颠覆认知!微软发布1比特大模型BitNet b1.58,手机跑AI不再是梦?

颠覆认知!微软发布1比特大模型BitNet b1.58,手机跑AI不再是梦?

javpower
发布于 2025-05-30 11:34:18
发布于 2025-05-30 11:34:18
当ChatGPT还在为算力发愁时,微软突然扔出一颗“深水炸弹”——
BitNet b1.58 2B4T。这个仅用1.58比特表示参数的AI模型,不仅性能媲美全精度大模型,还能在手机、IoT设备上流畅运行!它究竟有何魔力?今天带你一探究竟!
1.58比特:AI模型的“瘦身革命”
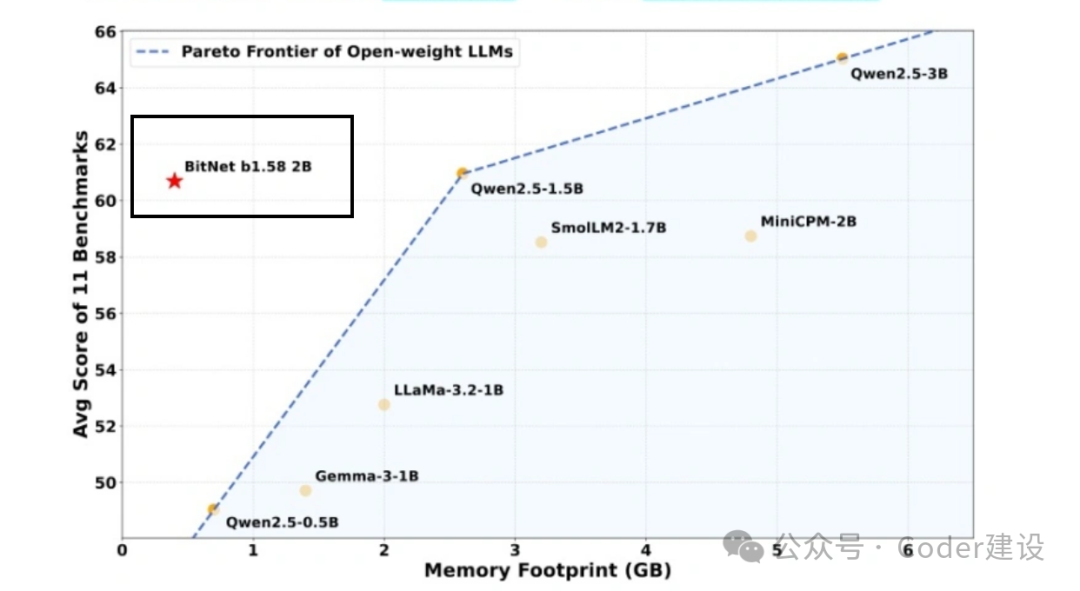
传统大模型(如GPT-4)动辄消耗海量算力,而BitNet b1.58用三值参数(-1、0、+1)实现极致压缩,每个参数仅需1.58比特存储空间,比传统FP16模型节省3-4倍内存。 技术亮点:
- 量化魔法:通过“绝对均值量化”,将权重矩阵动态缩放到{-1, 0, +1},避免精度损失。
- 整数加法替代浮点运算:矩阵乘法仅需加减法,计算速度提升2-4倍,能耗降低70倍以上。
- 兼容主流架构:基于Transformer改造,集成LLaMA的RMSNorm、旋转位置编码等技术,无缝适配Hugging Face等开源平台。
性能炸裂:跑得快还省电
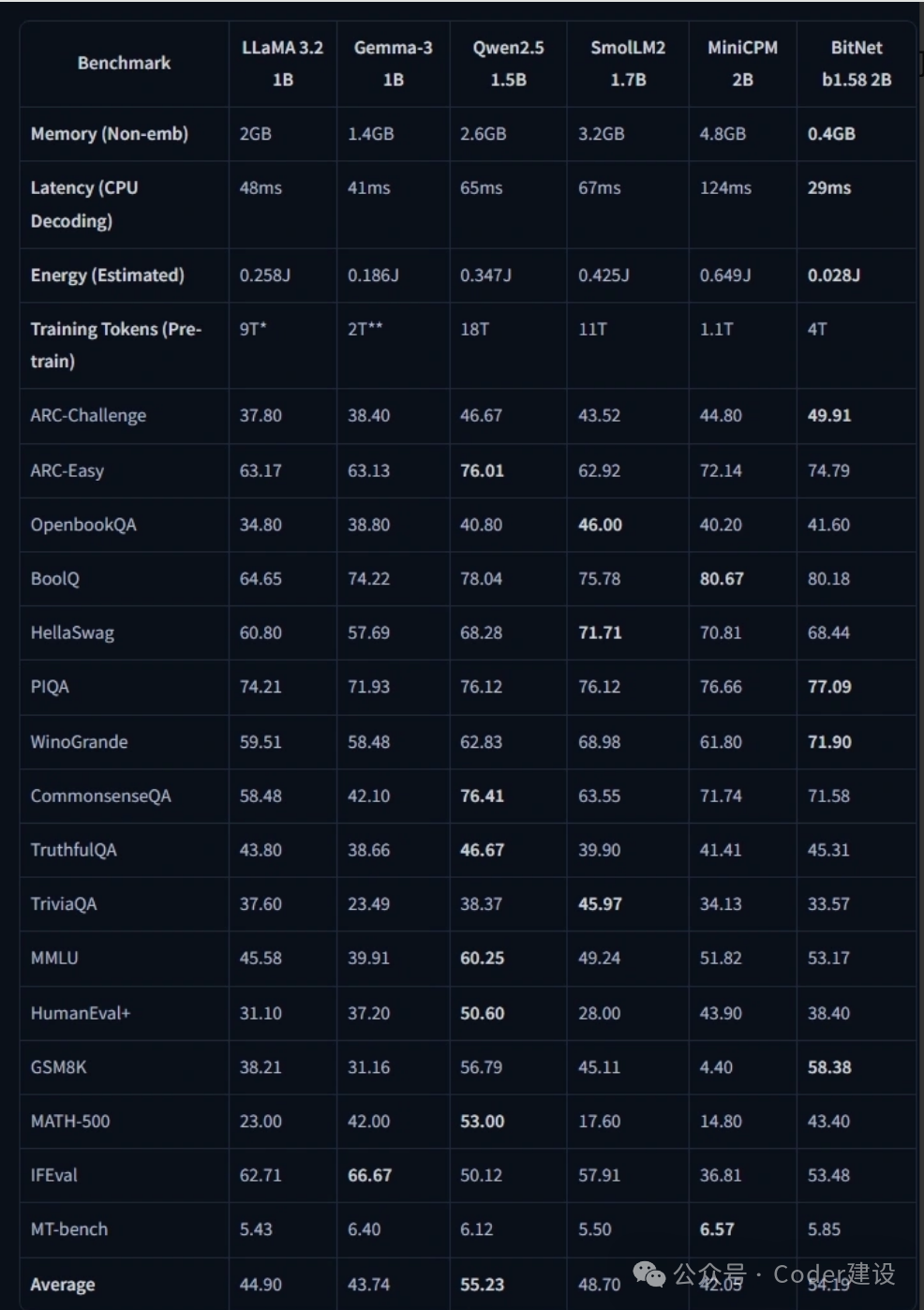
实测表现:
- 语言任务:在ARC、Hellaswag等基准测试中,性能与全精度模型持平。
- 数学推理:GSM8K小学数学题得分超过Meta Llama、Google Gemma等同规模模型。 更惊人的是,24GB显存的消费级GPU即可运行120B参数模型,未来手机跑分大模型或成现实!
落地场景:从云端到指尖
BitNet b1.58的“轻量化”特性彻底打破AI部署边界:
- 移动设备:手机实时运行复杂语言模型,实现离线翻译、语音助手深度交互。
- 物联网:智能家居设备具备多轮对话能力,可穿戴设备实现健康数据分析。
- 边缘计算:工厂、医院等场景低延迟处理海量数据,无需依赖云端。
- 绿色AI:云服务商部署成本降低90%,助力碳中和目标。
三进制计算的“文艺复兴”
BitNet的横空出世,不仅是对二进制计算的颠覆,更预示三进制AI硬件的崛起:
- 专用芯片:1比特计算无需GPU浮点单元,未来或出现“比特处理器”(LPU),效率再提升10倍。
- 模型容量突破:当前最大70B参数,未来可通过稀疏存储技术突破万亿规模。
- 长文本处理:激活值8比特量化使上下文长度翻倍,无损压缩至4比特后性能更值得期待。
从“暴力堆算力”到“优雅做减法”,BitNet b1.58为AI发展开辟了新航道。或许不久的将来,我们会看到这样的奇景:小学生用智能手表写作文,老人机流畅运行ChatGPT……而这,正是技术普惠最美的模样。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号