7个最常用的数据分析方法和技巧,收藏!

7个最常用的数据分析方法和技巧,收藏!

派大星的数据屋
发布于 2025-04-05 14:53:09
发布于 2025-04-05 14:53:09
翻译自: Emily Stevens
数据分析是通过分析原始数据提取有意义见解的过程,这一过程包括使用分析和统计工具对数据进行检查、清洗、转换和建模,最终提炼出有价值的信息。
这些信息用于确定业务决策——比如何时推出营销活动最合适?哪些客户群体最可能购买新产品?
但究竟如何将原始数据转化为有用信息?这才是最难的。
下面推荐真实业务场景中最常使用的7种分析模型和方法,非常有帮助。
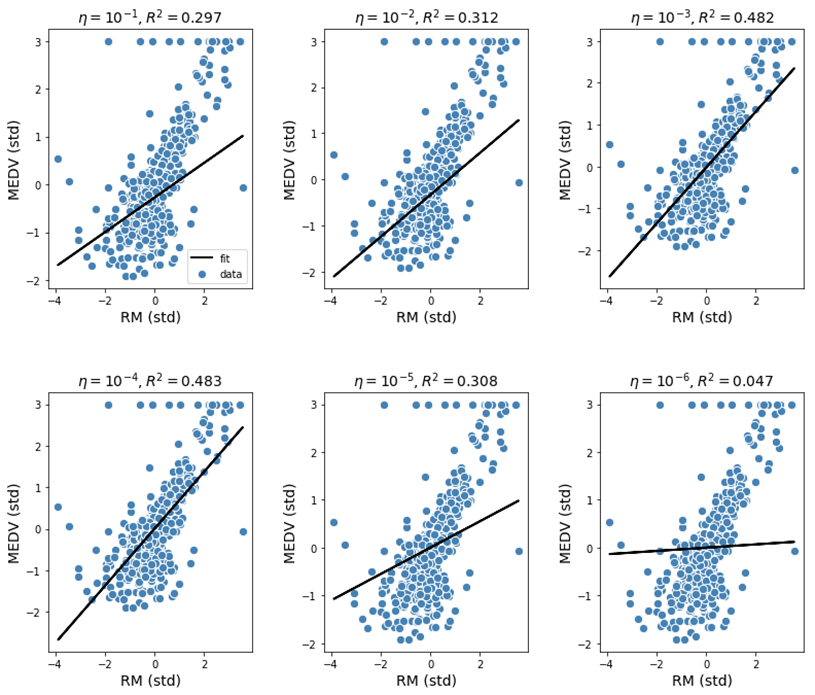
回归分析
回归分析用于估计一组变量之间的关系。
在进行任何类型的回归分析时,你需检验因变量(即需测量或预测的结果变量)与若干自变量(可能影响因变量的因素)之间是否存在相关性。
其核心目标在于评估一个或多个变量如何影响因变量,以识别趋势与规律。这种方法在预测和未来趋势预测中尤为重要。

假设你就职于某电商企业,需研究以下两项的关系:
(1)社交媒体营销投入金额;(2)销售额。
这个业务中,销售额是因变量——即你最关注的指标。
社交媒体支出是自变量——需验证其是否对销售额产生影响。
通过回归分析,可判断二者是否存在关联。若呈现正相关,则表明营销投入增加可能带动销售额增长;若无相关性,则说明社交媒体营销对当前销售无显著影响。此类分析可为预算决策提供依据。
需要注意的是,回归分析仅能揭示变量间的统计关联,无法直接证明因果关系。例如,即使发现社交媒体支出与销售额正相关,仍需结合其他研究方法(如实验设计或时间序列分析)验证其因果性。
回归分析的模型类型取决于因变量数据类型。若因变量为连续型(如以万元计量的销售额),则适用线性回归等模型;若为分类变量(如按省划分的客户地理位置),则需采用逻辑回归等适配方法,具体模型选择需结合数据特征和研究目标。
蒙特卡洛模拟
在决策或行动时,往往存在多种可能的结果。例如选择乘公交可能遭遇堵车,步行则可能淋雨,导致行程延误。日常生活中,你常会快速权衡利弊后作出选择;但面对高风险决策时,你必须尽可能全面、精确地计算所有潜在风险与收益。
蒙特卡洛模拟(又称蒙特卡洛方法)是一种通过计算机模型生成多种可能结果及其概率分布的技术。
其核心在于分析所有潜在结果的范围,并计算每种结果发生的可能性。数据分析师常借此方法进行高级风险预测,以优化决策。
蒙特卡洛模拟的实施通常以数学模型为基础,模型中包含一个或多个目标输出变量(如利润、销售额),以及可能影响输出的输入变量(如营销预算、员工薪资)。
若所有输入值均确定,可直接计算最终利润;但当变量存在不确定性时,蒙特卡洛模拟通过以下步骤实现预测:
- 替代不确定变量:将不确定的输入值替换为随机函数,这些函数根据预设的概率分布(如正态分布、均匀分布)生成样本。
- 多轮迭代计算:通过反复执行多次计算,模拟不同输入组合下的输出结果。
- 结果分析与可视化:汇总所有模拟结果,生成概率分布图或置信区间,量化风险并识别最优策略。
该方法因能有效评估不确定性对目标变量的影响,成为风险分析领域的主流工具。
例如在金融工程中,蒙特卡洛模拟被用于期权定价、投资组合优化及市场波动预测;在供应链管理中,则可评估生产波动、库存风险等复杂场景。
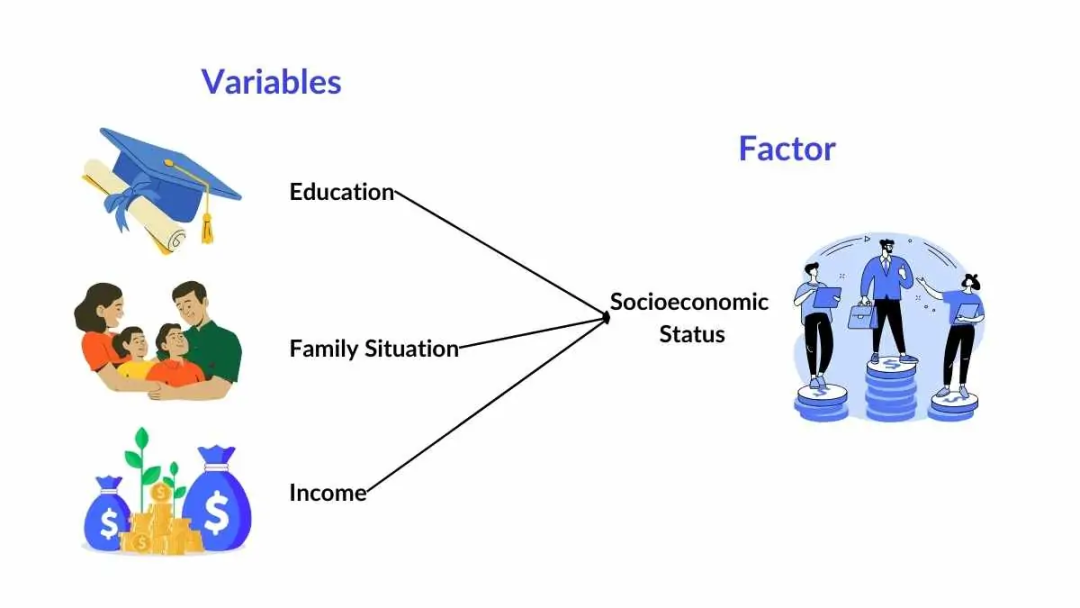
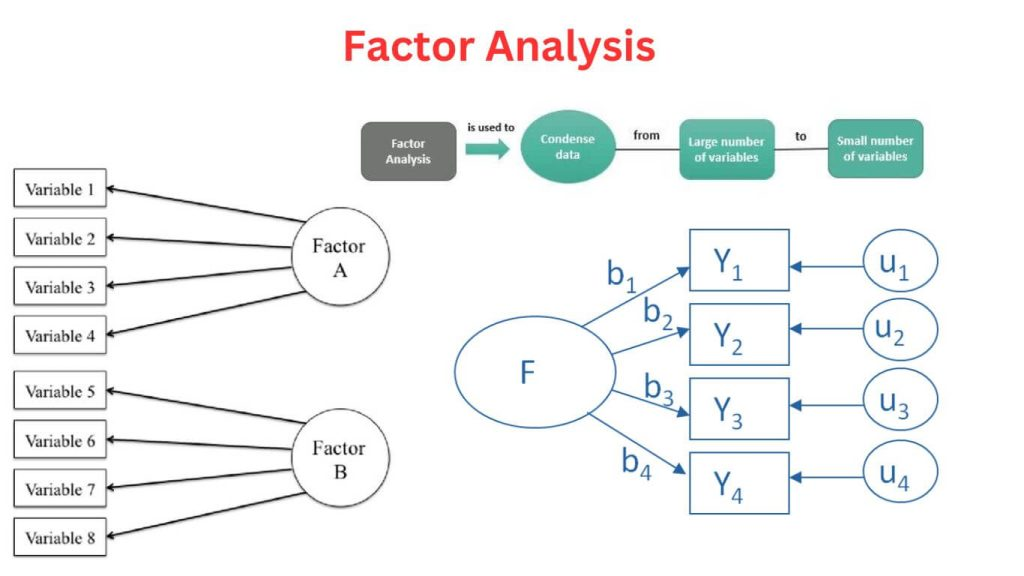
因子分析
因子分析是一种通过合并多个显性变量来提取潜在因子的技术。
其核心逻辑在于:当若干可观测变量存在强相关性时,它们可能受到同一潜在结构的影响。
这种方法不仅能将庞杂的数据集压缩为更易处理的维度,还能揭示数据底层隐藏的规律,尤其适用于量化抽象概念——例如财富水平、幸福感,或商业场景中的客户忠诚度、满意度等难以直接测量的指标。
假设某企业为深度洞察客户特征,发起一项包含100个问题的调研。
问卷内容涵盖两类信息:
态度型问题:如“你会向朋友推荐我们的产品吗?”、“请对整体服务体验评分”; 行为与经济型问题:如“你的家庭年收入是多少?”、“每月愿意为护肤品支付多少预算?”
收集到大量反馈后,数据集将包含每位客户的100项独立变量。
若逐项分析,不仅效率低下,还可能忽略变量间的内在联系。此时通过因子分析,可将高度相关的变量聚类为少数核心因子。
例如:
- 协方差聚类:若家庭年收入与护肤品月预算呈现显著正相关(即收入越高,消费意愿越强),这两项可能被归为“消费能力”因子;
- 态度关联:当客户给出10分满意度评分时,往往更倾向推荐产品,此类关联问题可提炼为“客户满意度”因子。
通过降维处理,原始100个变量可能被简化为5-10个核心因子。这些因子不仅承载了原始数据的关键信息,还能作为后续分析(如市场细分、需求预测)的基础,大幅提升决策效率。
因子分析通过计算变量间的协方差矩阵,识别高度关联的变量簇,并为其赋予因子载荷(反映变量对因子的贡献度)。
最终提取的因子需满足两方面要求:
- 解释力最大化:各因子能覆盖原始变量的大部分信息;
- 独立性:不同因子之间相关性较低,确保分析结果无冗余。
群组分析
群组分析是一种基于用户共有特征(如注册时间、首次购买商品)进行分组的分析技术。
将用户划入特定群组后,可长期追踪其行为轨迹,挖掘生命周期中的趋势与规律。
传统用户分析往往呈现静态快照(如某日所有用户的平均消费金额),但群组分析强调动态视角:
- 生命周期洞察:从用户首次访问网站、加入购物车到完成首单,完整观察行为演变路径;
- 精细化运营:识别不同群组的留存率、复购周期等差异,制定针对性策略。
聚类分析
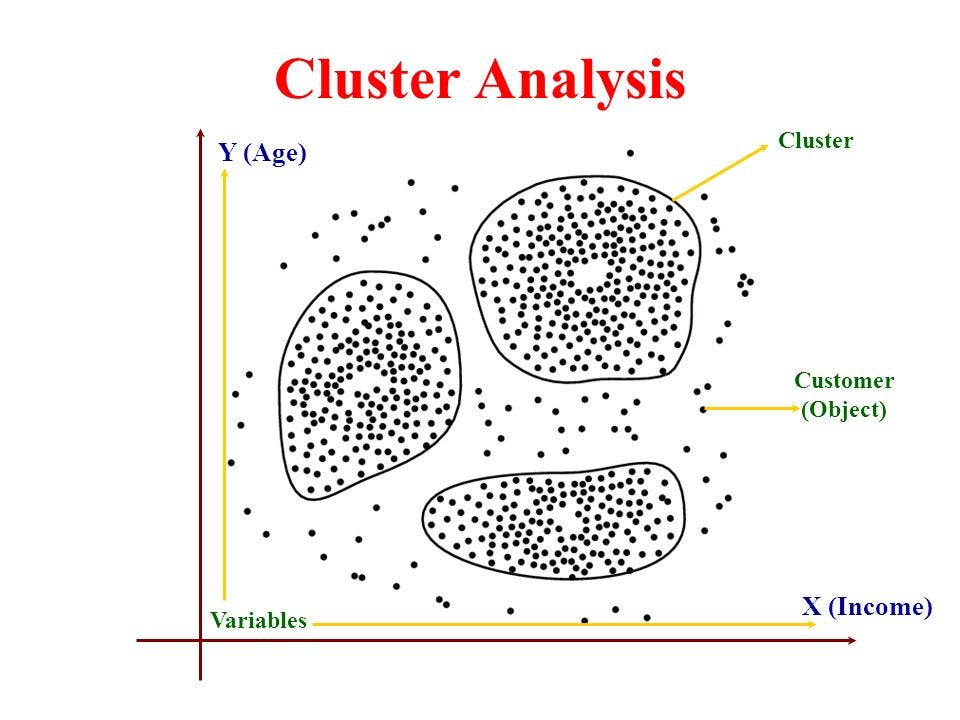
聚类分析是一种探索性分析方法,用于识别数据集中的潜在结构。
其核心目标是将不同数据点划分至若干组别(即"簇"),使组内数据具有高度相似性,而组间数据差异显著。
通过这种"物以类聚"的划分,既能揭示数据分布规律,也可为后续算法(如分类模型)提供预处理基础。
聚类过程遵循两大准则:
- 组内同质化:同一簇中的数据点在特征维度上紧密聚集,如电商用户按消费频次与客单价划分后,"高活跃群体"的月均下单次数均高于10次;
- 组间异质化:不同簇之间特征差异明显,如保险公司的"高风险客户群"与"低风险客户群"在历史理赔次数、居住区域等指标上存在显著区隔。
聚类算法可以根据数据特性选用K均值(数值型数据)、层次聚类(小样本数据)或DBSCAN(噪声数据)等算法。
聚类分析仅能呈现数据结构,无法解释成因。例如某零售集群显示"周末高频购物群体",需结合用户访谈验证是否与双休作息相关。
在机器学习领域,聚类常作为客户分群、异常检测的初始步骤,其结果可输入推荐系统实现"相似用户偏好推送"。
时间序列分析
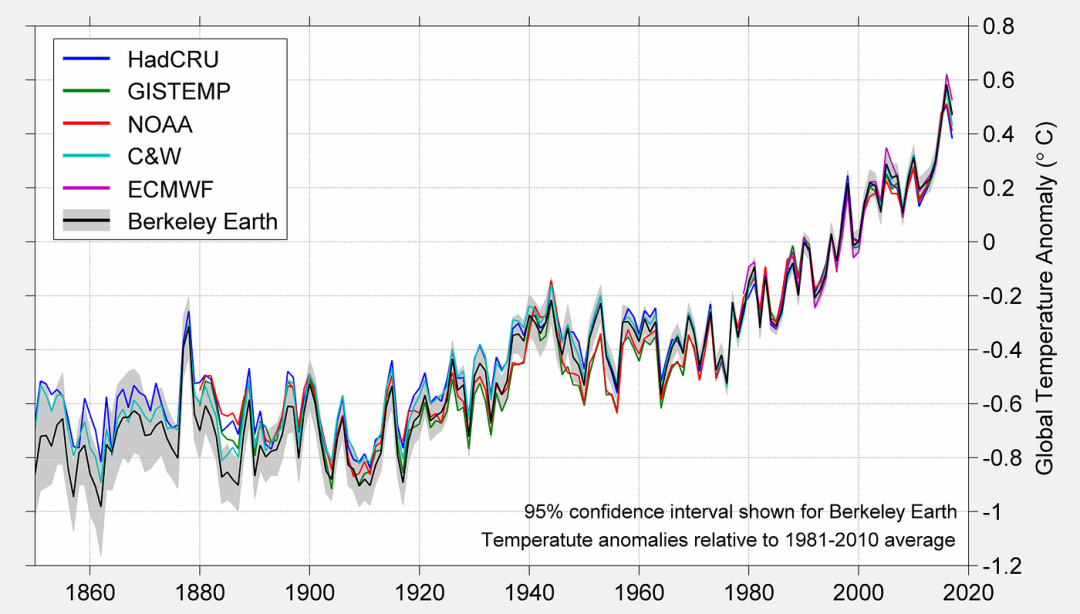
时间序列分析是一种通过统计手段识别数据随时间变化的趋势与周期的技术。
其研究对象是按固定时间间隔采集的序列数据(如周销售额、月度新增用户数),用于通过历史规律预测未来波动。
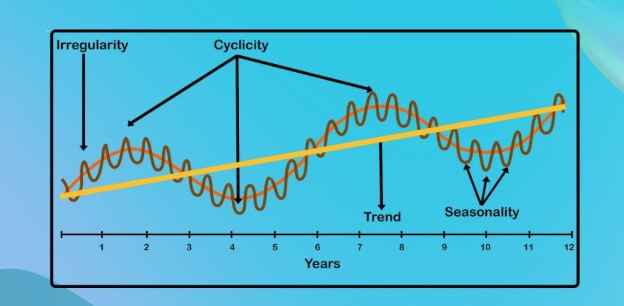
分析过程中需重点关注三类典型模式:
- 趋势:数据在较长时间跨度内呈现的稳定上升或下降走向,如某品牌连续三年客单价每年增长8%;
- 季节性:由固定周期因素引发的规律波动,例如空调销量每年二季度环比激增40%;
- 周期性波动:非固定时段出现的起伏变化,通常与经济周期或行业特性相关,如建材行业需求随房地产政策调整呈现3-5年波动周期。
根据数据类型与预测目标,时间序列模型通常分为三类:
- 自回归(AR)模型:利用变量历史值预测当前值,适用于具有持续惯性的数据; - 差分(I)模型:通过对非平稳序列进行差分处理使其平稳化,常与AR/MA模型结合使用; - 移动平均(MA)模型:基于历史预测误差的加权平均修正未来预测值,擅长捕捉随机干扰。
实践中的高阶建模往往采用三者的组合形式(如ARIMA模型)。
例如在电商大促预测中,ARIMA可通过分解历史销售的季节成分与趋势成分,精准预测营销活动期间的流量峰值与转化率拐点。
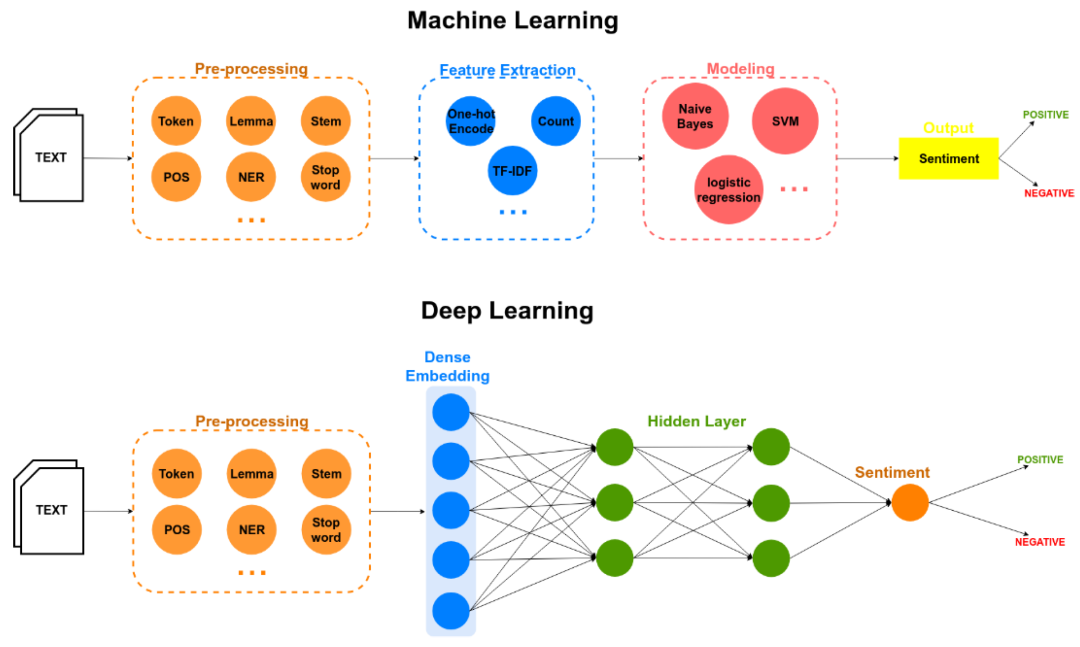
情感分析
多数企业将数据简单等同于数字与表格,往往忽视文本类定性数据的价值。
事实上,客户在评论、社交媒体、客服对话中表达的观点,往往蕴藏着洞察品牌口碑与产品体验的宝贵线索。
如何系统化挖掘这些文本数据?情感分析作为文本分析的核心技术,可通过自动化手段解析文本中的情绪倾向,量化客户对品牌、产品或服务的态度。

情感分析模型主要分为三类,分别对应不同的解析深度:
- 极性判断模型
基础型分析,将文本情绪归类为"正向"、"中性"或"负向"。例如: "这款耳机音质远超预期!" → 正向 "快递配送延迟三天" → 负向
- 细粒度情感分析
在极性判断基础上,进一步识别评价对象与情感强度的对应关系。例如: "降噪功能惊艳(正向),但续航时间不足(负向)" 此类分析可精准定位产品优劣势,常用于竞品对比与功能迭代决策。
- 情感强度建模
通过情感词典与语义分析,量化情绪激烈程度。例如: "客服响应太慢!"(愤怒指数:0.85) "物流速度一般"(不满指数:0.40) 适用于优先处理高危客诉,或评估营销活动的情感共鸣度。
以某美妆品牌为例,情感分析系统发现"持妆效果"的正向评价占比从78%下降至62%,同期竞品该指标稳定在80%以上。
经成分实验室排查,锁定某原料供应商质量波动导致产品脱妆加速,及时更换供应商后负面评价减少34%。
情感分析正逐步与生成式AI结合,实现差评自动归因与定制化回复建议。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号