基于python大数据的社交舆情分析系统
原创

1 绪论
1.1 项目背景及意义
社交网络舆情分析与监测平台项目旨在结合社交网络分析和舆情分析与监测系统的技术,为用户提供更精准、个性化的信息服务。该项目的背景源于对用户需求个性化、社交关系影响力的认识,以及对信息传播、产品推广等方面的需求。随着互联网的快速发展,人们在社交网络平台上产生了大量的信息[1],用户面临着信息过载和推荐困境。
1.2 国内外研究现状
在国外,社交网络舆情分析与监测系统领域取得了许多重要的研究成果和进展,吸引了众多学者和科研机构的关注和投入。国外研究者通过图论、复杂网络分析等方法,深入研究社交网络中节点之间的连接关系、社区结构、信息传播路径等,揭示社交网络的特征和规律。利用数据挖掘、机器学习等技术,国外学者致力于评估用户在社交网络中的影响力和传播能力,为社交媒体营销、舆情监测等提供支持[3]。国外研究者将深度学习技术引入推荐系统,通过建模用户兴趣、行为等信息,提高推荐系统的准确性和覆盖范围。结合文本、图片、视频等多模态信息,国外学者开展了跨媒体推荐系统的研究,实现跨领域、多样化的舆情分析与监测。国外研究表明,考虑用户之间的社交关系可以改善推荐系统的效果,提高推荐结果的个性化和准确性。将社交网络中的信息传播、用户互动等因素纳入推荐系统的设计,国外学者探索了更具社交性和用户参与感的推荐模型。国外在社交网络舆情分析与监测系统领域的研究已经取得了许多创新性的成果,涵盖了社交网络结构分析、舆情分析与监测系统设计、社交影响力评估等多个方面。这些研究成果不仅推动了学术界对该领域的深入探索,也为相关行业的实践应用提供了重要的理论支持和技术指导。
在国内,社交网络舆情分析与监测平台领域也受到了广泛关注,许多研究机构和高校积极开展相关研究,取得了一系列重要成果。国内研究者通过对社交网络数据的挖掘和分析,揭示了中国特有的社交网络结构、用户行为模式等特点,为社交网络研究提供了深入理解。国内学者关注用户在社交网络上的行为特征,探索用户兴趣演化、信息传播路径等问题,为舆情分析与监测提供数据基础。国内研究者借助大数据技术,构建用户画像、行为模型,设计舆情分析与监测算法,提高推荐系统的准确性和效果。国内学者将社交网络数据、用户行为数据等多源信息进行融合,开展跨平台、多维度的舆情分析与监测研究[4]。国内研究者重视用户间的社交关系对推荐的影响,开展基于社交网络的推荐算法研究,提高推荐系统的个性化程度。国内学者探索将社交网络中的用户互动、信息传播等因素纳入推荐系统,设计更具社交性和用户参与感的推荐平台。国内在社交网络舆情分析与监测平台领域也有着不俗的研究实力,相关研究涵盖了社交网络结构分析、舆情分析与监测系统设计、社交关系挖掘等多个方面。这些研究成果不仅促进了学术界对该领域的深入研究,也为国内社交网络应用、电商推荐等领域的发展提供了重要支撑和技术支持。
2 关键技术介绍
2.1 Python
Python 是一种高级编程语言,具有简洁、易读、易学的特点,广泛应用于各个领域。Python 采用简洁的语法和丰富的标准库,使得代码易于编写和理解。这种特性使得 Python 成为初学者学习编程的理想选择,同时也提高了开发效率。Python 可以在多个操作系统上运行,包括 Windows、Mac OS 和 Linux 等。这种跨平台的支持使得开发人员可以更加方便地进行开发和部署。Python 拥有庞大的第三方库和工具集,如 NumPy、Pandas、TensorFlow 等,提供了丰富的功能和工具支持[5]。这些库和工具可以帮助开发人员快速构建各种应用,包括数据分析、机器学习、网络开发等。Python 支持面向对象编程(OOP),允许开发人员以对象的方式组织和管理代码。这种编程范式提供了更高的灵活性和可重用性,使得代码更易于维护和扩展。Python 适用于多个领域,包括数据科学、人工智能、Web 开发、自动化脚本等。它被广泛应用于科学研究、工程开发、数据分析和教育等领域。
2.2 MySQL
MySQL 是一种流行的大数据数据库管理系统,以其灵活性、可扩展性和高性能而闻名。MySQL 是一个文档型数据库,它使用 BSON(二进制 JSON)格式来存储数据。相比传统的关系型数据库,MySQL 的文档模型更加灵活,可以存储不同结构的数据,且支持嵌套和复杂的数据类,MySQL 采用分布式架构,可以水平扩展,实现高性能和高可用性。它支持数据的自动分片和负载均衡[6],可以在集群中添加或删除节点,并自动重新分配数据,以满足不断增长的数据需求。MySQL 提供了丰富的查询功能,包括灵活的查询语言和多种查询操作符,如比较、聚合、排序和分组等。它还支持全文搜索和地理空间查询,可以方便地处理各种复杂的数据查询需求。MySQL 的设计目标之一是提供高性能和可扩展性。它使用内存映射文件技术,将数据直接映射到物理内存中,以提高读写性能。此外,它还支持多线程和异步操作,能够有效地处理大量并发请求。
2.3 Flask
Flask 是一个轻量级的 Web 应用框架,它基于 Python 编程语言开发,被广泛应用于构建简单而灵活的 Web 应用程序。Flask 以简洁、易用的设计理念出名。它提供了基本的功能和组件,但没有过多的约束和限制,使得开发人员可以根据自己的需求进行自由的定制和扩展。Flask 是一个微型框架,它的核心只包含了处理 HTTP 请求和路由等基本功能,其他高级功能(如数据库访问、表单处理等)需要通过扩展或第三方库来实现[7]。这种设计使得 Flask 非常轻量级,同时也允许开发人员选择自己喜欢的工具和库。Flask 内置了 Jinja2 模板引擎,它可以帮助开发人员将动态内容和静态页面分离,并提供灵活的模板语法。模板引擎的支持使得开发人员可以更方便地构建美观而可维护的 Web 页面。Flask 对于构建 RESTful 风格的 API 非常友好。它提供了简单的路由和视图函数,可以轻松地处理 HTTP 请求和响应,同时支持多种常用的 HTTP 方法(如 GET、POST、PUT、DELETE 等)。
2.4 数据采集
Python 是一种广泛应用于数据爬取技术的编程语言,具有丰富的库和工具来实现网页数据的爬取和处理。Scrapy 是一个强大的开源网络爬虫框架,基于 Python 编写,提供了高效的数据抓取功能和灵活的数据处理能力。通过 Scrapy,开发人员可以定义爬虫规则、提取数据、处理异常情况等。这两个库是 Python 中常用的 HTML 解析库,可以帮助开发人员从网页中提取特定的信息,并进行结构化处理。它们支持 CSS 选择器和 XPath 表达式,方便快速定位目标数据。对于需要模拟浏览器行为的场景[8],Selenium 是一个非常有用的工具。通过 Selenium 可以控制浏览器执行 JavaScript、填写表单、点击按钮等操作,实现更加复杂的网页数据爬取任务。Python 提供了多种数据存储方式,如 CSV、JSON、数据库(如 MySQL、SQLite、MySQL)等。开发人员可以根据需求选择适合的数据存储格式,并使用相应的库进行数据的写入和读取。
2.5 Echarts
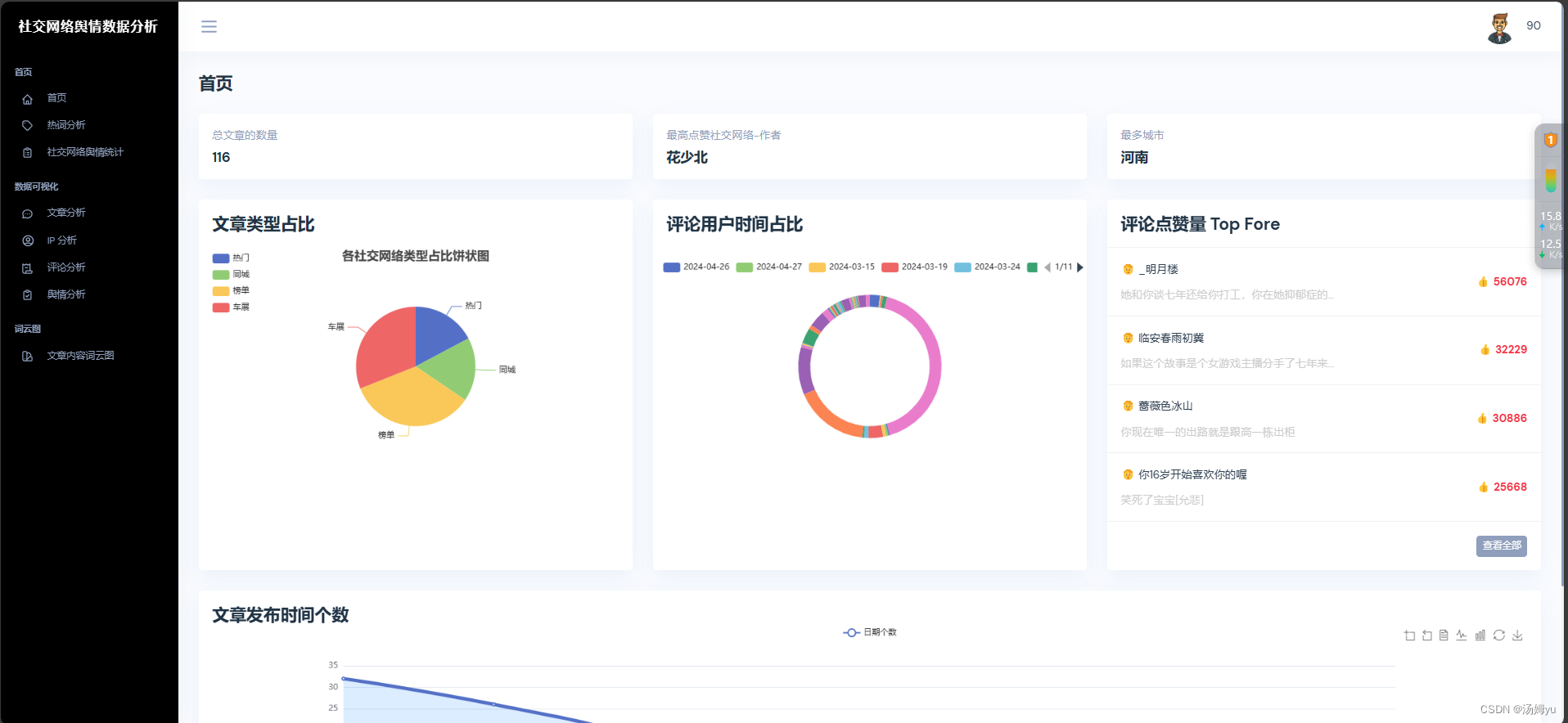
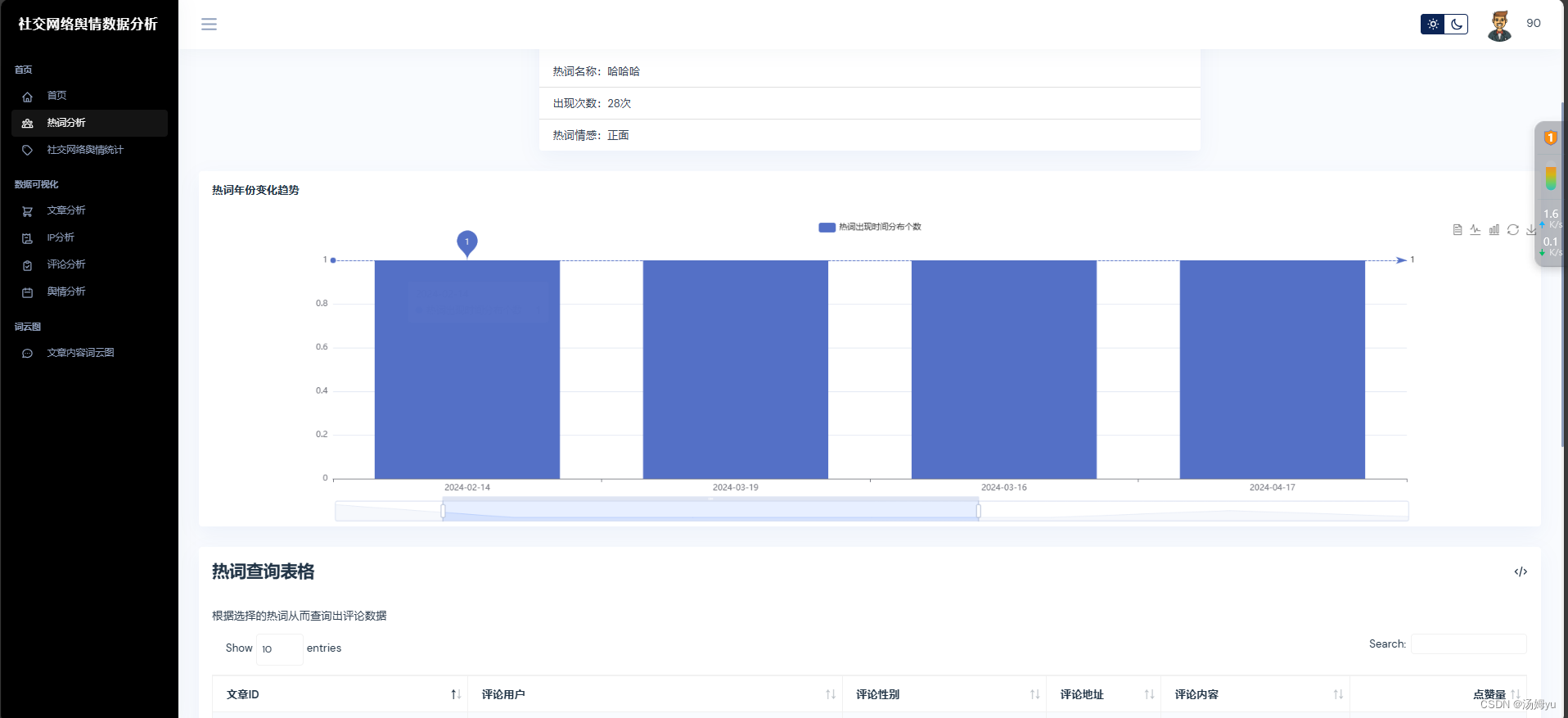
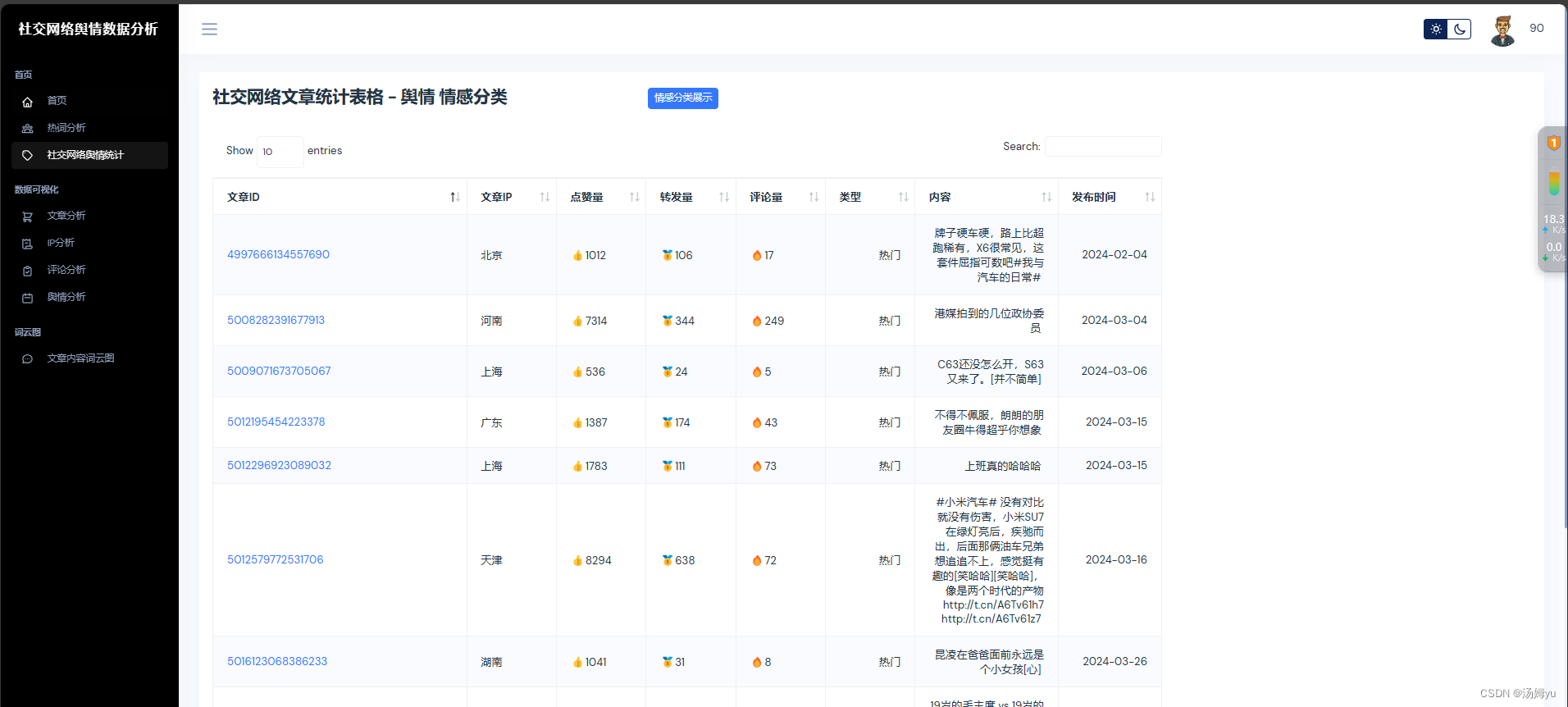
ECharts 是一款开源的数据可视化库,由百度公司开发。它使用 JavaScript 构建,旨在提供丰富的图表类型和灵活的配置,适用于各种数据可视化需求。ECharts 以其简单易用的 API、强大的交互功能和广泛的可定制性而著称,支持多种图表类型,包括折线图、柱状图、饼图、散点图、热力图、地图、漏斗图、树图、雷达图等,提供丰富的交互特性,如缩放、缩放重置、数据提示、数据高亮等,用户可以轻松实现图表之间的联动与交互。
3 系统实现部分
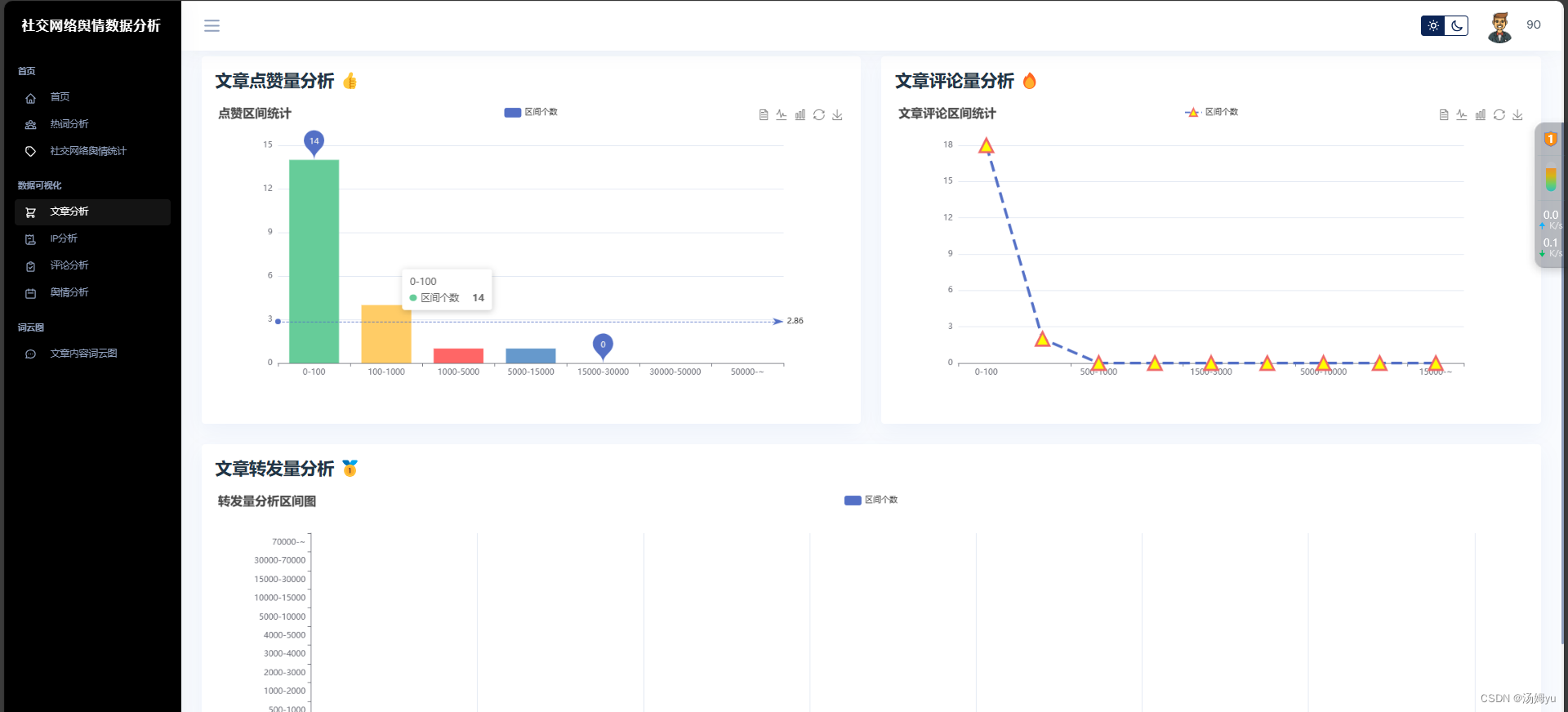
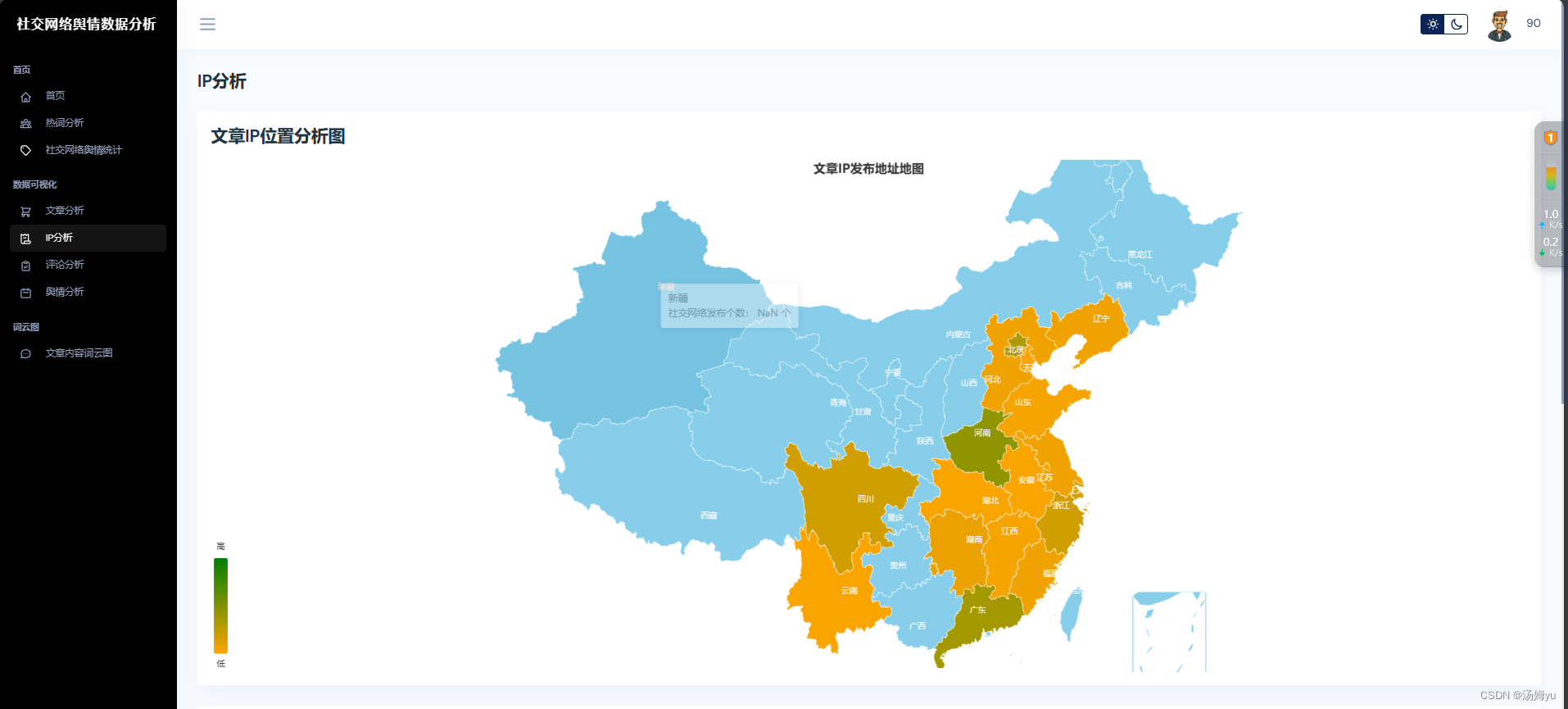
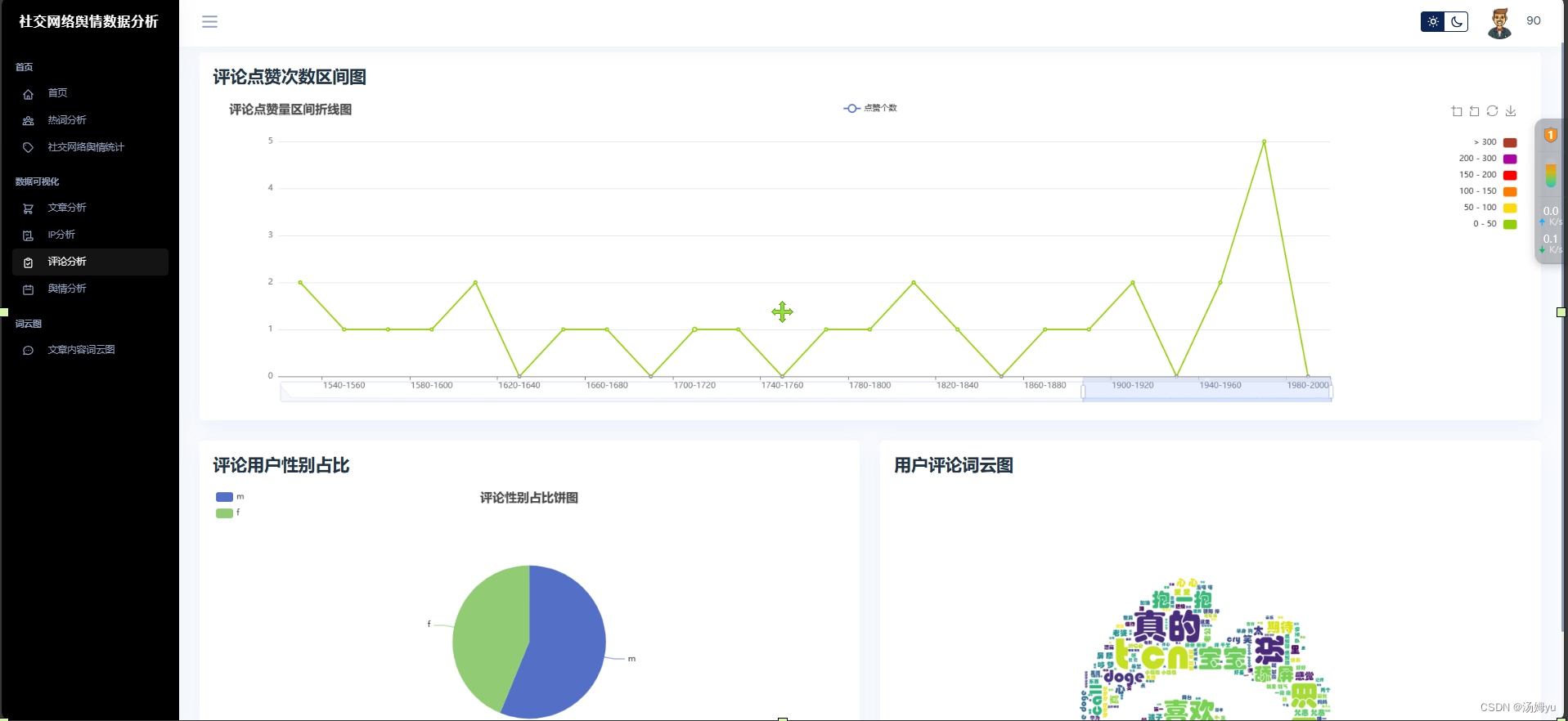
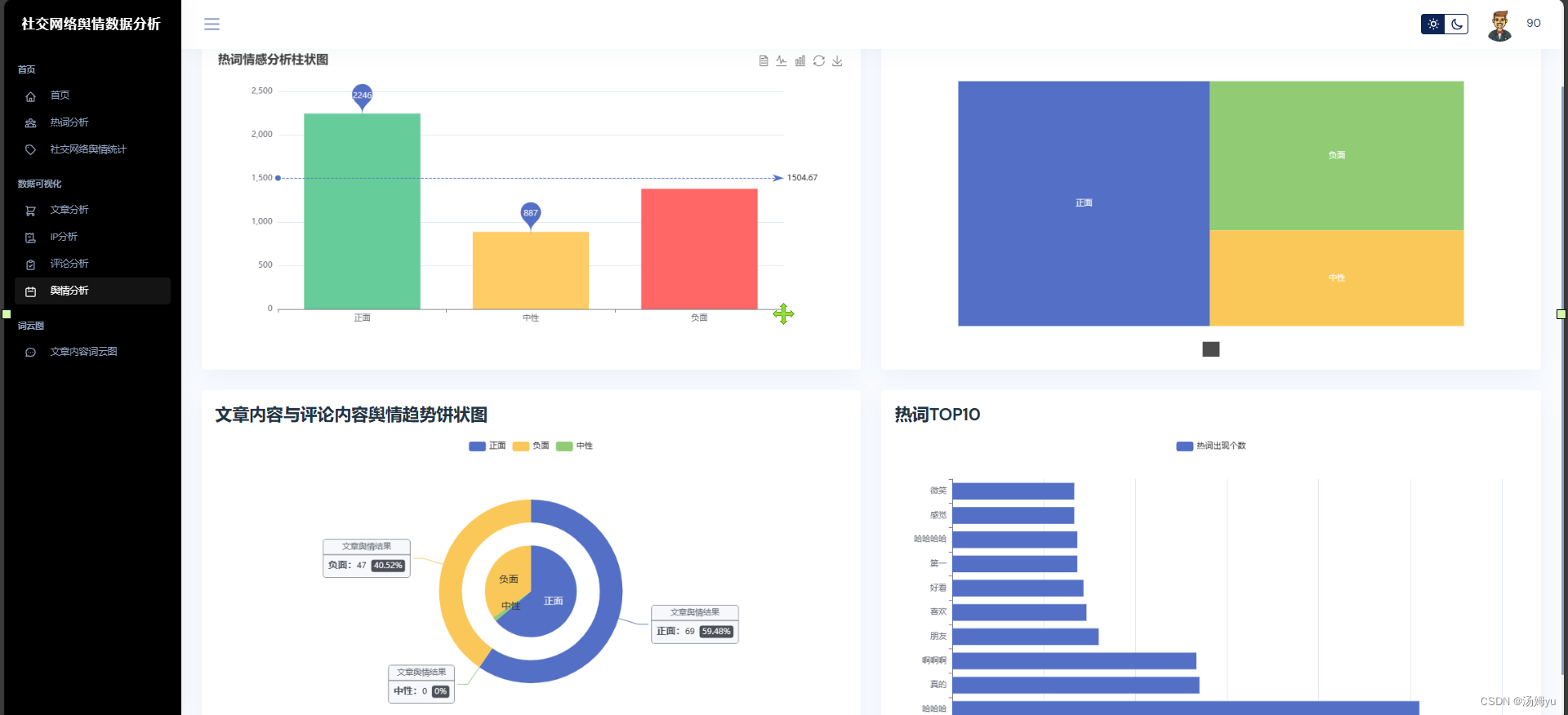

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号