边缘计算新底座:基于VPP+DPDK的开放智能网关
原创
边缘计算新底座:基于VPP+DPDK的开放智能网关
原创
星融元Asterfusion
发布于 2025-07-07 16:24:29
发布于 2025-07-07 16:24:29
当今网络流量激增(视频流、云服务、IoT、5G),传统基于专用硬件和封闭操作系统的网络设备(如路由器、交换机、防火墙)面临巨大挑战:成本高昂、升级缓慢、生态封闭、创新受限。企业和服务提供商迫切需要一种更灵活、更具成本效益且高性能的网络解决方案。正是在此背景下,基于开源软件和通用硬件的开放网络技术应运而生,而 VPP (Vector Packet Processing) 与 DPDK (Data Plane Development Kit) 的结合,正是这一革命浪潮的核心引擎。
VPP + DPDK:软件定义的高性能网络新范式
VPP 作为 Linux 基金会 FD.io 项目的核心,目标明确:在通用 CPU(x86, ARM, POWER)上,通过纯软件实现媲美甚至超越传统专用网络硬件的性能。它不再依赖昂贵的 ASIC 和专属操作系统,而是巧妙地结合了先进的软件架构和硬件加速技术。
VPP:矢量包处理(Vector Packet Processing)
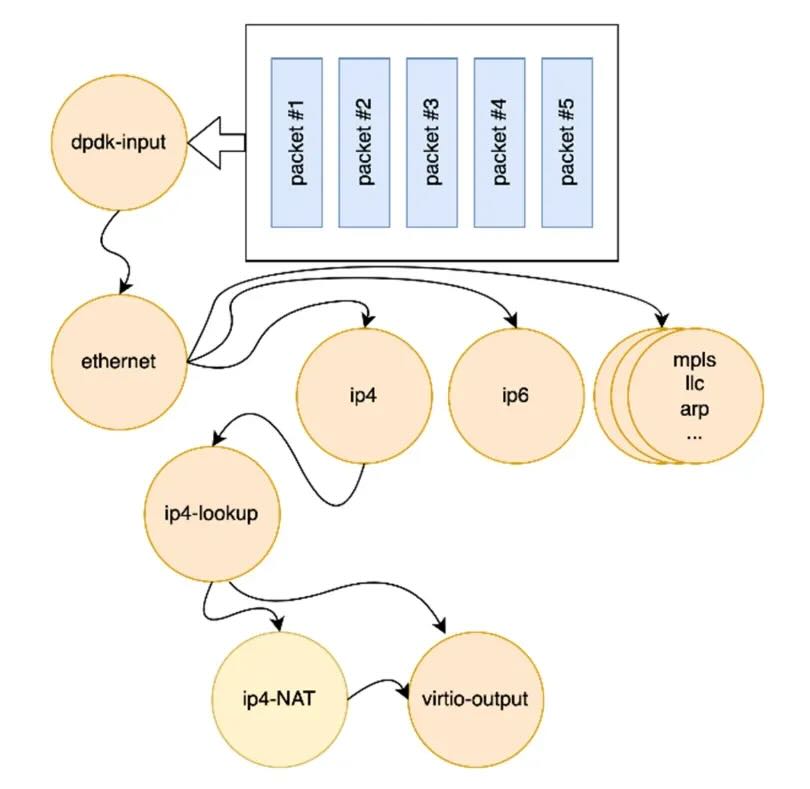
传统网络处理(标量处理)的瓶颈在于“一个一个来”:
- 处理粒度小: 一次仅处理一个数据包。
- 开销占比大: 每个包独立经历资源分配、缓存管理、上下文切换,在高IO时,这些开销甚至接近数据处理本身,效率低下。
VPP 的革命性在于“批量并行干”
- 批量化: 将多个数据包(如64个)聚合成一个“矢量 (Vector)”,在每个处理节点上一次性完成整个矢量的操作。这摊薄了每个包的固定开销(资源准备、上下文切换),显著提升效率。
- 并行化: 充分利用现代 CPU 的 SIMD (Single Instruction Multiple Data) 指令集。一条指令可同时处理多个数据包中的相同字段(如校验和、IP地址查找)。例如,在支持 SVE2 的 ARM Neoverse N2 处理器上,一条指令可同时处理高达64个 IPv4 地址,极大加速核心网络操作。
- 优化缓存利用: 批量处理允许一次性将更多相关数据(包头或完整包)加载到高速的 CPU L1/L2 缓存中。减少了与慢速主内存的交互次数。例如,64KB L1 缓存可容纳数千个IP包头,极大提升查找和处理速度。
简言之,VPP 通过“打包处理、并行计算、缓存优化”三大法宝,将通用CPU的网络处理能力榨取到极致。
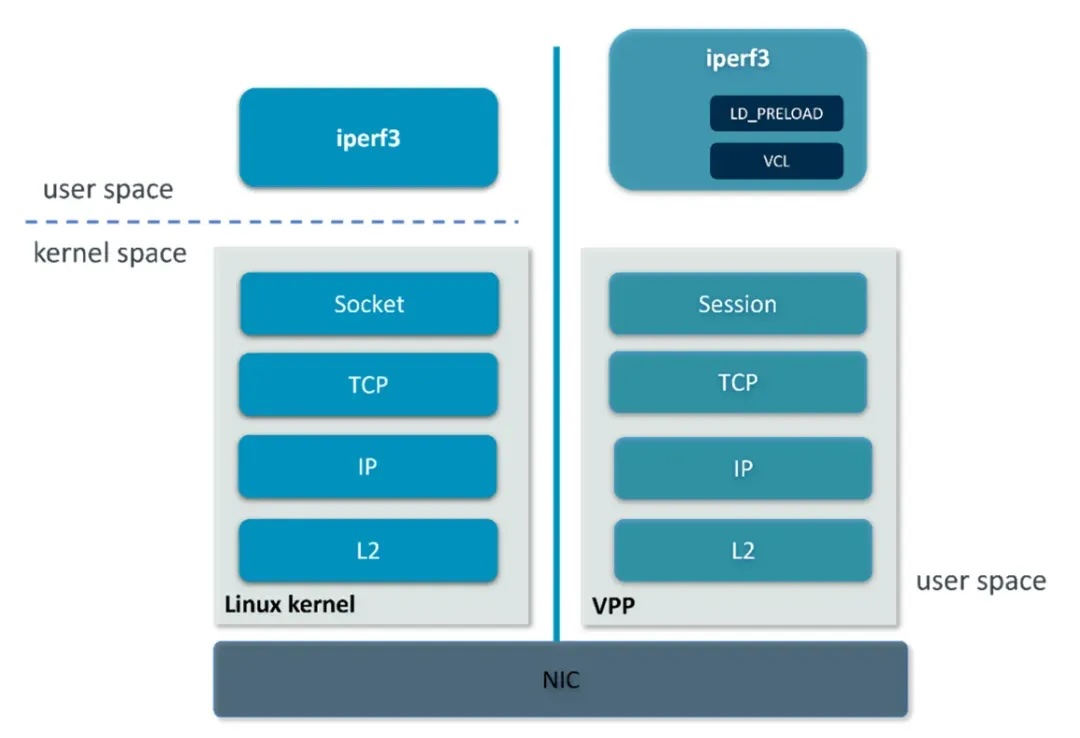
用户态网络协议栈:挣脱内核束缚
传统 Linux 内核协议栈为通用性设计,但在高性能网络场景下成为瓶颈:
- 内核/用户态切换: 数据处理需频繁跨越边界,产生高延迟。
- 协议栈分层开销: OSI 各层独立处理,数据拷贝和协议解析层层叠加。
- 单线程与中断限制: 难以充分利用多核,软中断和调度成为瓶颈。
VPP 在用户态实现了完整的 L2-L4 (甚至 L7) 网络协议栈,带来颠覆性优势:
- 消除模式切换: 全程用户态运行,结合 DPDK 绕过内核直接访问网卡,彻底消除内核/用户态切换开销。
- 协议融合处理: IP、TCP、Session 等协议处理在同一高效内存区域协同完成,大幅减少层间数据拷贝和传递。
- 真正的多核并行: 用户态线程池灵活调度,将网络流量近乎线性地分布到所有CPU核心,突破单核和内核调度限制。
DPDK:用户态直达硬件的桥梁
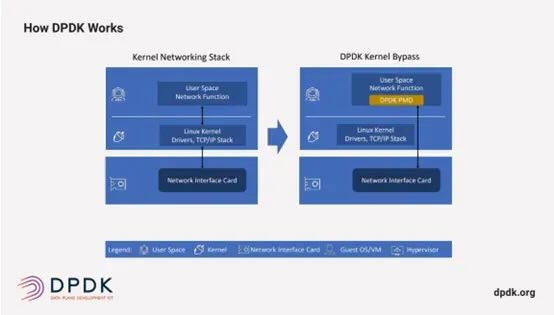
DPDK 绕过 Linux 内核,在用户态执行数据包处理以最大限度地提高网络性能,DPDK通过使用在用户态运行的“轮询式驱动程序”(PMD)来实现这一点,该驱动程序不断检查传入的数据包队列以查看新数据是否已到达,从而实现高吞吐量和低延迟。PMD 在数据链路层(L2)工作。
VPP 专注于从 L2-L7 的网络协议,并使用 DPDK 作为其网络驱动程序。这种集成将 DPDK 的 L2 性能与 VPP 在 L3 到 L7 上的灵活性相结合。
VPP 与 DPDK 的完美融合
- 直接硬件访问: VPP 使用用户态的 DPDK 来直接访问网络硬件,从而避免了传统 Linux网络协议栈中的内核态与用户态切换,消除了大部分与内核相关的开销。
- 直接内存访问: VPP 通过将网络设备的 DMA 内存区域映射到用户态,减少了内存拷贝和上下文切换。
通过与 DPDK 相结合,VPP 实现了完整的用户态网络协议栈,并大幅度提升网络处理性能。
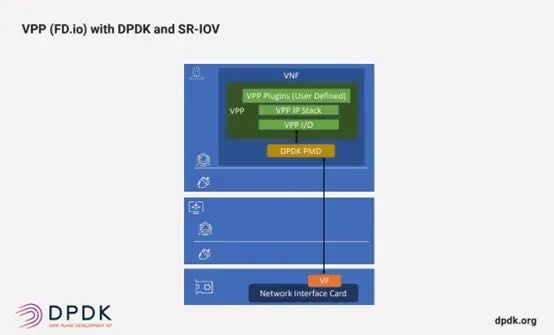
开放网络硬件平台:释放 VPP + DPDK 潜能
厂商利用 VPP + DPDK 技术,在基于通用处理器(如 Marvell ARM, Intel x86)的开放硬件平台上,打造出极具竞争力的网络产品:
智能网关平台
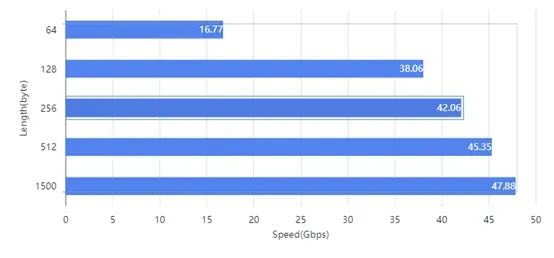
- 基于 Marvell OCTEON 10 ARM Neoverse N2 (8核) 紧凑型设备。
- 加载 100万条全量 BGP 路由 时,仍能提供 48Gbps 的路由转发能力 (相当于同时处理 3000 路 4K 视频通话)。
- 相比非 VPP 方案的同等硬件,性能提升 10 倍以上,满足企业、城域网边缘、云边缘网关需求。
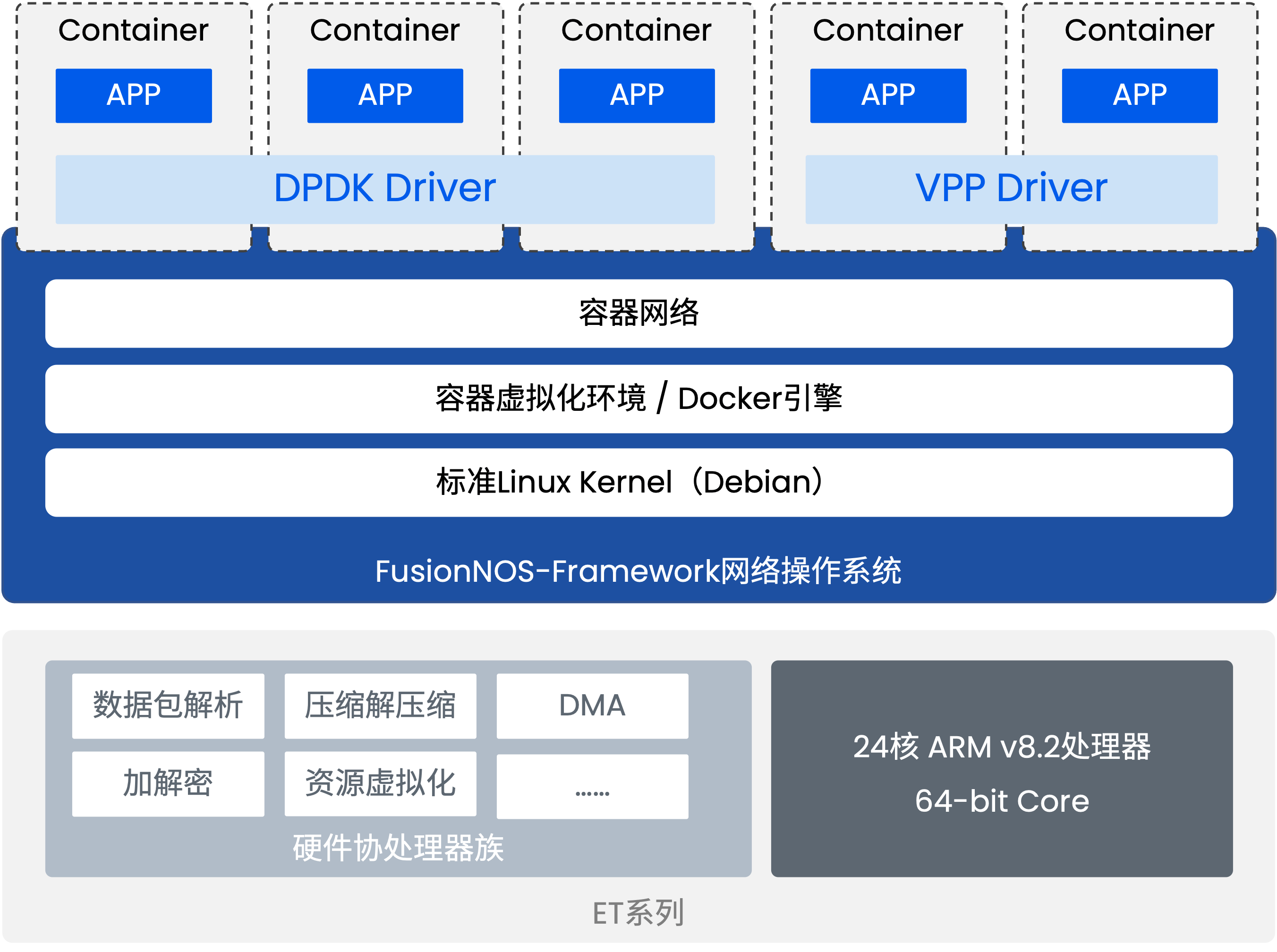
开放计算平台: 提供底层 OS、容器化环境、开发套件,支持 x86 应用迁移和自研应用快速开发,适用于边缘计算、AIoT 等场景。
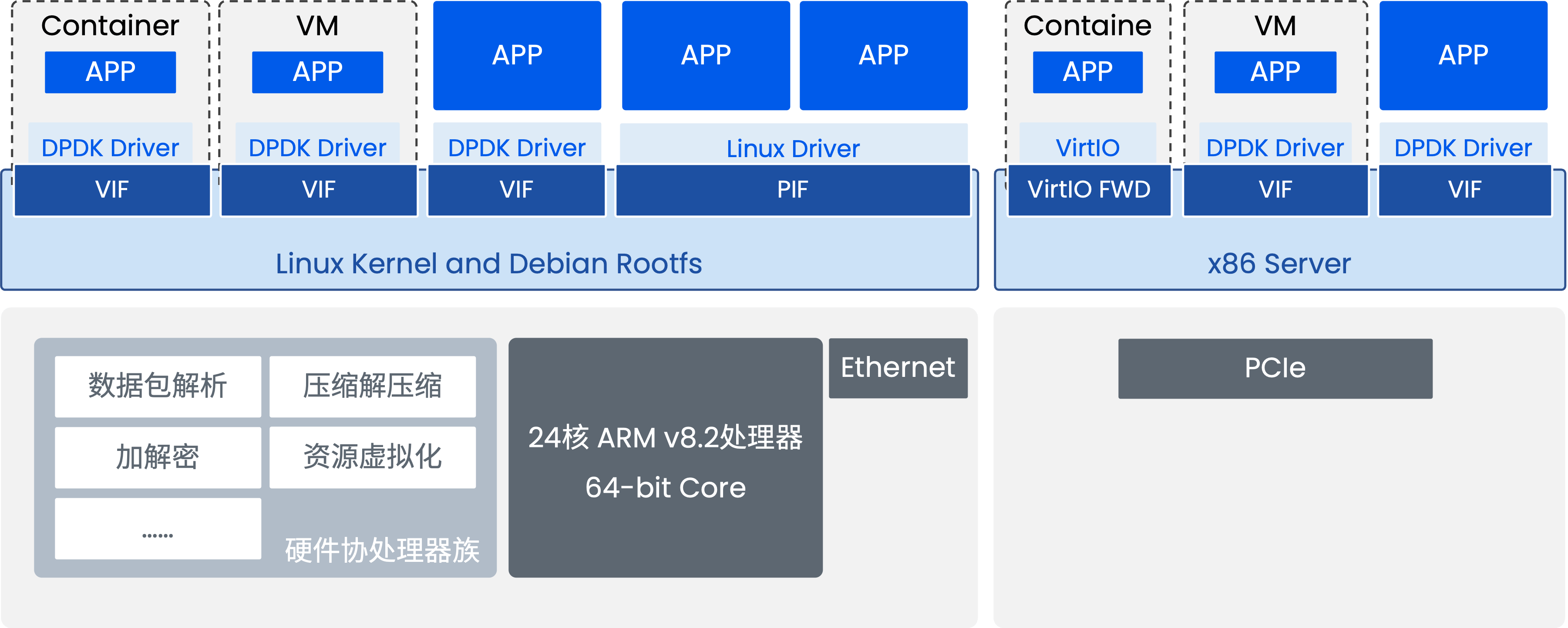
智能网卡
- 基于高性能 DPU 芯片,提供 PCIe Gen3.0/4.0 接口,支持 100Gbps 多功能业务处理 (网络/计算/存储卸载)。
- 显著释放服务器主 CPU 资源。
- 强大的应用移植性: 基于 x86 开发的 DPDK 应用、VPP 应用、标准 Linux 驱动应用,通常只需重新编译即可快速迁移 到 Helium DPU 上运行,加速业务部署。提供 4x25G 和 2x100G 等规格。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号