GraphRAG+neo4j实战
原创
GraphRAG+neo4j实战
原创
happywei
修改于 2025-06-27 17:45:17
修改于 2025-06-27 17:45:17
Local Search
本地搜索方法通过将AI提取的知识图谱中的相关数据与原始文档的文本块相结合来生成答案。此方法适用于需要理解文档中提到的特定实体的问题(例如,洋甘菊的治疗功效是什么?)。
Global Search
全局搜索方法通过以 map-reduce 方式搜索所有 AI 生成的社区报告来生成答案。这是一种资源密集型方法,但对于需要整体理解数据集的问题(例如,本笔记中提到的草药中最重要的价值是什么?),通常能提供良好的答案。
DRIFT Search
DRIFT Search 通过在搜索过程中引入社区信息,为本地搜索查询引入了一种新方法。这极大地扩展了查询的起点,并使得最终答案能够检索和使用更丰富的事实。这一新增功能扩展了 GraphRAG 查询引擎,为本地搜索提供了更全面的选项,它利用社区洞察将查询细化为详细的后续问题。
部署Graphrag
安装 GraphRAG
pip install graphragRAG需要的txt格式的文件都要放入input文件夹下
mkdir -p ./ragtest/input设置工作区
graphrag init --root ./ragtest工作区.env文件下配置
GRAPHRAG_API_KEY=apikey
GRAPHRAG_CLAIM_EXTRACTION_ENABLED=True在setting.yaml下配置llm和embedding模型
### This config file contains required core defaults that must be set, along with a handful of common optional settings.
### For a full list of available settings, see https://microsoft.github.io/graphrag/config/yaml/
### LLM settings ###
## There are a number of settings to tune the threading and token limits for LLM calls - check the docs.
models:
default_chat_model:
type: openai_chat # or azure_openai_chat
api_base: https://api.siliconflow.cn/v1
# api_version: 2024-05-01-preview
auth_type: api_key # or azure_managed_identity
api_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
model: Qwen/Qwen3-32B
deployment_name: <azure_model_deployment_name>
encoding_model: cl100k_base # automatically set by tiktoken if left undefined
model_supports_json: true # recommended if this is available for your model.
concurrent_requests: 25 # max number of simultaneous LLM requests allowed
async_mode: threaded # or asyncio
retry_strategy: native
max_retries: 10
tokens_per_minute: auto # set to null to disable rate limiting
requests_per_minute: auto # set to null to disable rate limiting
default_embedding_model:
type: openai_embedding # or azure_openai_embedding
api_base: https://api.siliconflow.cn/v1
# api_version: 2024-05-01-preview
auth_type: api_key # or azure_managed_identity
api_key: ${GRAPHRAG_API_KEY}
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
model: BAAI/bge-m3
deployment_name: <azure_model_deployment_name>
encoding_model: cl100k_base # automatically set by tiktoken if left undefined
model_supports_json: true # recommended if this is available for your model.
concurrent_requests: 25 # max number of simultaneous LLM requests allowed
async_mode: threaded # or asyncio
retry_strategy: native
max_retries: 10
tokens_per_minute: auto # set to null to disable rate limiting
requests_per_minute: auto # set to null to disable rate limiting运行
graphrag index --root ./ragtest报错:KeyError:'Could not automatically map Qwen/Qwen3-32B to a tokeniser. Please use tiktoken.get_encoding to explicitly get the tokeniser you expect.
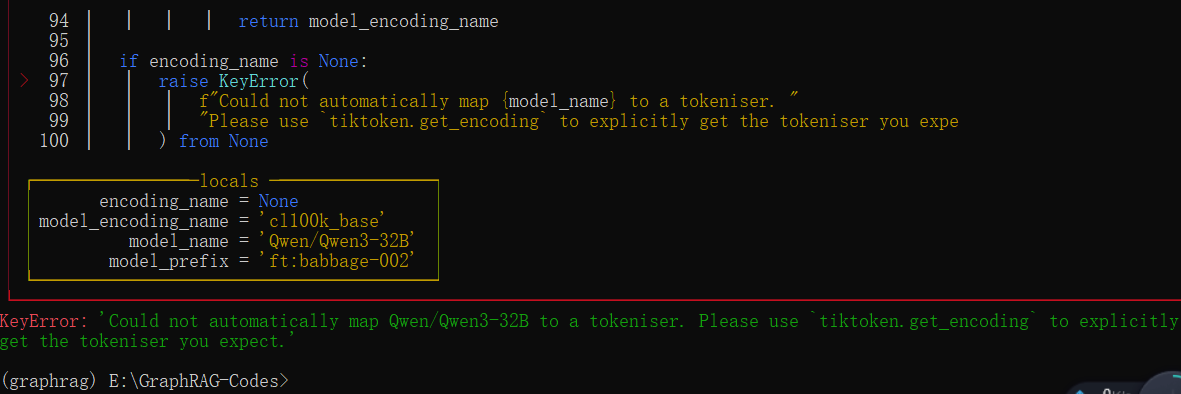
解决方法:
打开这条注释即可解决

部署neo4j
首先需要安装jdk和neo4j-community
然后安装neo4j库
pip install --upgrade --quiet neo4j启动方法:
方法一:命令neo4j.bat console只是临时启动,关闭命令行窗口,数据库就会无法访问
方法二:cd E:\neo4j-community-5.26.8\bin>进入bin目录neo4j console
方法三:配置服务化启动,可以持久neo4j,打开cmd,输入neo4j windows-service install,注册NEO4J服务
访问:http://localhost:7474/输入账号、密码即可连接数据库,初始默认用户名和密码都是neo4j
在neo4j里面创建图
GRAPHRAG_FOLDER="./output"
import pandas as pd
from neo4j import GraphDatabase
import time
NEO4J_URI="bolt://localhost:7687"
NEO4J_USERNAME="neo4j"
NEO4J_PASSWORD="wW854012083"
NEO4J_DATABASE="neo4j"
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
print("-------------------------")
def batched_import(statement, df, batch_size=1000):
total = len(df)
start_s = time.time()
for start in range(0,total, batch_size):
batch = df.iloc[start: min(start+batch_size,total)]
result = driver.execute_query("UNWIND $rows AS value " + statement,
rows=batch.to_dict('records'),
database_=NEO4J_DATABASE)
print(result.summary.counters)
print(f'{total} rows in { time.time() - start_s} s.')
return total
statements = """
create constraint chunk_id if not exists for (c:__Chunk__) require c.id is unique;
create constraint document_id if not exists for (d:__Document__) require d.id is unique;
create constraint entity_id if not exists for (c:__Community__) require c.community is unique;
create constraint entity_id if not exists for (e:__Entity__) require e.id is unique;
create constraint entity_title if not exists for (e:__Entity__) require e.name is unique;
create constraint entity_title if not exists for (e:__Covariate__) require e.title is unique;
create constraint related_id if not exists for ()-[rel:RELATED]->() require rel.id is unique;
""".split(";")
for statement in statements:
if len((statement or "").strip()) > 0:
print(statement)
driver.execute_query(statement)
doc_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/documents.parquet', columns=["id", "title"])
doc_df.head(2)
# import documents
statement = """
MERGE (d:__Document__ {id:value.id})
SET d += value {.title}
"""
batched_import(statement, doc_df)
text_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/text_units.parquet',
columns=["id","text","n_tokens","document_ids"])
text_df.head(2)
statement = """
MERGE (c:__Chunk__ {id:value.id})
SET c += value {.text, .n_tokens}
WITH c, value
UNWIND value.document_ids AS document
MATCH (d:__Document__ {id:document})
MERGE (c)-[:PART_OF]->(d)
"""
batched_import(statement, text_df)
print("----------------------------------------------------------------------------------------")
df_temp = pd.read_parquet(f'{GRAPHRAG_FOLDER}/entities.parquet')
entity_df = df_temp[["id", "title", "type", "description", "text_unit_ids"]] # 挑出你需要的字段
cypher_statement = """
MERGE (e:Entity {id: value.id})
SET e.title = value.title,
e.type = value.type,
e.description = value.description,
e.text_unit_ids = value.text_unit_ids
"""
batched_import(cypher_statement, entity_df)
print("----------------------------------------------------------------------------------------")
rel_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/relationships.parquet')
rel_df = rel_df[["id", "source", "target", "description", "weight", "combined_degree", "text_unit_ids"]]
rel_df.head(2)
rel_statement = """
MERGE (a:Entity {id: value.source})
MERGE (b:Entity {id: value.target})
MERGE (a)-[r:RELATED {id: value.id}]->(b)
SET r.description = value.description,
r.weight = value.weight,
r.combined_degree = value.combined_degree,
r.text_unit_ids = value.text_unit_ids
"""
batched_import(rel_statement, rel_df)
community_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/communities.parquet',
columns=["id","level","title","text_unit_ids","relationship_ids"])
community_df.head(2)
statement = """
MERGE (c:__Community__ {community:value.id})
SET c += value {.level, .title}
/*
UNWIND value.text_unit_ids as text_unit_id
MATCH (t:__Chunk__ {id:text_unit_id})
MERGE (c)-[:HAS_CHUNK]->(t)
WITH distinct c, value
*/
WITH *
UNWIND value.relationship_ids as rel_id
MATCH (start:__Entity__)-[:RELATED {id:rel_id}]->(end:__Entity__)
MERGE (start)-[:IN_COMMUNITY]->(c)
MERGE (end)-[:IN_COMMUNITY]->(c)
RETURN count(distinct c) as createdCommunities
"""
batched_import(statement, community_df)
community_report_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/community_reports.parquet',
columns=["id","community","level","title","summary", "findings","rank","rank_explanation","full_content"])
community_report_df.head(2)
# import communities
community_statement = """
MERGE (c:__Community__ {community:value.community})
SET c += value {.level, .title, .rank, .rank_explanation, .full_content, .summary}
WITH c, value
UNWIND range(0, size(value.findings)-1) AS finding_idx
WITH c, value, finding_idx, value.findings[finding_idx] as finding
MERGE (c)-[:HAS_FINDING]->(f:Finding {id:finding_idx})
SET f += finding
"""
batched_import(community_statement, community_report_df) 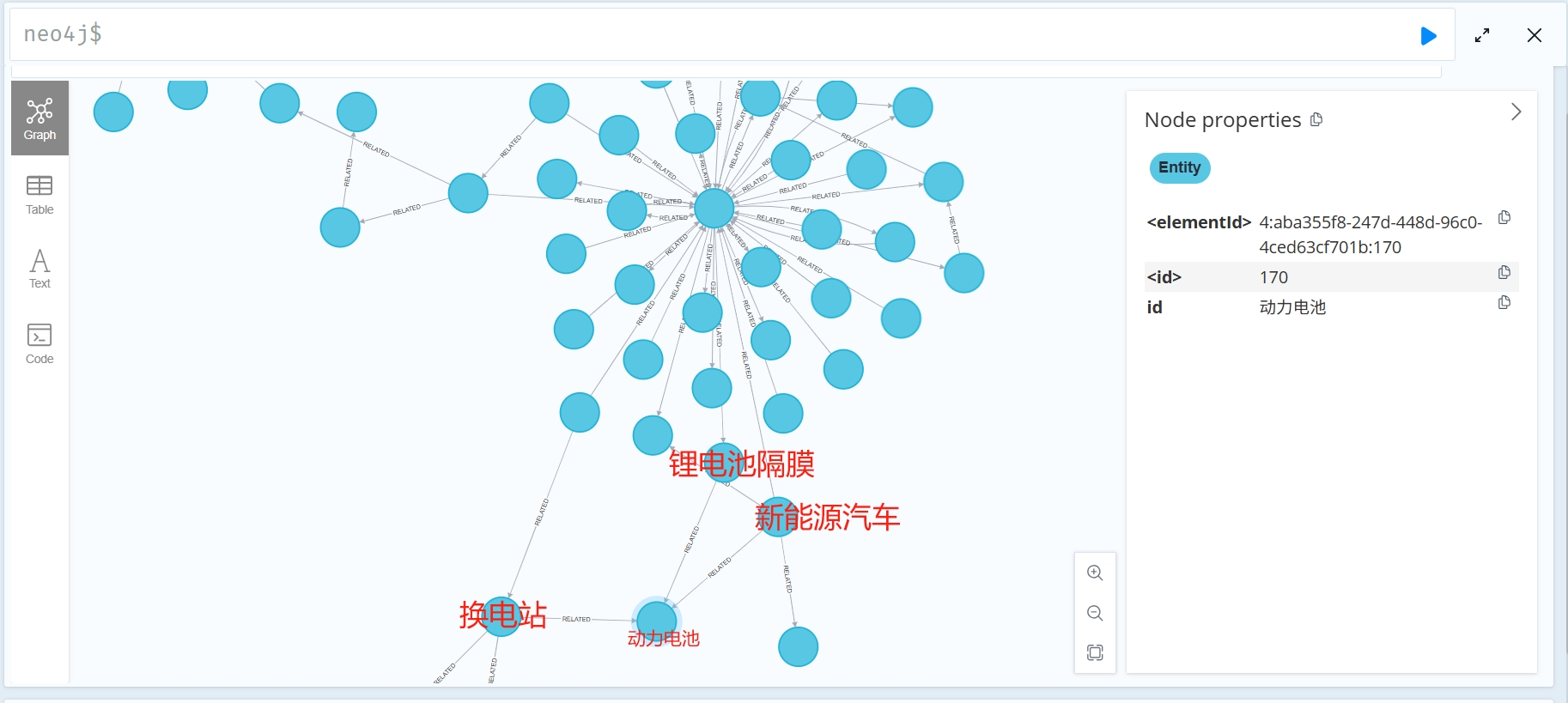
ref:
https://blog.csdn.net/qq_52148082/article/details/147923014
https://blog.csdn.net/Python_0011/article/details/146035071
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号