AI智能体的阅读笔记:来自国外大佬的2篇技术爽文


前言
最近阅读了几篇国外大佬写的技术文章
- 《Why I'm Betting Against AI Agents in 2025》
- 《Building-Effective-Agents》
更加搞懂了:什么是智能体,什么是工作流,什么是自动化?
Anthropic(Anthropic PBC,是一家美国的人工智能(AI)初创企业和公益公司,由OpenAI的前成员创立。),他们公司提出明确定义,区分了工作流和大模型的区别:
🤖 Workflows vs Agents: What’s the Difference? Workflows = Predefined, coded paths where LLMs and tools follow a fixed structure. Agents = LLMs that dynamically control their own process and tool usage. They make decisions on-the-fly based on the current state of the task. https://www.anthropic.com/engineering/building-effective-agents
那么工作流是怎么样的呢?
工作流 AI大模型和工具,通过预定义的代码路径,进行编排的系统(平时99%的商业化产品,比如扣子、dify,通过特定的步骤和链条,在某个节点调用了AI大模型)。
提示词工作流(The prompt chaining workflow)的适用范围是:可以轻松清晰地分解为固定子任务的情况,主要目标是通过简化每次 LLM 调用,以降低延迟并提高准确率。
落地示例:
- 生成营销文案,然后将其翻译成不同的语言。
- 编写文档大纲,检查大纲是否符合某些标准,然后根据大纲编写文档。
那么真正智能体是怎么样的呢?
智能体 AI大模型自己指导自己的流程,以及对工具的使用,并且保持对整个系统的控制器。
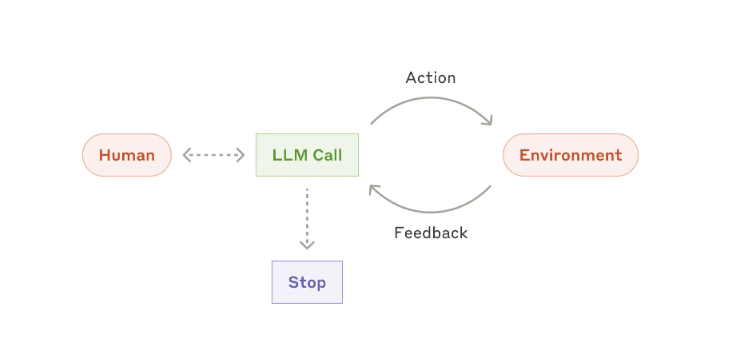
更加详细的定义:
Agents are emerging in production as LLMs mature in key capabilities—understanding complex inputs, engaging in reasoning and planning, using tools reliably, and recovering from errors.
随着 LLM 在理解复杂输入、进行推理和规划、可靠地使用工具以及从错误中恢复等关键能力方面的日趋成熟,智能体正在越来越多的投入生产。
Agents begin their work with either a command from, or interactive discussion with, the human user. Once the task is clear, agents plan and operate independently, potentially returning to the human for further information or judgement.
智能体的工作始于人类用户的指令或与人类用户的互动讨论。
一旦任务明确,智能体就会独立规划和运行,并可能返回给人类用户以获取更多信息或判断。
During execution, it's crucial for the agents to gain “ground truth” from the environment at each step (such as tool call results or code execution) to assess its progress.
在执行过程中,智能体必须在每个步骤(例如工具调用结果或代码执行)从环境中获取“基本事实”以评估其进度。
Agents can then pause for human feedback at checkpoints or when encountering blockers. The task often terminates upon completion, but it’s also common to include stopping conditions (such as a maximum number of iterations) to maintain control.
然后,智能体可以在检查点或遇到阻碍时暂停以等待人类的反馈。任务通常在完成后终止,但通常也会包含停止条件(例如最大迭代次数)以保持控制。
Agents can handle sophisticated tasks, but their implementation is often straightforward. They are typically just LLMs using tools based on environmental feedback in a loop. It is therefore crucial to design toolsets and their documentation clearly and thoughtfully.
Agent可以处理复杂的任务,但它们的实现通常很简单。它们通常只是基于环境反馈循环使用工具的LLM。因此,清晰周到地设计工具集及其文档至关重要。
小结
这种智能体模式就是Autonomous agent,AI在循环过程中,反复迭代,直到满足结果,人类不参与其中。举例子,两个名副其实的智能体
- manus智能体:被媒体宣传为AI软件工程师
- 基础智能体:号称解决所有工作量(实际上效果不太好,20个任务,只有个位数成功)
对比工作流和智能体:
- 工作流只能做人类原来就可以做的事,依赖人原来的思路和流程,目的是提高效率。
- 智能体则可以创造新的思路和流程,比如:著名的AlphaGo-围棋37手。
什么时候使用智能体,什么时候选择工作流?
在商业化过程中,我们应该尽可能找到简单高效的解决方案。只有必要的时候,才增加其复杂性。换而言之,我们或许不需要构建智能体系统。很多商业化应用,在某个逻辑节点调用大模型就已经足够了。(绝大部分开发者都同意,千真万确)
我们的业务肯定早已形成了稳定的工作流程了,我们要做的只是对某些节点自动化,提升效率。
开发智能体有哪些坑?
错误复合效应
智能体演示Demo:5个步骤以内的简单任务
真实生活:往往有10+步骤,整体执行效果会出现巨大落差,得不到预期效果
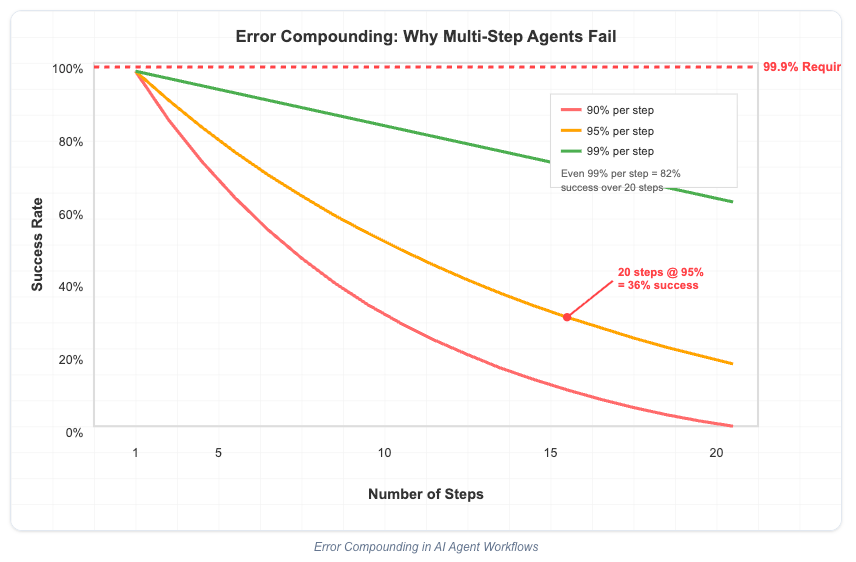
如上图所示,一个大模型执行任务的准确率是95%,那么连续执行15~20个步骤,你猜准确率会是多少?没错,准确率会锐减到36%以下了(95%的20次方),意味着可能在复杂问题处理过程中,Agent会在某个步骤有2/3的概率掉链子。。
意味着,即使提示词写的再好,也无法颠覆这个客观的数学规律,你放心把工作交给一个有2/3的概率搞砸的工具吗?
如何兜底呢?
不追求全自动化,而是补充人工检查和确认的步骤。
The dirty secret of every production agent system is that the AI is doing maybe 30% of the work. The other 70% is tool engineering: designing feedback interfaces, managing context efficiently, handling partial failures, and building recovery mechanisms that the AI can actually understand and use. https://utkarshkanwat.com/writing/betting-against-agents
上下文烧钱-平方成本诅咒多轮会话
There is another mathematical reality that agent evangelists conveniently ignore: context windows create quadratic cost scaling that makes conversational agents economically impossible.
代理布道者很容易忽略另一个数学现实:上下文窗口会产生二次成本缩放,从而让对话代理在经济上变得不可能。
Here is what actually happens when you build a agent: Each new interaction requires processing ALL previous context Token costs scale quadratically with conversation length A 100-turn conversation costs $50-100 in tokens alone Multiply by thousands of users are looking at unsustainable economics
以下是构建“对话”代理时实际发生的情况:

Token Cost Scaling in Conversational Agents
- 每次新的互动都需要处理所有先前的上下文
- 代币成本与对话长度呈二次方关系
- 一次 100 轮对话仅代币成本就高达 50-100 美元
- 乘以数千名用户,你就会发现经济效益是不可持续的
经验分享
老外大神在整个软件开发生命周期中构建了十几个不同的Agent系统之后,总结了一些经验和模式:
- UI 生成Agent:每个生成的界面在部署之前都会经过人工审核。AI 负责处理将自然语言翻译成 React 功能组件的复杂工作,而最终用户体验的决定权则落在了人工身上。
- 数据库Agent:它在执行之前会确认每个破坏性操作。AI 负责处理将业务需求转换为 SQL 的复杂性,而人类则掌控着数据完整性。
- 函数生成Agent:它在明确定义的边界内运行。输入一个规范,它就会返回一个函数。没有副作用,无需状态管理,也没有任何集成复杂性。
- DevOps自动化Agent:它生成了可审查、可版本控制、可回滚的基础设施即代码。AI 处理了将需求转换为 Terraform 的复杂性,而部署流水线则保留了我们习以为常的所有安全机制。
- CI/CD Agent:每个阶段都有明确的成功标准和回滚机制。AI 负责处理代码质量分析和修复的复杂工作,而流水线则负责控制实际合并的内容。
模式很清晰:人工智能处理复杂性,人类保持控制,传统软件工程处理可靠性。
总结
建设Agent的正确的方式是什么呢?如果您正在考虑使用 AI Agent行构建,请遵循以下原则:
- 明确界限。你的Agent到底能做什么?它会把什么交给人类或确定性系统?
- 为失败而设计。你如何处理 20-40% 的 AI 错误情况?你的回滚机制是什么?
- 解决经济问题。每次交互的成本是多少?成本如何随使用量变化?无状态通常胜过有状态。
- 可靠性优先于自主性。用户更信任能够持续运行的工具,而不是偶尔能带来神奇效果的系统。
- 建立在坚实的基础之上。使用人工智能处理困难部分(理解意图、生成内容),但依靠传统软件工程处理关键部分(执行、错误处理、状态管理)。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号