单个4090就能跑,Mistral开源多模态小模型,开发者:用来构建推理模型足够香

单个4090就能跑,Mistral开源多模态小模型,开发者:用来构建推理模型足够香

机器之心
发布于 2025-03-18 19:48:25
发布于 2025-03-18 19:48:25
机器之心报道
编辑:张倩
多模态,性能超 GPT-4o Mini、Gemma 3,还能在单个 RTX 4090 上运行,这个小模型值得一试。
小模型正在变得越来越好,而且越来越便宜。
刚刚,法国 AI 创企 Mistral AI 开源了一个 24B 的多模态小模型,该模型在多个基准上击败了 Gemma 3 和 GPT-4o Mini 等同类模型,而且推理速度达到了 150 个 token / 秒,称得上是又好又快。
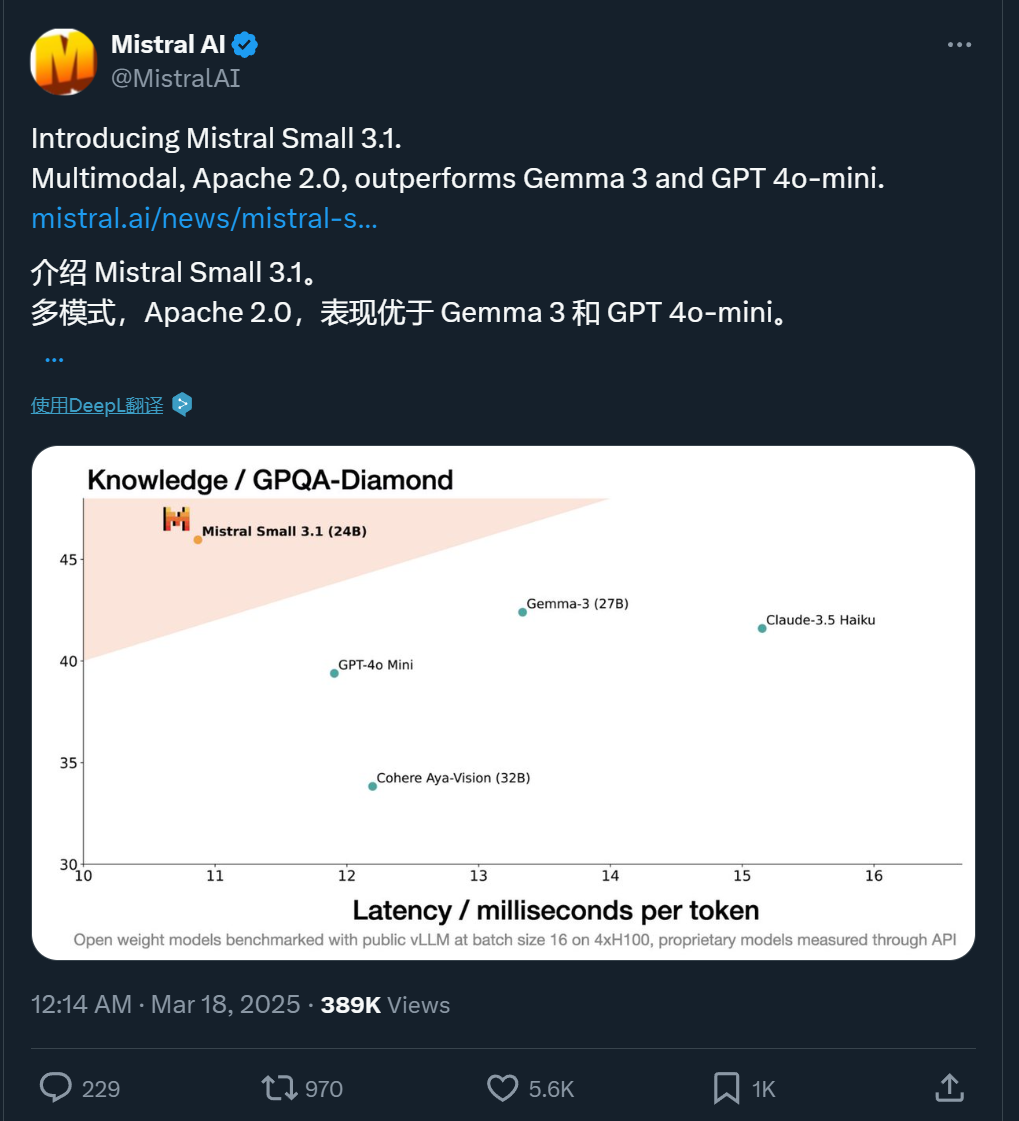
重要的是,它只需要一个 RTX 4090 或 32GB RAM 的 Mac 就能运行,而且开源协议是 Apache 2.0,因此既能用于研究,也能商用。
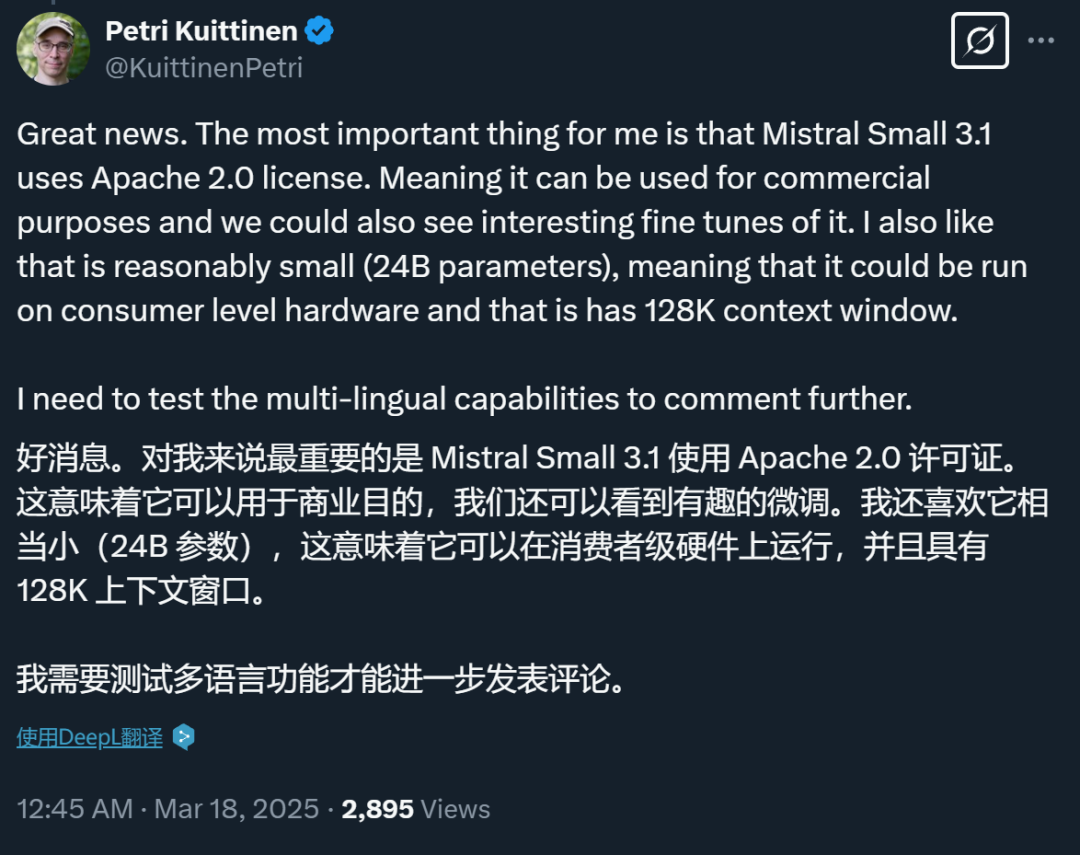
具体来说,Mistral Small 3.1 是基于 Mistral Small 3 构建的。与 Mistral Small 3 相比,它的上下文窗口更大,达到了 128k(Mistral Small 3 仅为 32k),文本生成能力得到了改进,还新增了视觉能力。
Mistral 官方表示,Mistral Small 3.1 是一款多功能模型,旨在处理各种生成式 AI 任务,包括指令遵循、对话辅助、图像理解和函数调用。它为企业级和消费级 AI 应用提供了坚实的基础。
目前,部分开发者已经在自己的设备上完成了部署,并晒出了体验效果:


Mistral Small 3.1 可在 huggingface 网站 Mistral Small 3.1 Base 和 Mistral Small 3.1 Instruct 上下载。
- Mistral Small 3.1 Base:https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503
- Mistral Small 3.1 Instruct:https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Instruct-2503
以下是该模型的详细信息。
核心特性
Mistral Small 3.1 具有以下特点:
- 轻量级:可以在单个 RTX 4090 或具有 32GB RAM 的 Mac 上运行。这使其非常适合端侧使用情况。
- 快速响应能力:非常适合虚拟助手和其他需要快速、准确响应的应用程序。
- 低延迟函数调用:能够在自动化或智能体工作流中快速执行函数。
- 针对专业领域进行微调:Mistral Small 3.1 可以针对特定领域进行微调,打造精准的主题专家。这在法律咨询、医疗诊断和技术支持等领域尤其有用。
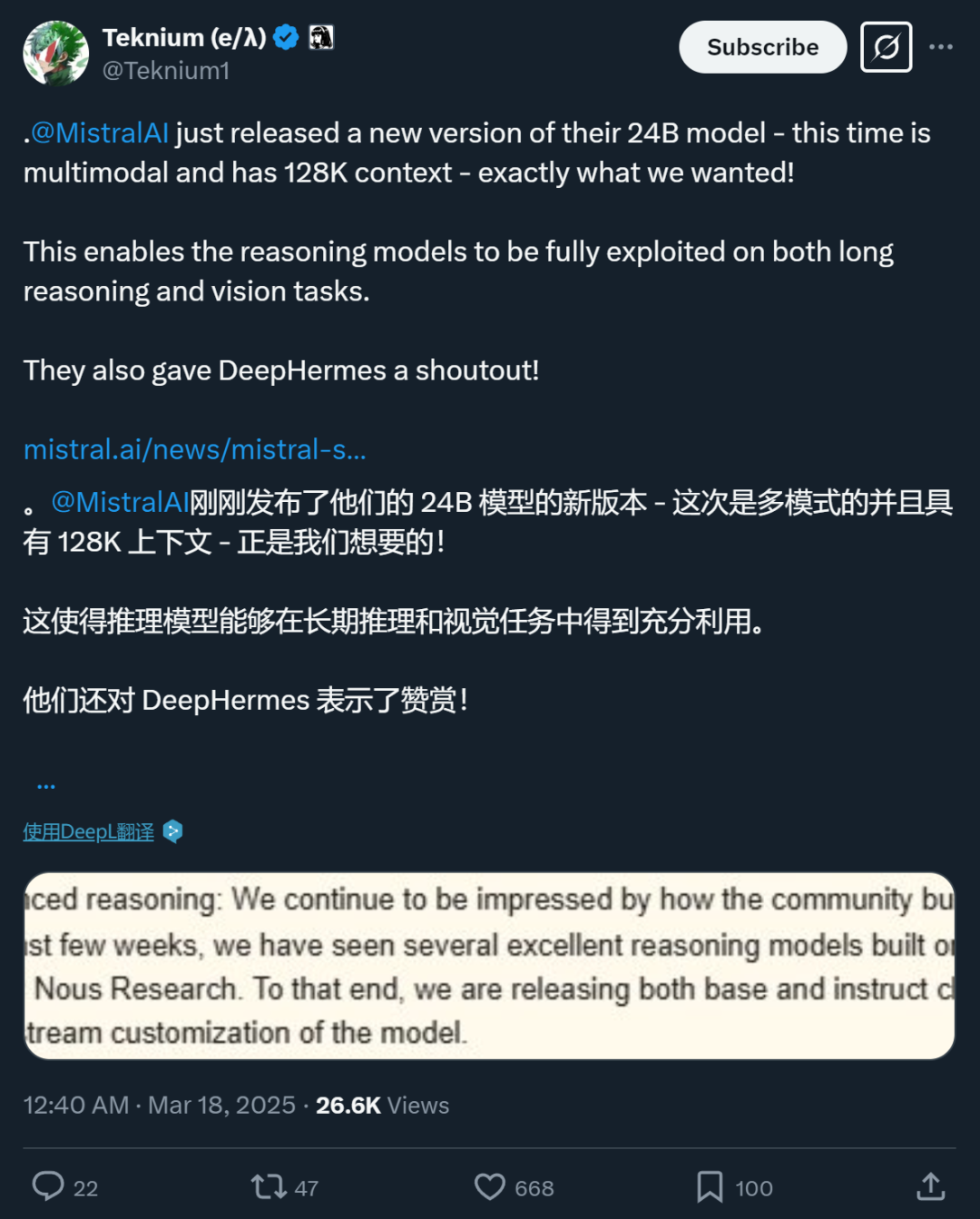
- 高级推理的基础:开放的 Mistral 模型已经被开发者用来构建出色的推理模型,比如 Nous Research 的 DeepHermes 24B 就是基于 Mistral Small 3 构建出来的。为了鼓励这种创新,Mistral AI 发布了 Mistral Small 3.1 的基础模型和指令检查点,以便社区进一步对模型进行下游定制。
Mistral Small 3.1 可用于需要多模态理解的各种 B 端和 C 端应用程序,例如文档验证、诊断、端侧图像处理、质量检查的视觉检查、安全系统中的物体检测、基于图像的客户支持和通用协助。
性能展示
以下是 Mistral Small 3.1 在文本、多模态、多语言、长上下文等场景中的性能表现情况。
文本指令基准
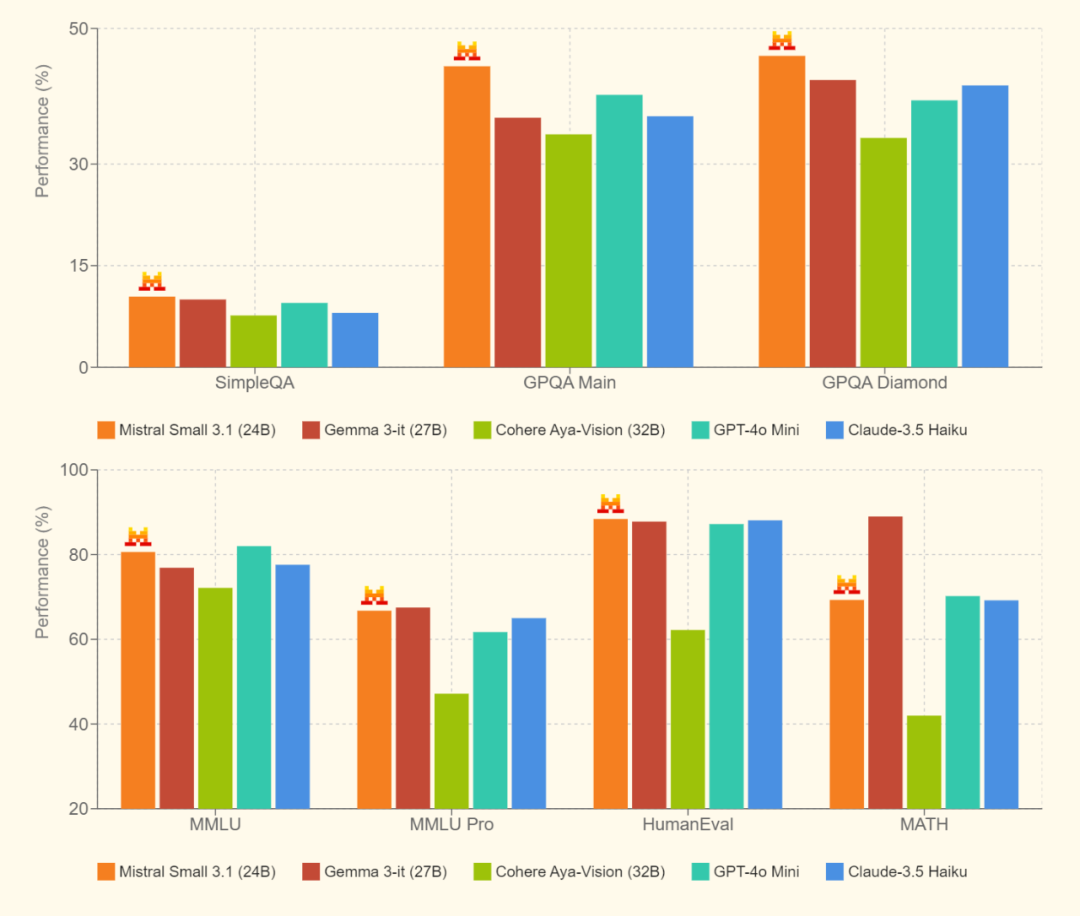
多模态指令基准
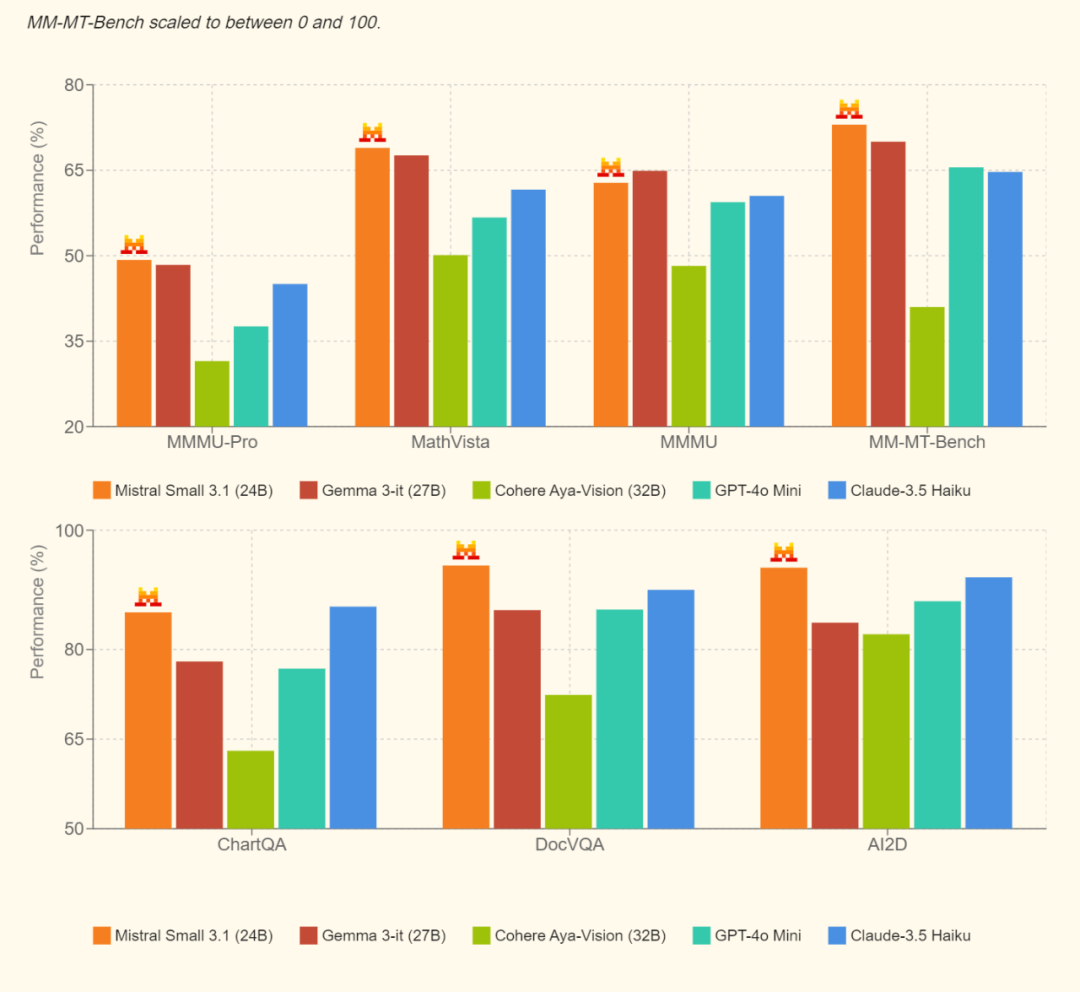
多语言指令基准
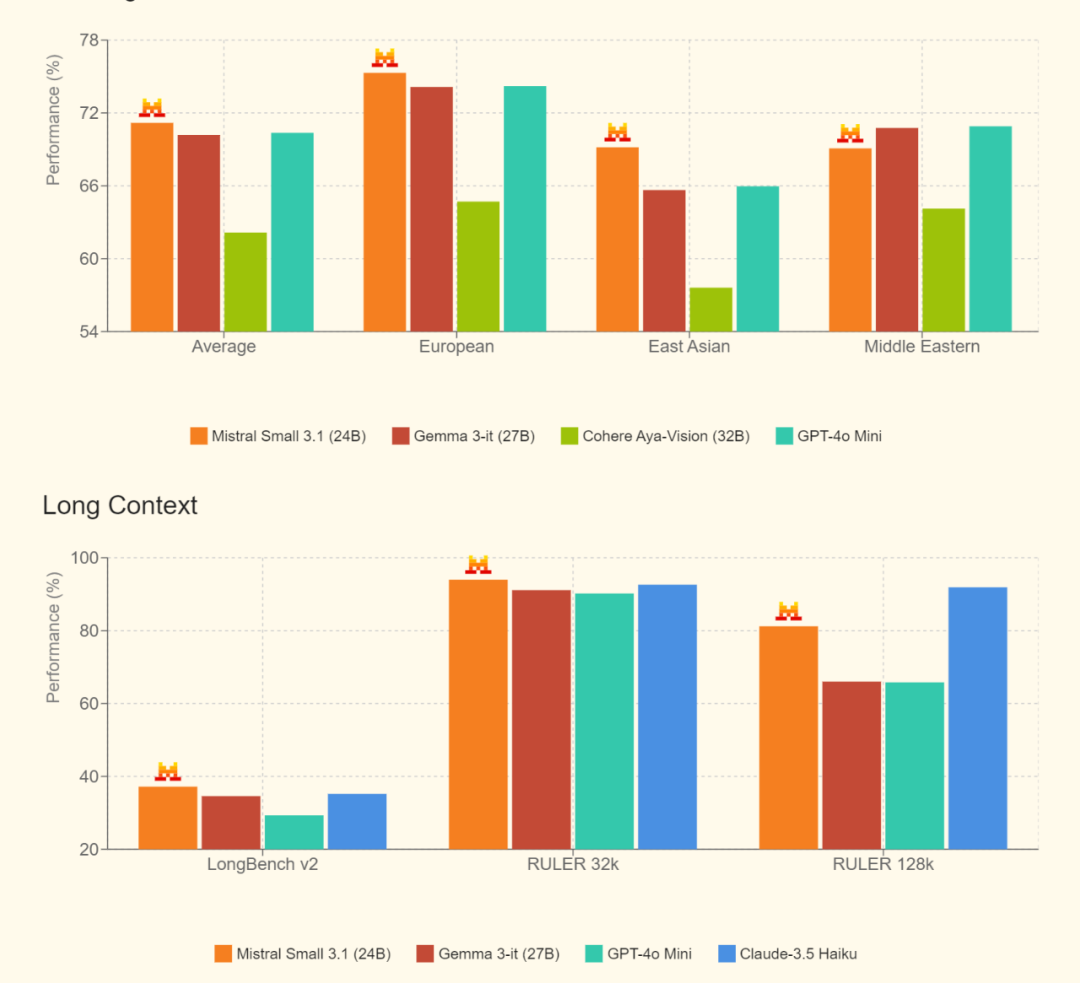
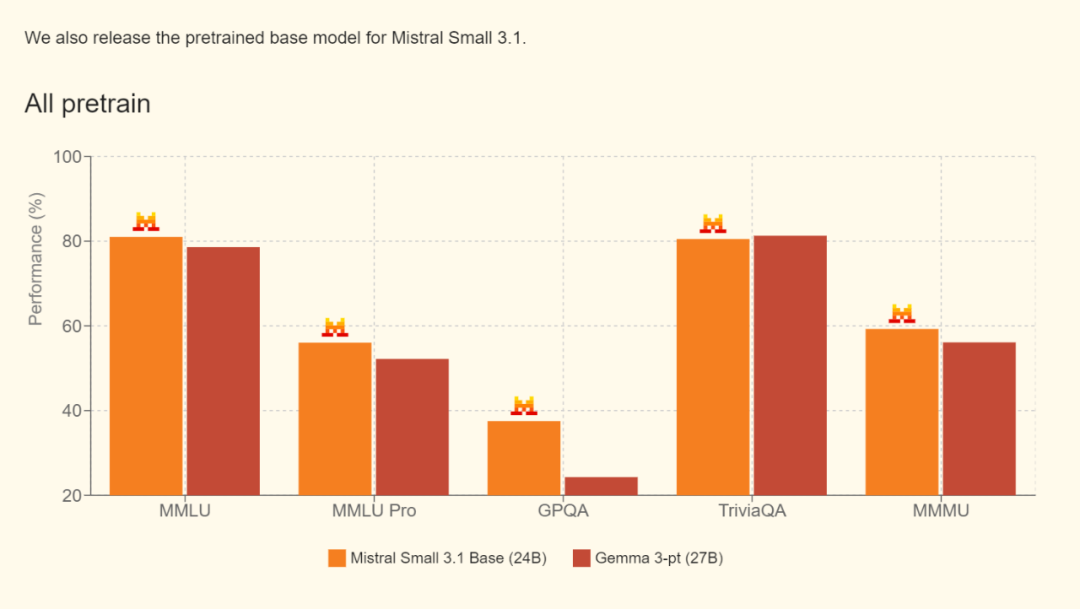
预训练性能
参考链接:https://mistral.ai/news/mistral-small-3-1
© THE END
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号