自适应多尺度分解框架:时间序列预测的新范式



论文标题:Adaptive Multi-Scale Decomposition Framework for Time Series Forecasting
论文链接:https://arxiv.org/abs/2406.03751
研究背景
自从Dlinear、Nlinear模型提出以来,时间序列预测(TSF)领域长期存在MLP与Transformer两大技术路线的竞争,今天这篇文章还是以NLP为核心:
- Transformer方法:凭借自注意力机制擅长捕捉长程依赖,但计算复杂度高,且易因过度关注突变点而过拟合。
- MLP方法:计算高效且能建模连续时间点的动态性,但受限于线性映射的“信息瓶颈”,难以捕捉复杂时序模式。
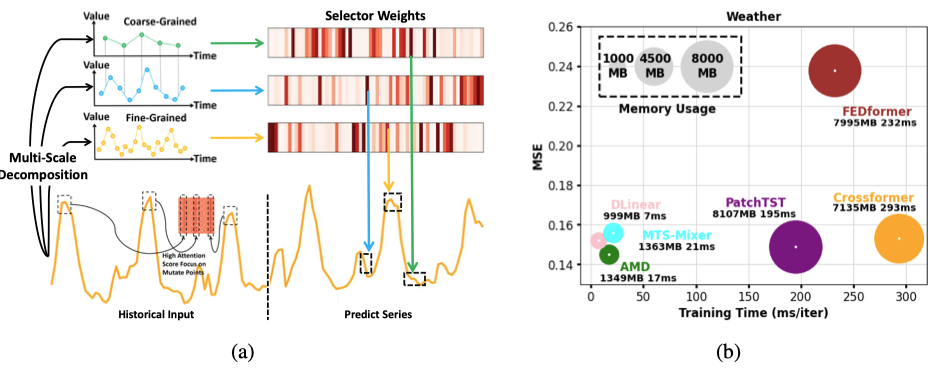
本文提出的自适应多尺度分解(AMD)框架,通过MLP架构实现了多尺度时序模式的高效建模,兼具Transformer的表达能力和MLP的效率。其核心创新在于:
- 多尺度分解:将时间序列分解为不同粒度的时序模式(如小时级突变与月级趋势),避免传统方法仅分解为季节/趋势的局限性。
- 自适应融合:通过自相关分析动态加权不同尺度模式的预测贡献,提升对复杂变化的适应性。
方法设计:三模块协同架构
AMD框架由三个核心模块构成:
1. 多尺度可分解混合(MDM)模块
分解:通过平均池化(AvgPooling)将原始序列逐层下采样,得到多尺度时序。
混合:采用残差连接从粗粒度到细粒度逐层融合信息,保留宏观趋势与微观波动的交互。
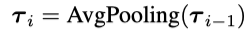
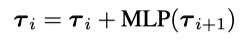
2. 双重依赖交互(DDI)模块
时序依赖:通过残差MLP块建模相邻时间片段的关联。
通道依赖:引入可调节系数beta抑制跨通道噪声,避免无关变量干扰。
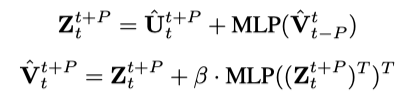
3. 自适应多预测器合成(AMS)模块
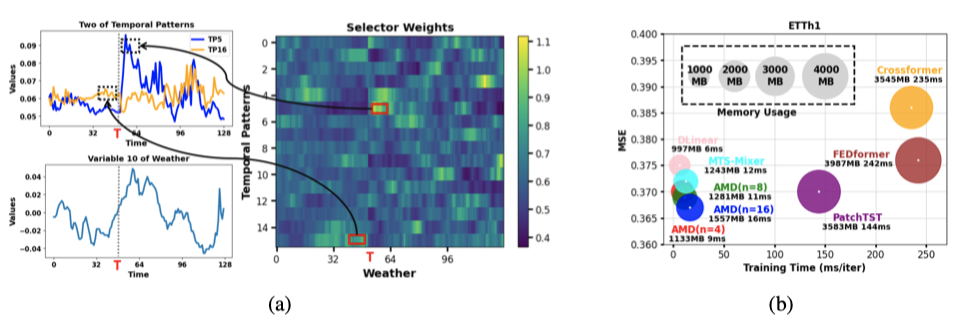
时序模式选择器(TP-Selector):基于门控机制为不同模式分配权重,突出主导模式。
预测器合成:采用稠密MoE(混合专家)结构,加权聚合多尺度预测结果,避免稀疏MoE的负载不均问题。

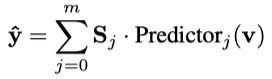
实验验证
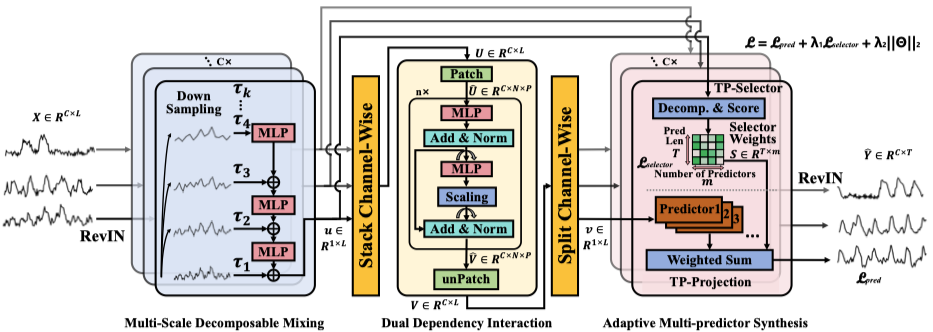
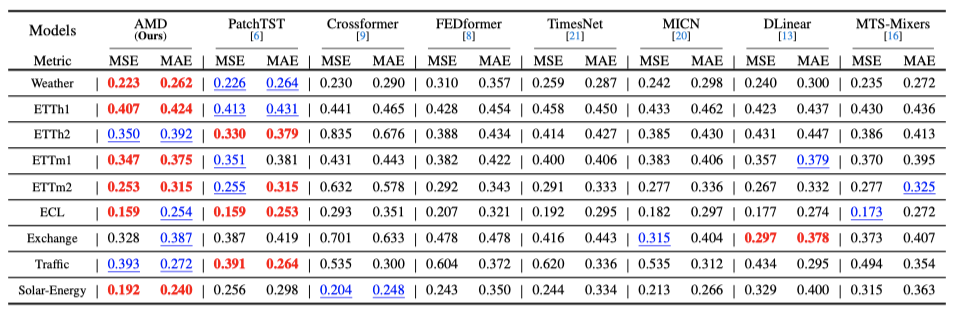
在7个真实数据集(Weather、ETT、ECL等)上,AMD在50/80项任务中达到SOTA,长期预测:在Weather数据集上,AMD的MSE(0.223)优于PatchTST(0.226)和DLinear(0.240)。 短期预测:在PEMS04数据集上,AMD的MAE(0.198)显著低于Crossformer(0.218)。
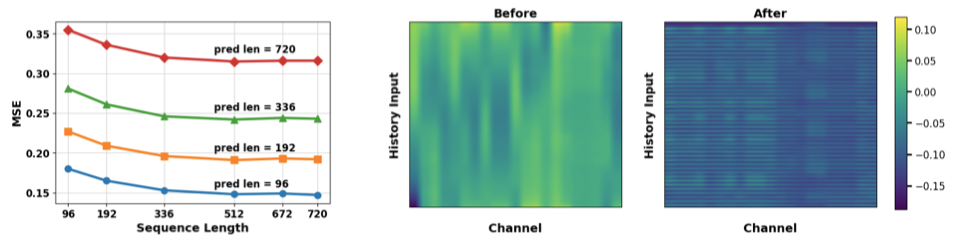
多尺度信息的价值:输入长度L越大,性能提升越显著,证明AMD能有效利用长程历史信息。 通道依赖的陷阱:跨通道交互可能引入噪声,需通过系数beta抑制。
未来方向与讨论
任务扩充,缺失值填充、异常检测等任务效果如何? 探索频域多尺度分解(如结合FFT)进一步降低计算成本。 如何权衡多尺度分解的粒度与计算开销? 稀疏MoE与稠密MoE在时序任务中的优劣? 非平稳数据下AMD的适应性如何?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号