Inner Error! atten mask dim should be 2 or 4, but got 3
原创
Inner Error! atten mask dim should be 2 or 4, but got 3
原创
happywei
修改于 2025-05-22 15:08:05
修改于 2025-05-22 15:08:05
部署QW2.5-VL-7B-Instruct之后
在运行下面代码
import gradio as gr
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
# 加载模型和处理器
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
def process_image_and_text(image, text_prompt):
if image is None:
return "请上传一张图片。"
# 构建消息格式
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image, # Gradio将自动处理图片路径
},
{"type": "text", "text": text_prompt if text_prompt else "Describe this image."},
],
}
]
try:
# 准备推理输入
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to(model.device)
# 生成输出
with torch.no_grad():
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
return output_text[0]
except Exception as e:
return f"处理过程中出现错误: {str(e)}"
# 创建Gradio界面
with gr.Blocks() as demo:
gr.Markdown("# Qwen2.5-VL 图像理解演示")
with gr.Row():
with gr.Column():
image_input = gr.Image(type="filepath", label="上传图片")
text_input = gr.Textbox(
placeholder="请输入提示语(如不输入,默认描述图片)",
label="提示语"
)
submit_btn = gr.Button("提交")
with gr.Column():
output = gr.Textbox(label="输出结果")
submit_btn.click(
fn=process_image_and_text,
inputs=[image_input, text_input],
outputs=output
)
gr.Examples(
examples=[
["path/to/example1.jpg", "这张图片里有什么?"],
["path/to/example2.jpg", "描述图中的场景"],
],
inputs=[image_input, text_input],
)
# 启动应用
if __name__ == "__main__":
demo.launch(share=True)
执行上述代码后,在gradio输入图片报错:
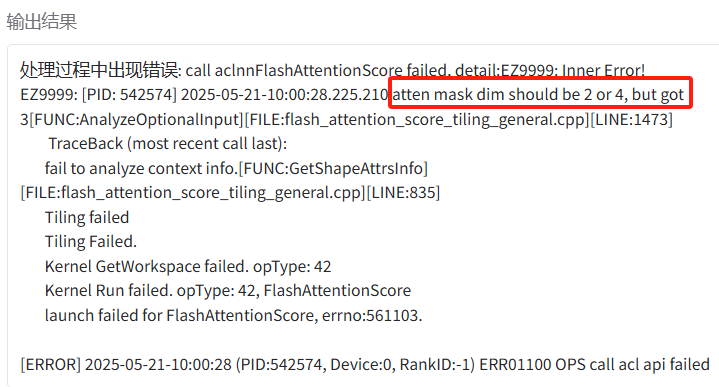
call aclnnFlashAttentionScore failed, detail:EZ9999:
Inner Error! EZ9999: [PID: 542574] 2025-05-21-10:00:28.225.210 atten mask dim should be 2 or 4, but got 3
[FUNC:AnalyzeOptionalInput][FILE:flash_attention_score_tiling_general.cpp][LINE:1473]可能原因:
Qwen2.5-VL 在处理图文时会构造 image embedding + text embedding 的组合,而 attention mask 通常变成三维,形如:
attention_mask.shape == (batch, total_seq_len, total_seq_len)这在昇腾的 aclnnFlashAttentionScore 里不被支持,因为华为当前 FlashAttention 实现只支持:
-
[batch, seq_len](2D) - 或
[batch, 1, seq_len, seq_len](4D)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号