TPAMI & ICML Oral | SparseTSF:轻量且鲁棒的稀疏时序预测

TPAMI & ICML Oral | SparseTSF:轻量且鲁棒的稀疏时序预测

时空探索之旅
发布于 2025-10-11 13:47:27
发布于 2025-10-11 13:47:27
论文标题:SparseTSF: Lightweight and Robust Time Series Forecasting via Sparse Modeling
作者:林升升,林伟伟*,吴文泰,陈浩钧,陈俊龙
机构:华南理工大学,鹏城实验室
论文发表:IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2025, 当前期刊版本) & International Conference on Machine Learning (ICML 2024 Oral, 先前会议版本)
关键词:时间序列预测,长期预测,轻量化模型,稀疏建模,结构正则化
会议论文链接:https://proceedings.mlr.press/v235/lin24n.html
期刊论文链接:https://ieeexplore.ieee.org/abstract/document/11141354
代码链接:https://github.com/lss-1138/SparseTSF

点击文末阅读原文跳转本文IEEE链接
摘要
本文提出了SparseTSF,一种新颖且极其轻量化的长时序预测(Long-term Time Series Forecasting, LTSF)方法,旨在以最小的计算资源应对超长序列中复杂时间依赖建模的挑战。SparseTSF的核心是跨周期稀疏预测(Cross-Period Sparse Forecasting)技术,该技术通过对原始序列进行降采样,将预测任务简化为跨周期趋势建模。该方法不仅显著降低了模型复杂度和参数规模,同时还引入了一种隐式的结构正则化机制,从而提升预测模型的鲁棒性,实现性能与效率之间的最佳平衡。基于该技术,SparseTSF在参数量少于1,000的情况下,仍能获得与先进方法相媲美的预测性能,并在更长的历史窗口(如长为720)下表现出明显优势,使模型能够更好地利用序列中固有的周期性与趋势信息。此外,SparseTSF展现出卓越的泛化能力,尤其适用于计算资源有限、小样本或低质量数据等应用场景。
引言
时间序列预测在交通流量、产品销售和能源消耗等领域具有重要价值,因为准确的预测能够帮助决策者提前做好规划。实现高精度预测通常依赖功能强大但结构复杂的深度学习模型,例如循环神经网络(RNN)、卷积神经网络(CNN)、图神经网络(GNN)以及Transformer。在近些年,长时序预测(Long-term Time Series Forecasting, LTSF)逐渐受到越来越多关注,其目标是为长期规划提供更长时间跨度的预测视角。
然而,更长的预测范围虽然带来便利,却也伴随着更大的不确定性。这要求模型能够从更长的历史窗口中挖掘更丰富的时间依赖信息,导致建模复杂度显著提升。例如,基于Transformer的预测模型往往需要数百万甚至上千万参数,使其在计算资源受限的场景中难以应用。
事实上,长时序预测的准确性在很大程度上依赖于数据中固有的周期性与趋势性。以家庭用电量为例,长期预测是可行的,原因在于电力消耗存在清晰的日周期和周周期规律。特别是日周期,如果将每天某一时刻的电力消耗采样形成日序列,则能够得到相似或一致趋势的子序列(见图1)。在这种情况下,原始序列的周期性和趋势被分解和转化:日周期模式转化为子序列间的动态关系,而趋势模式则体现为子序列内部的特征。这种分解为设计轻量化的长时序预测模型提供了新的思路。
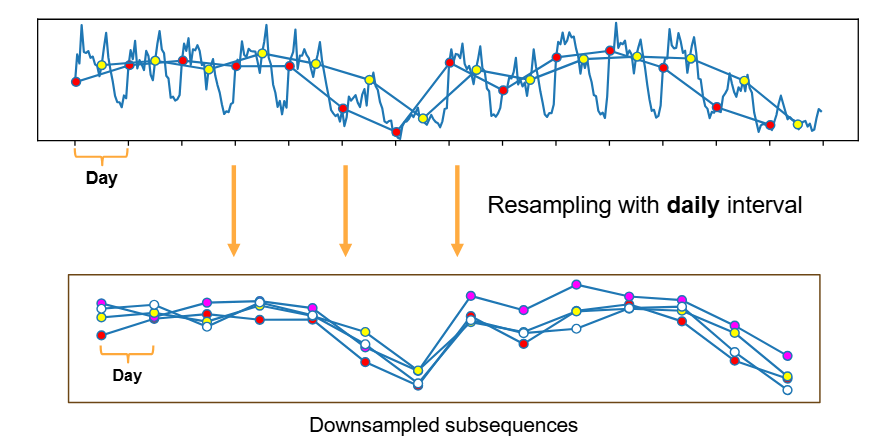
图1. 对Electricity数据集进行日间隔重采样后得到的子序列表现出相似的模式
在本文中,我们率先探索如何利用数据中的固有周期性与分解特性来构建专门的轻量化时序预测模型。具体而言,我们提出了SparseTSF,这是一种极其轻量的LTSF模型,主干架构可以是单层线性结构或浅层多层感知机(MLP)。其核心是跨周期稀疏预测(Cross-Period Sparse Forecasting,以下简称Sparse技术):它首先将具有固定周期性的原始序列降采样为多个子序列,然后在每个子序列上进行预测,从而将原始的时间序列预测任务简化为跨周期趋势预测任务。这一设计带来了两方面优势:(i)有效解耦数据的周期性与趋势,使模型能够稳定地识别和提取周期特征,同时聚焦于趋势变化预测;(ii)极大压缩模型参数规模,显著降低对计算资源的需求。正如图2 所示,在长历史窗口(如720)设置下,SparseTSF仅需不到1,000个可训练参数,即可取得接近主流方法的预测性能,其参数规模比对手小1至4个数量级。
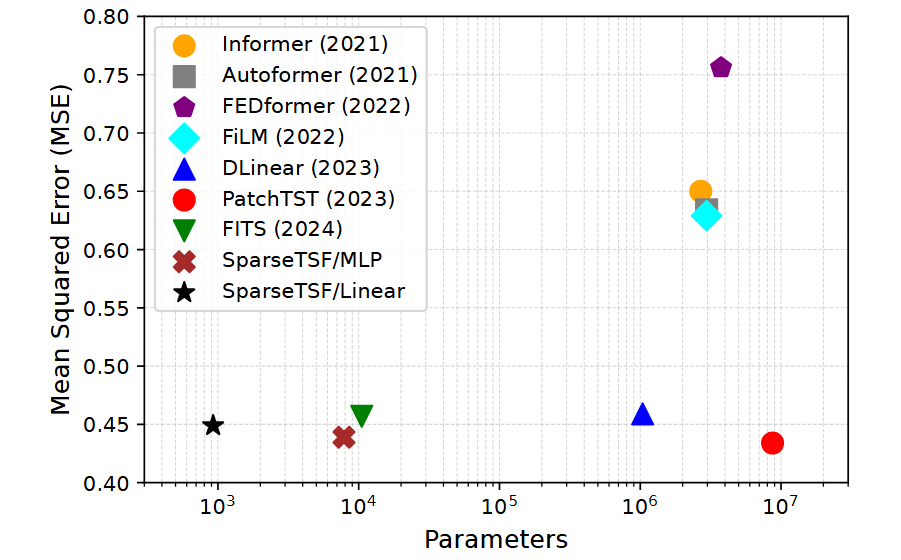
图2. 在Traffic数据集上预测范围为720时,SparseTSF与其他主流模型在MSE与参数量上的对比
在先前会议(ICML)版本工作的基础上,本期刊(TAPMI)版本论文得到了多项重要扩展,主要包括:
- 引入了SparseTSF/MLP变体,在高维多变量预测场景下显著提升了SparseTSF模型的性能;
- 提供了更深入的理论分析,证明了所提出的稀疏建模技术在模型结构中引入了隐式正则化机制,从而显著增强了模型的鲁棒性与泛化能力;
- 大幅扩展了实验部分以进一步综合评估SparseTSF的表现,覆盖了更广泛的数据集,纳入了单变量预测场景的对比实验,开展了更全面的泛化能力评估,以及补充了更多相关的实验验证。
总结而言,本文的主要贡献总结如下:
- 提出了一种新颖的跨周期稀疏预测技术,通过降采样原始序列聚焦于跨周期趋势建模,有效提取周期特征并显著降低模型复杂度与参数规模;
- 证明了Sparse技术在结构上引入了隐式正则化,使模型能够聚焦于历史周期中的关键信息,从而显著提升鲁棒性;
- 基于Sparse技术构建的SparseTSF模型仅需不到1,000个参数,大幅降低了时序预测模型对计算资源的需求;
- SparseTSF在极低参数量的条件下,不仅实现了与最先进方法相当甚至更优的预测精度,还展现出卓越的泛化能力。
方法
前置知识
长时序预测
长时序预测(LTSF)的任务是利用已观测到的多变量时间序列(MTS)数据,预测未来较长时间范围内的取值。其形式化定义为:
其中,,。在该定义中, 表示历史回溯窗口的长度, 表示特征或通道的数量, 表示预测区间的长度。
LTSF 的核心目标是尽可能延长预测区间 ,因为更长的预测范围能够在实际应用中提供更丰富、更前瞻性的指导。然而,预测区间的延长也会显著增加模型复杂度,并导致主流模型参数量的快速增长。为应对这一挑战,我们的研究聚焦于开发极度轻量化、同时保持鲁棒性与有效性的预测模型。
通道独立策略
近年来,LTSF 领域的研究逐渐转向 通道独立(Channel-Independent, CI) 策略,尤其在处理多变量时间序列时表现突出。该方法通过将多变量序列拆解为单变量序列,并针对每个通道独立建模,从而简化了预测任务。形式化表达为:
相比传统方法需要建模复杂的跨通道依赖,CI 策略更直接地关注单变量时间序列的周期性与趋势建模,降低了复杂度。近年来的主流模型正是基于这种思路。比如DLinear 通过单层线性结构提取单变量序列中的主要周期性特征;而PatchTST与TiDE等则在单通道建模上引入更复杂的结构,以进一步提升预测性能。
本文同样采用这种 CI 策略,探索如何在单通道序列建模中设计一种更加轻量却依然有效的方法。同时,我们也在实验章节详细讨论了这种CI方法与通道依赖(Channel-Dependent, CD) 策略的优缺点。为简化表述,下文统一省略通道维度,假设模型输入为 ,输出为 。
SparseTSF
在许多场景中,待预测的数据往往具有先验已知的稳定周期性(例如电力消耗与交通流量通常呈现日周期)。基于这一特性,我们提出了跨周期稀疏预测(Cross-Period Sparse Forecasting) 技术,在增强长时依赖建模能力的同时,显著降低模型参数规模。结合该技术,仅依赖单层线性层或双层 MLP 作为预测骨干网络,即构成了SparseTSF,如图3所示。
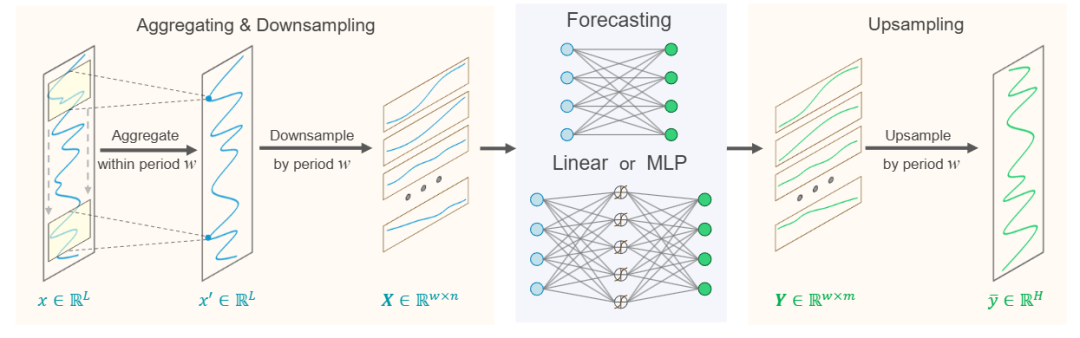
图3. SparseTSF结构图,其中SparseTSF/Linear和SparseTSF/MLP分别表示使用单层Linear或者双层MLP作为SparseTSF的基石模型
跨周期稀疏预测
假设时间序列 的周期为 ,我们首先将原始序列按周期进行降采样,得到 个子序列,每个子序列长度为 。接着,利用参数共享的骨干模型分别对这些子序列进行预测,预测结果再上采样回长度为 的完整序列。
降采样与预测的过程可形式化为:
其中 ,,骨干模型 在各子序列间共享参数。预测结果上采样的过程为:
其中 ,,且 。
在工程实现上,降采样与上采样均可通过矩阵reshape与转置高效完成。
不过,这一过程仍存在两方面问题:
- 由于每周期仅保留一个点,可能造成信息丢失;
- 异常值可能被放大,对预测产生不利影响。
为解决上述问题,我们在稀疏预测前额外引入滑动聚合(sliding aggregation)操作,如图3所示。该操作在每个周期内对邻近点进行加权聚合:
- 既能弥补信息丢失问题;
- 又能通过平滑降低异常值的影响。
其实现方式是带零填充的一维卷积(Conv1D),卷积核大小为 。公式为:
直观上,SparseTSF 的整体预测过程可视为跨周期的稀疏滑动预测,其本质是参数共享的周期内预测,如图4所示。
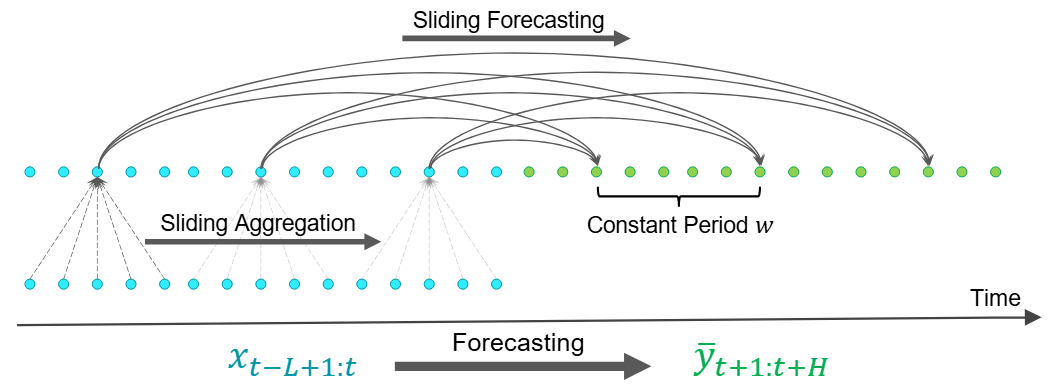
图4. SparseTSF在时间轴的工作示意图
基石模型
SparseTSF 的核心目标是探索预测模型在轻量化上的极限。为此,我们采用:
- 单层线性模型(SparseTSF/Linear):结构最简单,极致压缩模型的参数规模;
- 双层 MLP(SparseTSF/MLP,两层Linear叠加,中间激活函数为ReLU):具备非线性建模和学习能力,更加适合高维多变量预测任务。
非线性使模型能够更好区分通道间的不同模式,而纯线性模型在这方面能力有限,实验章节的结果对比亦可证明这点。
实例归一化
时间序列常存在训练集与测试集分布不一致的问题。已有研究表明,简单的实例归一化(Instance Normalization)策略能够有效缓解该问题。我们在模型输入与输出间均采用如下归一化方式:
其中 为序列均值。
损失函数
与主流方法保持一致,我们采用经典的均方误差(MSE)作为损失函数:
该指标衡量预测值 与真实值 之间的差异。
理论分析
本节以 SparseTSF/Linear 为例,进行理论分析,重点讨论其参数效率与稀疏技术的有效性。我们证明,Sparse 技术相当于对模型引入了隐式的结构正则化,从而增强模型对噪声的鲁棒性,并提升泛化能力。
参数效率
定理一(参数数量):设历史回顾窗口长度为 、预测步长为 ,数据具有固定周期 ,则 SparseTSF 模型所需的总参数量为:
在长时序预测任务中,回顾窗口 与预测步长 通常较大(例如 720),而数据的固有周期 也较大(如 24)。此时,总参数量为
说明 SparseTSF 的参数规模远低于最简单的标准线性模型,充分体现了其极轻量化特性。
结构正则化
本小节证明,SparseTSF 中的稀疏化技术相当于对模型权重施加隐式的结构正则化,从而增强鲁棒性并改善泛化性能。
定理二(SparseTSF/Linear 模型的优化目标):结合 Sparse 技术的Linear模型的优化目标为:
其中 ,且
其中 ,,。
定理二证明:
Sparse 技术将历史序列降采样 以预测未来降采样序列 。使用共享权重的全连接线性层建模所有子序列预测任务:
其中 ,,。子序列预测任务的优化目标为:
通过复制和零填充 的元素,可以得到等价的权重矩阵 ,用于原始序列的预测。 的对角块对应 的位置填充 元素,其余位置填零(即 )。
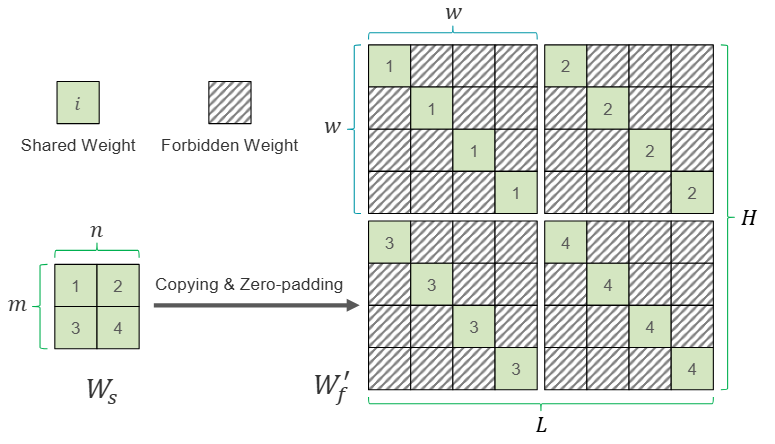
图5. 通过复制和零填充 得到等价的权重矩阵 的示意图
图5展示了如何通过复制和零填充得到完整的等价参数矩阵 。等价矩阵可以直接通过原始权重矩阵 引入两种正则化项得到:
- :通过惩罚小矩阵的非对角元素绝对值之和,实现稀疏化;
- :约束每个 子矩阵对角元素的方差,实现权重共享。
组合两项正则化与原始损失,即得到完整优化目标:
充分训练后,得到的 等价于稀疏预测参数矩阵 的扩展矩阵 ,证明了Sparse 技术的优化目标等价于该形式。
定义一(线性模型的 正则化优化目标):线性模型在原始序列预测任务中结合 正则化的优化目标为:
其中 ,,,。
在神经网络中引入 正则化有助于特征选择,通过稀疏化将不重要的权重逼近零,从而增强模型的鲁棒性和泛化能力。对比定义一与定理二,可以发现两者优化目标形式相似:第一项为经验损失 ,衡量预测与真实值差异;后续项作为正则化项约束模型复杂度。
在 Sparse 技术的优化目标中, 强制弱相关特征的权重为零,实现结构约束; 实现子矩阵内部参数共享,降低模型自由度。这种正则化类似于 稀疏化,但更具结构化,利用领域知识引入约束(零化非对角块、子块内部权重共享),非单纯的 或 范数所能表达。
综上,SparseTSF 中的稀疏预测技术可视为隐式正则化机制(类似 ,实现结构稀疏化),增强模型鲁棒性和泛化能力。通过结构化稀疏设计,SparseTSF 能够在处理噪声和复杂数据时更有效地提取有意义特征,实现极致模型压缩的同时保持预测性能。
实验
本节展示了SparseTSF在主流长时序预测(LTSF)基准上的实验结果,并进一步探讨其轻量化架构所带来的效率优势。同时,我们还进行了消融实验与分析,以更深入揭示稀疏技术的有效性。
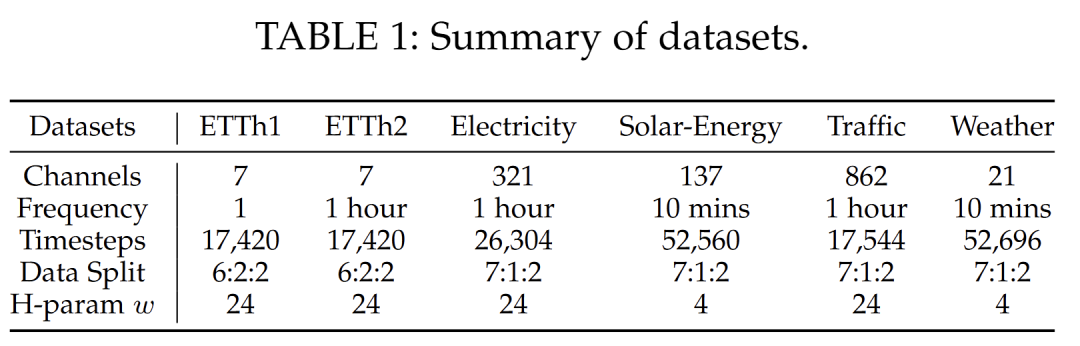
表1. 数据集信息统计
主要结果
表2给出了SparseTSF与多变量时序预测任务中的其他基线模型的性能对比。可以看到,SparseTSF(包括Linear与MLP两个变体)在大多数场景中均进入前三,达到或接近最新水平,同时其参数规模显著更小。在多变量预测场景中,SparseTSF/MLP表现优于SparseTSF/Linear,分别获得39次与24次前三排名。这主要是因为SparseTSF采用了主流的通道独立(CI)策略(即通过共享模型来建模多通道序列),在这种情况下,MLP的非线性能力能够更好地捕捉不同通道间的时序模式,从而提升预测效果。
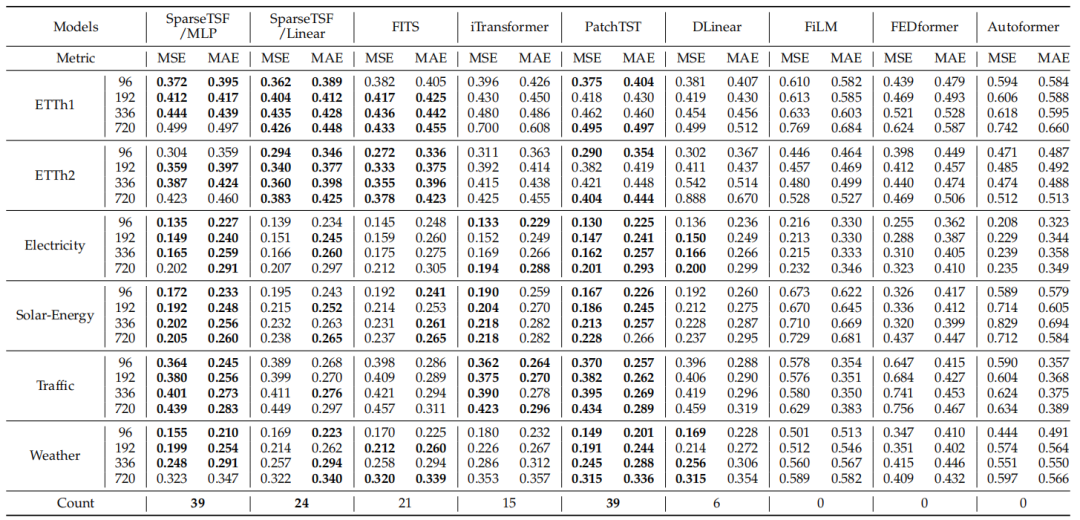
表2. SparseTSF与其他主流模型在多变量长时序预测任务中的结果对比
表3展示了在单变量时序预测任务上的对比结果。SparseTSF依然展现出卓越性能,其中SparseTSF/Linear整体上取得了最优结果。与多变量预测不同,在单变量预测中,SparseTSF/Linear优于SparseTSF/MLP。此外,基于线性的模型(如FITS与DLinear)也优于深度非线性模型(如PatchTST)。其原因在于单通道预测任务中,线性方法已经具备足够的预测能力与鲁棒性,无需额外的非线性结构来拟合多通道模式。
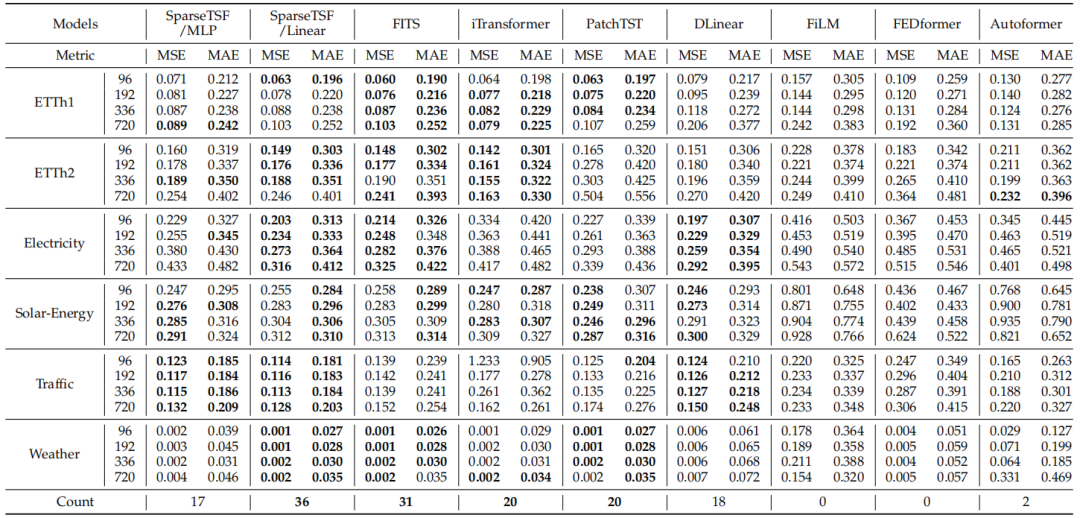
表3. SparseTSF与其他主流模型在单变量长时序预测任务中的结果对比
综合来看,上述结果充分证明了本文提出的稀疏技术的优势。正如定理二所示,稀疏技术相当于一种隐式正则化,使模型能够更专注于历史序列中的关键周期特征,同时降低对无关信息的关注,从而更有效地解耦数据中的周期性与趋势,在长预测范围场景下实现卓越的预测性能。
SparseTSF的效率优势
除了强大的预测性能,SparseTSF的另一大优势是其极致轻量化。图2 已经展示了SparseTSF与其他主流模型在参数量与性能上的对比。我们进一步在静态与运行时指标上与其他基线模型进行全面比较,表4展示了比较结果。可以看到,SparseTSF在参数量等静态指标以及显存占用等运行时指标上均显著优于其他模型。特别是SparseTSF/Linear首次将LTSF任务的模型规模降低到不足一千参数。即便是具备更强多变量预测能力的SparseTSF/MLP,其参数量也控制在八千以内,远低于其他基线。这使得SparseTSF能够在计算资源极其有限的设备上运行。
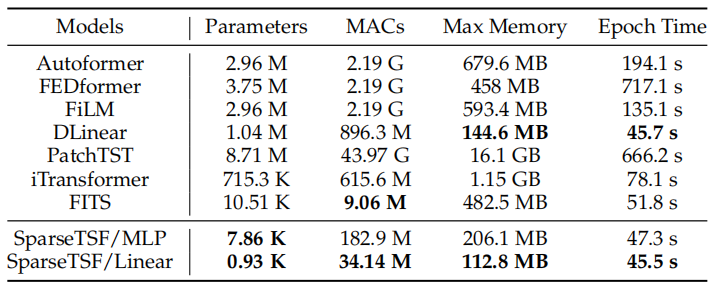
表4. SparseTSF与其他主流模型在Traffic数据集上的静态与运行时指标对比
稀疏技术的有效性
我们在三个不同数据集上进行了消融实验:(i)ETTh1:按小时采样、具有日周期;(ii)Traffic:按小时采样,具有日周期与周周期;(iii)Weather:按10分钟采样、具有日周期。对于前两个数据集,超参数 设置为日周期长度,即 。但对于Weather数据集,其日周期为144,若直接设为144则会导致过短的降采样序列,信息利用不足,因此设置为 。关于 的选择标准将在后续进一步讨论。
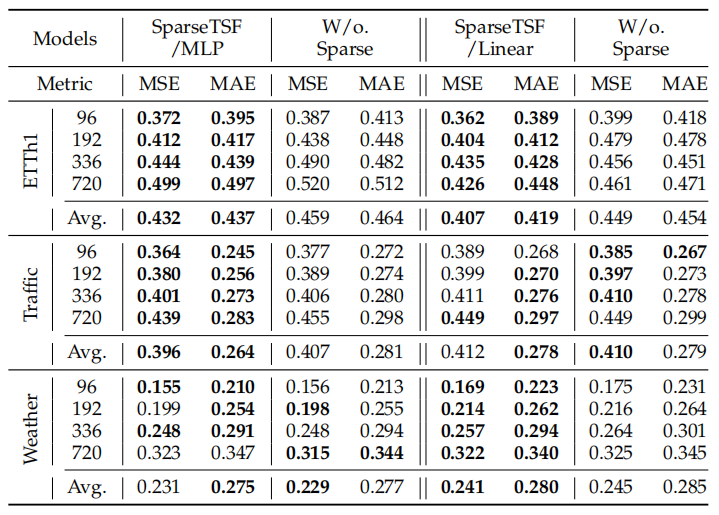
表6. Sparse技术的消融实验
表6的结果表明,稀疏技术在大多数情况下均能提升模型性能。在ETTh1数据集上,Linear与MLP两种骨干均明显受益;在Traffic与Weather数据集上,尽管少数情况下MSE略有上升,但整体上误差下降,验证了稀疏技术的有效性,即在极限压缩模型参数规模的同时,仍能保持甚至提升模型的预测性能。
稀疏技术的表征学习
在理论分析部分,我们揭示了稀疏技术为何能提升预测性能,即其引入了结构正则化的机制。本节进一步从表示学习角度进行验证。图6可视化了Linear模型与SparseTSF/Linear在Traffic数据集上的归一化权重分布。结果显示:
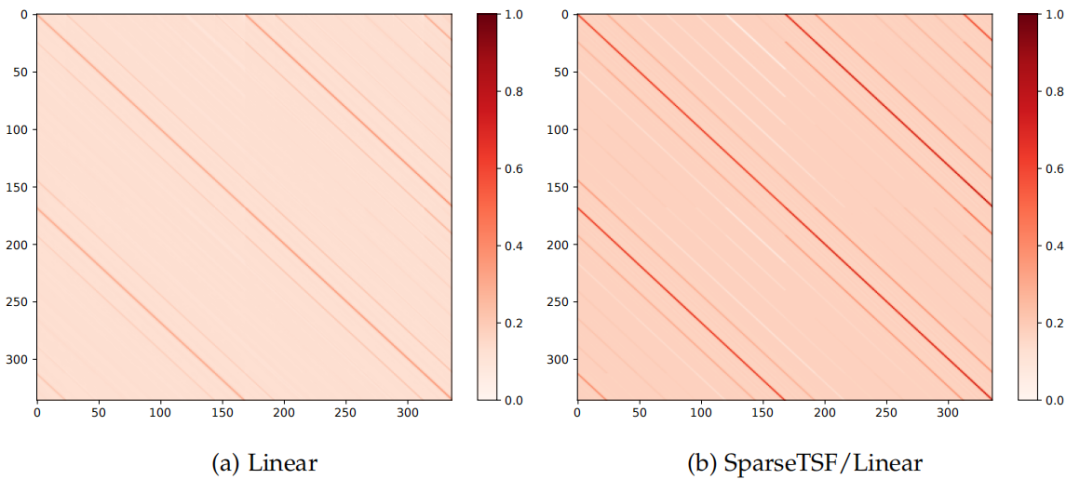
图6. 在Traffic数据集上训练的模型,其归一化权重的可视化结果
- Linear模型能够学习到均匀分布的周期性权重条纹,说明单层线性模型已能捕捉主要周期特征;
- SparseTSF/Linear的权重分布更清晰、规律,表明其具有更强的周期特征提取能力。这源于稀疏技术提供了结构先验,引导模型关注更相关的历史信息,弱化对噪声的依赖。
因此,稀疏技术通过强化周期特征提取,进一步提升了LTSF任务的预测性能。
超参数 的影响
超参数 控制了稀疏正则化的强度:更大的 带来更强的正则化。图7展示了不同 下SparseTSF/Linear的表现。
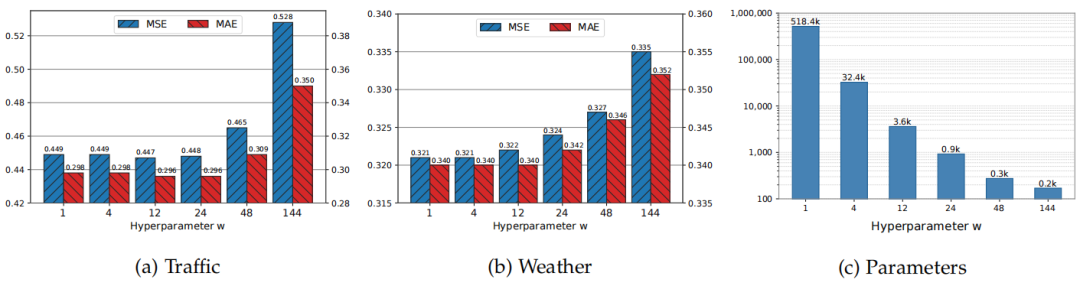
图7. SparseTSF/Linear模型在不同超参数 下的性能与参数规模对比
- 在Traffic数据集上,最佳表现出现在 ,对应其日周期;当 时,虽未精准对齐周期,模型仍因正则化作用保持较好性能;但当 时,过度稀疏导致关键信息丢失,性能显著下降。
- 在Weather数据集上,理论上应设 ,但过大 会造成信息不足,性能急剧下降。此时设置较小的 (如4)能在正则化与信息利用间取得平衡,参数量减少十倍以上的同时提升准确率。
因此,对于按小时采样的日周期数据(如ETTh1、Electricity),推荐设 ;而对于高密度采样的日周期数据(如Weather、Solar-Energy),则推荐使用较小 值。
泛化能力
稀疏技术增强了模型的鲁棒性,尤其在跨数据集迁移中表现突出。我们在表7评估了SparseTSF在四种迁移场景下的性能(如ETTh2 ETTh1、Traffic Electricity 等)。结果表明:
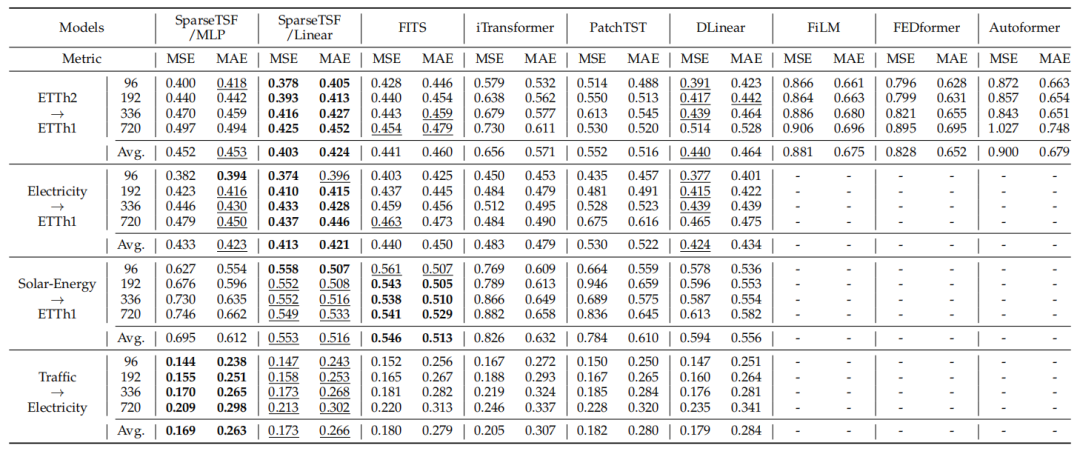
表7. SparseTSF与其他主流模型的泛化能力对比
- 在相同周期长度下,SparseTSF/Linear与MLP均取得领先性能;
- 在周期长度不一致时(如Solar-Energy ETTh1),虽然性能有所下降,但SparseTSF/Linear依旧位居前二,显示出较强的跨域适应性。
总体上,SparseTSF/Linear在小规模数据集上的泛化更好,而SparseTSF/MLP在大规模数据集上表现更佳。这表明稀疏技术带来的结构正则化能够有效避免过拟合,提升模型迁移能力。
通道独立策略的影响
SparseTSF基于通道独立(CI)策略,在长历史窗口下(如 )展现出卓越性能。然而,许多最新SOTA模型采用通道依赖(CD)策略(如iTransformer、TQNet),在短窗口(如 )下表现更好,因为其跨通道建模机制能在有限时序上下文中补偿信息不足。
我们在图9比较了不同方法受到历史窗口长度的影响。可以发现,随着窗口加长,CI方法(如SparseTSF、PatchTST)逐渐赶上甚至超过CD方法。这是因为: (i) 长窗口已提供足够丰富的时序信息; (ii) 过多通道交互可能引入噪声导致过拟合; (iii) 非线性CI模型(如SparseTSF/MLP)仍能有效捕捉多变量模式。
因此,作为一种机制轻量化的CI模型,我们强烈推荐在条件允许时,为SparseTSF提供尽可能长的历史窗口,来实现模型最佳的效果与效率的平衡。
讨论
SparseTSF在处理具有稳定主周期的数据时表现突出,兼具卓越的周期特征提取能力与极致轻量化。然而,它也存在一定局限:
- 超长周期:当周期超过100时,过度稀疏连接可能导致性能下降,需要设置更小 ;
- 多重周期:当数据包含多个交织周期时,SparseTSF只能聚焦于最小周期,难以同时建模多周期特征;
- 短历史窗口:SparseTSF依赖较长窗口来提取鲁棒信息,在窗口过短时性能可能下降。
未来,我们将探索引入更多信息提取模块,以进一步增强SparseTSF的建模能力,在性能与轻量化之间取得更佳平衡。
结论
本文提出了跨周期稀疏预测(Cross-Period Sparse Forecasting)技术及其对应的SparseTSF模型。通过理论分析与实验验证,我们展示了SparseTSF模型的轻量特性及其在有效提取周期性特征方面的优势。特别是,我们在理论上证明了所提出的稀疏技术具备隐式结构正则化作用,能够显著提升模型的鲁棒性。在极少参数规模的前提下,SparseTSF依然能够达到甚至超越当前先进模型的性能,因而成为在计算资源受限场景下的有力候选方案。此外,SparseTSF展现出强大的泛化能力,为小样本和低质量数据等应用场景提供了新的可能性。这标志着轻量化长时序预测模型研究的重要里程碑。未来,我们将进一步探索超长周期与多周期数据的特征提取问题,力求在模型性能与参数规模之间实现最优平衡。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号