LightPROF:新型轻量级高效 Prompt学习-推理框架用于知识图谱问答,“检索-嵌入-推理”流程显优势 !

LightPROF:新型轻量级高效 Prompt学习-推理框架用于知识图谱问答,“检索-嵌入-推理”流程显优势 !

未来先知
发布于 2025-05-09 11:40:09
发布于 2025-05-09 11:40:09

大语言模型(LLMs)在文本理解和零样本推理方面展现出令人印象深刻的能力。然而,知识更新的延迟可能导致它们推理错误或产生有害结果。 知识图谱(KGs)通过结构化组织和连接广泛实体和关系,为LLMs的推理过程提供丰富且可靠的环境信息。现有的基于知识图谱的LLMs推理方法仅以文本形式将知识图谱的知识注入 Prompt 中,忽略了其结构信息。此外,它们大多依赖于封闭源模型或参数量大的开源模型,这给高资源消耗带来了挑战。 为此,作者提出了一种新型轻量级高效 Prompt 学习-推理框架用于知识图谱问答(LightPROF),该框架充分利用LLMs的潜力,以参数高效的方式处理复杂推理任务。具体而言,LightPROF遵循“检索-嵌入-推理”流程,首先通过检索模块从知识图谱中准确、稳定地检索相应的推理图谱。 接下来,通过基于Transformer的知识 Adapter ,精细提取和整合知识图谱中的事实和结构信息,然后将这些信息映射到LLMs的token嵌入空间,创建一个LLM友好的 Prompt ,供LLM进行最终推理。 此外,LightPROF仅需训练知识 Adapter ,并且可以兼容任何开源LLM。在两个公开知识图谱问答基准上的大量实验表明,LightPROF使用小规模LLMs即可实现优异性能。此外,LightPROF在输入token数量和推理时间方面表现出显著优势。
1. 引言
随着更多大语言模型(LLMs)的出现,它们持续提升的性能为自然语言处理(NLP)领域带来了重大创新 。在大量训练数据和庞大参数下展现出的“涌现能力”使LLMs在复杂的零样本任务中表现出色。尽管LLMs效果显著,但由于任务特定先验知识和理解能力有限,它们在知识密集型任务中仍面临挑战。此外,LLMs高昂且耗时的训练过程给持续更新和维护其知识库带来了相当大的难题。
为应对上述挑战,使大语言模型(LLMs)能够访问可靠且持续更新的知识库以支持更准确和可解释的推理至关重要(Pan等人,2024)。知识图谱(KGs)非常适合此目的,因为它们提供了一个结构化的语义框架,能够提供易于访问且及时的信息。知识图谱问答(KGQA)作为一种常见的知识密集型任务,现有工作已探索了将LLMs与KGs结合进行KGQA推理的方法。总的来说,当前KG赋能的LLM推理主要涉及从KGs中检索信息并将其结果整合到LLM输入 Prompt 中,利用LLMs的推理能力来回答问题。
尽管大语言模型在知识图谱上的推理具有巨大潜力,但仍存在若干挑战:首先,知识图谱的内容通常直接以大量文本形式呈现,未能有效传达其图结构中丰富的逻辑关系,而这些关系对于推理至关重要。以往工作中,知识图谱的内容以多维列表或自然语言形式出现在输入 Prompt 中,难以清晰表达其内部的复杂关系和层次结构。其次,知识图谱的检索和推理需要大量大语言模型的调用和强大的推理能力。以往工作采用从问题实体开始、逐步获取推理信息的迭代方法,这增加了大语言模型的调用次数,牺牲了推理效率,并降低了可行性。描述知识图谱的文本内容庞大,不仅需要更大的上下文窗口,还需要更强大的大语言模型,以确保在避免冗余上下文中生成错误答案的同时不遗漏任何信息。
针对这些挑战,作者提出了一种名为RetrieveEmbed-Reason的LLM框架,这是一个新颖的轻量级且高效的 Prompt 学习-推理框架,称为LightPROF,旨在为小规模LLM提供稳定的检索和高效的推理能力。
该框架围绕三个核心组件构建:检索模块、嵌入模块和推理模块。检索模块以关系作为基本检索单元,并根据问题的语义限制检索范围,以获取回答问题所需的推理图。这种方法不仅提高了检索的准确性和稳定性,还显著缩小了搜索空间,减少了频繁调用LLM的需求。接下来,嵌入模块引入了一个小型且精炼的基于Transformer的知识 Adapter ,从推理图中提取和整合文本和结构信息,生成非常适合LLM的表示。该模块提供了一种高效且简化的信息编码方式,解决了潜在的歧义和信息冗余问题,同时减少了所需的输入token数量和上下文窗口大小,从而实现更准确和高效的推理过程。最后,推理模块将嵌入的表示向量与精心设计的自然语言 Prompt 相结合,使LLM能够推导出最终答案。这种设计使LightPROF能够无缝支持任何开源LLM和各种知识图谱,在训练过程中仅需调整知识 Adapter ,而无需更新昂贵且耗时的LLM。作者的贡献总结如下:
据作者所知,这是首个将知识图谱的文本内容和图结构转化为用于 Prompt 大语言模型的嵌入的框架。
作者提出了LightPROF,这是一个轻量级且高效的 Prompt 学习推理框架,为小规模大语言模型提供稳定的检索和高效的推理能力,其所需的训练参数远少于大语言模型本身。
在两个知识图谱问答数据集上进行的广泛实验表明,作者提出的LightPROF优于使用大规模大语言模型(如LLaMa-2-70B、ChatGPT)的方法。进一步分析显示,LightPROF在输入token数量和推理时间方面具有显著的效率优势。
相关工作
大语言模型 Prompt 工程。在扩展大语言模型的能力方面, Prompt 工程已成为一项关键技术。它通过设计特殊的任务指令(即 Prompt ),在不改变模型参数的情况下,最大限度地提升大语言模型在不同应用和研究领域的性能。关于 Prompt 工程的研究已提出许多,涵盖零样本 Prompt (Radford等人,2019)、少样本 Prompt (Brown等人,2020)、思维链(CoT)(Wei等人,2022b)及其衍生方法,如思维树(ToT)和思维图(GoT)(Besta等人,2024)。此外,为解决离散 Prompt 的鲁棒性差和表达能力弱的问题,许多研究探索了软 Prompt ,并在各种自然语言处理任务和结构化数据表示中展示了其有效性和可行性。精通 Prompt 工程能够增强对大语言模型优缺点的理解。
基于知识图谱的LLM推理。知识图谱存储了大量的显式和结构化知识,能够有效提升LLM的知识 Aware (Pan等人,2024)。因此,针对使用知识图谱增强LLM预训练和生成技术的研究已展开。与自然语言相比,知识图谱具有更清晰的结构化逻辑,能够更好地指导推理。许多研究利用知识图谱中的事实三元组构建语料库,并采用各种预训练任务来增强LLM的能力。然而,这种方法会导致知识图谱失去其可解释性和动态性的优势,并在训练过程中可能面临灾难性遗忘问题(Hu等人,2023)。
因此,利用知识图谱中的事实性信息构建大语言模型 Prompt 是一种更灵活、便捷和安全的解决方案,llm-LightPROF_2504属于此类方法。例如,KAPING(Baek, Aji, and Saffari 2023)基于问题的语义相似性从知识图谱中检索事实性知识,将其作为 Prompt 添加到问题中,然后使用大语言模型生成答案。
KGGPT(Kim et al. 2023)通过三个步骤——句子分割、图推理和推理——使用大语言模型对知识图谱数据进行推理。StructGPT(Jiang et al. 2023)为知识图谱构建了一个专用接口,并提出了一种迭代阅读和推理(IRR)框架,用于通过该接口解决基于知识图谱的任务。ToG(Sun et al. 2024)利用大语言模型在知识图谱上迭代进行束搜索,发现推理路径并返回最可能的推理结果。KnowledgeNavigator(Guo et al. 2024)通过更高效、准确地从知识图谱中检索外部知识来增强大语言模型的推理能力。尽管上述方法已展现出优异的性能,但它们统一以自然语言表示知识图谱,这可能导致信息冗余和混淆,最终导致推理错误。
前提
知识图谱(KG)是一种数据结构,以三元组的形式存储大量知识:,其中和分别表示实体集和关系集。三元组表示头实体与尾实体之间存在关系。
实体 和尾部实体 Anchor 实体是一组实体:,这些实体在基于知识图谱的提问中被引用,其中 表示提问 中的第 个实体
关系链是一个关系序列: ,由一个 Anchor 实体发起,用于进行J跳探索,其中 表示关系链中的第j个关系。
推理路径表示 Anchor 实体 在知识图谱中的关系链接 的一个具体实例。,其中 和 分别表示 中的第 个关系和实体。
方法论
作者设计了LightPROF框架,该框架通过精确检索和细粒度结构化数据处理能力,在小规模LLM下实现高效的复杂知识图谱推理。如图1所示,作者提出的Retrieve-Embed-Reason框架包含三个阶段:推理图检索、知识嵌入和知识 Prompt 混合推理。
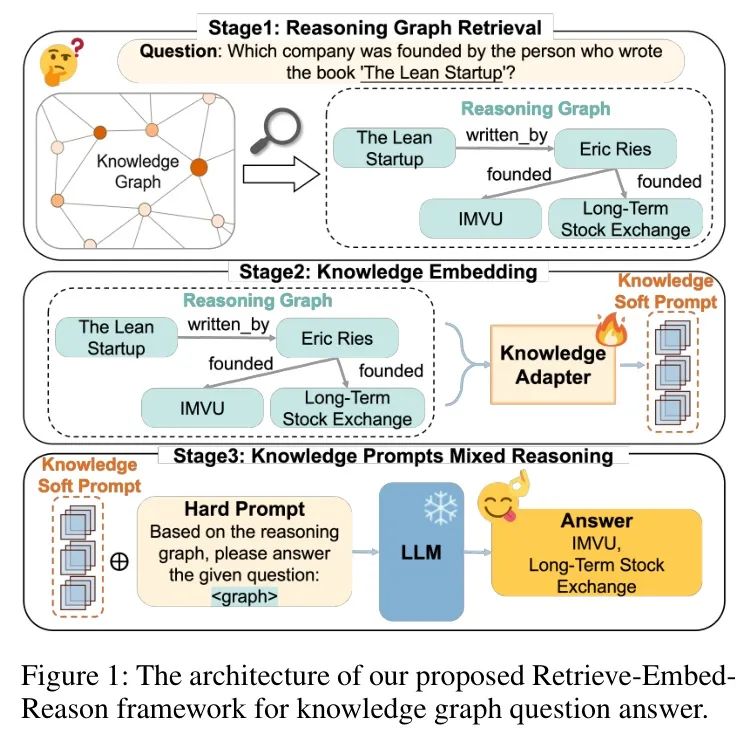
阶段1:推理图检索
对于复杂的多跳知识图谱问答任务,如何高效、准确且稳定地基于问题从知识图谱中检索信息是一个关键问题。为了解决这一重要问题,作者将检索模块分为三个步骤:语义提取、关系检索和推理图采样,如图2所示。
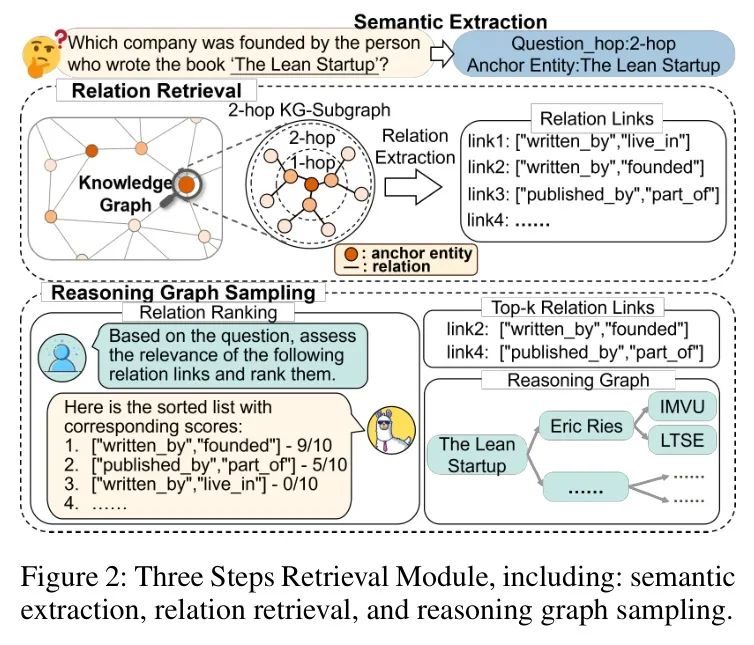
语义提取。对于给定的提问,作者的目标是提取相关的语义(即跳跃次数和 Anchor 实体),从知识图谱(KG)中缩小检索范围,同时保留关键的推理知识。这种方法能够实现高度相关且精确的推理图的检索和构建(Guo等人,2024)。具体而言,作者微调预训练语言模型(PLM),例如BERT,以基于提问的语义向量学习在KG中进行推理所需的跳跃次数。是数据集中的最大跳跃次数,这可以被视为一个分类任务:
关系检索。知识图谱(KG)中的关系描述了两个实体之间的特定连接,为它们的交互提供了语义清晰度,并显著丰富了知识图谱的信息内容。许多当前的研究利用语义丰富的关系链接进行知识图谱推理任务(Xiong,Hoang和Wang 2017;Xu等人2022;Dong等人2023b)。
更重要的是,与不断变化和复杂的实体相比,知识图谱中的关系表现出更高的稳定性和直观性(Cai等人2023)。为了尽可能收集相关知识,作者基于 Anchor 实体和预测的跳数,在知识图谱中搜索关系链接。具体而言,模型首先选择一个 Anchor 实体,然后采用深度限制为的约束广度优先搜索(BFS)。该过程旨在收集所有从 Anchor 实体出发并延伸至预定长度的关系链接。
推理图采样。首先,检索到的关系链接被输入到大语言模型(LLM)中。随后,LLM根据其与问题的语义相关性计算分数并进行排序。然后,作者选择前个相关链接。最后,基于选定的关系链接在知识图谱中进行采样,提取多个推理路径,以构建一个精细的推理图,记为。
阶段2:知识嵌入
知识图谱(KGs)通常包含丰富的复杂结构信息,包括子图结构、关系模式以及实体之间的相对关系(Zhang等人 2023a)。此类结构信息对于大语言模型(LLMs)深入理解知识图谱至关重要。然而,知识图谱结构信息的自然语言表达存在冗余和混淆,无法直接揭示其内在本质,从而阻碍LLMs有效利用这些信息。
为应对上述挑战,受 (Chen et al. 2024; Perozzi et al. 2024) 启发,作者提出一种改进且紧凑的知识 Adapter ,该 Adapter 能够在推理图中编码文本信息的同时提取其结构信息,如图3所示。通过在细粒度层面上结合文本信息与结构细节,知识 Adapter 有助于模型深入理解推理图中的知识,从而实现更精确的推理。
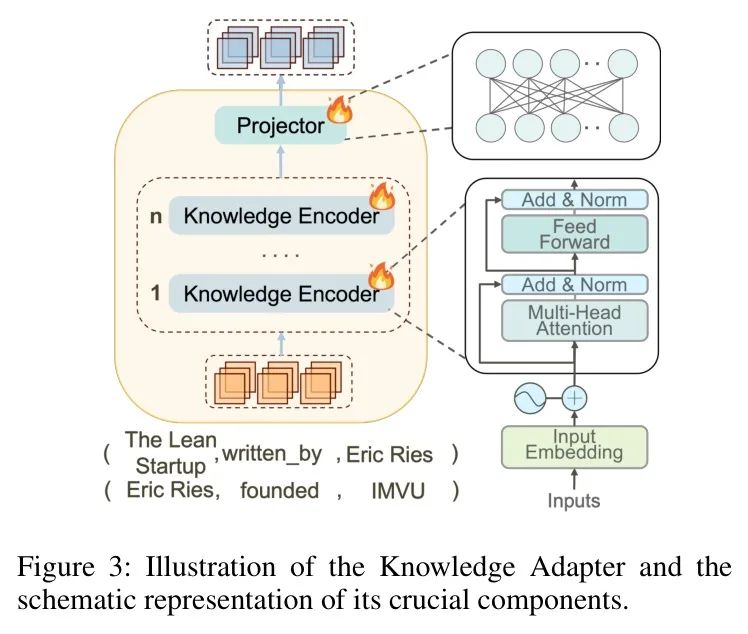
具体而言,作者假设推理图 G_R}= \{R_{n}\}_{n=1}^{N}由N条推理路径组成,每条推理路径被分解为一组三元组\mathcal{T}^{\bar{n}}={(h_{i}^{n},r_{i}^{n},t_{i}^{n})i\in[1,h_{q]},其中h_{q}是推理跳数。随后,使用嵌入\bar{(\cdot)},即,为每个三元组获取关系嵌入e_{i}^{r}:
作者可以以相同的方式获得实体嵌入 。接下来,作者的目标是捕捉每个实体与关系之间的局部和全局交互。首先,作者使用 对 中第 个三元组的局部结构信息 进行编码。然后,使用线性层 Linear 从整个推理路径 中聚合全局结构信息 。
此外,为了捕获推理路径 的文本信息,作者使用 将 中所有实体和关系的文本级信息进行融合。作者首先按照如下方式获得所有头实体的组合文本表示 :
然后,关系 和尾实体的文本表示 可以以相同的方式获得。随后,这些向量被整合为一个向量 ,以表示整个推理路径 的综合文本信息。
其中 是聚合函数。虽然 可以是复杂的神经网络或语言模型,但为了保持文本的语义完整性并降低模型的训练复杂度,作者使用简单的拼接操作来形成一个复合向量,该向量封装了整个推理路径的所有文本信息。
最后,作者使用KnowledgeEncoder 无缝集成所获得的综合文本信息 和全局结构信息 ,导出推理路径的融合表示,如图3所示:
通过这种方式,知识编码器能够有效地将推理图中的每条推理路径编码为一个单一 Token ,显著提高了大语言模型的 Token 利用率,并增强了推理路径的表征能力。在编码过程中,知识编码器不仅捕获了推理图中的丰富文本信息,还捕获了关键的结构信息。由于融合信息 包含文本和结构元素,模型在推理过程中能够更全面地理解嵌入在每条推理路径中的含义。这种多维信息表征增强了模型对上下文的敏感性,促进了更有效的深度语义分析和推理。因此,这种信息融合使得模型能够更准确地捕捉语义和结构之间的复杂交互,从而提高了推理的准确性和深度。
通过聚合所有路径 {Rn}N,作者得到推理图 G_R 的表示序列 [z1^f, z2^f, ..., zN^f]。在将序列输入到大语言模型之前,需要进行维度变换。由于知识编码器的嵌入空间与大语言模型的输入空间存在差异,直接使用这些 Token 将无效。因此,作者开发了一个可训练的 Projector Φ(·),它将这些 Token 映射到大语言模型的 Token Embedding 空间。结果,该过程生成一个适合大语言模型的输入序列,作者称之为知识软 Prompt ps。
在此,作者将设置为两层多层感知器。遵循上述过程,知识 Adapter 能够将推理图的文本表示编码为相应的知识软 Prompt 。重要的是,该 Adapter 的所有参数均来自知识编码器和 Projector 的参数,而这两个组件是LightPROF训练过程中唯一需要调整的部分。
第三阶段:知识 Prompt 混合推理
大语言模型通过在大规模语料库上进行广泛训练获得了丰富的知识。然而,尽管在一般知识方面表现出色,大语言模型在处理专业知识、复杂长逻辑链和多跳知识推理方面存在显著不足,这主要源于其预训练数据的局限性。此外,尽管大语言模型的知识库可以通过再训练进行扩展,但这种方法通常成本高昂且耗时(Sun等人,2024年)。更严重的是,再训练可能导致模型中现有知识的灾难性遗忘(Zhang等人,2024年)。因此,这给保持大语言模型的知识更新带来了一定的挑战。
为了避免上述挑战,作者在LightPROF训练过程中冻结大语言模型的参数,并采用软 Prompt 和硬 Prompt 的组合来指导模型更精确、高效地回答问题,如图1所示。
具体而言,LLM的输入以聊天格式组织,其中指令和问题通过精心设计的文本模板相结合,作者称之为硬 Prompt 。在LLM的编码阶段,作者将代表推理图的软 Prompt 知识插入到硬 Prompt 的特定位置,以有效注入外部知识,如图1所示。这种方法使LLM能够根据给定输入内容自主且准确地回答问题,而无需更新参数。通过这种方法,作者不仅保持了模型的稳定性,还提升了其在特定知识领域的性能和效率。
LightPROF的训练目标是最大化数据集中所有样本生成正确答案的可能性。这可以与下一词预测任务相兼容,后者是训练生成模型的基本方法。训练目标可以表述为:
其中 是包含硬 Prompt 和软 Prompt 的输入序列,而 是输出序列的第 个 Token 。值得注意的是,当 时, 是模型的起始序列(BOS) Token 。
实验
在本实验中,作者将深入探讨以下问题。问题1:LightPROF能在KGQA任务中多大程度上提升LLMs的性能?问题2:LightPROF能否与不同的LLM主干网络集成以提升性能?问题3:LightPROF能否使用小规模LLM实现高效的输入和稳定的输出?
数据集
作者在基于Freebase知识图谱(Bollacker等人,2008年)的两个公共数据集上训练和评估LightPROF的多跳推理能力:WebQuestionsSP(WebQSP)(Yih等人,2016年)和ComplexWebQuestions(CwQ)(Talmor和Berant,2018年)。根据先前的研究,作者利用匹配精度(Hits@1)来评估模型的top-1答案是否正确。
WebQSP是一个包含较少问题但知识图谱更大的基准,共包含4,737个问题。每个问题包括一个主题实体、一个推理链和一个用于查找答案的SPARQL Query 。答案实体需要在Freebase上进行最多2跳推理。CwQ是一个专门为复杂知识图谱问答研究设计的基准,基于WebQSP数据集构建,包含34,689个问答对。它通过自动创建更复杂的SPARQL Query 并生成相应的自然语言问题,从而创建广泛多样的问题类型。这些问题需要在Freebase上进行最多4跳推理。
Baseline 模型
作者考虑三种类型的 Baseline 方法:全微调方法、纯LLM方法和LLM+知识图谱方法。全微调方法包括KV-Mem(Miller等人,2016年)、EmbedKGQA(Saxena、Tripathi和Talukdar,2020年)、TransferNet(Shi等人,2021年)、NSM(He等人,2021年)、KGT5(Saxena、Kochsiek和Gemulla,2022年)、GraftNet(Sun等人,2018年)、PullNet(Sun、Bedrax-Weiss和Cohen,2019年)、UniKGQA(Jiang等人,2022年)。纯LLM方法包括LLaMa系列模型(Touvron等人,2023年)。LLM+知识图谱方法包括StructGPT(Jiang等人,2023年)、ToG(Sun等人,2024年)、KnowledgeNavigator(Guo等人,2024年)、AgentBench(Liu等人,2024年)。值得注意的是,为确保公平比较,作者选择的LLM+知识图谱方法不涉及对LLM进行微调,即它们都是零样本方法,没有任何LLM的训练。
实现
为展示LightPROF的即插即用便利性和参数效率,作者在LLaMa系列中的两个小规模语言模型上进行了实验:LLaMa7B-chat(Touvron等人,2023年)和LLaMa-8B-Instruct'。该模型经过一个训练周期的优化,批处理大小为4。初始学习率设置为2e-3,采用余弦退火调度进行调整,以提高模型在训练过程中的学习效率。所有实验均使用PyTorch工具包在NVIDIA A800 GPU上进行。
知识编码器模块基于BERT模型。该模块包含一个两层的多层感知器 Projector ,用于将维度映射到LLM的输入维度。
Q1 性能比较
主要结果。作者将LightPROF与三类 Baseline 方法进行评估:全量微调、纯LLM和方法。如表1所示,LightPROF不仅在对简单问题的回答上表现优异,而且在需要深度推理和复杂 Query 处理的场景中同样展现出高性能。具体而言,LightPROF在WebQSP数据集上显著超越了当前最佳模型( vs. ),并且在更复杂的CwQ数据集上也表现出色( vs. )。这些结果验证了llm-LightPROF_2504在处理KGQA任务方面的卓越能力,突出了LightPROF在应对多跳和复杂挑战时的有效性。、
与使用纯文本 Prompt 的普通LLM和方法相比,LightPROF的显著改进表明知识 Adapter 生成的软 Prompt 能够比离散文本更有效地封装更复杂的结构化知识,这些软 Prompt 简洁、信息丰富且表达力强,从而增强了LLM对KG信息理解。值得注意的是,llm-LightPROF_2504在所有实验条件下均优于其他大规模模型。例如,与使用LLaMa2-70B-Chat的ToG(Sun等人,2024)和使用ChatGPT的StructGPT(Jiang等人,2023)相比,llm-LightPROF_2504表现尤为突出,尤其是在解决复杂问题时。此外,即使使用较小的LLaMa2-7b版本,llm-LightPROF_2504也能与其他大规模模型有效竞争,这突显了llm-LightPROF_2504设计的效率和优化。
消融实验。对LightPROF进行消融实验,以研究知识的具体影响
KGQA任务上的 Adapter 性能。作者考察了三种变体:(1) w/o Struct,移除知识嵌入过程中包含的结构信息,(2) w/o Train,不训练知识编码器,以及(3) Random Retrieve,从知识图谱中随机检索推理路径。结果展示在表2中。
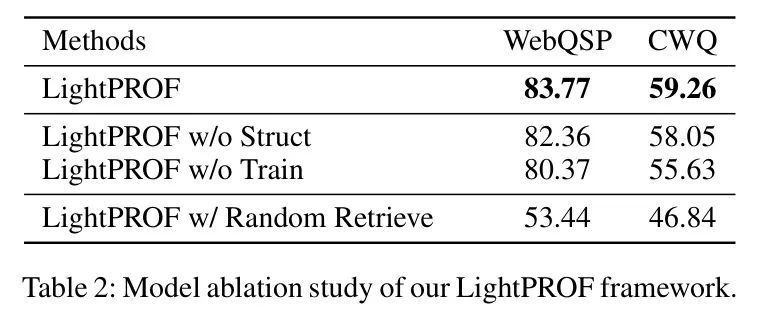
结果表明,结构信息的整合对于模型理解和处理复杂 Query 中的实体和关系至关重要。结构信息的引入显著提升了模型在知识图谱中数据利用效率。知识编码器的持续训练对于增强模型的知识表示理解和生成同样关键。该训练过程显著提高了模型编码复杂结构知识的能力,使其能够更准确地响应基于深层知识的 Query 。此外,随机检索的推理路径会对性能造成显著损害,凸显了准确且稳定的检索模块的重要性。
此外,作者还探索了不同的结构编码器。llm-LightPROF_2504中使用的结构编码器将三元组编码为头(HΣ+)关系(R)-尾(T)。表3中的结果表明,由于无法区分三元组的顺序,H+R+T编码方法的性能略有下降,例如从(埃里克·里斯,创立,IMVU)和(IMVU,创立,埃里克·里斯)中推导出的结构信息是相同的,这降低了模型理解结构信息的能力。相比之下,LightPROF能够更好地在推理图中捕获结构信息,并以更细粒度的方式将其整合,从而增强了模型的理解能力,特别是在涉及复杂结构数据推理的场景中。

Q2:即插即用
对于llm-LightPROF_2504,任何能够接受token嵌入输入的开源LLM都适用。在本节中,作者评估了在LightPROF中集成不同LLM的有效性。如表5所示,结果表明LightPROF框架显著提升了集成LLM的性能,无论原始模型的 Baseline 性能如何。LightPROF通过结构化数据的有效集成和优化,增强了模型解决复杂KG问题的能力。这种即插即用的集成策略无需对LLM进行昂贵的微调,因此特别适合快速提升现有模型在KGQA任务上的性能。

Q3:高效输入与稳定输出
效率结果。进行了一系列效率测试,以比较LightPROF和StructGPT(Jiang等人,2023年)在处理WebQSP数据集时的性能。具体而言,测量了模型的运行时间、输入token总数以及每个请求的平均token数(NPR),结果如表6所示。该表显示,在处理相同数据集时,LightPROF具有更高的时间效率,时间成本降低了30%(1:11:49 vs. 1:42:12)。关于输入token总数,LightPROF和StructGPT之间存在显著差异(365,380 vs. 24,750,610),这表明LightPROF在输入处理方面更为经济,减少了约98%的token使用。此外,LightPROF的NPR值为224,显著低于StructGPT的6400。这种比较进一步突出了LightPROF在每项请求所需的token数量上的优势,展示了其更精确和资源高效地处理每个请求的能力,验证了LightPROF在集成小规模LLM时的有效性。

案例研究。如表4所示,作者通过将LightPROF的性能与StructGPT进行比较,验证了其在使用小规模LLM时具备高效的输入和稳定的输出能力,以回答关于琳达·洛翰药物滥用的复杂 Query 。结果表明,LightPROF不仅能够准确识别并全面回答 Query ,还展示了更深入的推理路径和整体评分。相比之下,虽然StructGPT处理了相关问题,但它未能全面捕捉所有相关答案。有趣的是,作者发现LightPROF能够始终如一地生成仅包含答案的输出,并使用更少的输入token和更短的推理时间。这表明LightPROF能够有效整合并精确输出知识图谱中的复杂信息,展示了其在高效、准确处理复杂KGQA任务中的可靠性和实用性。

参考
[1]. LightPROF: A Lightweight Reasoning Framework for Large Language Model on Knowledge Graph
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号