从数学神经元到硅基文明:人工智能进化史诗

从数学神经元到硅基文明:人工智能进化史诗

AI.NET 极客圈
发布于 2025-03-20 16:59:26
发布于 2025-03-20 16:59:26
开篇:认知边界的坍塌与重建
当GPT-4在律师考试中超越90%人类考生时,我们突然意识到:图灵在1950年提出的"模仿游戏",早已从哲学思辨演变为文明级的技术革命。这场以二进制代码重塑碳基智慧认知体系的征程,正以无法想象的速度改写人类文明的定义边界。
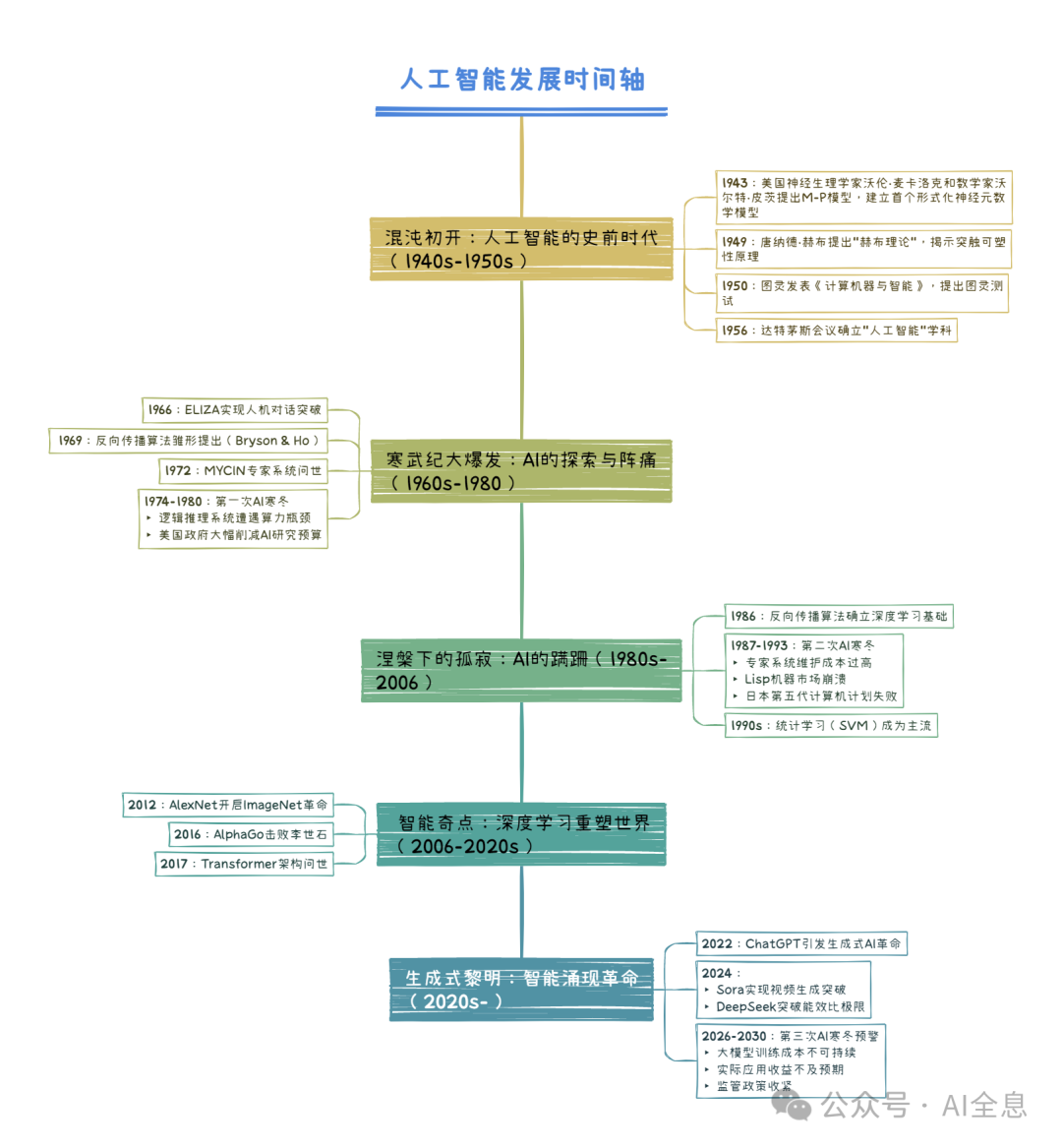
第一章 混沌初开:人工智能的史前时代(1940s-1950s)
1.1 数学神经元的觉醒(1943)
美国神经生理学家沃伦·麦卡洛克(Warren McCulloch)与数学家沃尔特·皮茨(Walter Pitts)在《神经活动中内在思想的逻辑演算》中,用命题逻辑构建了首个形式神经元模型(M-P模型)。这个仅有两页的奠基性论文证明:由阈值逻辑单元构成的网络,可以执行任何逻辑运算。这如同神经科学界的"DNA双螺旋时刻",为后来神经网络奠定了数学基础。
这项被后世称为M-P模型的突破,首次证明思维过程可被数学公式解构,如同用E=mc²揭示宇宙本质。
1.2 学习法则的生物学启示(1949)
加拿大心理学家唐纳德·赫布(Donald O. Hebb)在其著作《行为的组织》中提出划时代的赫布理论:"当神经元A反复参与激发神经元B时,两者间的连接效率将增强"。
这个被称为"一起激活的神经元会连接在一起"(Cells that fire together, wire together)的突触可塑性原理,60年后成为深度学习算法的生物学蓝本。
1.3 智能判定的终极之问(1950)
艾伦·图灵在论文中设计的"模仿游戏",用30%的欺骗概率定义机器智能。这个充满英式幽默的测试标准,至今仍在挑战人类的认知优越感——当GPT-4通过图灵测试的比例达到 67.3% (2023斯坦福报告),我们不得不重新审视"思考"的本质。
1.4 学科诞生的创世时刻(1956)
达特茅斯会议上,约翰·麦卡锡提出"人工智能"概念,明斯基现场演示M-P模型的模式识别能力。这场汇集数学、神经科学、计算机科学的跨界对话,标志着人类首次系统性地向造物主角色发起冲击。
标志性突破 1957年:弗兰克·罗森布拉特发明感知机,首个可自主调整权重的神经网络 1966年:MIT开发出ELIZA,史上第一个聊天机器人 1972年:斯坦福推出MYCIN医疗诊断系统,准确率达69%(高于人类医生平均水平)
第二章 寒武纪大爆发:AI的探索与阵痛(1960s-1980s)
2.1 机器对话的黎明(1966)
约瑟夫·维森鲍姆在MIT实验室创造出ELIZA——史上首个能模拟心理医生的自然语言程序。其核心算法仅用200行代码实现模式匹配:
# ELIZA经典关键词响应逻辑示例 Python
if "母亲" in input:
return "多谈谈你的家庭"
elif "悲伤" in input:
return "这种感觉持续多久了?"尽管技术简陋,但实验中85% 的用户坚信屏幕背后是人类咨询师,这个"ELIZA效应"揭示了人类对AI的情感投射本能。
2.2 学习之钥的锻造(1969)
亚瑟·布莱森(Arthur Bryson)与何毓琦(Yu-Chi Ho)在《应用最优控制》中提出反向传播算法雏形,首次将微积分链式法则引入网络训练。这个当时被标注为"理论特例"的方法,直到1986年才由鲁梅尔哈特团队实现实用化,成为深度学习革命的数学引擎。
算法突破点: ▌ 误差从输出层反向传递至输入层 ▌ 权重调整量=学习率×局部梯度×输入信号
2.3 专家系统的破晓(1972)
斯坦福大学研发的MYCIN医疗诊断系统,采用500条规则判断血液感染病原体:
(defrule bacterial-sepsis
(patient-temperature > 38.5)
(white-blood-cell-count < 4000)
=>
(assert (likely-pathogen pseudomonas-aeruginosa)))在盲测中取得69%准确率(人类专家平均65%),证明AI可超越直觉经验。但其知识固化缺陷也预示了第一次AI寒冬的来临。
2.4 第一次寒冬(1974-1980):理想主义的溃败
当早期乐观预期未能实现,马文·明斯基在《感知机》著作中指出神经网络的致命缺陷,加之政府资金断崖式削减,AI研究陷入长达6年的冰封期。
政府资助锐减,美国国防部报告直言:"我们投资的是会下棋的猴子,而不是战场指挥官"。
第三章 涅槃下的孤寂:AI的蹒跚(1980s-2006)
3.1 坚硬的磐石
1986年,反向传播算法(Backpropagation)被广泛应用,成为神经网络训练中的关键技术。通过这一算法,神经网络能够有效地调整权重,从而提升模型的准确性与效率。这一突破极大推动了神经网络的研究与发展,并为后来的深度学习技术奠定了基础。
3.2 第二次寒冬(1987-1993):专家系统的黄昏
导火索:1987年LISP机器市场崩盘,AI硬件厂商全军覆没。
致命伤:
- 专家系统维护成本高达30万/年(相当于2023年的30万/年(相当于2023年的75万)
- 日本第五代计算机计划耗资$8.5亿却未达预期
1990年:DARPA终止语音识别项目资助:"我们需要的不是实验室玩具,而是能实战的系统"
意外收获 日本启动第五代计算机计划,投入8.5亿美元研发智能计算机。虽然最终失败,却催生了DENDRAL(化学分析系统)、XCON(计算机配置系统)等专家系统,IBM的Deep Blue更在1997年击败国际象棋世界冠军卡斯帕罗夫,即便仅限于封闭规则系统。
3.3 寒冬的持续(2000s):黎明前的黑暗
- 2000年互联网泡沫破裂波及AI领域
- 语音识别错误率长期卡在30%瓶颈
寒冬启示录 ▌投资人教训:任何不能处理现实噪声的技术都是空中楼阁 ▌学者共识:AI需要从"规则编码"转向"自主演化"
第四章 智能奇点:深度学习重塑世界(2006-2020s)
4.1 ImageNet时刻:量变引发质变
2009年,李飞飞团队发布包含1400万标注图片的ImageNet数据集。2012年,AlexNet以16.4%的错误率碾压传统算法(第二名26.2%),标志着深度学习统治计算机视觉领域。
4.2 里程碑之战:人机终极对决
2016年3月,DeepMind的AlphaGo以4:1战胜围棋冠军李世石。这场世纪对决中,AI展示了直觉创造力——第37步"天外飞仙"让解说惊呼:"这不像人类的棋!"
4.3 三驾马车驱动复兴
✅ 算力突破:NVIDIA Tesla GPU算力达1 TFLOPS(2008年) ✅ 数据革命:ImageNet数据集规模超人脑视觉训练量1000倍 ✅ 算法创新:ReLU激活函数使训练速度提升6倍
4.4 改变世界的四年
2014年:GAN生成对抗网络诞生,AI获得"想象力" 2015年:ResNet将图像识别错误率降至3.57%(超越人类) 2016年:AlphaGo的蒙特卡洛树搜索评估600万局面/秒 2017年:Google提出Transformer架构,为自然语言处理(NLP)奠定新范式
技术突破三要素: ✅ 海量数据(互联网时代数据大爆炸) ✅ 算力飞跃(GPU算力十年提升1000倍) ✅ 算法创新(GAN、Transformer等架构涌现)
第五章 生成式黎明:智能涌现革命(2020-至今)
5.1 2020:参数暴力美学
GPT-3和GPT-4分别以1750亿参数和1.8万亿参数(推测),重塑行业认知: ✅ 少样本学习:仅用任务描述即可生成Python代码 ✅ 成本代价:GPT-4单次训练耗电2.4GWh(相当于约1.7万个家庭的用电量) ◼️ 技术遗产:揭示"规模定律"(Scaling Law)——性能 = c × (模型大小)^a
5.2 2021:视觉创造觉醒
DALL-E用120亿参数打通文图界限:
# 其核心的CLIP跨模态对齐机制
text_embed = transformer_encode("畅享宇宙")
image_embed = vision_transformer(生成图)
loss = cosine_similarity(text_embed, image_embed)5.3 2022:对话智能奇点
ChatGPT以5天破百万用户刷新技术扩散纪录: ▌ 模型本质:基于人类反馈的强化学习(RLHF) ▌ 产业冲击波:
- 客服行业人力成本下降40%(印度BPO行业报告)
- Stack Overflow访问量锐减35%(2023Q1数据)
5.4 2023:多模态数字巴别塔
GPT-4通过美国律师考试(成绩前10%),其核心突破在于: 🔥 混合专家架构(MoE):激活参数仅占总量22% 🔥 视觉理解:可解析4万像素图像中的显微癌细胞 ◼️ 能效革命:相同性能下能耗比GPT-3降低
5.5 2024:低成本智能元年
① Sora物理引擎 实现1080P视频生成中流体动力学模拟误差<3% 好莱坞特效公司裁员潮:环球影业数字部门缩减
② Claude 3语境革命 支持100万token上下文(相当于《战争与和平》全文) 法律文档分析错误率仅0.9%(vs 人类律师平均2.7%)
③ DeepSeek演绎AI界的哪吒脑海 动态稀疏架构实现突破: ✅ 训练成本:$550万(GPT-4的十几分之一) ✅ 硬件需求:多块RTX 4090运行满血版DeepSeek(清华大学KTransformers方案) ✅ 超低功耗与微型化:为人人都拥有私域AI提供了无限想象力
④行业替代率进度条
- 客服岗位:▉▉▉▉▉▉▉▉▉ 40%
- 平面设计:▉▉▉▉▉ 25%
- 代码编写:▉▉▉▉▉▉▉ 35%
- ……
第六章 硅基文明:未来十年演进图谱
6.1 技术奇点临近
- 脑机接口:Neuralink通过侵入式的穿戴设备实现了意念打字
- 量子AI:谷歌Sycamore完成传统超算需万年处理的计算
- 自进化系统:Anthropic的Constitutional AI实现道德准则自主迭代
6.2 2030社会图景
时间轴 | 智能革命印记 |
|---|---|
07:00 | 睡眠优化AI同步昼夜节律与日程安排 |
09:30 | 数字孪生城市预判交通拥堵点 |
15:00 | AI律师完成跨国并购协议智能审核 |
21:00 | 神经编织技术实现梦境可视化 |
6.3 文明级挑战
- 能源悬崖:全球AI耗电量将在2027年超过意大利全国用电
- 认知污染:深度伪造导致大量虚假信息
- 伦理困境:自动驾驶道德算法在电车难题中展现文化偏见
当我们在GPT-4的代码生成中看到数学之美,在蛋白质折叠预测中窥见生命奥秘,这场智能革命早已超越工具进化,成为文明演化的新范式。或许正如凯文·凯利所言:"最像人类的AI,终将教会我们如何成为更好的人类。"
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号