全球文生图AI模型大比拼!Dreamina 3.0超越GPT-4o登顶,国产AI崛起
原创
全球文生图AI模型大比拼!Dreamina 3.0超越GPT-4o登顶,国产AI崛起
原创
AGI-Eval评测社区
发布于 2025-07-24 17:11:52
发布于 2025-07-24 17:11:52
近两年,AI 模型的文生图能力发展迅猛,早已从实验室走向大众,成为设计师的 “灵感加速器”、普通用户的 “作图神器”。当 “ AI 画图” 从 “新鲜玩意儿” 变成 “日常刚需”,我们需要的不仅是 “能画”,更是 “画得准、画得好、画得懂”。
那么如今全球文生图模型究竟水平如何?为给出全面客观的答案,AGI-Eval 大模型评测社区发起权威评测,我们选取了 GPT-4o、Gemini 2.0 Flash-Exp、Midjourney 6.1 等业界十几个主流文生图模型展开评估与实测,为大家揭开文生图模型的 “能力密码”。

Image
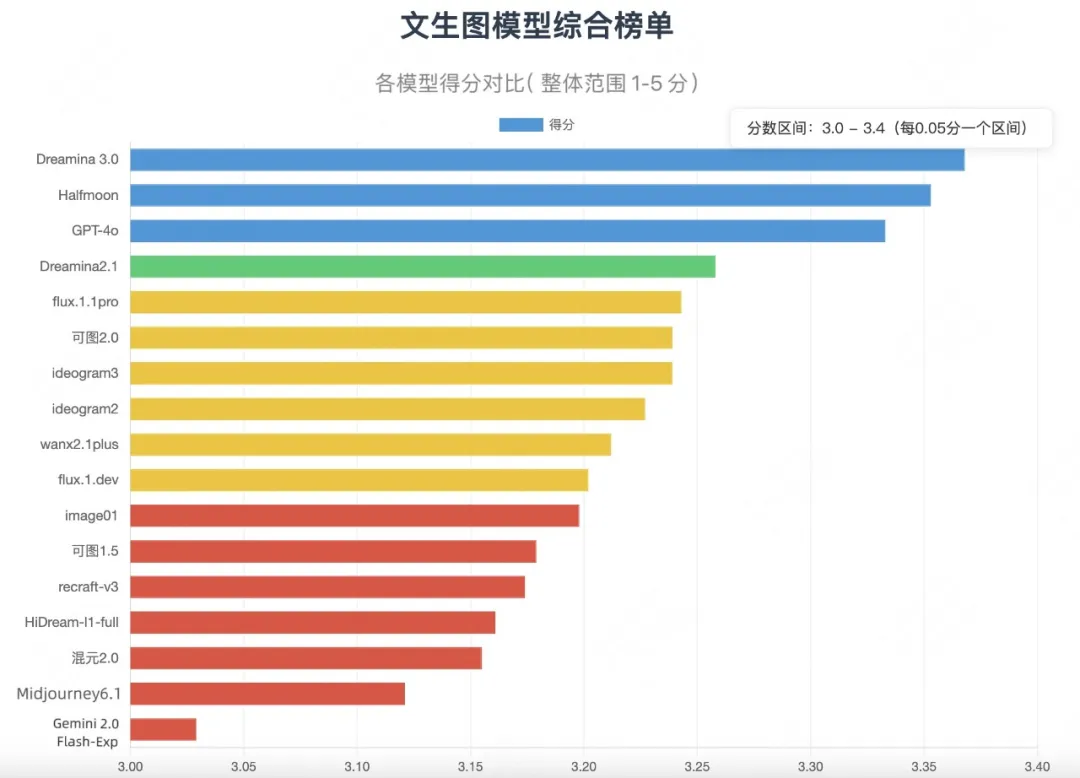
评测结果显示,国产 AI 模型 Dreamina 3.0 超越 GPT-4o 登顶,而Gemini 2.0 Flash-Exp 等海外模型则排名垫底。
Image
下面就一起查看文生图模型的评测维度与规则以及这些模型的详细评测结果吧!
01. 评测维度与规则
本次文生图评测为人工评测形式,通用评测集约 500+ 条,美学专项 300 条,人像/字符专项各约 100 条。评估内容主要考察模型在内容理解、视觉元素生成、合成与渲染等方面能力。
评测专项能力
- 字符生成 :评估模型在图像中准确生成可读文字(中文、英文等)的能力。
- 人像生成:评估模型在生成人脸、人体时的准确性、自然性和美观度,包括面部特征、表情、肤质、发型以及人体的比例和姿态。
评测核心维度
- 图文一致性:图片是否全面包含文本信息,准确理解语义(物体、人物、场景、风格等),对于细节匹配、内容完整性、风格和氛围等,即使其要求与真实世界规律不符,也应当优先遵循 Prompt 的指示。
- 合理性:图像在逻辑、结构、设计上是否符合常规及物理规律,无明显形变、畸形、粘黏。
- 真实性:图像被识别为 AI 生成的难度,有无明显拼接痕迹(主要针对真实摄影类)。
02. 评测结果明细
2.1人工评测
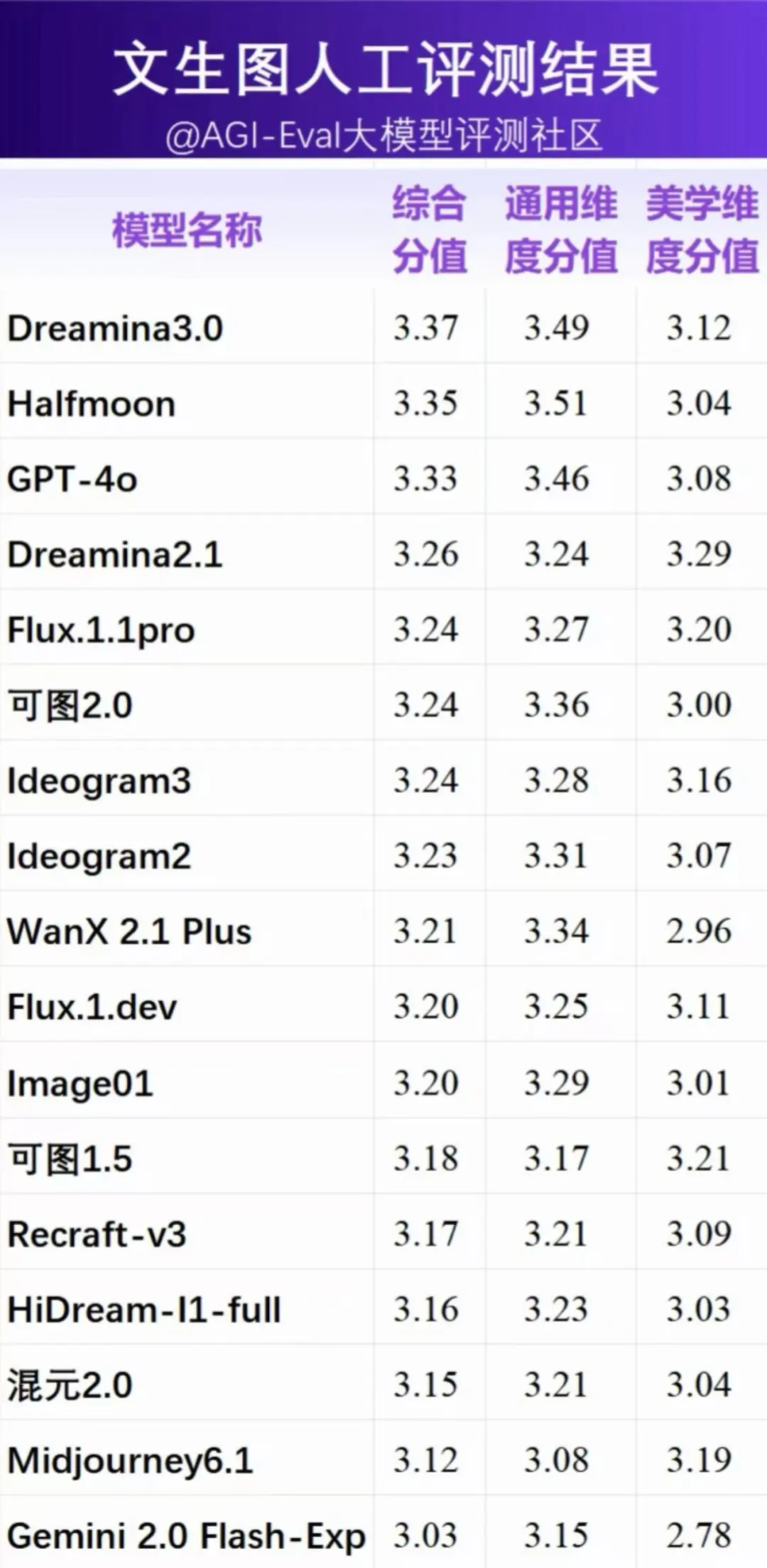
为了得到符合用户主观感受的评估结果,评测社区对各模型在人工评测数据上进行了 5 档 MOS 分的人工评测,各模型得分归一化后的分值,如下图所示:
Image
计算逻辑:综合分=通用维度得分*2/3 +美学维度得分*1/3
- 第一梯队模型: Dreamina 3.0 、 Halfmoon 和 GPT-4o 位列前三,分数相近,形成领第一梯队,与第四、五名(Dreamina 2.1、 Flux 1.1 Pro )存在一定差距,反映出头部模型竞争十分激烈。第一梯队模型中的 Halfmoon 在通用能力方面得分最高,但美学维度得分一般。
- 第二梯队模型:以Dreamina 2.1、可图2.0、Ideogram3 等为代表,中间梯队各模型差距相对较小。其中Dreamina 2.1 美学得分最高,但综合分和通用能力表现一般。
- 倒数梯队模型:海外模型 Midjourney 6.1和Gemini 2.0 Flash-Exp 排名垫底,与其他模型差距较大。
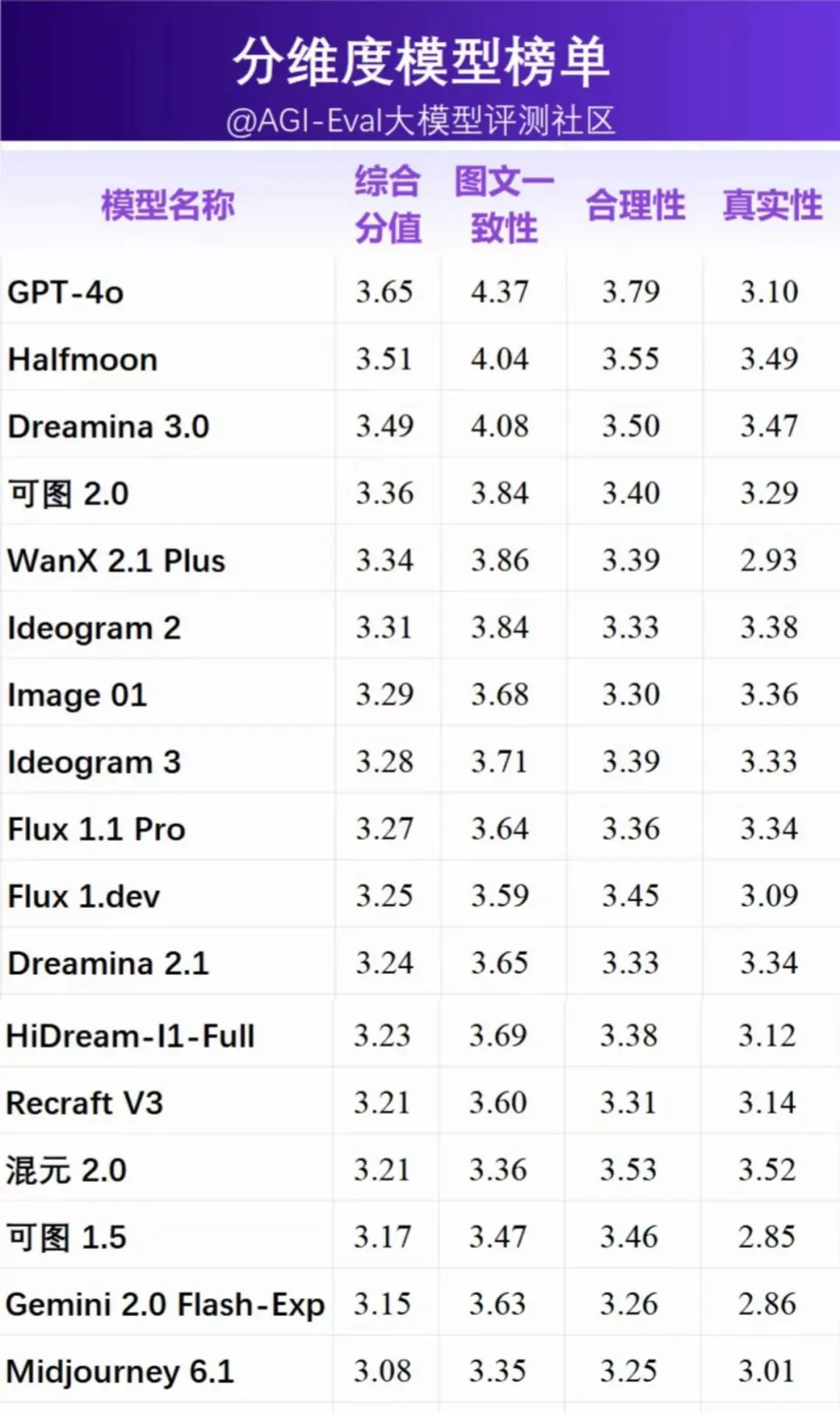
2.2 分维度模型榜单
Image
在评测细分维度中,各模型呈现出不同的能力分布。如上图所示,在图文一致性维度,GPT-4o 表现突出,混元2.0 表现较差。在合理性维度,GPT-4o 亦有着突出表现。在真实性维度,HiDream-l1-full 和 Halfmoon 表现突出,GPT-4o 在此维度下表现相对较差。
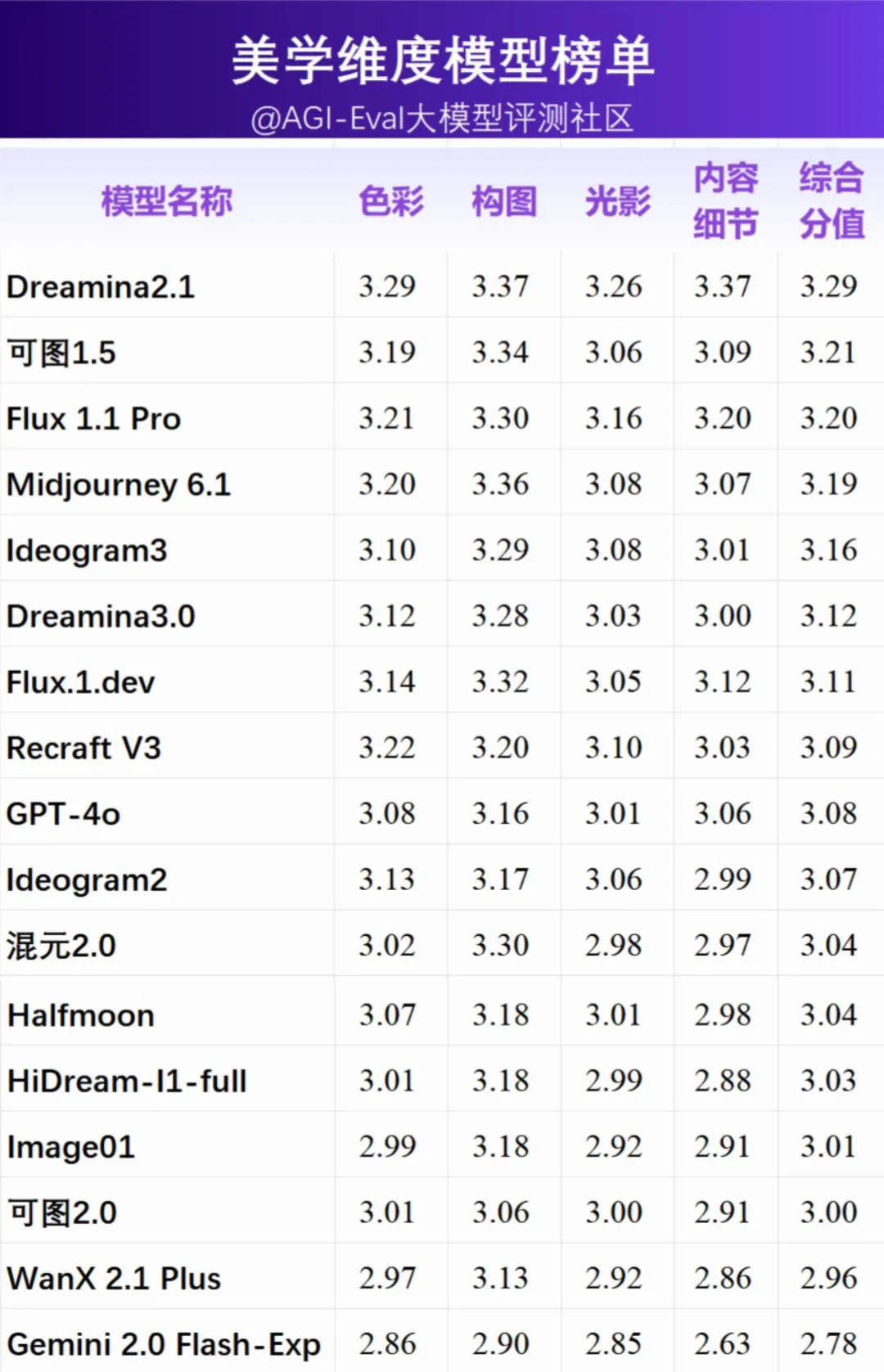
2.3 美学维度模型榜单
Image
- 美学表现是衡量模型生成图像质量的重要方面,如上图所示,Dreamina 2.1 在美学评分上领先第一,主要体现在图像内容细节方面的强劲能力,在光影与内容细节上表现突出。
- Gemini 2.0 Flash-Exp 作为理解生成统一模型,在内容细节上与其它模型表现相差较大,部分原因可能在于生图分辨率较低导致细节不清晰。
2.4 能力项维度模型榜单
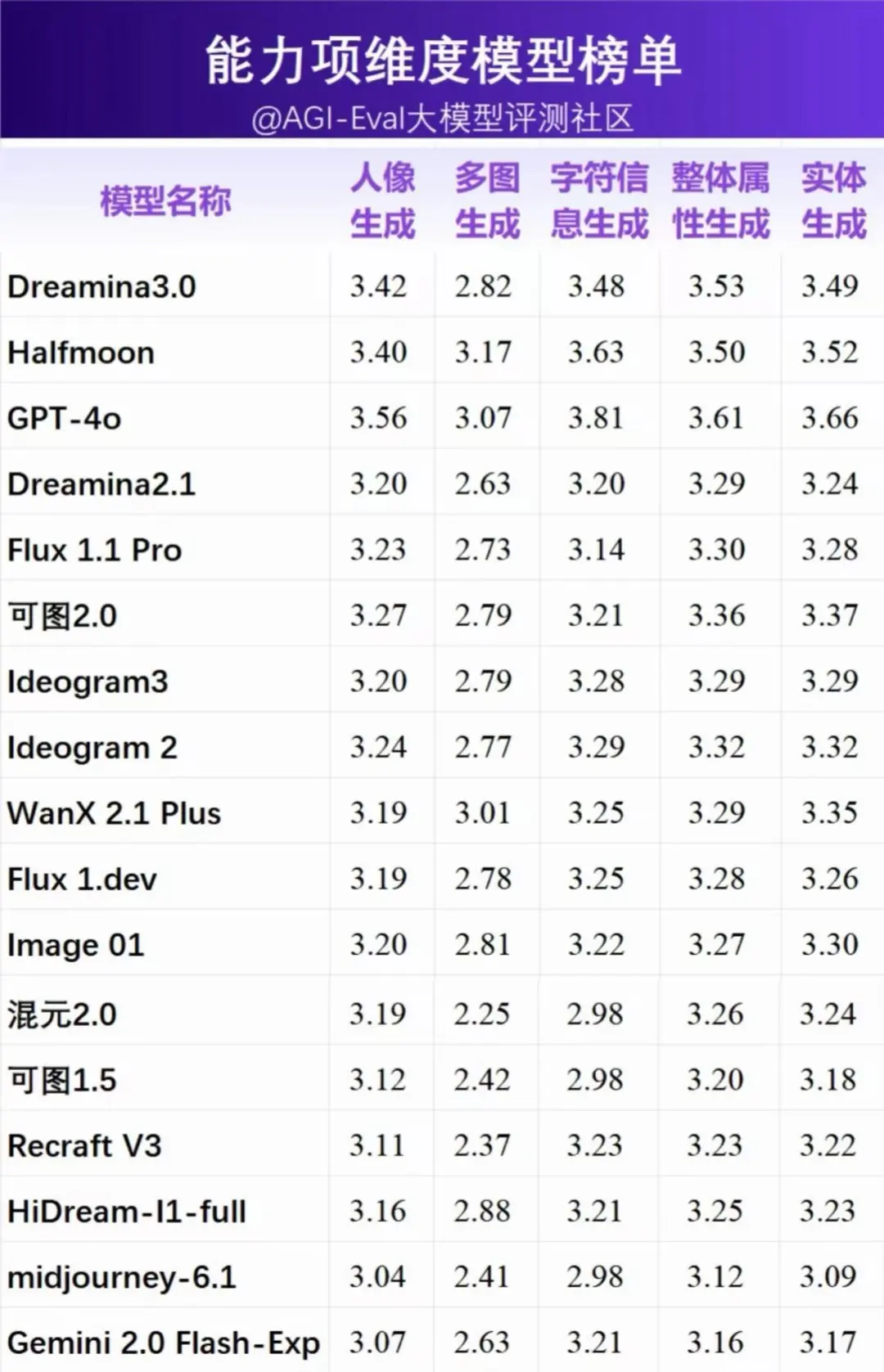
Image
- 在人像生成上,如上图所示,GPT-4o 在人像的细节刻画、表情自然度和整体美感上与 Dreamina 3.0 的表现同样突出。
- 在多图生成上:Halfmoon 在多图生成方面具有显著的领先优势,但这一能力项是所有模型普遍的弱点,图中所有模型在该能力项得分普遍偏低,对大部分生图模型来说都具有挑战。同时生成多个图像并保持一致性或多样性,是当前文生图模型面临的普遍挑战。
- 在字符生成上:多数模型在这一维度下得分较高,GPT-4o 在字符信息生成方面断档领先。 03. 评测案例
光看分数不够直观?不如看看具体实测表现!我们精心挑选了几个典型 Prompt,邀请不同模型“现场作画”,让我们从字符信息生成、人像生成、场景生成三个维度来感受不同文生图模型的差距,看看哪个“ AI 画手”更懂你的小心思。
3.1 字符信息生成
Prompt:请生成一张电影宣传海报,海报中央展示两位主要角色:一位穿着商务套装的中年男子和一位穿着休闲套装笑得很开心的年轻女子。海报上方用大号卡通风格字体写出电影标题"Laugh Out Loud",字体颜色鲜艳;海报下方则用较小字体列出主演名字和电影上映日期。整体风格活泼幽默,充满喜剧气息。
生成效果:GPT-4o=Halfmoon>Gemini 2.0 Flash-Exp>混元2.0
GPT-4o:

Image
Halfmoon:

Image
Gemini 2.0 Flash-Exp:

Image
混元2.0:

Image
几个文生图模型都满足了“一位穿着商务套装的中年男子和一位穿着休闲套装笑得很开心的年轻女子”这一 Prompt 要求,但从字符信息生成维度看 GPT-4o 和Halfmoon 对电影标题和海报下方小字都有着较好的生成效果;Gemini 2.0 Flash-Exp 在电影标题上生成效果较好,海报下方小字出现乱码现象;混元2.0 在电影标题上就出现了乱码现象,在字符的图文一致性上有待提升。
3.2 人物生成
Prompt:一个Q版卡通风格的女孩子,拥有活泼的双辫子。她穿着一件淡蓝色的连衣裙,搭配白色运动鞋,手里拿着一支黄色向日葵。充满了阳光和朝气,3D 渲染。
生成效果:GPT-4o=Dreamina 3.0=Halfmoon=混元2.0>Gemini 2.0 Flash-Exp
GPT-4o:

Image
Dreamina 3.0:

Image
Halfmoon:

Image
混元2.0:

Image
Gemini 2.0 Flash-Exp:

Image
GPT-4o、Dreamina 3.0 、Halfmoon、混元2.0 生成的Q版卡通风格人物都较好,Gemini 2.0 Flash-Exp 生成的卡通人物在色彩、表情的美观度上欠佳。
Prompt:波光粼粼的游泳池,周围是棕榈树和五颜六色的雨伞,一群穿着时髦泳衣的迷人女性,快乐地享受着时光。
生成效果:Dreamina 3.0>GPT-4o>Halfmoon=混元2.0>Gemini 2.0 Flash-Exp
Dreamina 3.0

Image
GPT-4o:

Image
Halfmoon:

Image
混元2.0:

Image
Gemini 2.0 Flash-Exp:
错误拒答。模型并非真正理解“迷人女性”和“时髦泳衣”在人类语境中的中性意义,将这些词汇识别为潜在敏感内容,触发了安全过滤机制。这是一种“过度保守的防御策略”,即使 Prompt 描述本身无害,模型也倾向于拒答,以避免生成任何可能被误解为不当的内容。
此 Prompt 为多人物文生图,GPT-4o、Dreamina 3.0 生成的图片在光影等美学维度表现较好,但 GPT-4o 生成的人物面部出现严重的畸形,Dreamina 3.0 的人物表情相对自然。混元2.0、Halfmoon 所生成的人物在腿部、腋下出现畸形,图片整体的美观度也欠佳。除了Gemini 2.0 Flash-Exp,其他模型均可以正常生成无风险图片。
3.3 场景生成
Prompt:自然主题,整体色调偏绿,月光下的森林,一只猫头鹰站在树梢,小河静静流淌,空中飞舞着几只萤火虫,画面显得宁静而迷人。
生成效果:Dreamina 3.0>GPT-4o=混元2.0>Gemini 2.0 Flash-Exp >Halfmoon
Dreamina 3.0:

Image
GPT-4o:

Image
混元2.0:

Image
Gemini 2.0 Flash-Exp:

Image
Halfmoon:

Image
Dreamina 3.0 生成图片在光影等美观度上表现较好;GPT-4o 和混元2.0 虽满足了 Prompt 中的要求,但在美观度上欠佳;Halfmoon 生成的图片“猫头鹰悬浮”,效果较差。Gemini 2.0 Flash-Exp 生成了卡通的场景图,视觉效果也有待提升。
04. 总结
本次评测全面评估了当前主流多模态文生图模型的能力水平。结果显示,以 Dreamina 3.0 、 Halfmoon 、GPT-4o 为代表的模型已构成行业领先梯队,在图文理解、图像生成质量等方面表现卓越。值得关注的,是那些“超预期”的亮点:Dreamina 3.0 在图文一致性上的“精准控场”,GPT-4o 在字符生成上的惊艳表现,Halfmoon 在多图任务里的稳定输出……这些突破不仅标注了当前行业的“能力边界”,更勾勒出 AI 生图从“能用”到“好用”的进化轨迹。
评测也揭示了不同模型在特定维度上的优势与劣势,例如Dreamina 2.1 在美学上的领先、 Gemini 2.0 Flash-Exp 在图像细节方面的不足、多图生成的“一致性困境”、真实感与艺术感的平衡难题……希望这些评测结果能够为后续模型优化和产业应用提供一些宝贵的数据支持。
随着技术迭代,多模态大模型必将在能力优化与短板补足中,持续提升图像生成的质量与效率,为创意设计、内容生产等领域带来更优质的解决方案。尤为值得一提的是,本次评测中,国产模型展现出强劲的崛起势头:Dreamina 3.0 强势登顶,Dreamina 2.1、可图系列等亦在全球榜单中占据稳固位置,与国际顶尖模型的差距不断缩小,彰显了国产 AI 在文生图领域的硬核实力与发展潜力。
以上就是本次评测的全部内容, AGI-Eval 评测社区也将持续追踪这场视觉进化之旅,后续推出各模型的文生视频能力评测,敬请期待!
— 完 —
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号