MiniMind:3小时训练26MB微型语言模型,开源项目助力AI初学者快速入门
原创
MiniMind:3小时训练26MB微型语言模型,开源项目助力AI初学者快速入门
原创
nine是个工程师
发布于 2025-07-08 14:59:04
发布于 2025-07-08 14:59:04
开发|界面|引擎|交付|副驾——重写全栈法则:AI原生的倍速造应用流
来自全栈程序员 nine 的探索与实践,持续迭代中。
欢迎关注评论私信交流~
在大型语言模型(LLaMA、GPT等)日益流行的今天,一个名为MiniMind的开源项目正在AI学习圈内引起广泛关注。这个项目让初学者能够在3小时内从零开始训练出一个仅26.88MB大小的微型语言模型,体积仅为GPT-3的七千分之一,却完整覆盖了从数据处理到模型对齐的整个流程。
项目亮点:极简入门与完整流程
MiniMind最吸引人的特点在于其极低的学习门槛和完整的训练流程:
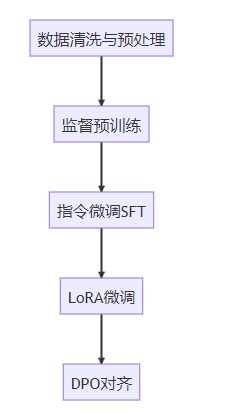
整个项目设计为"从零开始"的学习路径,特别适合想要理解语言模型底层原理的开发者。据Gitee项目页面显示,MiniMind已经实现了:
- 基础版26.88MB微型模型
- 支持MoE(混合专家)架构的扩展版本MiniMind-V
- 完整的训练代码和详细文档
技术特色:轻量化与高效率
与动辄数百GB的主流大模型相比,MiniMind的轻量化设计使其具有独特优势:
特性 | MiniMind | GPT-3 (对比) |
|---|---|---|
模型大小 | 26.88MB | ~175GB |
训练时间 | 3小时 | 数周 |
硬件需求 | 普通PC | 专业GPU集群 |
学习曲线 | 平缓 | 陡峭 |
该项目特别适合以下场景:
- 教育领域:帮助学生理解LLM基本原理
- 研究领域:快速验证新想法
- 资源受限环境:边缘设备部署
开源生态与学习资源
MiniMind已在GitHub开源,配套资源包括:
- 完整训练代码库
- 详细教程文档
- 社区讨论区
- 预训练模型权重
掘金技术社区上有开发者分享的学习笔记显示,项目已经涵盖了从预训练到强化学习对齐的完整流程,为初学者提供了难得的一站式学习体验。
对于想要入门AI领域却又被大模型复杂度吓退的开发者来说,MiniMind无疑打开了一扇新的大门。
正如新浪科技报道所言,这类"小而美"的开源项目正在降低AI技术的门槛,让更多人有机会参与到这场技术革命中来。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号