P (例如 P=0.9),代表“概率质量”的累积阈值。
- 4. 从最高概率的词元开始,累加它们的概率,直到这个“累积概率”达到或超过 P。
- 5. 所有被累加的词元,构成了“概率核”(Nucleus)。
- 6. 丢弃所有不在这个“核”内的词元。
- 7. 对“核”内的词元概率进行重新归一化,并从中采样。
数值示例: 假设 P=0.8,词元概率如下:
{"the": 0.5, "a": 0.2, "cat": 0.1, "dog": 0.1, "eats": 0.1}- • 排序: 已按顺序。
- • 累加:
- • "the" (0.5) -> 累积 = 0.5 (未达到 0.8)
- • "a" (0.2) -> 累积 = 0.5 + 0.2 = 0.7 (未达到 0.8)
- • "cat" (0.1) -> 累积 = 0.7 + 0.1 = 0.8 (达到 0.8,停止)
- • Nucleus (核):
{"the", "a", "cat"}。 - • 丢弃:
{"dog", "eats"}。 - • 新分布: P(the) = 0.5/0.8 = 0.625; P(a) = 0.2/0.8 = 0.25; P(cat) = 0.1/0.8 = 0.125。
为何 Top-P 优于 Top-K: 它的候选集大小是动态的。
- • 在“尖锐”分布时: "北京" (0.99)。若 P=0.9,则 Nucleus 仅包含
{"Paris"}。候选集大小自动缩小到 1。 - • 在“平坦”分布时: "这部电影是.."。P=0.9 可能需要累加 50 个词元才能达到。候选集大小自动扩大到 50。
Top-P 成功地“截断”了模型概率分布中那个“不可靠的长尾”(unreliable tail),只在模型真正自信的、占绝大多数概率的“核”中进行采样。
采样策略对比
策略 | 核心思想 | 优势 | 主要缺陷 |
|---|---|---|---|
Greedy Search | 始终选择 P(max) | 速度最快,完全确定 | “短视” ,极易产生重复和“退化”文本 |
Beam Search | 保留 K 个 P(max) 序列 | 比 Greedy 更优,能找到概率更高的序列 | 依然是确定性 ,“最大化”目标错误 ,导致重复循环 |
Temperature | 缩放 Logits (T) | 控制“创造力” ,T>1 增加多样性,T<1 增加确定性 | T 过高则语无伦次;它重塑分布,但不截断长尾 |
Top-K | 固定 K 个候选集 | 简单、有效,截断了“垃圾长尾” | K 值“一刀切”,无法适应分布的“胖瘦” |
Top-P (Nucleus) | 动态 P 值“概率核” | 自适应候选集大小 ,完美解决 K 的问题,截断“不可靠长尾” | 原理稍复杂 |
工程实践中的采样参数
在实际应用中,Temperature, Top-K, Top-P 经常被组合使用.
组合使用的“执行顺序”
当 T, K, P 同时使用时
- 1. T (Temperature) Scaling: 首先,原始
Logits除以T。 - 2. Softmax: 应用
Softmax,得到“调整后”的概率分布。 - 3. K (Top-K) Filtering: 接着,从该分布中筛选出
Top-K个词元(例如 K=100)。 - 4. P (Top-P) Filtering: 然后,在这 K 个词元中,再应用
Top-P进一步筛选(例如 P=0.9),得到最终的“核”。 - 5. Renormalize & Sample: 对这个最终的、最小的“核”进行归一化和采样。
这个执行顺序并非随意,而是一个优化的过滤级联(filtering cascade); 先用 Top-K(例如 K=100)进行“粗筛”,再用 Top-P(P=0.9)进行“精筛”。这使得 Top-P 的排序和累加计算不需要在整个 50K 的词汇表上执行,而只需要在 K=100 的小集合上执行,这在计算上是极大的优化。
调优的经验法则与挑战
这些参数的组合空间巨大,且它们的效果高度依赖于模型本身和特定任务。
- • 经验法则1: “只调 T 或 P,不同时调”。
- • 原因:
T和P都在试图控制“多样性/确定性”这个主轴。对于大多数简单应用,同时调整两者会使结果难以预测。 - • 建议: 创意任务(如写诗)用高
T(e.g., 0.8-1.0) 或高P(e.g., 0.95-0.99)。事实任务(如Q&A)用低T(e.g., 0.2) 或低P(e.g., 0.1) 。
- • 原因:
- • 经验法则 2 (T=0 等于 Greedy): 任何时候将
T设为 0 (或极低),或者K=1,或者P=0(或极低),都等同于(或近似于)Greedy Search。 - • 性能瓶颈 : 所有的采样策略都受限于“自回归”这个瓶颈,每一步都必须等待上一步完成,这导致了
LLM推理的“高延迟”,调优这些参数不会解决这个根本的延迟问题。
五、总结
本文从 Transformer 解码器内部(Q/K/V)出发,跟踪了数据(隐藏状态)如何流经 LM Head 变成 Logits,再通过 Softmax 成为概率分布。我们分析了经典策略(Greedy, Beam)为何失败,因为它们追求的“最大概率”目标本身就是导致“文本退化”的根源。
当前 LLM 的流畅性和创造力,来源于随机采样策略(Temperature, Top-K, Top-P)。这些策略,特别是 Top-P (Nucleus) ,通过巧妙地截断和重塑概率分布,迫使模型在“合理”的候选集(Nucleus)中进行随机选择,从而避免了重复循环,注入了必要的多样性。
LLM 的输出采样,是一场在“确定性”与“随机性”之间的精妙平衡。没有标准答案,只有面向特定任务的“最优调优”。而我们今天讨论的所有策略,都还只是在解决“如何选词”;而“如何更快地选词”,则是留给“推测解码”(Speculative Decoding)等下一代技术的新命题。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号