用腾讯云 CNB 搭建 Maven 制品库,竟如此简单!!再也不用再死磕Maven中央仓库了
原创
用腾讯云 CNB 搭建 Maven 制品库,竟如此简单!!再也不用再死磕Maven中央仓库了
原创
HELLO程序员
发布于 2025-11-14 14:30:37
发布于 2025-11-14 14:30:37
每次用 Maven 中央仓库拉依赖,都像在跟网速 “掰手腕”—— 要么慢悠悠转圈圈,要么直接爆红报错,心态分分钟崩掉!尤其是赶项目 deadline 的时候,卡在哪一步都想原地跺脚:“这破仓库能不能给力点!”
直到我挖到了腾讯云 CNB 这个 “宝藏制品库”,才发现原来管理 Maven 依赖可以这么丝滑!比中央仓库快到飞起,还能私有部署防泄露,甚至支持 Gradle 本地推送 APK 包,简直是研发人的 “效率救星”~ 今天就用最接地气的方式,手把手教你搭建,全程无废话,小白也能轻松上手!
为啥放弃 Maven 中央仓库?
先别急着动手,咱们先聊聊:为啥非要换掉用了多年的 Maven 中央仓库?说多了都是泪啊!
中央仓库服务器在国外,国内访问经常 “卡壳”,拉一个大点的依赖包,喝杯奶茶回来还没好,摸鱼都不踏实;
公开仓库里的依赖包良莠不齐,一不小心下载到恶意包,项目直接 “中招”,排查起来头都大;
自己写的工具类、项目依赖,想共享给团队用,放中央仓库不安全,搭私人仓库又嫌麻烦,左右为难!
而腾讯云 CNB 制品库直接把这些坑全填了:国内节点加速,拉依赖秒级响应;私有部署 + 权限管控,数据安全拉满;还能兼容 Maven、Gradle,甚至支持各种格式的制品管理,简直是 “全能选手”!
3 步搞定前置条件,零门槛起步!
在动手搭建之前,咱们先把 “装备” 备齐,超简单,不用复杂操作:
没有的话去官网注册一个,实名认证一下,免费额度完全够个人和小团队用,不用心疼钱;
登录腾讯云控制台,搜 “CNB” 找到对应服务,一键开通就行,流程跟开通会员一样简单;
mvn -v
gradle -v搞定这些,咱们就可以正式 “开工” 啦!
图片
3分钟搞定 Maven 制品库
第一步:创建 Maven 制品库,像建文件夹一样简单
登录腾讯云 CNB 控制台,找到 “制品库管理”,点击 “新建制品库”;
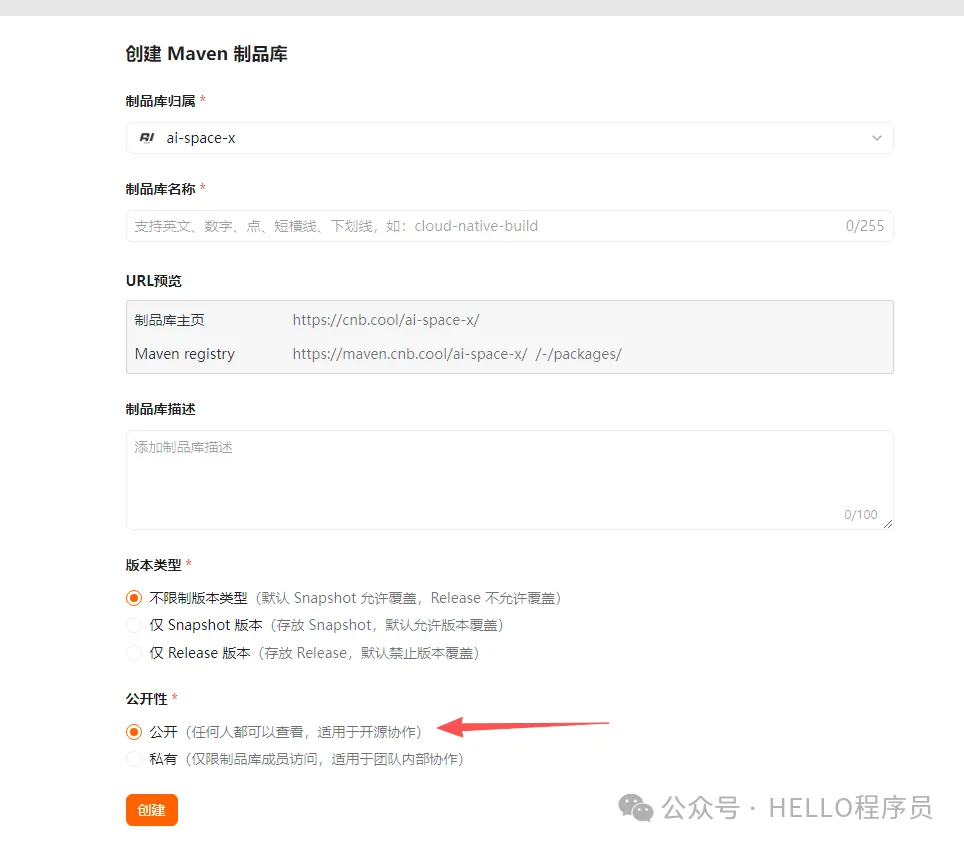
填写基本信息:名称随便起(比如 “我的 Maven 仓库”),类型选 “Maven”,存储类型“公开”(开源项目推荐) “私有”(团队用更安全),描述随便写两句,点击 “确认创建”;
https://cnb.example.com/repository/my-maven/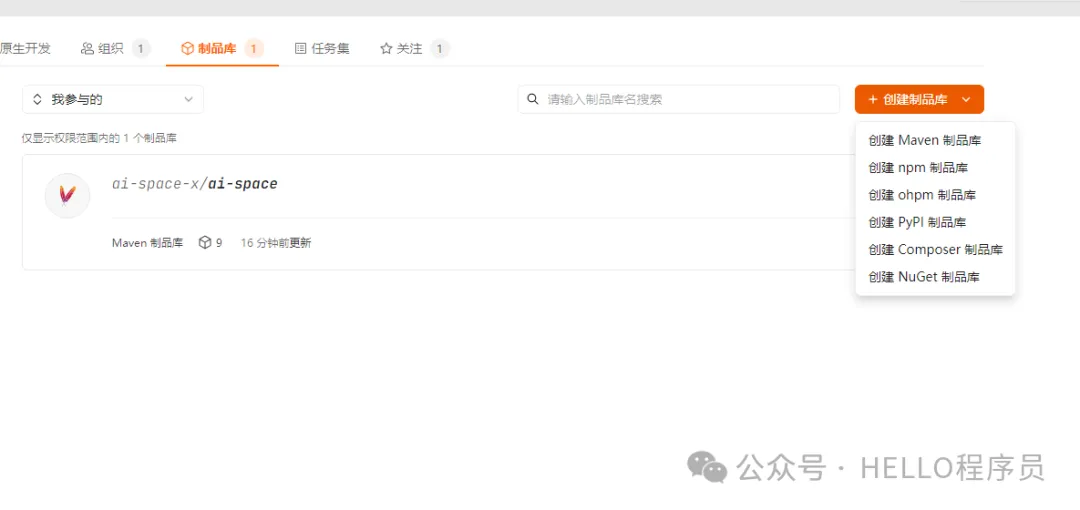
图片
图片
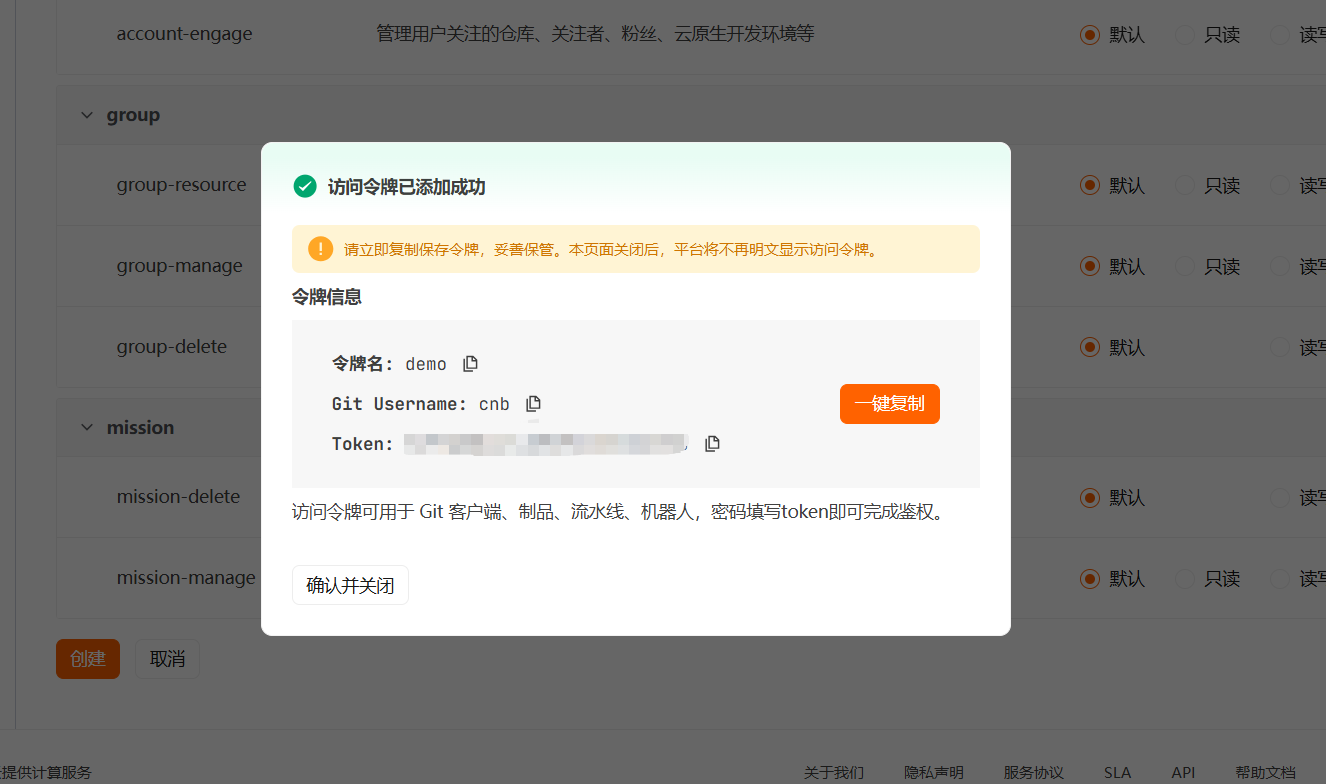
配置凭据
将 server、repo 配置添加到 settings.xml 中, <your_token>为访问令牌 (令牌常见场景需勾选制品库)
<settings>
<servers>
<server>
<id>cnb-maven</id>
<username>cnb</username>
<!-- 请替换为您的访问令牌 -->
<password><your_token></password>
</server>
</servers>
<profiles>
<profile>
<id>ai-space-x-ai-space-profile</id>
<repositories>
<repository>
<!-- 须与 server 的 id 一致 -->
<id>cnb-maven</id>
<!-- 替换为制品库地址 -->
<!-- 示例
<url>https://maven.cnb.cool/cnb/maven_repo/-/packages/</url>
-->
<url><REPO_URL></url>
</repository>
</repositories>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
</profile>
</profiles>
</settings>推送制品
在 pom.xml 中配置发布仓库及制品属性,需要先完成 配置凭据
<!-- 发布仓库 -->
<distributionManagement>
<repository>
<!-- 须与 settings.xml 中 server 的 id 一致 -->
<id>cnb-maven</id>
<name>cnb-maven</name>
<!-- 示例
<url>https://maven.cnb.cool/cnb/maven_repo/-/packages/</url>
-->
<url><REPO_URL></url>
</repository>
</distributionManagement>执行发布命令,推送制品
mvn deploy推送完成后就能在制品库见到推送的public的maven包
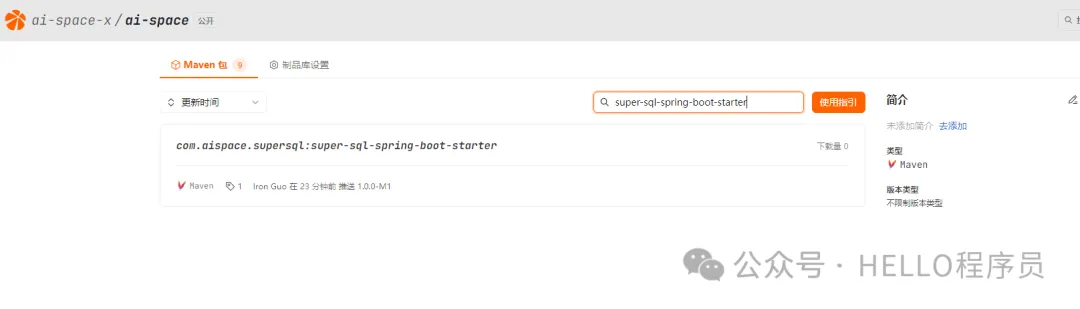
图片
拉取制品
将制品库配置添加到 pom.xml 中
<repositories>
<repository>
<id>ai-space-x-ai-space</id>
<url>https://maven.cnb.cool/ai-space-x/ai-space/-/packages/</url>
</repository>
</repositories>测试一下
将 denpendency 配置添加到 pom.xml 中
<dependency>
<groupId>com.aispace.supersql</groupId>
<artifactId>super-sql-spring-boot-starter</artifactId>
<version>1.0.0-M1</version>
</dependency>docker启动本地chroma
docker run -it --rm --name chroma -p 8000:8000 ghcr.io/chroma-core/chroma:1.0.0配置SuperSQL的配置文件
spring:
ai:
azure:
openai:
api-key: xxxxxxxxxxxxxx
chat:
options:
deployment-name: gpt-4o-latest
endpoint: https://your-resource-name.openai.azure.com/
embedding:
options:
deployment-name: embedding-ada-002
vectorstore:
chroma:
client:
host: http://127.0.0.1
port: 8000
collection-name: super-sql
initialize-schema: true 配置init-train配置项,默认为false,表示不进行训练,如果为true,则自动根据数据库连接配置进行全表训练。scope代表是否整库训练,schemas代表对应的库
super-sql:
init-train: true
scope: ALONE #ALONE单库训练,ALL 整库训练
schemas:
- demo_db #待训练的库编写测试代码
@PostMapping("/getSql")
public ResponseResult<String> getSql(@RequestBody ChatBO chatBO) {
String sql = sqlEngine
.setChatModel(chatModel)
.setOptions(RagOptions.builder().topN(10).rerank(true).limitScore(0.4).build())
.generateSql(chatBO.getQuestion());
return ResponseResult.success(sql);
}postman请求已成功集成SuperSQL的能力
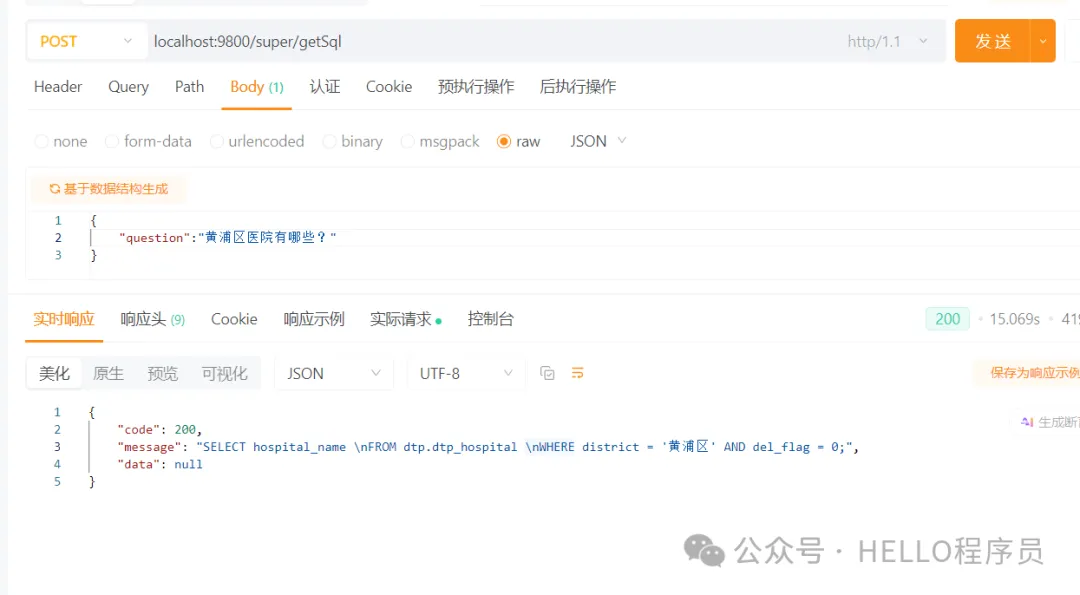
图片
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号