感觉简单 | NatMed | 92名医生与GPT-4在多种临床场景下的表现对比

感觉简单 | NatMed | 92名医生与GPT-4在多种临床场景下的表现对比

生信菜鸟团
发布于 2025-04-26 20:50:41
发布于 2025-04-26 20:50:41
Basic Information
- 英文标题:GPT-4 assistance for improvement of physician performance on patient care tasks: a randomized controlled trial
- 中文标题:GPT-4辅助提高医生在患者护理任务中的表现:一项随机对照试验
- 发表日期:05 February 2025
- 文章类型:Article
- 所属期刊:Nature Medicine
- 文章作者:Ethan Goh | Adam Rodman
- 文章链接:https://www.nature.com/articles/s41591-024-03456-y
Abstract
Para_01
- 大型语言模型(LLMs)在诊断推理方面显示出潜力,但它们对管理推理的影响尚不清楚。管理推理涉及平衡治疗决策和检测策略的同时管理风险。
- 这项前瞻性、随机对照试验评估了LLM辅助是否能提高医生在开放性管理推理任务中的表现,与传统资源相比。
- 从2023年11月到2024年4月,92名执业医师被随机分配使用GPT-4加传统资源或仅使用传统资源来回答五个由专家开发的临床病例场景,在模拟环境中。
- 所有案例均基于真实、匿名的患者接触记录,并按顺序揭示信息,以反映临床环境的性质。
- 主要结果是在专家制定的评分标准上两组之间的总分差异。
- 次要结果包括特定领域的得分和每个案例所花的时间。
- 使用LLM的医生得分显著高于仅使用传统资源的医生(平均差异=6.5%,95%置信区间(CI)=2.7至10.2,P<0.001)。
- LLM用户在每个案例上花费的时间更多(平均差异=119.3秒,95% CI=17.4至221.2,P=0.02)。
- LLM增强的医生和仅LLM之间没有显著差异(-0.9%,95% CI=-9.0至7.2,P=0.8)。
- LLM辅助可以在复杂的临床病例场景中改善医生的管理推理,与传统资源相比,应在真实的临床实践中进行验证。
- ClinicalTrials.gov注册号:NCT06208423。
Main
Para_01
- 大型语言模型(LLMs)在诊断推理方面表现出相当的能力,在构建有助于区分诊断、解释推理和从标准化患者那里收集历史信息方面优于先前的人工智能(AI)模型和人类医生。
- LLMs尚未被证明在管理推理方面表现相似,这包括围绕治疗、检测、患者偏好、健康的社会决定因素和具有成本意识的护理的决策,同时还要管理风险。
Para_02
- 虽然存在重叠,临床推理通常被认为既包括诊断推理也包括管理推理。
- 诊断推理的研究有着百年历史,并有许多元认知框架和评估方法,而管理推理过程则是一个相对较新的研究领域。
- 当前管理推理的框架包括依赖于情境的概念,如共享决策、动态关系以及医疗系统和个人之间的优先事项冲突、医患关系以及现代临床接触中固有的时间限制。
- 与诊断推理不同,诊断推理可以看作是一项分类任务,通常只有一个正确答案,管理推理可能没有正确的答案,涉及权衡具有内在风险的行为方案之间的取舍;即使通过‘观望等待’的不作为也是一种经过深思熟虑的选择,可能会带来潜在的风险和利益。
- 从认知心理学的角度来看,管理推理常常使用称为管理脚本的启发法,这使临床医生能够快速做出决定。
- 然而,这些脚本容易受到影响人类推理其他领域的同样缺陷的影响。
- 除少数例外情况外,这些脚本必须根据具体情况进行调整,以平衡所有影响管理推理的因素,并且必须不断更新以适应新出现的信息。
Para_03
- 前几代非LLM的AI系统可以在某些情况下改善人类管理决策,尤其是在人类用户将AI建议视为第二个意见时。
- LLMs的一个理论优势是它们能够作为合作伙伴,增强人类的认知。
- LLMs可以提供不同的观点,这有助于将患者和临床医生的价值观和目标整合到一个连贯的计划中。
- 我们设计了一项前瞻性、随机、对照试验,以评估使用LLM的医生是否在一系列复杂的临床管理问题上比使用标准资源的医生表现更好。
- 然后我们将医生的回答与LLM(没有人的参与)单独的输出进行了比较。
- 所有案例均来源于真实的、去识别化的患者病例。
- 医生不是一次性获得全部病例信息,而是按顺序接收信息,以反映临床进展的复杂性。
- 这一设计选择使医生能够在新数据出现时迭代地制定和调整他们的管理计划。
Results
Para_01
- 我们招募了92名医生参与这项从2023年11月30日到2024年4月21日进行的研究。
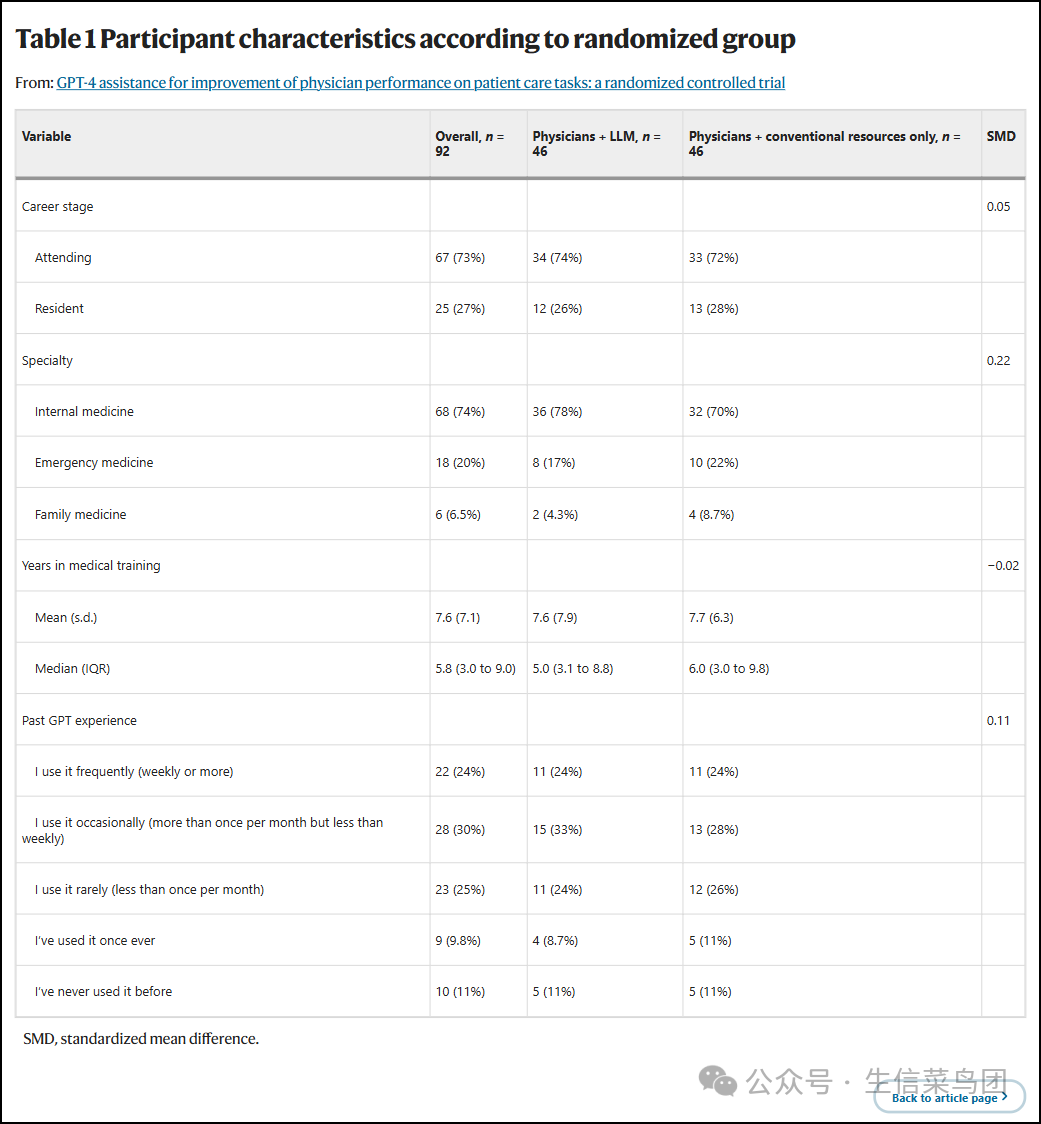
- 参与者被随机均分为LLM组和传统资源组(图1);其中73%(67人中的92人)是主治医生,而27%(25人中的92人)是住院医生(表1)。
- 74%(68人中的92人)的专业是内科,20%(18人中的92人)是急诊科,6.5%(6人中的92人)是家庭医学。
- 所有医生的平均执业年限为7.6年,中位数为5.8年(四分位间距(IQR)= 3.0至9.0年)。
- 只有24%(22人中的92人)自我描述为经常使用LLM的人;20.8%(19人中的92人)要么只使用过一次,要么从未使用过。
Fig. 1: Study flow diagram.
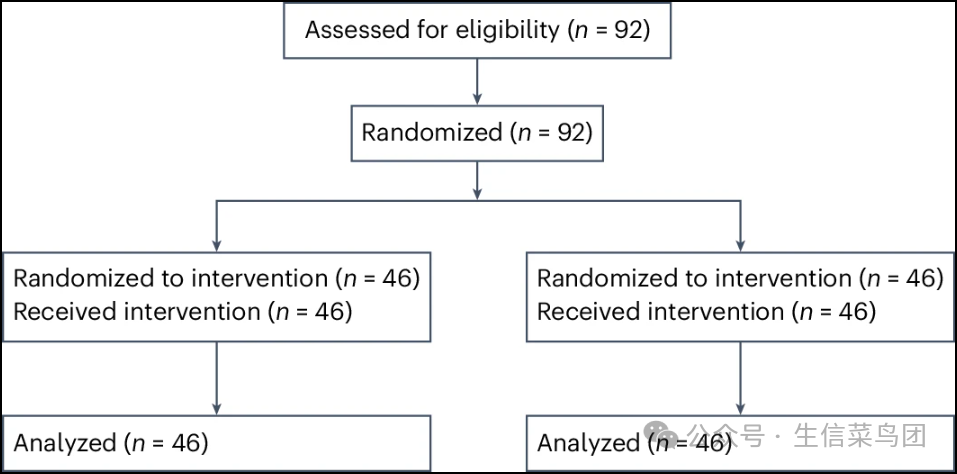
- 图片说明
◉ 这项研究包括92名正在执业的主治医师和住院医师,他们接受过内科、家庭医学或急诊医学的培训。◉ 提出了五个由专家开发的病例,并使用德尔菲法创建了评分标准。◉ 医生们被随机分配到两个组,一组使用GPT-4通过ChatGPT加上传统资源(例如,UpToDate、Google),另一组仅使用传统资源。◉ 主要结果是在专家开发的评分标准上两组总分的差异。◉ 次要结果包括特定领域的分数和每个病例所花费的时间。◉ 数据来源
Table 1 Participant characteristics according to randomized group 表1 随机分组后的参与者特征
Para_02
- 从这92名医生中,总共对400个病例进行了评分,其中176个病例来自使用LLM的医生组,199个病例来自仅使用传统资源的医生组,25个病例来自单独使用LLM的医生。三位评分者对400个病例中的328个(82%)达成了评分一致,综合kappa统计量(κ)为0.80,反映了评分者之间存在显著的一致性(案例1 κ=0.58,案例2 κ=0.83,案例3 κ=0.82,案例4 κ=0.90,案例5 κ=0.89)(补充材料1提供了案例、评分标准和高分与低分参与者案例响应的例子)。
Management performance
管理绩效
Para_01
- 医师们使用LLM的表现优于对照组(43.0%对比35.7%,差异=6.5%,95%置信区间(CI)=2.7%至10.2%,P<0.001)(表2和图2)。
- 仅使用LLM的得分与使用LLM的人类相当(43.7%对比43.0%,差异=0.9%,95% CI=-7.2%至9.0%,P=0.80),而倾向于比使用传统资源的人类得分更高(43.7%对比35.7%,差异=7.3%,95% CI=-0.7%至15.4%,P=0.074)(图3)。
- 我们进行了额外的事后敏感性分析,使用重复测量方差分析(补充材料5),结果显示与主要使用混合效应模型的分析结果相似。
Table 2 Comparisons of the primary and secondary outcomes for physicians with LLM and with conventional resources only (scores standardized to 0–100) 表2 医师使用LLM和仅使用传统资源的主要和次要结果比较(分数标准化为0-100)
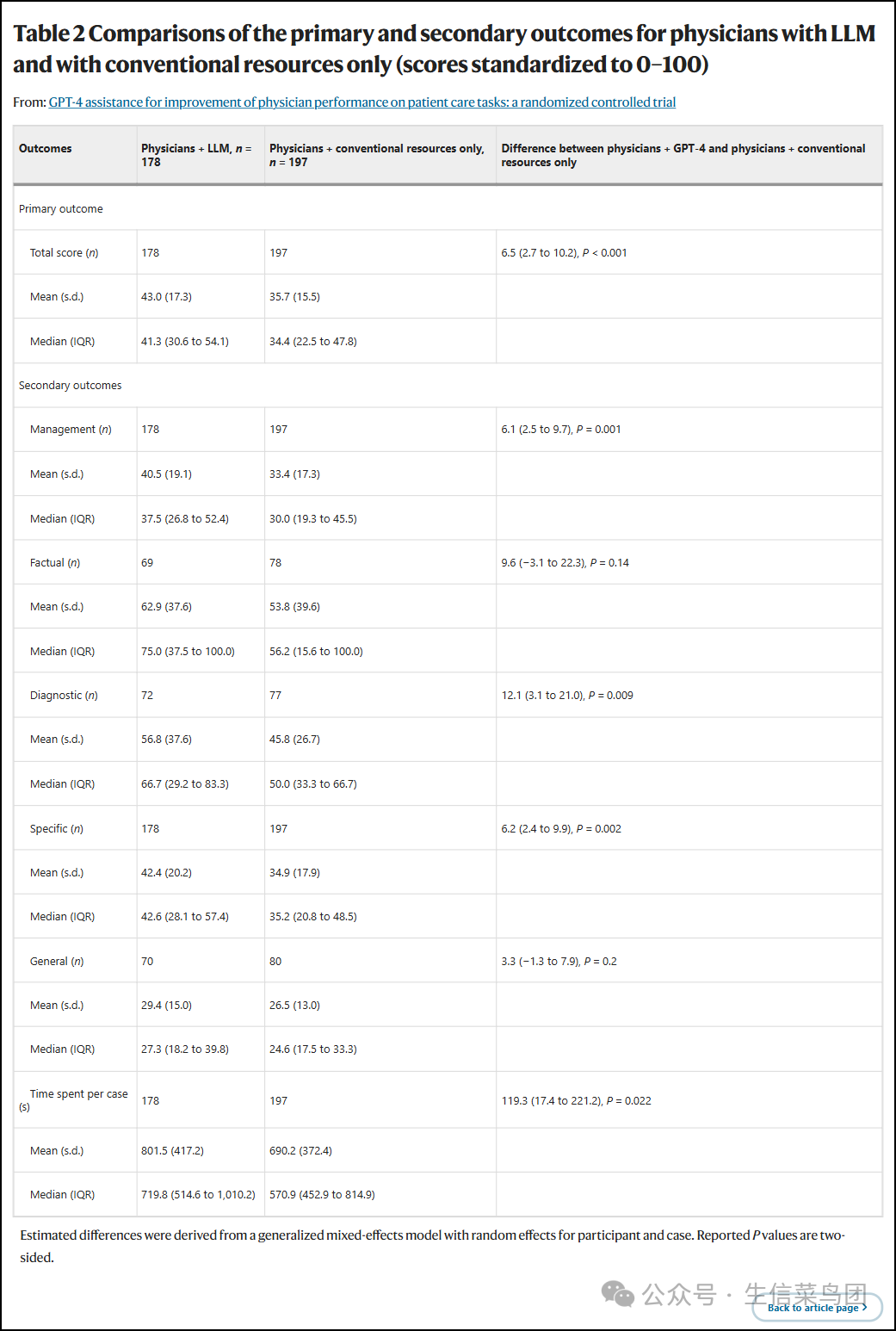
Fig. 2: Comparison of the primary outcome for physicians with LLM and with conventional resources only (total score standardized to 0–100).
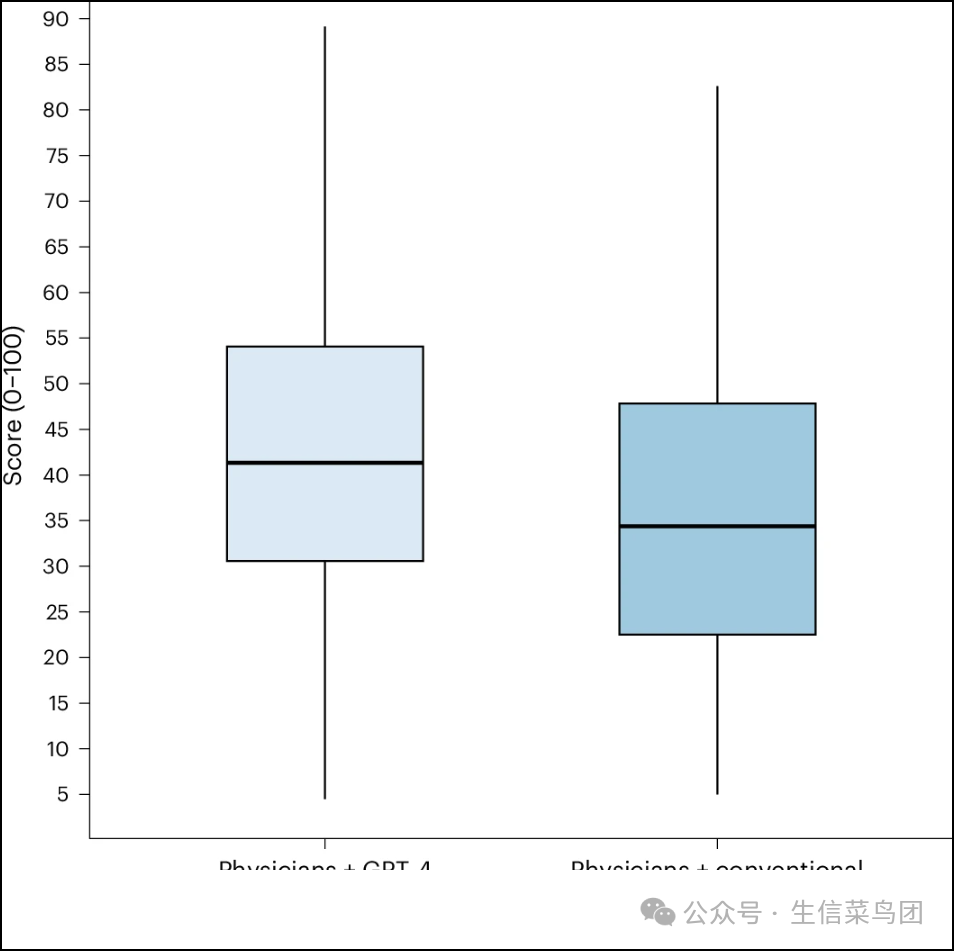
- 图片说明
◉ 九十二名医生(46名随机分配到LLM组和46名随机分配到传统资源组)完成了375个病例(LLM组中有178个,传统资源组中有197个)。箱线图的中心代表中位数,边界代表第一和第三四分位数。须线代表中心1.5倍四分位距范围内的最远数据点。◉ 无额外句子。
Fig. 3: Comparison of the primary outcome according to GPT alone versus physician with GPT-4 and with conventional resources only (total score standardized to 0–100).
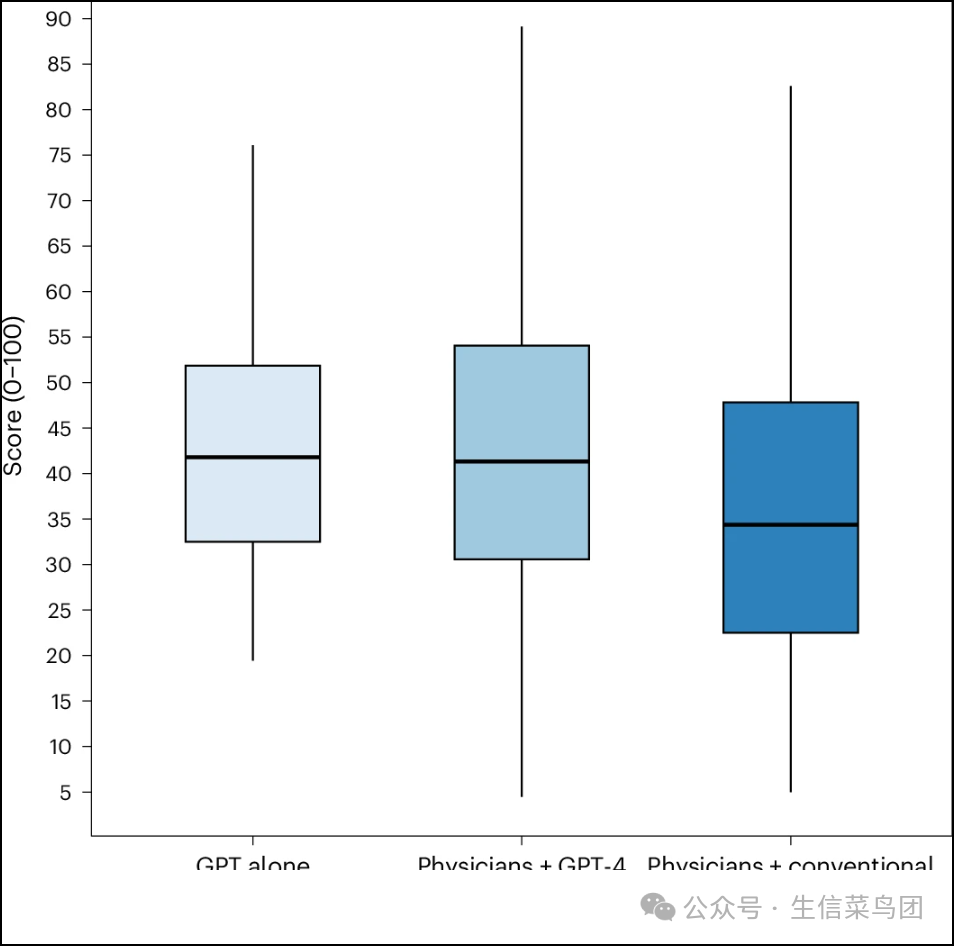
- 图片说明
◉ GPT-alone 组代表由研究团队提示模型完成五个案例,每个案例提示模型五次,总共得到25个观察结果。◉ 拥有 GPT-4 的医师组包括46名参与者,完成了178个案例,而拥有传统资源的医师组包括46名参与者,完成了197个案例。◉ 箱线图的中心表示中位数,边界表示第一和第三四分位数。◉ 须触线表示中心点外最远的数据点,在1.5倍四分位距(IQR)范围内。
Question domain subgroups
问题领域子群
Para_01
- 使用LLM的医生在明确测试管理决策的问题上得分高于仅使用传统资源的医生(40.5%对比33.4%,差异=6.1%,95%置信区间=2.5%至9.7%,P=0.001),
- 在测试诊断决策的问题上得分更高(56.8%对比45.8%,差异=12.1%,95%置信区间=3.1%至21%,P=0.009),
- 以及在特定情境的问题上得分更高(42.4%对比34.9%,差异=6.2%,95%置信区间=2.4%至9.9%,P=0.002)。
- 虽然我们没有发现两组之间在事实回忆方面存在显著差异(62.9%对比53.8%,差异=9.6%,95%置信区间=-3.1%至22.3%,P=0.14)和一般管理知识方面(29.4%对比26.5%,差异=3.3,95%置信区间=-1.3%至7.9%,P=0.2),
- 但这些结果在方向上与其他子领域相似。
Time
时间
Para_01
- 使用LLM的医师每例多花费了111.3秒(801.5秒对比690.2秒,差异=119.3秒,95%置信区间=17.4至221.2,P=0.022)(图4)。
- 我们进行了额外的事后敏感性分析,调整了每例所花时间(扩展数据表1),结果显示即使调整了所花时间,每例得分仍增加了5.4个百分点(95%置信区间=1.7至9.0,P=0.004)。
- 子领域中的结果相似。
- 我们进一步检查了未调整的时间花费与总分之间的相关性,发现两组在花费时间和总分之间均存在正相关(扩展数据表2)。
- 总体而言,我们观察到对于每增加的一分钟案件处理时间,每例得分有小幅但统计上显著的增长,增长了0.6分(95%置信区间=0.4至0.8,P<0.001),这使用混合效应模型得出(扩展数据图1)。
Fig. 4: Comparison of the time spent per case by physicians using GPT-4 and physicians using conventional resources only.
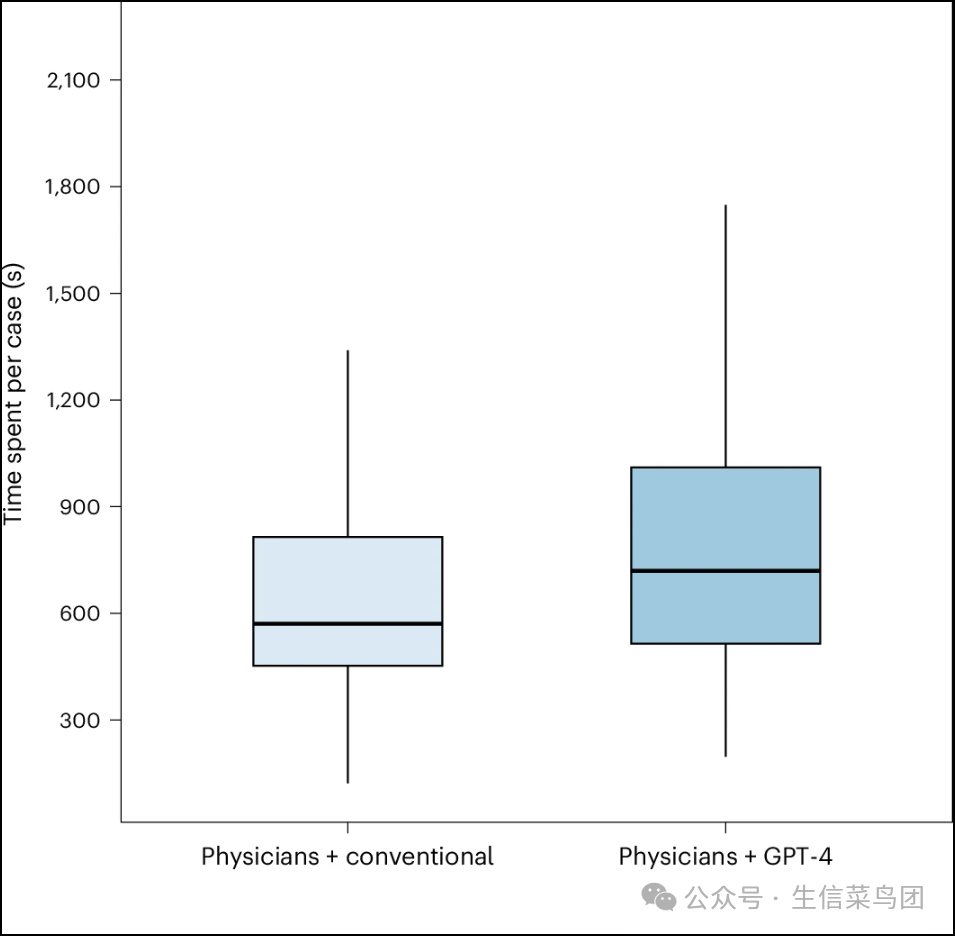
- 图片说明
◉ 九十二名医生(46名随机分配到LLM组和46名随机分配到传统资源组)完成了375个病例(LLM组中有178个,传统资源组中有197个)。箱线图的中心代表中位数,边界代表第一和第三四分位数。须线代表中心1.5倍四分位距范围内的最远数据点。◉ 无附加句子
Response length
响应长度
Para_01
- 为了应对响应长度对评分的潜在影响,我们进行了额外的事后敏感性分析,调整了我们的主要分析中的响应字符数(补充项目 3)。
- 这一分析显示了效果有所减弱,但仍然为正向,LLM 组得分高出了 3.7 个百分点(95% 置信区间 = 0.7 到 6.7,P = 0.02)。
- 值得注意的是,虽然较长的响应往往得分更高(大约每 100 个字符增加 0.3 分),但在进行这一调整后,LLM 手段组的表现仍优于传统资源组。
Likelihood and extent of harm
可能性和伤害程度
Para_01
- 分析潜在危害显示了各组之间相似的模式(补充材料项目6)。
- 在LLM辅助组中,8.5%和4.2%的医生回复分别具有中度和高度的危害可能性,而在传统资源组中,这一比例分别为11.4%和2.9%。
- 关于危害严重程度,LLM辅助组中有4.0%的回复观察到轻至中度危害,而在传统资源组中这一比例为5.3%。
- 两组之间的重度危害评分几乎相同(LLM=7.7%;传统=7.5%)。
Discussion
Para_01
- 在这项随机对照试验中,与仅使用传统资源相比,LLM的可用性提高了医师的管理推理能力,而随机分配到使用AI和单独使用AI的医师得分相当。
- 这表明LLM在未来可能作为辅助临床医生判断的一种有用的工具,同时也突显了在某些临床场景中独立LLM应用的潜力。
- 区分LLM辅助在哪些具体情境下能为医师带来附加价值,以及AI可能在哪些领域独立发挥作用,变得越来越重要。
- 从认知心理学的角度来看,LLM增强管理推理能力这一点令人惊讶。
- LLM做出诊断决策的能力可能源于其底层的标记预测架构,以及这种架构与医师在诊断过程中聚集和激活语义疾病脚本的相似性。
- 另一方面,管理脚本高度依赖于具体情境和个人化因素,并包括许多超出生物医学接触范围的因素。
- 因此,在特定情况下患者的最佳治疗方案可能与另一名患有相同疾病的患者在不同情境下的最佳治疗方案不同。
- 例如,偶然发现的位于上叶的2.0厘米肺结节在住院患者中的适当处理方式可能是:对于不太可能随访的患者进行立即活检;对于有能力组织并确保连续性的医疗系统中的患者安排门诊活检;对于不愿意接受侵入性程序的患者进行门诊正电子发射断层扫描;或者对于预期寿命有限的患者进行系列影像检查。
- 了解上叶存在大结节的患者恶性肿瘤的可能性较高只是制定后续计划的第一步,患者的偏好、对医疗系统的了解以及患者的社会状况同样是重要因素。
Para_02
- 使用LLM的小组花费了更多时间解决病例,这一发现与对诊断支持系统的历史研究一致19,20,但与最近关于LLM在诊断推理中的使用的发现相矛盾4,5。
- 虽然这种增加的时间可能是因为案例问题解决和与LLM互动的综合影响,但与LLM的互动可能起到了有益的‘暂停’作用,以便更好地考虑患者背景。
- 例如,我们观察到使用LLM的医生在困难情况下对其他提供者和患者的明显同情心表现得更频繁。
- 我们怀疑其中一些新出现的能力来自一种称为通过人类反馈进行强化学习的微调过程,在这个过程中,富有同情心和以患者为中心的回应被人类评为有利21。
- 类似于研究表明LLM对患者查询的沟通方式更具同情心的研究,本研究表明LLM可能会促使医生在管理推理中更好地考虑人类因素22,23,24。
- 当临床医生与LLM合作时,他们表现出改进的人文主义和以患者为中心的行为是一个重要且甚至令人安心的发现,即使这需要花费更多的时间。
Para_03
- 值得注意的是,在调整了每个案件花费的时间和回复长度(补充项目4)后,LLM组持续的优势表明这种改进的性能不能仅归因于这些因素。
- 进一步探索LLM是否仅仅是鼓励用户放慢速度并更深入地反思,或者它是否正在积极增强推理过程将是有价值的。
- 虽然我们的研究结果表明这两种影响的结合,但未来的研究可以通过引入一个被提示暂停并考虑替代因素而不使用LLM支持的小组来更明确地控制这一变量,并且更系统地评估用户如何直接与LLMs互动。
Para_04
- 本研究存在多个局限性。
- 首先,案例是临床病例描述,基于但不是实际患者病例。
- 尽管我们的评分标准显示了相当高的评分者间可靠性,但这些标准的有效性证据尚未在本研究之外进行收集。
- 只对可能正确的答案给予信用,而错误的答案未被惩罚。
- 这种方法与许多标准化的临床推理评估方法一致,例如美国的Step 2临床技能考试和英国的实用临床检查技能考试。
- 这种方法的选择是为了便于解释结果,并关注奖励适当的临床决策而不是惩罚错误。
- 虽然这种方法没有捕捉到错误决策可能带来的潜在危害,但探索性的二次分析表明,在LLM可供医生使用的情况下,无论是伤害的可能性还是伤害的程度都没有显著差异。
- 在临床环境中实施LLM的实际应用需要仔细考虑潜在的幻觉和错误信息如何影响患者的护理。
- 具体而言,现实世界中的LLM部署可能需要医生作为唯一的可靠后盾来纠正错误信息,这可能会影响认知负荷和决策质量。
- 此外,我们承认在回答中区分准确性与全面性具有内在挑战。
- 我们的评分标准设计通过修改后的德尔菲过程基于专家共识,试图通过为每个问题设定最大得分上限来平衡这些因素,并奖励回答的适当性而非全面性。
- 继续改进评估工具可能进一步提高区分临床推理这些方面的能力。
Para_05
- 只有五个案例预计供参与者在一个小时内完成,我们有意选择了涵盖普通医学广泛内容的内容,与标准化评估如客观结构化临床考试一致。
- 更多的案例种类可能会显示出不同的结果。
- 最后,我们只提供了对两个组使用大型语言模型的基本培训以及技术支持。
- 尽管证据表明提示策略可以显著提高模型在医疗任务上的表现,但我们故意选择模仿当前在医疗环境中部署大型语言模型的策略,这些策略在形式化的提示策略培训方面提供的最少。
- 25,26.
Para_06
- 这项研究发现,与传统资源相比,加入LLM AI助手改善了医生的管理推理。
- 早期将LLM应用于医疗保健主要集中在文书临床工作流程上,包括门户消息传递和环境监听。
- 我们的研究结果表明,即使是在像管理推理这样复杂的任务中,决策支持也代表了LLM的一个有前景的应用。
- 为了充分发挥其潜力以提高患者护理质量,需要在真实的临床环境中进行严格的验证。
Methods
Participants
参与者
Para_01
- 我们通过斯坦福大学、贝丝以色列女执事医疗中心和弗吉尼亚大学的电子邮件列表招募了具有普通内科专业培训的执业主治医师和住院医师。
- 在注册和随机分组前获得了书面知情同意。
- 斯坦福大学、贝丝以色列女执事医疗中心和弗吉尼亚大学的机构审查委员会审查后确定此研究无需接受机构审查委员会监管。
- 参与者的小团体由研究协调员远程或在实体计算机实验室监考。
- 每次会议持续1小时。
- 住院医师完成研究可获得100美元报酬,主治医师可获得200美元报酬。
Clinical case vignette construction
临床病例描述构建
Para_01
- 我们从美国医师协会播客‘核心内部医学’中的‘灰色地带’系列中构建了我们的案例。
- 由于这些案例是专门为本研究改编的,因此在我们的研究之前,GPT-4和参与者都无法获得这些案例。
- 每个案例都是由一组专科和全科专家(包括A.R.、Z.K.、E.S.、J.H.和A.S.P.)构建的,目的是探讨当没有明确正确答案时医生如何做出决策。
- 我们故意选择了一系列案例,以探索普通内科管理决策的广度。
- 通过初步试点研究(这些研究未包含在分析中),我们确定没有参与者在一小时内完成超过五个案例,这与医生推理的标准测试一致,例如执照考试和结构化临床观察考试。
- 这些标准测试包括执照考试和结构化临床观察考试。
Development of scoring rubrics
评分标准的开发
Para_01
- 评估管理推理的主要挑战是,合理的答案因上下文因素而异,范围相对较广30,31。
- 与已确诊的病理最终诊断不同,管理推理通常有许多可接受的答案。
- 为了捕捉这种多种管理视角的细微差别,在每个案例中,我们召集了一个由五人组成的专家小组——研究团队的一名成员、两名全科医生和两名该病例适用领域的专科医生。
- 通过迭代修改后的德尔菲过程,我们完善了用于评分每个案例的管理标准。
- 这些标准旨在尽可能详尽地针对特定案例,同时承认可接受的管理方式存在相当大的差异。
- 因此,这些标准上的得分不符合教育干预的标准分界线(例如,40%并不代表‘通过’或‘未通过’分数,只反映了全面标准中的总可能分数的一部分;所有合理答案均获得分数,而较高的分数表示更全面的回答,但没有明确的高质护理分界线)。
- 每个标准都在两个试点组中进行了测试,并根据用户反馈进一步改进。
- 由于诊断和管理临床推理领域之间往往没有明确的界限,每个问题都由研究团队的两名成员(E.G. 和 H.K.)独立标记,反映案例特定推理或不需要案例特定信息的更通用的临床推理。
- 案例问题同样被分类为表示诊断决策(例如,偶然发现的肺结节的鉴别诊断),管理决策(例如,驱动肺结节后续检查步骤的背景因素)或知识回忆(使肺结节更可能恶性的风险因素)。
- 这些标签完全一致。
Study design
研究设计
Para_01
- 我们使用了一种前瞻性的、随机化的、单盲(对评分者来说)研究设计,参与者被随机分配到使用通过ChatGPT Plus(OpenAI)界面访问的GPT-4或常规资源组(图1)。
- 为了模拟实际应用情况,参与者接受了与当前临床环境中实际部署相仿的GPT-4培训。
- 这包括了系统访问和使用的初步指导,以及在整个研究过程中由监考人员提供的实时技术支持。
Para_02
- 两组都被指示可以使用他们在临床实践中通常使用的任何即时诊疗资源,如UpToDate(Wolters Kluwer)、Epocrates(Athenahealth)和其他互联网资源。
- 对照组被指示不得使用任何大型语言模型(例如,ChatGPT、Claude、Bard/Gemini)。
- 我们指示参与者在一小时内尽可能完成五个病例中的更多,优先保证答案的质量而非完成所有病例。
- 该研究使用Qualtrics调查工具进行;参与者在继续前会分段接收病例。
- 随着新信息的引入,参与者无法更改他们对先前提示的回答。
Prompt design for the LLM-only arm
LLM专用提示设计
Para_01
- 对于仅使用LLM的组,我们使用已确立的提示设计原则,通过复制和粘贴管理案例以及问题(补充项目2)33,迭代开发了一个零样本提示。每个提示运行了五次,这五次运行的结果连同人类输出一起被纳入盲评,然后才进行任何解盲或数据分析。
- 每个提示运行了五次,这五次运行的结果连同人类输出一起被纳入盲评,然后才进行任何解盲或数据分析。
Rubric validation
评分标准验证
Para_01
- 两个初步的数据集从十个人那里收集来验证评分标准。
- 三个评分者(A.R.、E.S. 和 K.P.L.)独立地对这两个数据集进行了评分。
- 随后他们亲自碰面,就这两个验证数据集的评分达成了一致。
- 数据收集完成后,每个案例由三位评分者中的两位独立进行评分,评分者对分组情况不知情。
- 当评分者意见不一致(预先定义为最终分数相差超过10%时),他们会讨论评估中的差异,并寻求共识。
- 我们计算了加权Cohen's kappa系数,以显示评分的一致性,既包括每个单独案例也包括所有案例的汇总。
Study outcomes
研究结果
Para_01
- 主要研究结果是各组的平均得分。
- 次要结果包括量规预定义领域的得分,包括管理、知识回忆和诊断领域,决策的案例特异性或普遍性以及处理案件所花费的时间。
Para_02
- 作为一次探索性评估,单盲审查员(A.R.)使用与先前发表的评估方法类似的方法对所有回复进行了潜在危害的评分。
- 可能的危害程度被评定为低、中或高;可能的危害范围被评定为无、轻/中度或严重/死亡。
- 这些评分是在个体回复层面上进行的,而不是用于其他分析的案例层面上。
Statistical methods
统计方法
Para_01
- 目标最小样本量为84名参与者是预先规定的,基于使用三个参与者中的13个病例的初步数据进行的功率分析,这些病例在研究注册前评分,相当于预计完成252至336个病例(每个参与者3至4个病例)。
- 这个最小目标样本量确保了主要结果和次要结果(花在病例上的时间)的足够功效(大于80%)。
- 所有分析都在病例层面进行,并根据参与者分组。
- 在主要分析中,我们只包括那些完成了回答的病例,即回答到了最后一个问题。
- 为了考虑潜在的聚类效应,应用了广义混合效应模型来评估LLM组与仅使用传统资源组之间的主要和次要结果差异。
- 模型中包含了参与者的随机效应以考虑同一参与者的不同病例之间可能的相关性。
- 此外,还包含了病例的随机效应以考虑不同病例之间可能存在难度差异。
- 仅由LLM完成的病例被视作第三组,由于对LLM重复提示可以有显著的依赖性,因此这些病例在单个参与者的嵌套结构中分为5次尝试。
- 所有的统计分析都是使用R v.4.3.2(R基金会统计计算)进行的。
- 统计学意义设定为P < 0.05。
Reporting summary
报告摘要
Para_01
- 关于研究设计的更多信息,请参阅本文链接的Nature Portfolio报告摘要。
- ,
Data availability
Para_01
- 案例描述、问题和评分包含在手稿中。所有由研究参与者产生的原始分数均可通过 Figshare 在 https://doi.org/10.6084/m9.figshare.27886788 查看(参考文献 37)。本论文提供了源数据。
- 源数据随本文提供。
Code availability
Para_01
- 当前研究无需定制代码或软件开发。
- ,
Change history
[ul]- 17 February 2025 A Correction to this paper has been published: https://doi.org/10.1038/s41591-025-03586-x
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号