存储范式解析:对象、键值(概念与架构)

存储范式解析:对象、键值(概念与架构)

数据存储前沿技术
发布于 2025-10-09 10:37:33
发布于 2025-10-09 10:37:33
问题意识
出差在途 读 《分布式统一大数据虚拟文件系统》一书 序言,摘录到下面这段话:
例如,在数据应用层,从最初的Apache MapReduce框架衍生出了很多不同的通用化和共性化的系统,包括通用数据处理平台Apache Spark,流式计算系统Apache Flink和Apache Samza,机器学习与深度学习系 Tensor Flow和PyTorch,查询系统Presto和ApacheDril,等等。
类似地,整个生态系统的存储层也从Hadoop分布式文件系统(HDFS)发展并增加了更多的可选项,例如文件系统、对象存储(object store) 系统、二进制大对象存储(blob store)系统、键值对存储(key-value store)系统,NoSQL数据库等。这些不同类型的系统实现了性能、速度、成本、易用性、架构等设计上的不同权衡。
提笔记下这几个问题:
- 如何理解 对象存储、二进制大对象存储、键值对存储 三者区别?
- 三者的存储系统构造方法差异,为什么这么构造?
- 使用场景差异?
7月份也曾整理过一篇类似的文章:【存储100问】键值与对象解耦的存储场景,本文对 对象和键值的架构范式做了更深入的洞察,可以从底层构造上更透彻理解两者差异,内容有点长,对于理解当下业务场景对存储系统选型的要求是有帮助的。
阅读收获
- 理解存储范式核心差异:掌握对象存储的元数据驱动特性与键值存储的极致简约抽象,是选择合适存储方案的基础。
- 洞察架构设计权衡:识别对象存储为EB级规模和高持久性而解耦的三层架构,以及键值存储为低延迟和高吞吐量而优化的数据分区与存储引擎选择。
- 精选数据持久与一致性策略:根据业务需求,评估对象存储的纠删码与强一致性演进,以及键值存储的可调一致性模型,以平衡成本、性能与数据可靠性。
- 优化应用场景匹配:明确LSM-Tree和B-Tree在读写密集型场景中的适用性,以及内存型与磁盘型键值存储的性能边界,避免存储方案与业务需求错配。

01
概念基础与数据模型
在深入探讨系统架构之前,必须首先建立对这三种存储范式核心概念的精确理解。本节旨在阐明它们的基础数据模型和抽象,为后续的架构比较奠定坚实的理论基础。
01
定义范式
对象存储:自描述的数据包
对象存储是一种计算机数据存储架构,它将数据作为离散的单元(称为“对象”)进行管理 1。这与传统文件系统基于目录层级的管理方式形成了鲜明对比 3。对象存储的核心是“对象”这一概念,它是一个包含了数据、元数据和唯一标识符的自足包。
一个对象的构成要素如下:
- 数据(Data):即对象存储的实际内容。它可以是任何形式的字节序列,代表着非结构化数据,如文档、图片、视频或日志文件。对象的大小可以从零字节到数TB不等 5。
- 元数据(Metadata):这是一组描述数据的键值对,是对象存储的关键差异化特征 5。元数据分为两类:系统元数据(如创建日期、内容类型、大小等)和用户自定义元数据。后者允许用户为对象附加丰富的、可查询的上下文信息,例如“患者ID”、“项目名称”或“数据保留策略”等 7。
- 唯一标识符(Unique Identifier, UID):这是一个在存储系统范围内全局唯一的地址或ID。应用程序使用此ID可以直接定位和访问对象,无需遍历复杂的目录路径 1。
对象存储采用“扁平命名空间”(Flat Namespace)的组织方式。所有对象都存放在一个逻辑上的“存储池”或“桶”(Bucket)中,彼此之间没有层级关系 1。这种扁平化结构是其实现大规模可扩展性的基石。尽管物理上没有目录,但用户可以通过在对象名称中使用前缀(如logs/2024/01/event.log)来模拟目录结构,以便于组织和批量操作 10。
键值存储:极致简约的抽象
键值存储是NoSQL数据库中最简单的一种数据模型,其核心思想类似于编程语言中的字典(Dictionary)或哈希表(Hash Table) 11。它将所有数据存储为一系列的键值对集合 14。
一个键值对的构成要素如下:
- 键(Key):一个唯一的标识符,通常是字符串。键是访问对应值的唯一途径,所有操作(增、删、改、查)都围绕键展开 12。
- 值(Value):与键相关联的数据。从数据库的角度看,值是一个不透明的数据块(Opaque Blob)。数据库本身不关心其内部结构,由应用程序负责解释。值可以是简单的字符串、数字,也可以是复杂的结构化数据,如JSON文档、序列化的对象,甚至是图片或视频等二进制数据 11。
键值存储通常是“无模式”(Schema-less)的,或更准确地说是“读时模式”(Schema-on-Read) 13。这意味着在写入数据时不需要预定义表结构。应用程序在读取值之后,根据自身逻辑来解析其结构,这提供了极大的灵活性,使得数据模型的演进变得非常容易。
揭秘Blob存储:术语与焦点的辨析
对“Blob存储”的理解常常引起混淆,厘清其概念对于准确比较至关重要。
- Blob作为数据类型:“Blob”是“Binary Large Object”(二进制大对象)的缩写 15。它特指一团不遵循任何特定文件格式的二进制数据 15。这恰恰是对象存储设计用来处理的核心数据类型——非结构化数据 17。
- 功能与架构的等价性:在现代云存储架构中,“Blob存储”系统,如微软的Azure Blob Storage,实际上是对象存储范式的一种商业实现 17。它们同样将数据存储在“容器”(Container,功能等同于对象存储的“桶”)中,使用唯一标识符访问,支持元数据,并通过HTTP API进行交互 17。
- 厂商术语与架构模式:将对象存储服务命名为“Blob存储”通常是一种市场定位策略,旨在强调其存储大型、不透明二进制文件的能力。其底层架构依然是基于对象的。一些术语上的混淆源于特定厂商的实现细节,例如Azure提供的“块Blob”(Block Blob)和“页Blob”(Page Blob)。这些术语描述的是Blob在内部如何被组织和优化以适应不同工作负载(前者适用于大型顺序写入,后者适用于随机读写)(这就类似于Juicefs在实现过程中定义了 Chunk 和 Slice),但它们仍然通过对象存储的API作为完整的对象来访问,而非像块存储那样作为原始的块设备进行操作 19。因此,在本报告的后续部分,将视Blob存储为对象存储的一个同义词或特定实现。
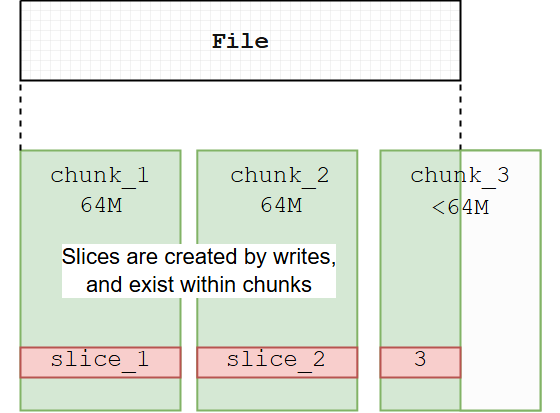
JuiceFS 数据组织范式|560x413
JuiceFS 数据组织范式|560x413
数据模型从根本上决定了查询模型。对象存储的数据模型(数据与丰富的、系统可知的元数据捆绑)和键值存储的数据模型(键与完全不透明的值映射)之间的差异,直接导致了它们查询能力的巨大鸿沟。
对象存储由于其元数据是系统的一等公民,系统本身能够理解并操作这些元数据。例如,系统可以执行服务端的操作,如“查找所有元数据标签为‘project-alpha’的对象”或“自动归档所有创建超过90天的对象” 1。这种能力使得数据管理和发现可以基于数据自身的属性进行,而不仅仅是其名称。
相比之下,纯粹的键值存储将值视为一个黑盒 13。系统对值的内部结构一无所知。因此,任何基于值内容的查询都必须在应用层实现。例如,要查找所有“国家”为“德国”的用户,应用程序要么需要通过已知的用户ID(键)逐一获取每个用户的值,然后在客户端进行过滤;要么需要自行构建和维护一个反向索引(例如,另一个键值表,其键是国家,值是用户ID列表)。这两种方式都比对象存储原生的元数据查询要复杂和低效。因此,在数据模型上的选择,实质上是在“系统级的数据智能”(对象存储)与“极致简约和已知键的快速访问”(键值存储)之间做出的根本性架构权衡。
02
系统架构与设计原则深度剖析
本节将从“是什么”转向“如何实现”,深入解构这两种存储系统内部的工程设计。我们将分析使其具备各自规模、性能和持久性特征的核心设计模式与架构权衡。
01
对象存储:EB级构建
对象存储系统的设计目标是管理EB(Exabyte)级别的数据,并提供高持久性和高可用性。为实现这一目标,其架构通常采用高度分布式和解耦的设计。
宏观架构:解耦的三层模型
一个典型的对象存储系统由三个核心组件构成:API网关、元数据服务和分布式存储节点 24。
- API网关(API Gateway):作为系统的公共入口,负责处理来自客户端的RESTful HTTP请求(如GET, PUT, POST, DELETE) 1。它处理认证、授权、请求限流、负载均衡,并将请求路由到内部的相应服务。在某些情况下,它还可能负责协议转换,例如提供一个文件系统网关,使传统应用能以文件协议访问对象存储 24。
- 元数据服务(Metadata Service):这是系统的“大脑”。它维护着从对象UID到其在存储节点上物理位置的映射关系 8。此外,它还负责管理对象的元数据、版本信息、访问控制策略(ACLs)和生命周期规则。元数据服务的性能和可扩展性直接决定了整个系统的上限。为了应对海量对象的元数据管理并提供强一致性保证,现代对象存储系统(如Google Cloud Storage)已开始采用像Spanner这样的全球分布式数据库作为其元数据后端 25。
- 存储节点(Storage Nodes):由大量商用服务器组成的庞大集群,每台服务器挂载多个大容量磁盘(通常是HDD以优化成本,或SSD用于高性能层) 26。这些节点是“无状态”的,它们只负责根据元数据服务提供的内部指令,存储和检索数据块。
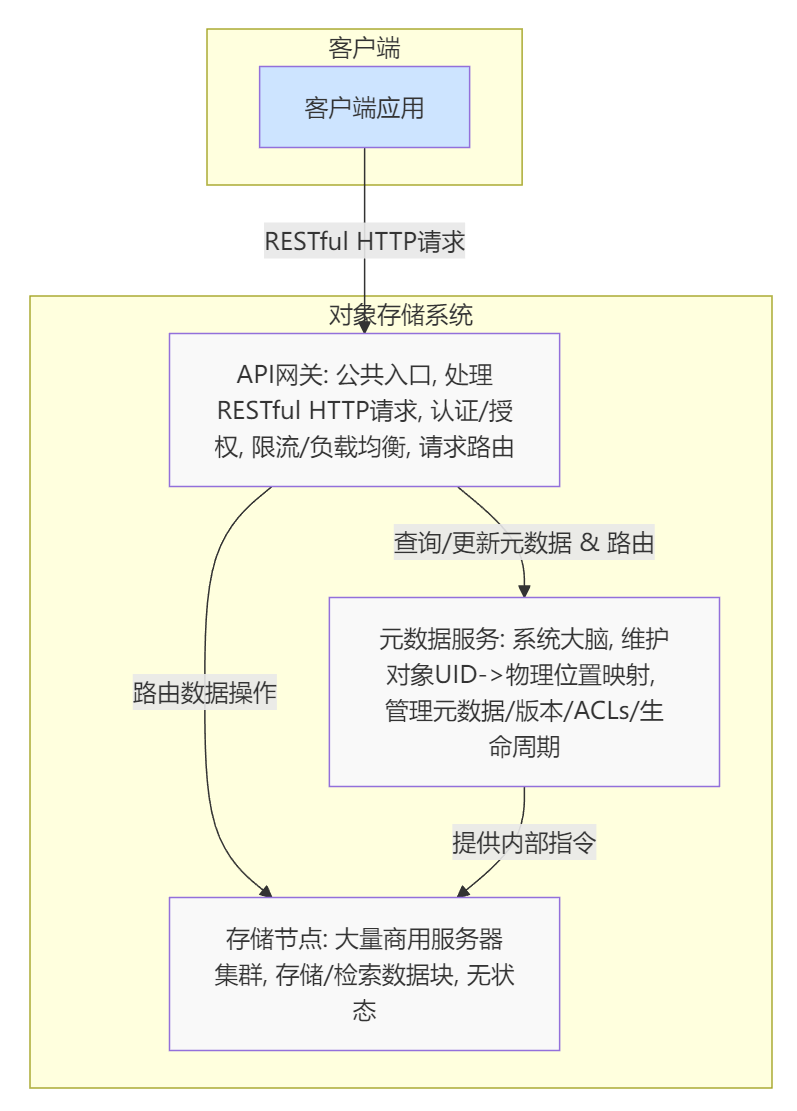
|798x1112
|798x1112
这种将元数据管理(控制平面)与数据存储(数据平面)彻底分离的架构决策,是对象存储能够实现海量扩展的最关键因素 1。控制平面可以独立于数据平面进行扩展和优化,以处理每秒数百万次的元数据操作;而数据平面则可以通过简单地增加存储节点来线性扩展存储容量和吞吐量,而无需改变系统的逻辑结构。
数据持久性与弹性:超越简单复制
为了保证数据在硬件故障、甚至整个数据中心失效时依然安全,对象存储采用了复杂的数据冗余策略。
- 复制(Replication):这是最传统的数据保护方法,即在不同的物理设备、机架或数据中心(可用区)存放多个(通常是3个)相同的数据副本 26。这种方法实现简单,读取性能好,但存储开销巨大。例如,3副本策略意味着需要3倍的物理存储空间,存储效率仅为33.3%。Amazon S3就在多个可用区之间复制对象以实现高持久性 6。
- 纠删码(Erasure Coding):这是一种更先进、存储效率更高的数据保护技术 31。其原理是将原始数据分割成 k个数据块,然后通过数学算法计算出m个校验块。这k+m个块被分散存储在不同的节点上。系统可以容忍任意m个块的丢失,并通过剩余的任意k个块恢复出原始数据。例如,一个6+3的纠删码方案(6个数据块,3个校验块)可以容忍3个节点故障,而其存储开销仅为50%((6+3)/6=1.5),远低于3副本的200% 32。在EB级别的数据规模下,纠删码带来的成本节约是极其显著的。
数据一致性:从最终一致到强一致的演进
数据一致性模型定义了当数据被写入后,后续的读操作能看到什么。
- 历史模型(最终一致性):在早期,对象存储系统普遍提供“写后强一致读”(read-after-write consistency)——即一旦一个对象上传成功,任何后续对该对象的直接读取请求都能获取到最新的数据。但对于元数据操作(如列出桶内所有对象),则只保证“最终一致性”(eventual consistency) 25。这意味着一个新上传的对象可能需要一段时间(从毫秒到数分钟不等)才会出现在对象列表中。这给依赖列表操作来发现和处理数据的数据处理管道(如MapReduce)带来了巨大的复杂性 25。
- 现代模型(强一致性):近年来,提供全局强一致性已成为行业趋势。Amazon S3在2020年宣布为其所有操作提供强一致性 33,Google Cloud Storage通过将其元数据层迁移到Spanner也实现了这一点 25。强一致性保证一旦写操作(创建、覆盖或删除)被系统确认,任何后续的读操作或列表操作都将立即反映这一变化,无论请求发往哪个数据中心 34。这极大地简化了应用程序的开发逻辑,但对底层元数据系统的要求也更高。
不可变性原则:为信任而构建的架构
对象存储的一个核心设计哲学是对象的不可变性。
- 核心原则:对象通常被视为不可变的。系统不支持对对象进行部分或就地修改。要“更新”一个对象,唯一的方法是上传一个全新的版本来完全覆盖旧对象 3。
- 版本控制(Versioning):许多系统允许启用版本控制功能。启用后,每当对象被覆盖或删除时,旧版本不会被真正擦除,而是被保留下来,并获得一个唯一的版本ID 5。这为数据提供了强大的保护,可以轻松恢复因意外操作或应用错误导致的数据丢失。
- WORM(Write-Once-Read-Many):通过S3 Object Lock等功能,用户可以为对象设置合规性或治理模式的保留策略。在指定的保留期内,该对象版本将变得真正不可变——任何用户(包括账户管理员)都无法删除或修改它 36。这一架构特性对于满足金融、医疗等行业的严格法规遵从性要求,以及防御勒索软件攻击(因为备份数据无法被加密或删除)至关重要 36。
02
键值存储:为速度生
键值存储的设计目标是在大规模集群上为简单的读写操作提供极低的延迟和极高的吞吐量(IOPS)。其架构围绕着如何快速地将一个键映射到存储节点,以及如何高效地在节点上存取数据而构建。
数据分区与定位:快速找到正确的节点
在一个由成百上千台服务器组成的集群中,核心挑战是如何高效、均匀地将海量的键值对分布到这些服务器上,并在查询时快速定位。
- 一致性哈希与分布式哈希表(DHT):一致性哈希是一种巧妙的哈希算法,它能确保当集群增加或减少节点时,只需重新映射一小部分键,从而最大限度地减少数据迁移的开销 39。分布式哈希表(DHT)则是一致性哈希的一种实践,它在节点之上构建一个逻辑的覆盖网络。每个节点负责哈希空间的一个片段,并且知道如何将不属于自己范围的键的请求路由到更“接近”目标键的节点,最终请求会被传递到负责该键的节点 39。
- 基于分区的系统(如DynamoDB):另一种常见架构是采用一个中心化的(逻辑上)或分布式的元数据服务,通常被称为“请求路由层”。该层维护一个分区映射表,记录了哪个分区(由一组副本节点构成)负责哪个哈希键范围 42。客户端的请求首先到达请求路由层,路由层根据请求的键计算哈希值,然后从映射表中查出对应的分区,最后将请求直接转发给该分区的领导者(Leader)节点 42。
存储引擎:性能的心脏
存储引擎是键值存储节点内部负责数据组织、存取和管理的组件。其数据结构的选择从根本上决定了系统的性能特征。
- 日志结构合并树(LSM-Tree):这是一种为高写入吞吐量而优化的数据结构。所有写入操作(插入、更新、删除)首先被追加到一个内存中的可写数据结构(通常是跳表或平衡树,称为MemTable)。当MemTable达到一定大小时,它会被冻结并作为一个新的、不可变的、已排序的文件(称为SSTable)顺序地刷写到磁盘上。读取操作则需要依次查询MemTable和磁盘上的多个SSTable层级,并合并结果。系统会在后台周期性地执行“合并”(Compaction)操作,将多个SSTable合并成更大的SSTable,以清除冗余数据(旧版本或已删除的条目)并提高读取效率 44。LSM-Tree的核心思想是将随机写入转换为顺序写入,这对于机械硬盘(HDD)和固态硬盘(SSD)都极为高效。但其代价是可能更高的读取延迟(读放大)和后台合并操作带来的额外I/O(写放大) 45。RocksDB、Cassandra和LevelDB等都采用了LSM-Tree。
- B-Tree / B+Tree:这是一种为高读取性能而优化的数据结构。数据被组织在一个多路的、平衡的树结构中,磁盘上的数据以固定大小的页(Page)为单位进行管理。写入操作通常是“就地更新”,可能需要从磁盘读取一个或多个页到内存,修改后,再写回磁盘,这涉及到随机I/O,因此在写密集型工作负载下性能可能不如LSM-Tree 46。然而,B-Tree的读取性能非常出色,因为查询一个键只需要沿着树的路径进行几次(通常是3-4次)磁盘寻道,且由于数据在页内和页间都是有序的,范围查询也非常高效 44。绝大多数关系型数据库和部分键值存储(如MongoDB的WiredTiger引擎)都使用B-Tree。
存储引擎的选择并非微不足道的实现细节,它是一种定义了系统宏观行为的微观架构决策。一个基于LSM-Tree构建的系统天然地适合于数据采集和日志记录等写入密集型场景,因为它能以极高的速率吸收写入洪峰 46。而一个基于B-Tree构建的系统则更适合于读多写少的应用,如在线查询系统,因为它能提供稳定且快速的读取响应 44。架构师在选择键值存储方案时,必须深入了解其底层的存储引擎,否则可能导致严重的性能错配。
复制与一致性:CAP理论的实践
为实现高可用性和数据持久性,键值存储中的数据通常会在多个节点上进行复制。
- 复制模型:在每个数据分区内,通常采用领导者-跟随者(Leader-Follower)模型。所有写请求都由Leader节点处理,Leader将写入操作日志同步给Follower节点 43。
- 一致性谱系:键值存储系统生动地体现了CAP理论(一致性、可用性、分区容错性)的权衡 50。它们通常为开发者提供了一系列可选的一致性模型:
- 强一致性(Strong Consistency):保证任何读操作都能返回最近一次成功写入的结果。这通常要求读写操作在得到一个“法定人数”(Quorum)的副本节点的确认后才能返回,这会增加延迟但保证了数据的最新性 42。
- 最终一致性(Eventual Consistency):系统保证如果没有新的更新,最终所有副本的数据都会达到一致。在更新后的短暂窗口期内,读操作可能会返回旧数据。这种模型允许读请求由任意副本节点提供服务,从而最大化了可用性并降低了延迟 52。
- 可调一致性(Tunable Consistency):像Cassandra和DynamoDB这样的系统,允许开发者在每次查询时动态指定所需的一致性级别(例如,ONE, QUORUM, ALL) 53。这给予了应用开发者在性能、可用性和数据一致性之间进行精细化控制的能力。
内存型与磁盘型架构
- 内存型(In-Memory),如Redis:整个数据集都存储在RAM中,以实现最低的访问延迟(通常在微秒级别) 55。数据的持久化通过后台异步地将数据快照写入磁盘或记录操作日志来完成。这种架构非常适合于缓存、高速计数器等对速度要求极致,且能容忍在节点故障时丢失少量最新数据的场景 55。
- 磁盘型(Disk-Based),如DynamoDB:数据集主要存储在持久化介质(通常是SSD)上,并利用内存作为缓存来加速对热点数据的访问 56。这种架构支持远超内存容量的大规模数据集,并提供更强的持久性保证,其访问延迟通常在个位数毫秒级别 42。
这两种存储架构的选择,直接导致了性能上的二分法。对象存储的解耦、多层架构(客户端 -> 网关 -> 元数据服务 -> 存储节点)为的是实现巨大的聚合吞吐量和规模,但这条长路径不可避免地在每一步都引入了网络和处理延迟 24。而键值存储的架构,特别是像DynamoDB那样通过请求路由层直连分区节点的模型,则旨在最大限度地缩短单个请求的关键路径,从而优化单次操作的延迟 42。因此,架构师不能笼统地要求“高性能”,而必须明确是需要“高聚合吞吐性能”(如每秒传输TB级数据)还是“高单操作性能”(如每秒处理百万次小请求)。
参考资料
- What is Object Storage? Use cases & benefits | Google Cloud, accessed September 6, 2025, https://cloud.google.com/learn/what-is-object-storage
- cloud.google.com, accessed September 6, 2025, https://cloud.google.com/learn/what-is-object-storage#:~:text=Object%20storage%20is%20a%20data,for%20easy%20access%20and%20retrieval.
- How Object vs Block vs File Storage differ | Google Cloud, accessed September 6, 2025, https://cloud.google.com/discover/object-vs-block-vs-file-storage
- What is Object Storage | Glossary | HPE ASIA_PAC, accessed September 6, 2025, https://www.hpe.com/asia_pac/en/what-is/object-storage.html
- AWS S3 Deep Dive | By Joud W. Awad - Medium, accessed September 6, 2025, https://medium.com/@joudwawad/aws-s3-deep-dive-1c19ad58af40
- S3 Storage: How It Works, Use Cases and Tutorial - Cloudian, accessed September 6, 2025, https://cloudian.com/blog/s3-storage-behind-the-scenes/
- Object metadata | Cloud Storage - Google Cloud, accessed September 6, 2025, https://cloud.google.com/storage/docs/metadata
- What is Object Storage: Definition, How It Works and Use Cases - Cloudian, accessed September 6, 2025, https://cloudian.com/guides/object-storage/object-storage-care/
- Why Metadata Is a Critical Asset for Storage and IT Managers - Dataversity, accessed September 6, 2025, https://www.dataversity.net/why-metadata-is-a-critical-asset-for-storage-and-it-managers/
- Object Storage Objects - Oracle Help Center, accessed September 6, 2025, https://docs.oracle.com/en-us/iaas/Content/Object/Tasks/managingobjects.htm
- What is a Key Value Database? - AWS, accessed September 6, 2025, https://aws.amazon.com/nosql/key-value/
- What is a Key-Value Database? - Redis, accessed September 6, 2025, https://redis.io/nosql/key-value-databases/
- What is a key-value store? | Aerospike, accessed September 6, 2025, https://aerospike.com/glossary/what-is-a-key-value-store/
- What Is A Key-Value Database? - MongoDB, accessed September 6, 2025, https://www.mongodb.com/resources/basics/databases/key-value-database
- www.cloudflare.com[1], accessed September 6, 2025, https://www.cloudflare.com/ru-ru/learning/cloud/what-is-blob-storage/#:~:text=A%20%22blob%2C%22%20which%20is,storage%20areas%20called%20data%20lakes.
- What is Azure Blob Storage? - LogicMonitor, accessed September 6, 2025, https://www.logicmonitor.com/blog/what-is-azure-blob
- Introduction to Azure Blob Storage - Microsoft Learn, accessed September 6, 2025, https://learn.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction
- About Blob (object) storage - Azure Storage, accessed September 6, 2025, https://docs.azure.cn/en-us/storage/blobs/storage-blobs-overview
- What is a block blob in azure and how is it different from object storage - Microsoft Learn, accessed September 6, 2025, https://learn.microsoft.com/en-us/answers/questions/1031660/what-is-a-block-blob-in-azure-and-how-is-it-differ
- What is BLOB? Azure BLOB storage & Features | Geek Culture - Medium, accessed September 6, 2025, https://medium.com/geekculture/what-is-a-blob-83e65f590694
- Object storage - Wikipedia, accessed September 6, 2025, https://en.wikipedia.org/wiki/Object_storage
- Are Azure "Block Blobs" an example of "block storage", "object storage", or (somehow) both?, accessed September 6, 2025, https://stackoverflow.com/questions/73857277/are-azure-block-blobs-an-example-of-block-storage-object-storage-or-som
- A Guide to Key-Value Databases | InfluxData, accessed September 6, 2025, https://www.influxdata.com/key-value-database/
- (PDF) Comparative Analysis of Object‐Based Big Data Storage ..., accessed September 6, 2025, https://www.researchgate.net/publication/378066788_Comparative_Analysis_of_Object-Based_Big_Data_Storage_Systems_on_Architectures_and_Services_A_Recent_Survey
- Spanner: The secret to Cloud Storage strong list consistency | Google Cloud Blog, accessed September 6, 2025, https://cloud.google.com/blog/products/gcp/how-google-cloud-storage-offers-strongly-consistent-object-listing-thanks-to-spanner
- Block vs File vs Object Storage - Difference Between Data Storage Services - AWS, accessed September 6, 2025, https://aws.amazon.com/compare/the-difference-between-block-file-object-storage/
- Amazon S3 Deep Dive: Fundamentals Explained - AWS, accessed September 6, 2025, https://aws.amazon.com/awstv/watch/65acaf1dec0/
- Data redundancy in your distributed relational database network - IBM, accessed September 6, 2025, https://www.ibm.com/docs/en/i/7.4.0?topic=dap-data-redundancy-in-your-distributed-relational-database-network
- Replication and Redundancy Techniques | Parallel and Distributed Computing Class Notes | Fiveable, accessed September 6, 2025, https://library.fiveable.me/parallel-and-distributed-computing/unit-10/replication-redundancy-techniques/study-guide/nt1DC1ndfzK2HJh2
- Diagramming System Design: Amazon S3 Storage System - Codesmith, accessed September 6, 2025, https://www.codesmith.io/blog/amazon-s3-storage-diagramming-system-design
- What Is Erasure Coding? - Pure Storage, accessed September 6, 2025, https://www.purestorage.com/knowledge/what-is-erasure-coding.html
- Erasure Coding in System Design - GeeksforGeeks, accessed September 6, 2025, https://www.geeksforgeeks.org/system-design/erasure-coding-in-system-design/
- Diving Deep on S3 Consistency | All Things Distributed, accessed September 6, 2025, https://www.allthingsdistributed.com/2021/04/s3-strong-consistency.html
- Cloud Storage consistency, accessed September 6, 2025, https://cloud.google.com/storage/docs/consistency
- What Is Immutable Data Storage for Backups? - NAKIVO, accessed September 6, 2025, https://www.nakivo.com/blog/immutable-storage/
- What Is Immutable Storage? - IBM, accessed September 6, 2025, https://www.ibm.com/think/topics/immutable-storage
- What is Object Storage? Architecture, Features, Pros & Cons, accessed September 6, 2025, https://objectfirst.com/guides/data-storage/what-is-object-storage/
- What is Immutable Storage? Benefits & Use Cases | Object First, accessed September 6, 2025, https://objectfirst.com/guides/immutability/immutable-storage/
- Distributed hash table - Wikipedia, accessed September 6, 2025, https://en.wikipedia.org/wiki/Distributed_hash_table
- What is a distributed hash table (DHT)? - Milvus, accessed September 6, 2025, https://milvus.io/ai-quick-reference/what-is-a-distributed-hash-table-dht
- Distributed Hash Tables (DHTs) - Tutorialspoint, accessed September 6, 2025, https://www.tutorialspoint.com/distributed-hash-tables-dhts
- DynamoDB Architecture | By Joud W. Awad | Medium, accessed September 6, 2025, https://medium.com/@joudwawad/dynamodb-architecture-5a38761501a7
- Understanding the Internal Architecture of Amazon DynamoDB | by Syed M. Shamail, accessed September 6, 2025, https://medium.com/@syedshamail3/understanding-the-internal-architecture-of-amazon-dynamodb-e9dccb8be8de
- B-Tree vs. LSM-Tree - ByteByteGo, accessed September 6, 2025, https://bytebytego.com/guides/b-tree-vs/
- [2507.09642] Rethinking LSM-tree based Key-Value Stores: A Survey - arXiv, accessed September 6, 2025, https://arxiv.org/abs/2507.09642
- Write throughput differences in B-tree vs LSM-tree based databases? - Reddit, accessed September 6, 2025, https://www.reddit.com/r/databasedevelopment/comments/187cp1g/write_throughput_differences_in_btree_vs_lsmtree/
- Revisiting B+-tree vs. LSM-tree - USENIX, accessed September 6, 2025, https://www.usenix.org/publications/loginonline/revisit-b-tree-vs-lsm-tree-upon-arrival-modern-storage-hardware-built
- What is the difference between a B+ tree and an LSM tree? Which one is better for search and indexing purposes, and under what conditions? - Quora, accessed September 6, 2025, https://www.quora.com/What-is-the-difference-between-a-B-tree-and-an-LSM-tree-Which-one-is-better-for-search-and-indexing-purposes-and-under-what-conditions
- Amazon DynamoDB - Wikipedia, accessed September 6, 2025, https://en.wikipedia.org/wiki/Amazon_DynamoDB
- What Is A Distributed Storage System - ScaleGrid, accessed September 6, 2025, https://scalegrid.io/blog/what-is-a-distributed-storage-system/
- Data Consistency Storage in the Cloud | ISC2 Article, accessed September 6, 2025, https://www.isc2.org/Insights/2021/10/data-consistency-storage-in-the-cloud
- AWS DynamoDB: Everything you need to know - N2W Software, accessed September 6, 2025, https://n2ws.com/blog/aws-cloud/amazon-dynamodb-latest
- Consistency Models in Distributed Systems | by Maneesh Chaturvedi - Medium, accessed September 6, 2025, https://medium.com/@codecraftspro/consistency-models-in-distributed-systems-7b01c88ef50a
- What are some common distributed database management systems? - Milvus, accessed September 6, 2025, https://milvus.io/ai-quick-reference/what-are-some-common-distributed-database-management-systems
- Redis Cluster Architecture | Redis Enterprise, accessed September 6, 2025, https://redis.io/technology/redis-enterprise-cluster-architecture/
- Key-Value Store System Design - EnjoyAlgorithms, accessed September 6, 2025, https://www.enjoyalgorithms.com/blog/design-key-value-store/
- [Answered] What is the difference between key-value store and object storage? - Dragonfly, accessed September 6, 2025, https://www.dragonflydb.io/faq/key-value-store-vs-object-storage
- Redis cluster specification | Docs, accessed September 6, 2025, https://redis.io/docs/latest/operate/oss_and_stack/reference/cluster-spec/
- Object vs. File vs. Block Storage: What's the Difference? | IBM, accessed September 6, 2025, https://www.ibm.com/think/topics/object-vs-file-vs-block-storage
- Key-Value Stores vs. Relational Databases: Performance & Use Cases | by Ahmet Soner, accessed September 6, 2025, https://ahmettsoner.medium.com/key-value-stores-vs-relational-databases-performance-use-cases-bcd95192ed04
- Key–value database - Wikipedia, accessed September 6, 2025, https://en.wikipedia.org/wiki/Key%E2%80%93value_database
- Understand data store models - Azure Architecture Center - Microsoft Learn, accessed September 6, 2025, https://learn.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-overview
- What is a data lake? - Cloudflare, accessed September 6, 2025, https://www.cloudflare.com/learning/cloud/what-is-a-data-lake/
- Ten Use Cases Where Object Storage Really Stands Out - Cloudian, accessed September 6, 2025, https://cloudian.com/blog/ten-use-cases-where-object-storage-really-stands-out/
- aws.amazon.com, accessed September 6, 2025, https://aws.amazon.com/nosql/key-value/#:~:text=You%20can%20use%20a%20key,stores%20to%20accelerate%20application%20responses.
- When to use a key-value data store vs. a more traditional relational DB? - Stack Overflow, accessed September 6, 2025, https://stackoverflow.com/questions/1500611/when-to-use-a-key-value-data-store-vs-a-more-traditional-relational-db
- Key-Value Stores vs Relational Databases - - The Iron.io Blog, accessed September 6, 2025, https://blog.iron.io/key-value-stores-vs-relational-databases/
- Why are key value pair noSQL db's faster than traditional relational DBs - Stack Overflow, accessed September 6, 2025, https://stackoverflow.com/questions/2354254/why-are-key-value-pair-nosql-dbs-faster-than-traditional-relational-dbs
Notice:Human's prompt, Datasets by Gemini-2.5-Pro-DeepResearch
---【本文完】---
👇阅读原文,查看历史文章,推荐PC端打开 💻(更新到 8.31)。
- http://www.cloudflare.com ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号