【大模型】一文彻底搞懂大模型是怎么“想”出答案的!
原创

一 大模型的推理原理:一次“概率算命”的奇幻漂流
输入变成向量
你敲下的每个字,都会被查表变成一个高维向量(Embedding)。
类比:把“猫”变成 GPS 坐标,语义相近的词坐标距离更近。
向量冲进“迷宫”——Transformer
多层 Transformer 就像一座 100 层的迷宫,每层都在问:
“当前这个词,应该去关注前面哪些词?”——这就是 Self-Attention。
结果:每个词都拿到一张“注意力地图”,知道自己该跟谁混。
迷宫出口:logits
最后一层给出的是“原始分数”logits,维度 = 词表大小(5 万~15 万)。
类比:15 万张彩票,每张对应一个候选词,初始奖金=分数。
Softmax:把分数变概率
所有彩票奖金归一化,总和=1,得到概率分布。
此时“猫”概率 3.2%,“狗”概率 2.7%……
采样:从彩票堆里抽一张
根据概率抽下一张词,循环回到第 1 步,直到抽到“<end>
二 大模型的问答工作流程
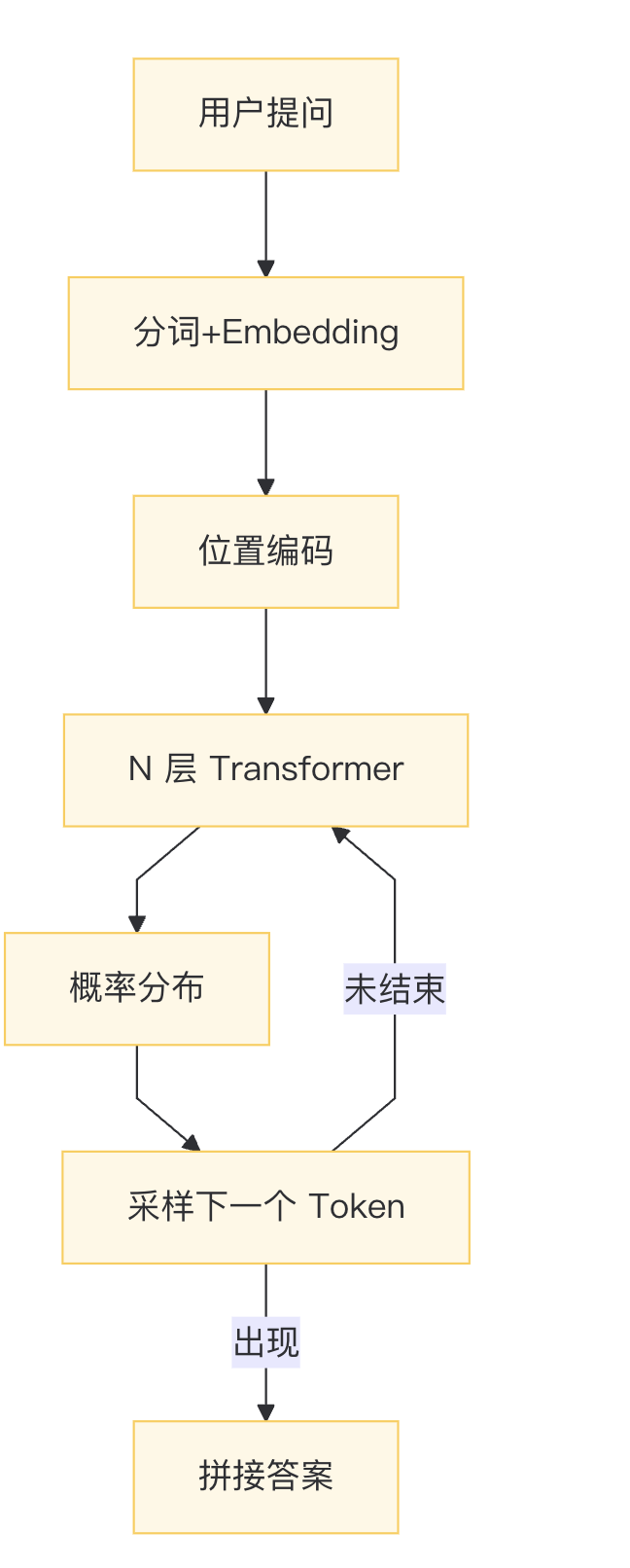
关键一句:每生成 1 个 Token,都要把已生成的全部文本重新送进迷宫,重新算注意力——这就是“自回归”。
三 影响大模型输出的因素:调参就是“驯兽”
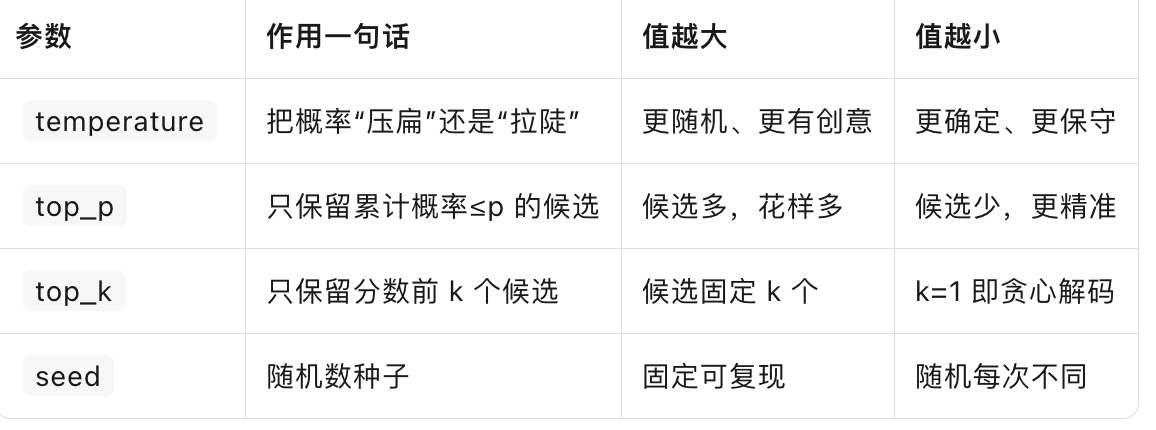
下面逐条拆开玩~
temperature:调整候选 Token 集合的概率分布
公式:
new_prob = exp(logits / T) / Z
当 T→0:概率最尖锐,几乎每次都选最高分词 → 复读机。
当 T→∞:概率趋近均匀 → 胡说八道生成器。
实战口诀
创意写作:0.7~1.0
客服问答:0.3~0.5
代码生成:0.2(错一个符号就编译失败)
top_p(核采样):控制候选 Token 的“动态圈子”
步骤:
按概率从高到低排序。
累加直到≥p,之外的词直接封杀。
在圈内重新归一化采样。
优点:圈子大小随上下文自动伸缩,避免 top_k“一刀切”。
top_k:最直白的“前 k 名入围”
k=50: vocabulary 的 0.1%,速度快。
k=1:贪心解码,完全确定但容易“车轱辘话”。
常与 temperature 组合:temperature=0.7, top_k=40 是官方默认 sweet spot。
seed:让随机可复现
固定 seed=42 后,同样输入→同样输出。
用途
回归测试:升级模型后对比答案是否漂移。
教学演示:录屏时不会“每次不一样”。
一键可调参数 cheat-sheet(保存这张表=调参自由)
彩蛋:把参数玩出花
“随机与确定”混搭
先 top_p=0.9 采样 3 个候选,再用 temperature=0.1 挑最终 → 既控范围又保准确。
动态温度
检测到重复 2 次→自动把 temperature+0.1,直到不重复为止——防车轱辘话神器。
种子轮询
同一问题换 seed=1~5 生成 5 版,投票选多数答案 → 自集成提升准确率。
小结一句话
大模型=概率迷宫+随机抽签;temperature、top_p、top_k、seed 是你手里的 4 个“骰子”,学会掷骰子,才能让这头猛兽指哪打哪!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号