【C++】B2110 找第一个只出现一次的字符


💯前言
- 在编程中,处理字符串是一个非常常见的任务,其中字符统计类问题经常会出现在各种编程竞赛和实际开发中。本篇文章将围绕一道典型的题目展开,从题目要求、不同实现方法的比较与优化,再到拓展内容,帮助读者深入理解相关问题的解决方案与技术实现。 C++ 参考手册
💯题目描述
题目要求如下:
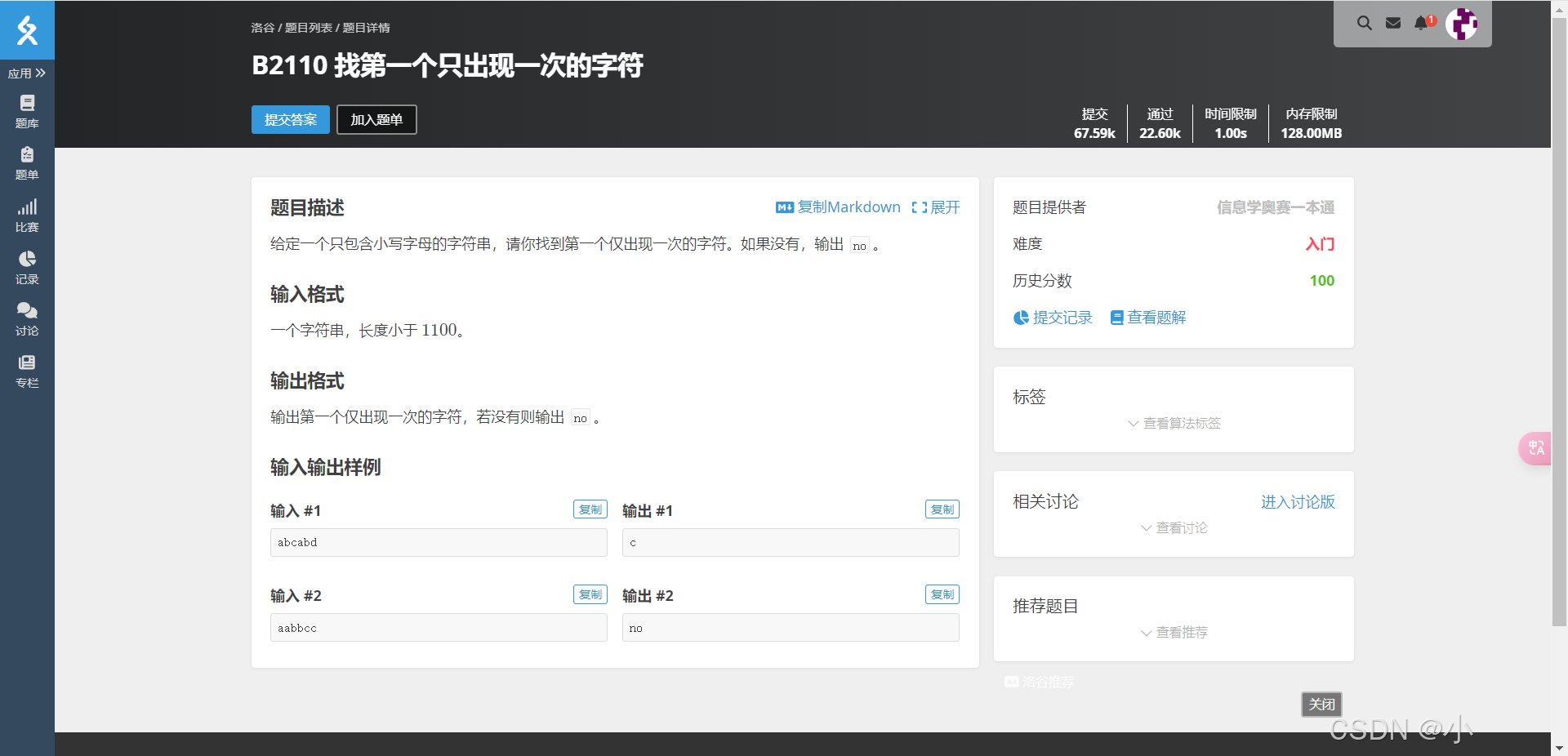
B2110 找第一个只出现一次的字符
给定一个只包含小写字母的字符串,请你找到第一个仅出现一次的字符。如果没有,输出 no。
输入格式
一个字符串,长度小于 1100。
输出格式
输出第一个仅出现一次的字符,若没有则输出 no。
示例
输入样例 1:
abcabd输出样例 1:
c输入样例 2:
aabbcc输出样例 2:
no💯解题思路
解决该问题的关键在于如何高效统计每个字符的出现次数,然后按照字符串的顺序找到第一个仅出现一次的字符。以下,我们将从不同实现方法出发,分析其优缺点,并给出优化方案。
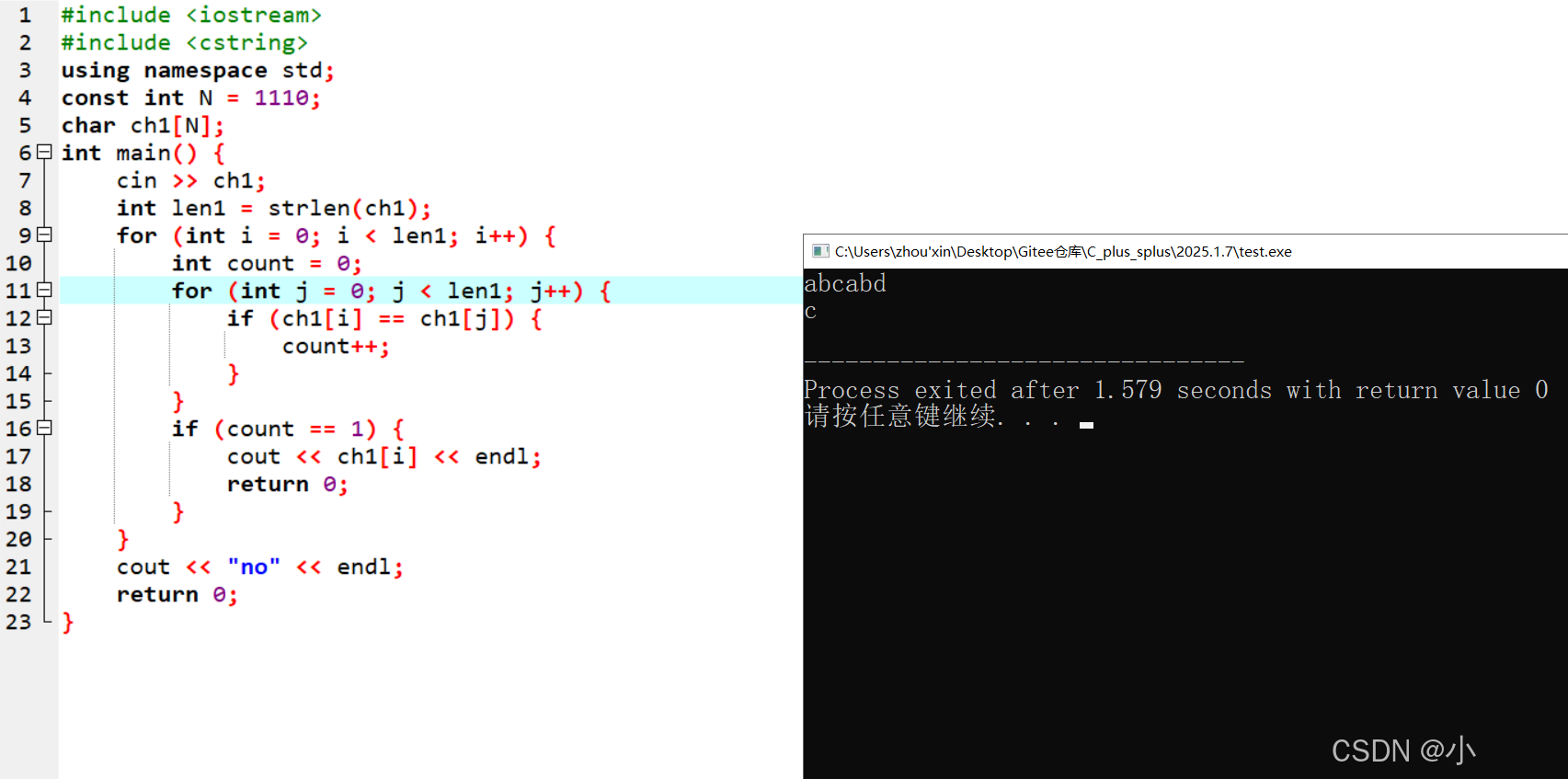
💯我的方法一:双重循环实现字符统计
代码实现
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1110;
char ch1[N];
char ch2[N];
int main()
{
cin >> ch1;
int len1 = strlen(ch1);
int i = 0;
int j = 0;
for(i = 0; i < len1; i++)
{
int count = 0;
for(j = 0; j < len1; j++)
{
if(ch1[i] == ch1[j])
{
count++;
}
}
ch2[i] = count;
}
int len2 = strlen(ch2);
for(i = 0; i < len2; i++)
{
if(ch2[i] == 1)
{
cout << ch1[i] << endl;
break;
}
if(i == len2 - 1)
{
cout << "no" << endl;
}
}
return 0;
} 
代码逻辑
- 遍历字符串的每个字符
ch1[i],通过内层循环统计其出现次数。 - 如果某个字符的统计次数为 1,则输出并结束程序。
- 如果遍历结束后没有符合条件的字符,输出
"no"。
优缺点
优点
- 直观简单:逻辑清晰,便于理解。
缺点
- 效率低下:时间复杂度为
,不适合处理大规模输入。
💯我的方法二:优化版双重循环
代码实现
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1110;
char ch1[N];
int main()
{
cin >> ch1;
int len1 = strlen(ch1);
int i = 0;
int j = 0;
for(i = 0; i < len1; i++)
{
int count = 0;
for(j = 0; j < len1; j++)
{
if(ch1[i] == ch1[j])
{
count++;
}
}
if(count == 1)
{
cout << ch1[i] << endl;
break;
}
if(i == len1 - 1)
{
cout << "no" << endl;
}
}
return 0;
} 优化点
- 在第一次遍历时,提前将字符的出现次数存储在
ch2中,避免重复统计。 - 第二次遍历中直接利用统计结果进行判断。
优缺点
优点
- 逻辑改进:分离统计与判断步骤,代码更具可读性。
缺点
- 效率问题仍然存在:本质上仍是双重循环,时间复杂度未优化。
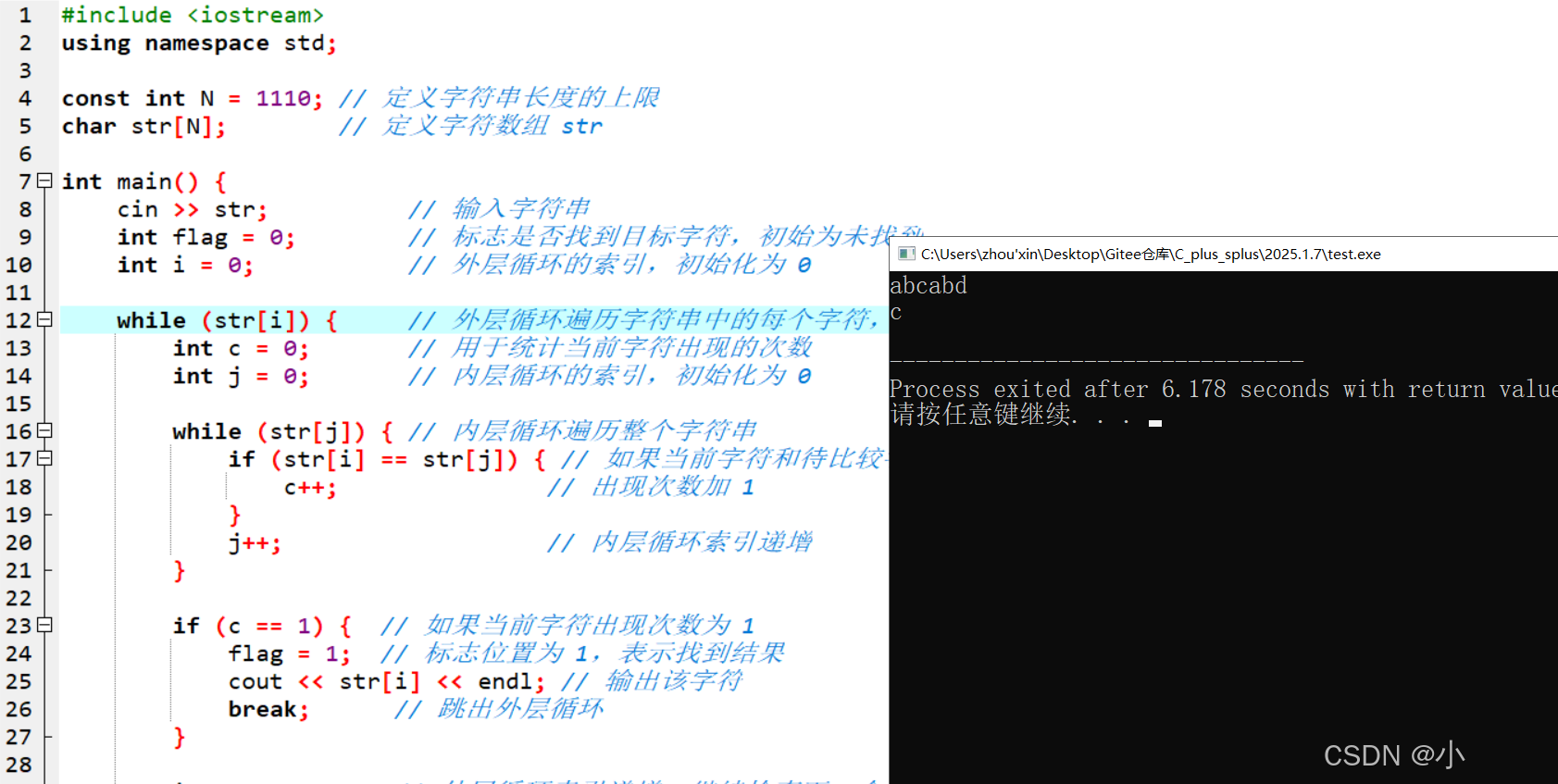
💯老师的方法一:暴力统计法
代码实现
#include <iostream>
using namespace std;
const int N = 1110; // 定义字符串长度的上限
char str[N]; // 定义字符数组 str
int main() {
cin >> str; // 输入字符串
int flag = 0; // 标志是否找到目标字符,初始为未找到
int i = 0; // 外层循环的索引,初始化为 0
while (str[i]) { // 外层循环遍历字符串中的每个字符,直到遇到字符串末尾 '\0'
int c = 0; // 用于统计当前字符出现的次数
int j = 0; // 内层循环的索引,初始化为 0
while (str[j]) { // 内层循环遍历整个字符串
if (str[i] == str[j]) { // 如果当前字符和待比较字符相同
c++; // 出现次数加 1
}
j++; // 内层循环索引递增
}
if (c == 1) { // 如果当前字符出现次数为 1
flag = 1; // 标志位置为 1,表示找到结果
cout << str[i] << endl; // 输出该字符
break; // 跳出外层循环
}
i++; // 外层循环索引递增,继续检查下一个字符
}
if (flag == 0) { // 如果标志仍然为 0,说明没有找到任何只出现一次的字符
cout << "no" << endl; // 输出 "no"
}
return 0; // 返回 0,程序结束
}
优缺点
优点
- 逻辑直观,容易实现。
缺点
- 双重循环导致时间复杂度高,效率较低。
💯老师的方法二:基于 ASCII 的哈希表优化
代码实现
#include <iostream>
using namespace std;
const int N = 1110; // 定义字符串长度的上限
char str[N]; // 定义字符数组 str,用于存储输入字符串
int nums[128] = {0}; // 用于统计字符出现次数的数组,大小为 128
int main() {
int ch = 0; // 用于读取字符
int i = 0; // 字符串索引初始化为 0
// 统计字符出现次数
while ((str[i] = getchar()) != '\n') { // 逐个读取字符,直到遇到换行符结束
nums[str[i]]++; // 利用字符的 ASCII 值作为下标,更新字符出现次数
i++;
}
i = 0; // 索引重置为 0,准备再次遍历字符串
int flag = 0; // 标志是否找到只出现一次的字符,初始为 0
// 遍历字符串,找到第一个只出现一次的字符
while (str[i]) { // 遍历字符串直到末尾(遇到 `\0`)
if (nums[str[i]] == 1) { // 如果该字符的出现次数为 1
cout << str[i] << endl; // 输出该字符
flag = 1; // 标志位置为 1,表示找到结果
break; // 跳出循环
}
i++; // 继续检查下一个字符
}
// 如果没有找到任何只出现一次的字符
if (flag == 0) {
cout << "no" << endl; // 输出 "no"
}
return 0; // 程序结束
}
优化点
- 使用
nums[128]数组记录每个字符的出现次数。 - 两次线性遍历分别统计字符出现次数与查找结果,时间复杂度降低至
。
💯对比与优化建议
方法 | 时间复杂度 | 空间复杂度 | 优点 | 缺点 |
|---|---|---|---|---|
我的方法一 | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 逻辑简单,代码直观 | 效率低下,不适合大规模输入 |
我的方法二 | O ( n 2 ) O(n^2) O(n2) | O ( n ) O(n) O(n) | 分离统计与判断逻辑,稍有改进 | 依然存在效率问题 |
老师的方法一 | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 易于理解,适合初学者 | 嵌套循环效率低 |
老师的方法二 | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | 高效,适合长字符串处理 | 仅适用于 ASCII 字符,扩展性较弱 |
逻辑简单,代码直观效率低下,不适合大规模输入我的方法二
分离统计与判断逻辑,稍有改进依然存在效率问题老师的方法一
易于理解,适合初学者嵌套循环效率低老师的方法二
高效,适合长字符串处理仅适用于 ASCII 字符,扩展性较弱
💯拓展与延伸
拓展:支持 Unicode 字符
如果需要支持 Unicode 字符(如中文或其他多字节字符),可以采用 C++ 中的 unordered_map 替代固定大小的数组。示例如下:
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
int main() {
string str;
cin >> str;
unordered_map<char, int> freq; // 使用哈希表统计字符频率
// 统计每个字符的出现次数
for (char c : str) {
freq[c]++;
}
// 找到第一个只出现一次的字符
for (char c : str) {
if (freq[c] == 1) {
cout << c << endl;
return 0;
}
}
// 如果没有找到,输出 "no"
cout << "no" << endl;
return 0;
}
优化输入输出
如果需要处理多行输入或更灵活的输入格式,可以使用 getline() 替代 getchar() 或 cin,使程序更加通用。
💯总结
通过本文,我们探讨了如何高效解决字符统计类问题。从暴力解法到基于哈希表的优化,再到支持更大字符集的拓展,每一种方法都对应了不同的应用场景和实现复杂度。在实际开发中,我们应根据问题的规模和输入特点选择合适的方法,平衡效率与代码可维护性。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-01-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号