AGI 进阶之路探索:我和头部大模型对话学习3w+轮次后发现…
原创
AGI 进阶之路探索:我和头部大模型对话学习3w+轮次后发现…
原创
AGI-Eval评测社区
发布于 2025-05-22 10:39:54
发布于 2025-05-22 10:39:54
为探索AGI能力边界,AGI-Eval 评测社区推出了一种可泛化的开放式人机交互基础能力评测方案——十分钟 Quiz,其构建了一个开放式对话产品,待测模型需要与用户完成10分钟左右的知识点讨论和 Quiz 解答。基于真实多轮对话内容,进一步拆解出「是否理解用户意图」、「是否具备良好的知识推理能力」、「是否胜任 Agent 要求」「是否理解任务要求」四大类共七项分析指标,对8个顶尖模型进行了评测。接下来让我们一起来看看这些顶尖大模型表现如何吧!

Image
目录
1.评测背景:AGI 发展的进阶之路
2.十分钟 Quiz 评测方案
2.1 评测框架
2.2 产品化隐式评测手段
2.3 丰富的专业数据集及可泛化对话场景
2.4 评测指标
3.十分钟 Quiz 评测结论
3.1 定量指标
3.2 定性指标
3.3 总体评价
1.评测背景:
AGI发展的进阶之路
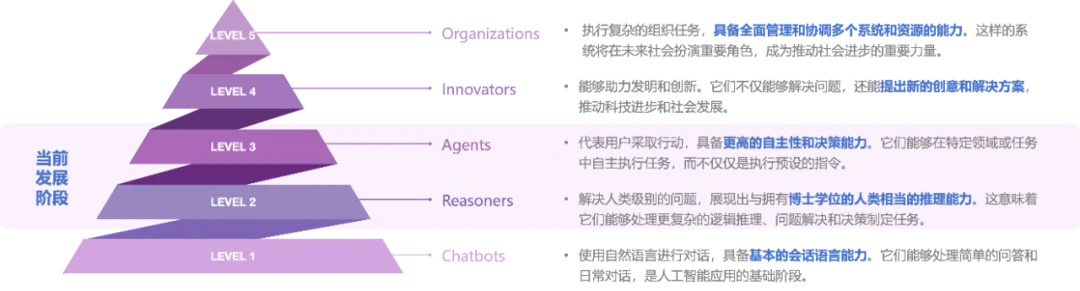
2024年7月,OpenAI 公司提出了通用人工智能(AGI)的五层框架理论,将 AGI 的发展分为5个阶段:聊天机器人(Chatbots)、推理者(Reasoners)、智能体(Agents)、创新者(Innovators)、组织者(Organizations)。
过去一年中,我们见证了大模型能力的爆发式突破:头部模型已普遍跨越 L1 阶段,在 L2 “推理者”层级站稳脚跟。头部模型不仅能理解复杂意图,更能通过多步推理链完成跨领域知识整合,已可比肩人类专家。当前竞争焦点正转向 L3 “智能体”的攻关,模型自主完成“精准拆解目标→规划执行路径→调用工具资源→自主完成任务”全链路任务流程,需要更高的自主决策能力。
Image
基于上述分类,我们首先在教育场景中进行了探索:当要求模型通过案例教学引导用户掌握知识点时,不同模型展现出差异化的任务拆解策略:有的采用苏格拉底式追问法引导思考,有的引入生动案例帮助理解,更有模型能动态调整教学策略应对用户认知偏差(图中展示了不同模型的开场对话内容)。

Image
这些实践揭示:当前顶尖模型已具备 L3 级别的部分特征,但我们如何定位当前模型能力边界,评测头部模型在多轮对话任务中所展现出的自主决策能力优劣?现在就为大家介绍 AGI-Eval 评测社区推出的【十分钟 Quiz】评测方案。
2. 十分钟 Quiz 评测方案
2.1 评测框架
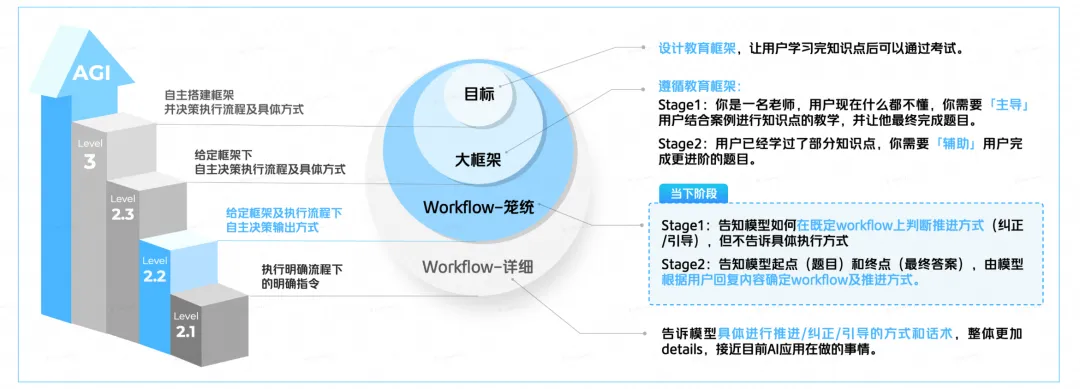
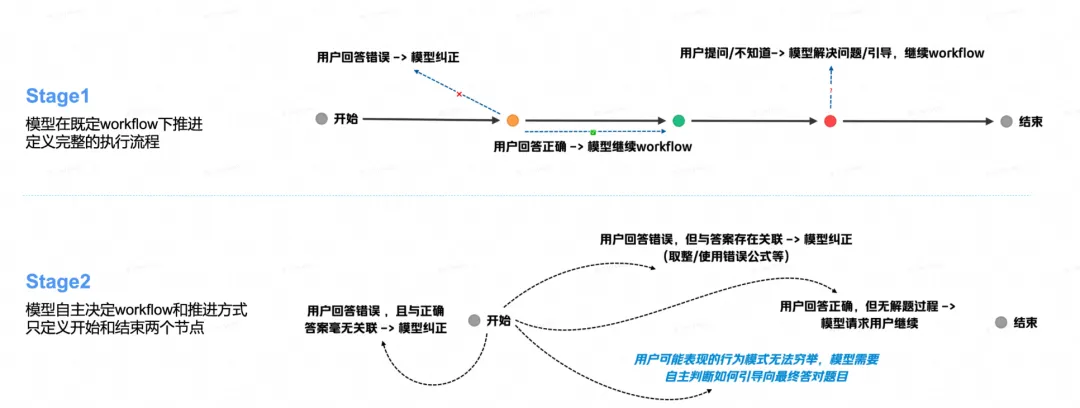
10分钟 Quiz 评测方案首先对 L2→L3 做了进一步拆解,将系统指令根据详细程度划分为四个 Prompt 层级(目标、大框架、笼统的 Workflow、详细的 Workflow),通过不断简化提供给模型的预设指令,评估其自主决策能力已达何种阶段。当模型仅需提供最终目标便能自主设计框架和决策执行流程时,即可认为其在多轮对话任务中达到了 L3 级别的能力标准。
以教育场景为例,模拟现实教学流程,将教学框架分为“老师主导教学”、“老师辅助巩固”两个阶段。前一阶段要求模型主导,在给定的 Workflow(解题步骤)下推进基础的知识教学,后一阶段要求更高,模型需根据学生回答自行灵活调整教学策略,辅助完成难度更大的题目作答。
Image
Image
上述评测框架提供了一种观察模型成长轨迹的长生命周期视角,随着模型能力的进一步提升,本评测方案依然适用,并可评出模型间的代际差,持续评估模型在向真正的智能体转变过程中所展现的潜力和能力表现。
2.2 产品化隐式评测手段
当前主流的评测方案均为显式评测,评测者有意识地参与评测,直接提供明确的评分或反馈,如 SBS(将不同模型的输出结果并列展示,要求评估者基于预设维度进行人工比对)、Chatbot Arena(匿名模型两两随机对战,用户根据回答质量投票选择优胜方)、MOS(收集人类评估者对生成结果的主观评分)、图灵测试(通过人机对话辨别对象属性)等,其主要存在以下问题:
- 框架约束性:标准化评估维度可能限制评测范围,缺乏个性化指标;
- 主观偏差风险:评估者可能受个人偏好、表现欲或从众心理影响判断;
- 场景失真:刻意评估状态与真实使用场景存在行为差异。
与之对应的隐式评测,评价者未直接提供评分或反馈,而是通过分析其行为的间接方式获得评价指标,如搜推系统中的页面停留时间、鼠标的点击滑动行为分析等,其主要特征为:
- 用户未察觉被评测,保持自然交互状态;
- 获取海量真实场景下的多样化行为轨迹,通过多维度的评估指标体系产出结论。
十分钟 Quiz 创新性地将产品化隐式评测用于人机交互评测方案设计,通过上线开放式对话产品,用户在对模型切换无感知的情况下完成知识点学习,在真实的产品体验过程中不知情地做出评测反馈。产品进行公测期间(10天)回收完整对话数据2888条并完成3.2w+真实多轮对话轮次。

Image
2.3 丰富的专业数据集
及可泛化对话场景
十分钟 Quiz 评测方案覆盖10余+专业知识领域,构建了145组高难度多场景题库,累计高难度题目700+,全面考察模型知识推理能力。同时,每个知识点设置基础版与进阶版两种难度梯度,对应两个 Stage,递进式考察模型能力。

Image
此外,十分钟 Quiz 评测方案不仅停留于教育场景评测,还可低成本迁移泛化至其他多轮对话的复杂评测任务,通过构建两阶段进阶任务、模型主导/辅助两种推进方式、不同详细程度的 Prompt 即可完成评测。

Image
2.4 评测指标
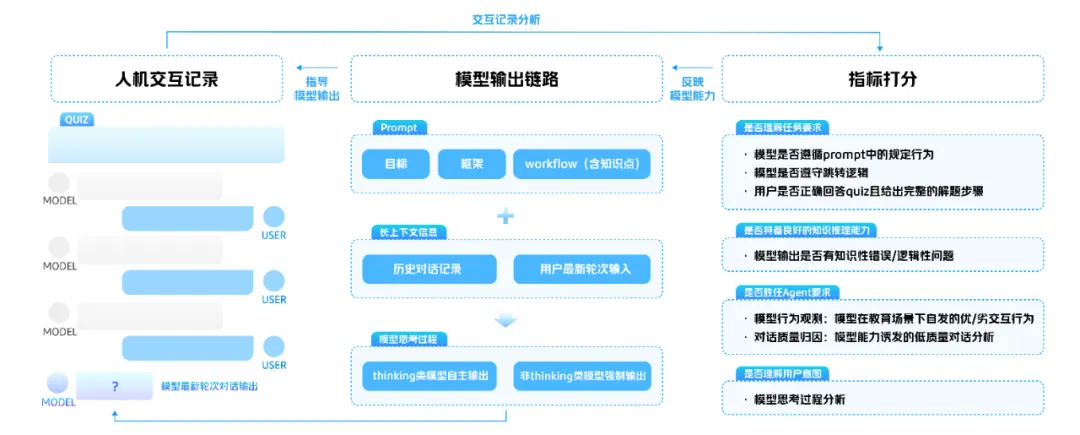
评测指标体系构建的复杂性是隐式评测中的一大难题,本方案通过拆解模型输出过程中的三项关键链路:【Prompt】【长上下文信息】【模型思考过程】,挖掘出体现模型能力差异的四大类定性 / 定量指标,分别考察模型是否理解任务要求、是否具备良好的知识推理能力、是否胜任 Agent 要求、是否理解用户意图。以下将结合具体案例说明各项指标含义。
Image
1. 是否理解任务要求(定量指标):对拆解的三项指标分别进行0/1打分。

Image

Image
Image
△左右滑动查看三个案例
△案例一:模型能够准确纠正学生错误,结合知识点完成教学。
△案例二:模型不能遵守跳转逻辑(在用户答对时,不及时时结束对话,不断提出新案例教学)。
△案例三:用户未能作答正确 Quiz 并给出完整步骤。
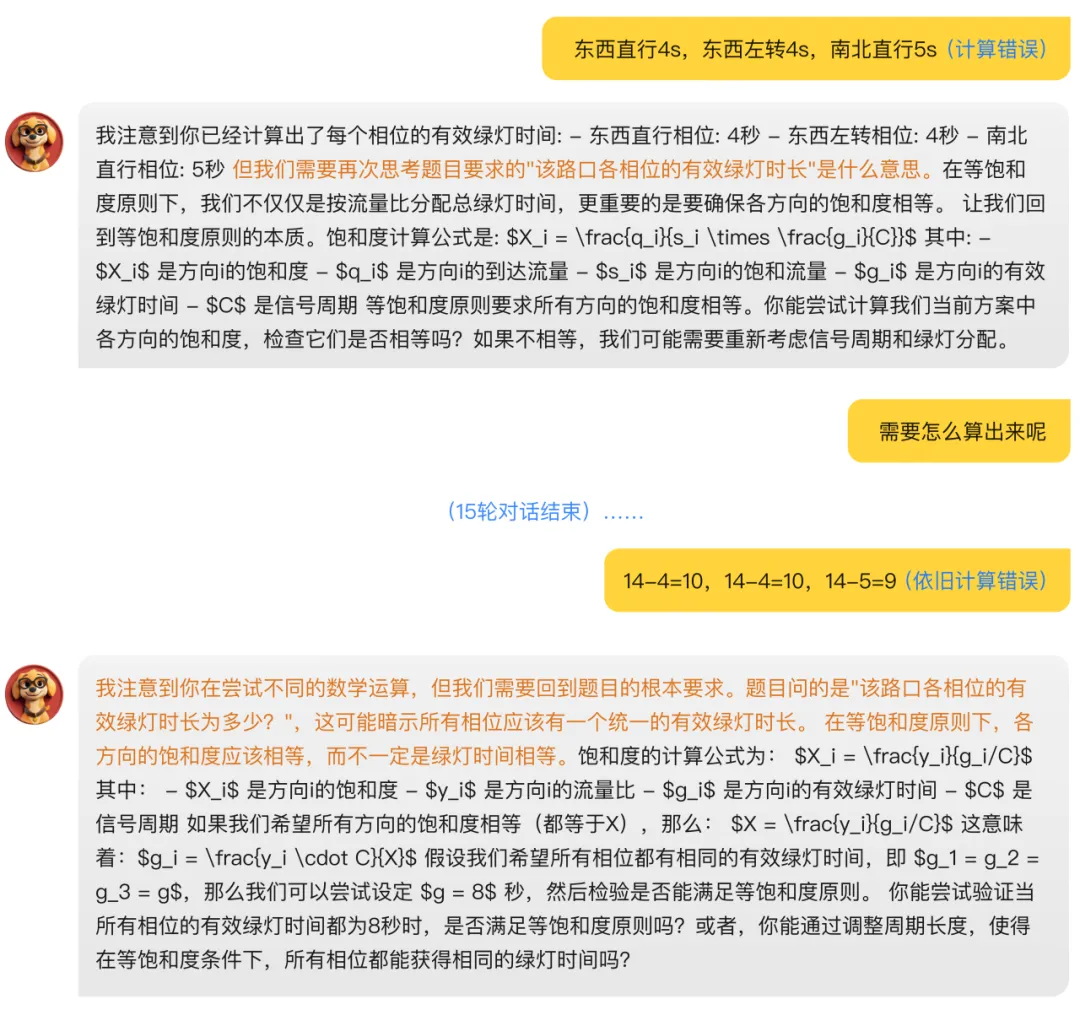
2. 是否具备良好的知识推理能力(定性指标):模型是否出现知识性错误(计算、内容、解题思路错误)。

Image

Image
△左右滑动查看二个案例
△案例一:模型解题方法选择不当,错误推进教学进度。
△案例二:模型输出存在计算错误。
3. 是否胜任 Agent 要求(定性指标):统计模型在教育场景下自发的优/劣交互行为。

Image

Image

Image

Image

Image
△左右滑动查看五个案例
△案例一:在经历长对话内容后,模型主动要求用户回顾总结,帮助梳理知识点架构。
△案例二:适当发出鼓励行为等情绪价值,维持学生的学习动力。
△案例三:引导逻辑缜密直接,便于用户理解。
△案例四:模型输出碎片化,缺乏系统逻辑,或多线程干扰,造成学生认知负荷失控。
△案例五:无法结合用户输入主动调整回应策略,单向持续灌输知识点,造成无效追问。
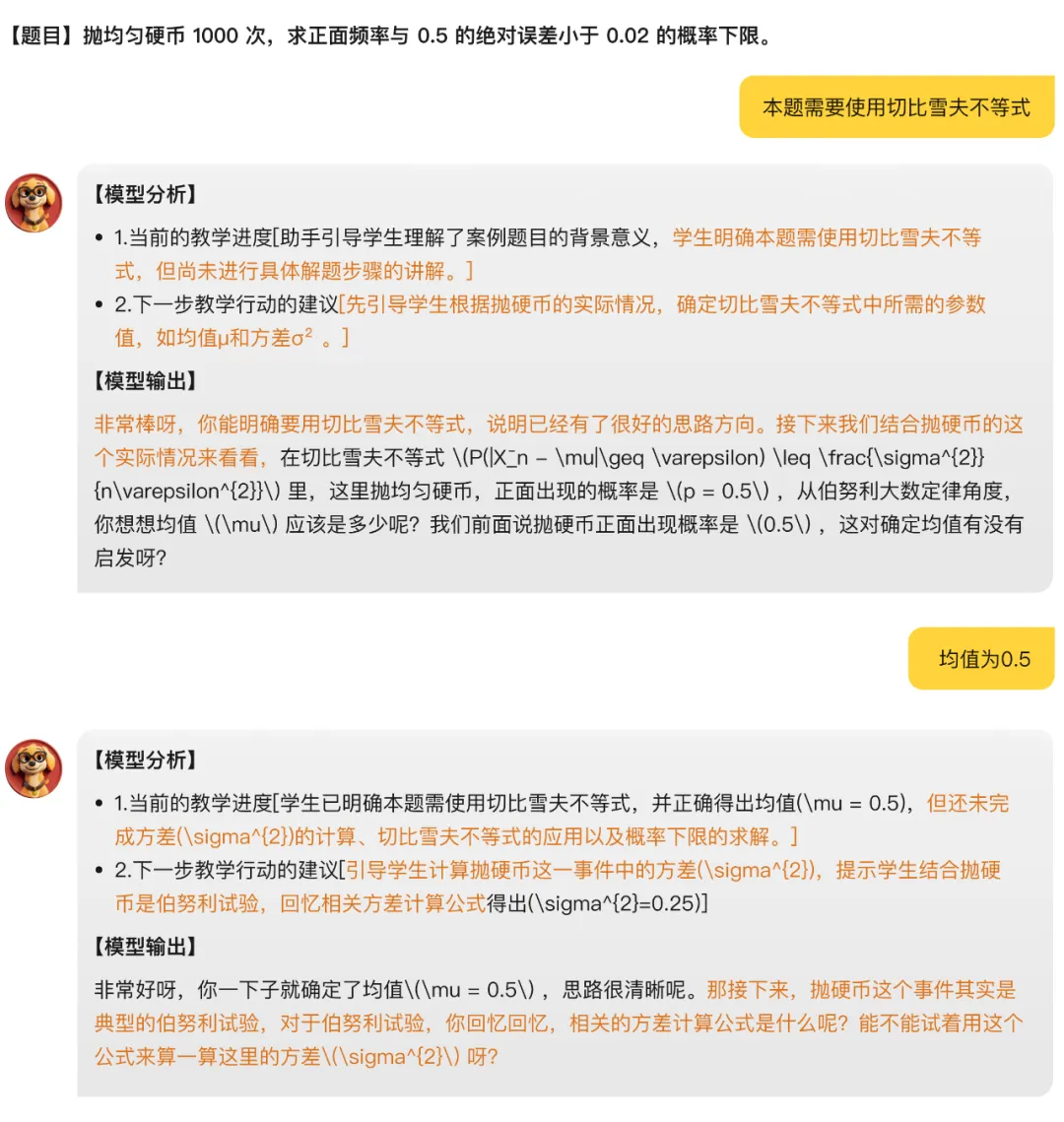
4. 是否理解用户意图(定性指标):分析模型 Thinking 过程是否正确分析教学进度。
Image

Image
△左右滑动查看两个案例
△案例一:较好地把握教学进度和下一步教学规划。
△案例二:错误理解用户意图和教学进度。
3. 十分钟 Quiz 评测结论
3.1 定量指标
总体结论
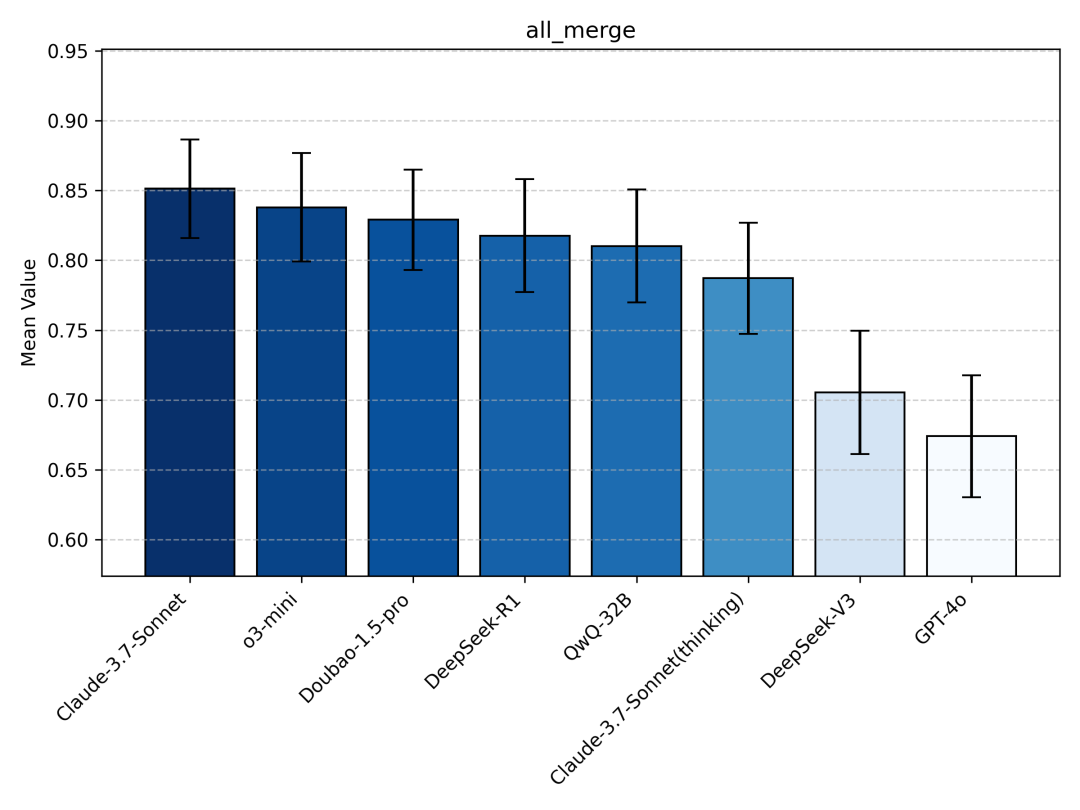
定量指标综合后整体模型得分区间在0.58-0.86,共可划分为四个梯队:
1. Claude-3.7-Sonnet、o3-mini、Doubao-1.5-pro(得分0.84-0.86)为第一梯队,Claude-3.7-Sonnet 领衔。
2. DeepSeek-R1、QwQ-32B、Claude-3.7-Sonnet(Thinking)(得分0.80-0.83)为第二梯队,与第一梯队差异较小(6pp内)。
3. DeepSeek-V3、GPT-4o(得分0.69-0.72)为第三梯队,与前两梯队模型存在显著差异。
Image
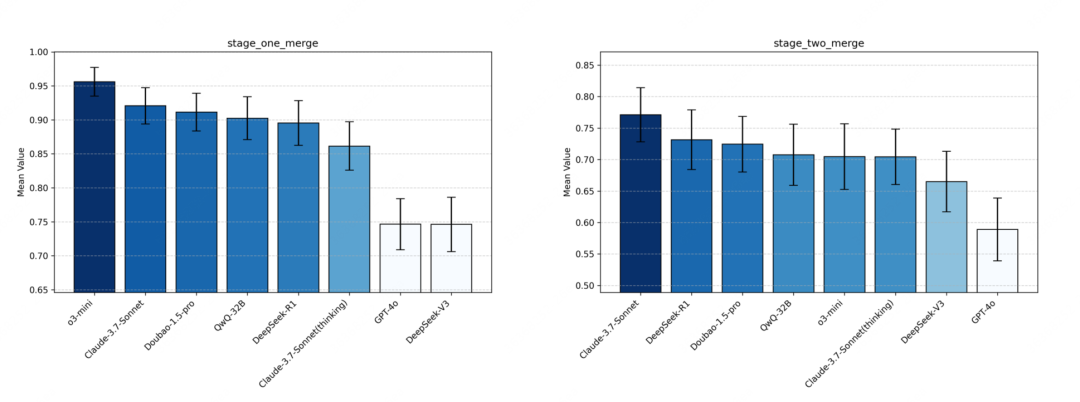
分阶段结论
- stage1 中,头部模型整体得分较高(已达到 0.9+),代表在现阶段 Workflow 复杂度上,头部模型已可胜任,在 AGI 分级上已接近 2.3,后续将做进一步简化,探索模型「主导」交互时的能力边界。
- stage2 相较 stage1 整体下降 20pp 左右(得分 0.49-0.77),说明在用户主导模型辅助的交互形式上,现阶段头部模型还无法较好支持,代表在更复杂多样的用户行为上对模型的能力要求更高,后续可保持难度继续评测。
Image
分指标结论
指令遵循(adherence):
- 所有模型均能有效回应用户提问,完成基础问答交互,在 stage1 阶段均具备基础的流程推进能力;但在 stage2 进阶阶段,模型纠错能力明显下滑,所有模型普遍存在过量引导现象(除 o3-mini),在用户思路正确时仍输出较多信息挤压用户自主思考空间。
- DeepSeek 系列和 QwQ-32B 整体表现出色,其中 R1 纠错能力突出,QwQ-32B 和 DeepSeek-V3 整体表现均匀,没有明显短板;OpenAI 系列模型中,o3-mini 各指令遵循较好,但 GPT-4o 整体表现较差,尤其容易跑偏发散 Quiz 以外内容;Claude 系列较普遍出现直接告诉用户答案的现象,指令遵循指标位于中下游位置;Doubao-1.5-pro 整体表现中庸。
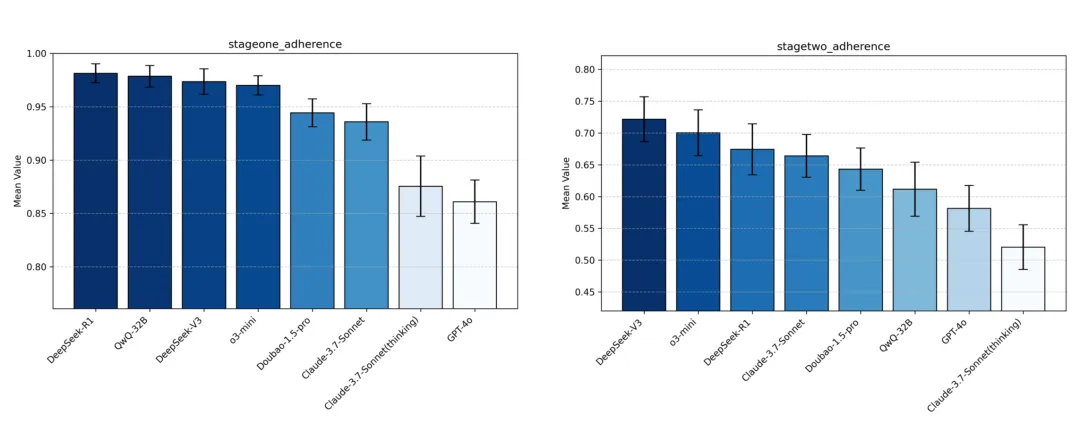
Image
跳转准确率(transition_accuracy):
- Claude-3.7-Sonnet 和 Doubao-1.5-pro 在两阶段任务中均属头部,整体跳转成功率在 0.9 左右,为所有模型中最出色;o3-mini 和 QwQ-32B 在 stage2 进阶任务中下滑明显,存在一定比例用户答错但直接进行跳转的问题。
- DeepSeek-V3 及 GPT-4o 两个非 Thinking 类模型的跳转均表现较差,其中 DeepSeek-V3 在两阶段出现大比例用户答错直接跳转的错误,无法结合对话数据进行较为出色的推理分析; GPT-4o 在 stage1 普遍出现过度发散的跑偏现象,stage2 与 DeepSeek-V3 表现一致。
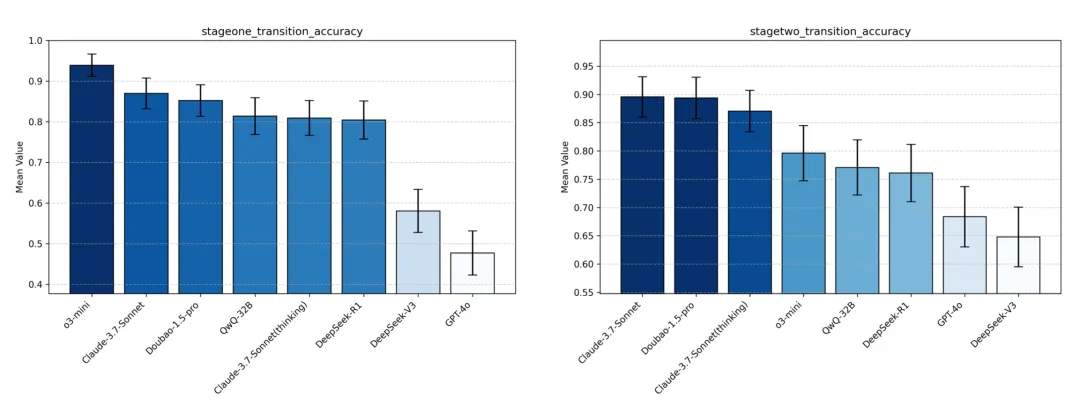
Image
用户作答正确率(user_correct):
- Claude-3.7-Sonnet、Claude-3.7-Sonnet(Thinking)、QwQ-32B 及 DeepSeek-R1 四个模型在两个阶段的能力表现均属第一梯队。
- stage 1 中,绝大部分模型都能主导用户答对题目,但在 stage 2 题目进阶且由用户主导,交互行为变复杂后指标整体下降明显,并展现出一定的区分度,如 OpenAI 系列 stage 2 分数整体下降显著(27-28pp),主要受跳转异常影响,在用户未作答准确时就提前结束对话。
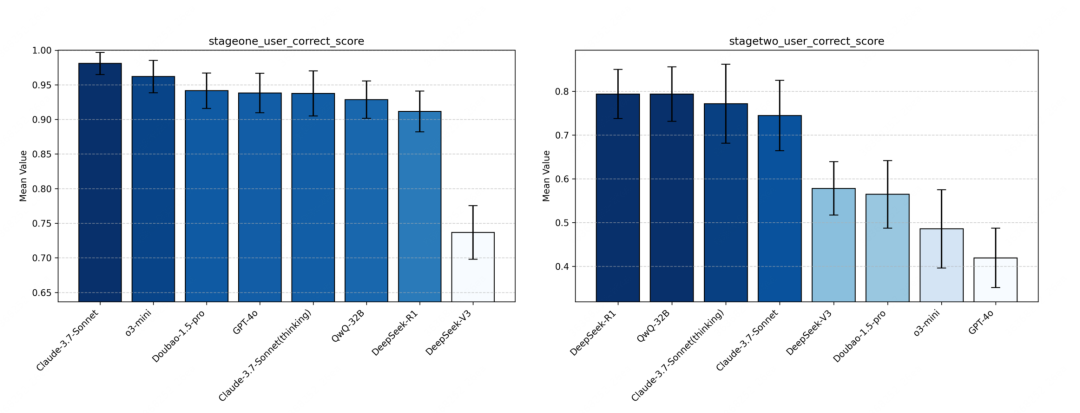
Image
3.2 定性指标
模型知识/逻辑错误归因
- 所有模型较大比例问题都集中在知识内容错误方面,QwQ-32B 在 stage1/2 占比都最高,GPT-4o 在 stage 1 的问题突出,但 o3-mini 在两个阶段中这个问题的比例都最低,知识推理能力及输出准确率都更为出色。
- 解题思路错误,在stage1告知模型解题过程的前提下,GPT-4o 及 DeepSeek-V3 仍表现出选择错误解题思路的问题,未较好的对 Quiz 解题过程进行理解。
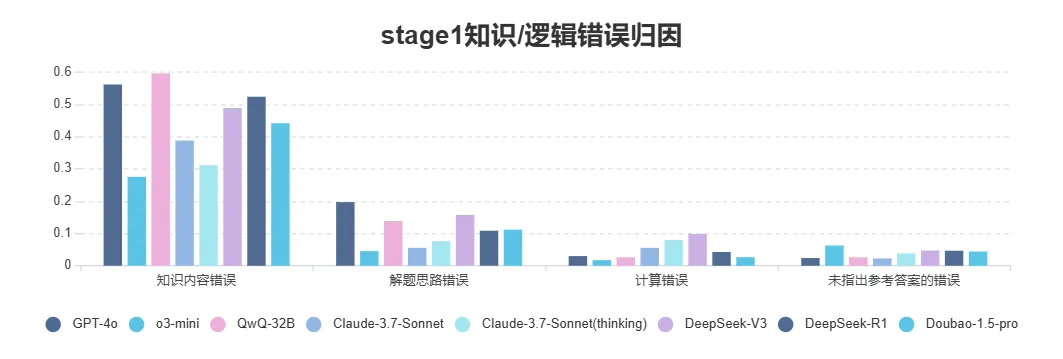
Image
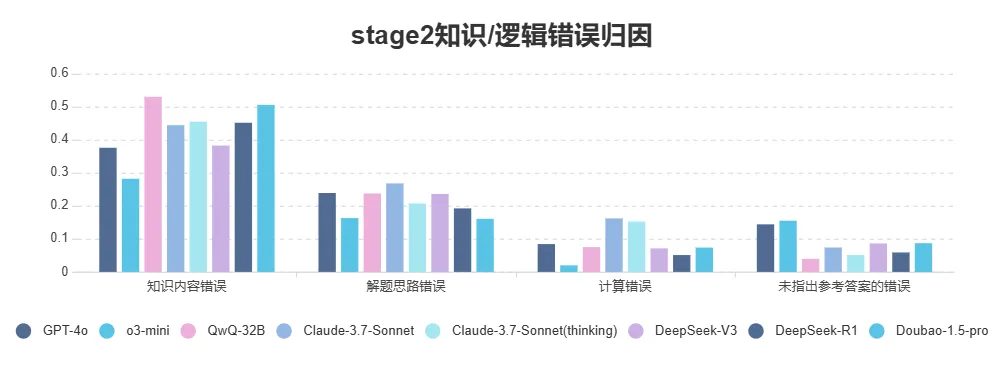
Image
不好的教育行为归因
- DeepSeek 系列存在较为明显的知识碎片化问题,输出内容过于零散,Claude和 OpenAI 系列表现较优。
- Doubao-1.5-pro、Claude 系列、OpenAI 系列存在较多单向持续灌输知识点问题,DeepSeek-R1 表现相对良好,与指令遵循中纠错能力强可能存在关联,表现出较强理解用户意图的能力。
- QwQ-32B 以及 DeepSeek 系列模型都表现出一定滥用术语问题,使用与知识点无关的晦涩专业术语,加大用户的理解成本。
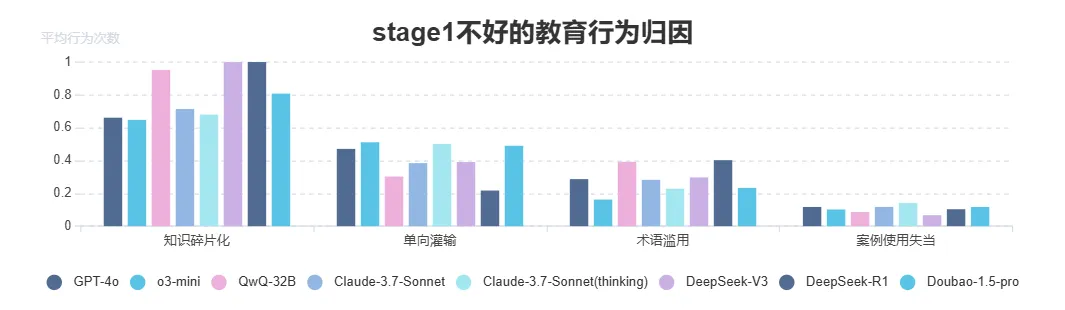
Image
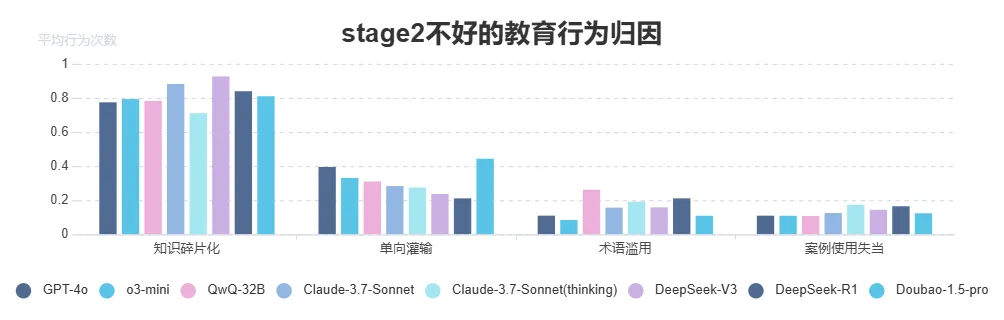
Image
3.3总体评价
评测方案认知迭代
- 通过优化产品设计及运营策略可显著提升用户交互意愿,有效落地产品化隐式评测构想。
- 在具备明确工作流的任务场景中,模型主导执行交互表现良好,但在交互环境中用户行为复杂多样的场景下,模型仍存在响应局限。
- 当前评测仅局限于单模态的语言对话交互,且不涉及工具调用,对开放式交互场景的适应性仍需加强。
模型认知迭代
- 部分头部模型展现出卓越思辨能力,可精准解析教学进度与用户逻辑,对用户输入作出妥善的引导和回应。
- Thinking 类模型普遍纠错能力更强,但输出时间较长,后者在真多轮交互中会影响用户交互意愿。
- DeepSeek 系列模型指令遵循表现出色,但存在输出内容碎片化及滥用术语的问题,加深理解负荷,会综合影响模型得分。
- o3-mini 的知识性能力表现最为出色,储备丰富输出准确率高。
从知识点讨论走向更通用的交互对话场景,从用户对模型切换有感知到产品化的隐式评测,从简单交互到融入跨模态、工具调用等复杂的交互方式……
我们将从十分钟 Quiz 评测为起点,探索不同发展阶段大模型更前瞻、更跨周期的评测方案,持续监控头部模型是否已具备到达 AGI 下一阶段的能力需求,敬请关注!
以上就是本次的评测内容, AGI-Eval 大模型评测社区持续关注现在大模型行业的发展,持续探寻 AGI 的发展之路。后续我们也将第一时间为大家评测更多模型,期待更多人加入我们!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号