【深度学习基础】线性神经网络 | 线性回归的从零开始实现

【深度学习基础】线性神经网络 | 线性回归的从零开始实现

Francek Chen
发布于 2025-01-22 21:55:05
发布于 2025-01-22 21:55:05
- 计算梯度
- 更新参数 在每个迭代周期(epoch)中,我们使用data_iter函数遍历整个数据集,并将训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。这里的迭代周期个数num_epochs和学习率lr都是超参数,分别设为3和0.03。设置超参数很棘手,需要通过反复试验进行调整。我们现在忽略这些细节,以后会在优化算法中详细介绍。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_lossfor epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')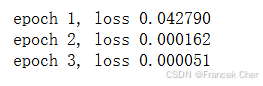
因为我们使用的是自己合成的数据集,所以我们知道真正的参数是什么。因此,我们可以通过比较真实参数和通过训练学到的参数来评估训练的成功程度。事实上,真实参数和通过训练学到的参数确实非常接近。
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')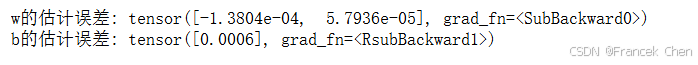
注意,我们不应该想当然地认为我们能够完美地求解参数。在机器学习中,我们通常不太关心恢复真正的参数,而更关心如何高度准确预测参数。幸运的是,即使是在复杂的优化问题上,随机梯度下降通常也能找到非常好的解。其中一个原因是,在深度网络中存在许多参数组合能够实现高度精确的预测。
小结
- 我们学习了深度网络是如何实现和优化的。在这一过程中只使用张量和自动微分,不需要定义层或复杂的优化器。
- 这一节只触及到了表面知识。在下面的部分中,我们将基于刚刚介绍的概念描述其他模型,并学习如何更简洁地实现其他模型。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-01-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号