【初阶数据结构篇】归并排序和计数排序(总结篇)


归并排序和计数排序
前言
本篇以排升序为例
代码位置
gitee 前篇:【初阶数据结构篇】插入、希尔、选择、堆排序介绍 中篇:【初阶数据结构篇】冒泡排序和快速排序
归并排序
基本思想
归并排序算法思想: 归并排序(MERGE-SORT)是建⽴在归并操作上的⼀种有效的排序算法,该算法是采⽤分治法(Divide andConquer)的⼀个⾮常典型的应⽤。将已有序的⼦序列合并,得到完全有序的序列;即先使每个⼦序列有序,再使⼦序列段间有序。若将两个有序表合并成⼀个有序表,称为⼆路归并。归并排序核⼼步骤:
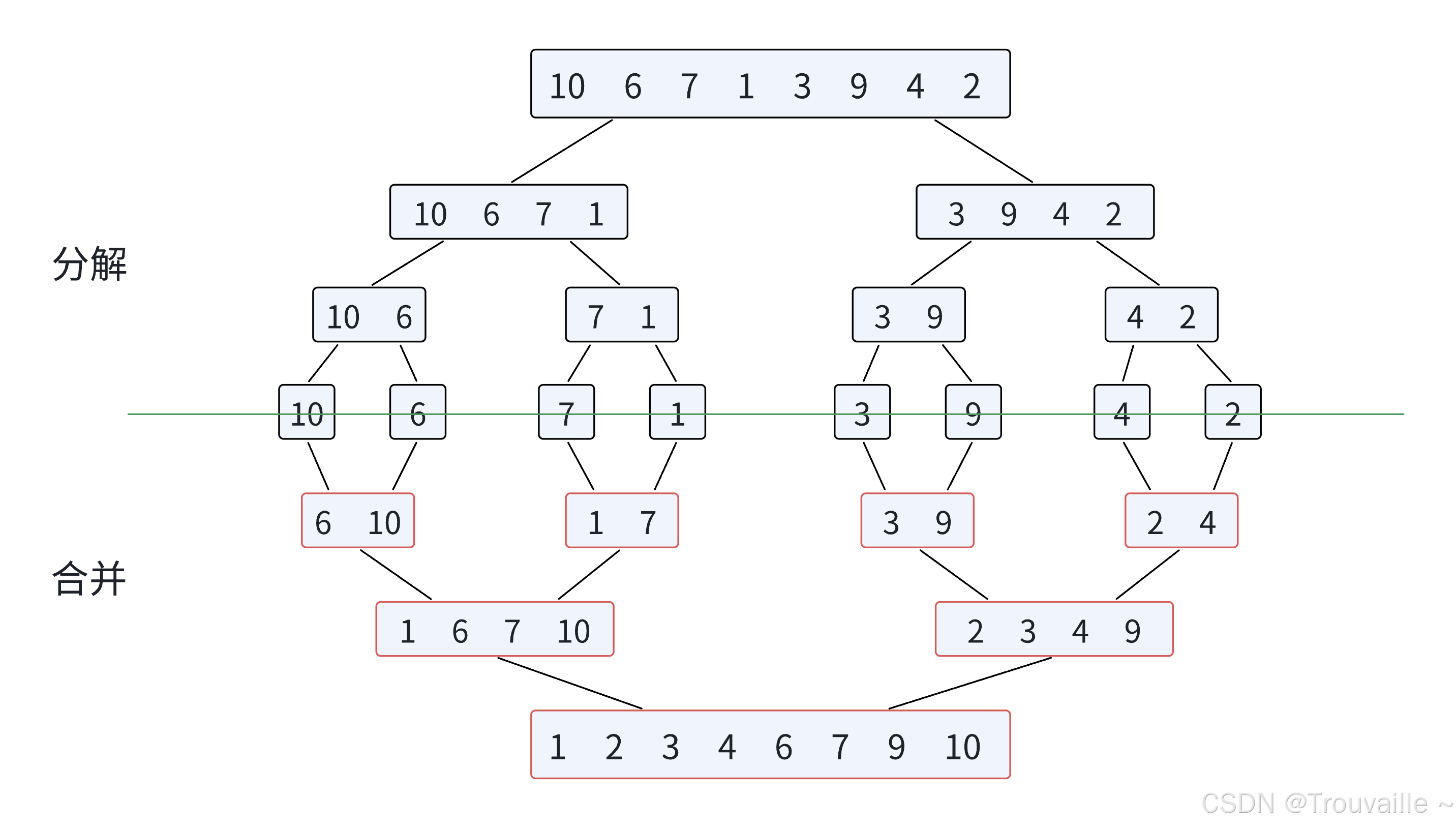
- 归并排序,顾名思义,先递归再合并,具体步骤如下:
- 第一步,拿到左右下标,一直二分到只有一个元素
- 以上图6 10这个函数栈帧为例,left=0,right=1,此时找到mid为0,这里二分为[0,0]和[1,1]两个区间,直接return(这里二分时要带上mid,在快速排序中每个函数栈帧我们把基准值排到了正确的位置,所以再进行递归时不用管这个位置的元素了,而这里我们是从下往上操作的,先细分到一个元素再依次向上两两合并)
- 第二步,开始合并
- 说白了就是合并两个有序数组的问题
- 这里展示一道在顺序表算法题里讲过的例题
- 给你两个按 非递减顺序 排列的整数数组
nums1和nums2,另有两个整数m和n,分别表示nums1和nums2中的元素数目。 请你 合并nums2到nums1中,使合并后的数组同样按 非递减顺序 排列。 **注意:**最终,合并后数组不应由函数返回,而是存储在数组nums1中。为了应对这种情况,nums1的初始长度为m + n,其中前m个元素表示应合并的元素,后n个元素为0,应忽略。nums2的长度为n。- 思路其实是一样的,只不过上面这个确实是两个数组
- 但在归并排序里面,说是两个序列,但其实只是同一个数组里不同的区间,如果还在原数组操作会把数组的元素覆盖掉,无法排序。
- 所以我们新创建了一个和原来数组一样的数组tmp,用来存储我们排序后的顺序
- 其他思路就是一样的了,依次比较,然后把小的放在前面,最后跳出循环时再把没有越界的指针后面元素依次放到tmp就行,这样就实现了有序序列的合并了(注意在放入tmp时候也要保证下标对应)
- 第三步,我们要排序的是原数组的元素,所以每次在[left,right]区间内排好的序列要复制给arr
- 经过不断的合并回归,最后在arr数组里得到的就是排好序的序列了
- 代码如下,思路很简单,但就是第一次看整个代码可能有点懵
void _MergeSort(int* arr, int left, int right, int* tmp)
{
if (left >= right)
{
return;
}
int mid = (left + right) / 2;
//[left,mid] [mid+1,right]
_MergeSort(arr, left, mid, tmp);
_MergeSort(arr, mid + 1, right, tmp);
//合并
//[left,mid] [mid+1,right]
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int index = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tmp[index++] = arr[begin1++];
}
else {
tmp[index++] = arr[begin2++];
}
}
//要么begin1越界但begin2没有越界 要么begin2越界但begin1没有越界
while (begin1 <= end1)
{
tmp[index++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = arr[begin2++];
}
//[left,mid] [mid+1,right]
//把tmp中的数据拷贝回arr中
for (int i = left; i <= right; i++)
{
arr[i] = tmp[i];
}
}
void MergeSort(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
_MergeSort(arr, 0, n - 1, tmp);
free(tmp);
}- 复杂度分析
- 时间复杂度:递归深度logn,对于每一层来说都是会把所有元素遍历一次,例如在递归第一层(二叉树第一层的函数栈桢)把原区间分为了两个区间,最后回归的时候就是合并两个有序数组,会把其中元素都遍历一次;其他层都同理为n,总计O(nlogn)。
- 空间复杂度:递归深度logn,开辟n个元素的空间,为O(n)。
且这个复杂度很稳定,不会像快速排序一样因为基准值的好坏或着排序序列的变化而改变(二分序列一旦左右下标有了就定了,而在快排中左右序列区分还要基于基准值,基准值的位置一旦“一边倒”就会导致很差的时间和空间复杂度。)
计数排序
- 前面讲的七中排序方法都是比较排序法,意味着我们在函数的实现中都或多或少通过比较了两个元素的大小来进行排序
- 这里介绍一种非比较排序方法,计数排序
基本思想
计数排序⼜称为鸽巢原理,是对哈希直接定址法的变形应⽤。
至于什么是哈希直接定址法,其实就是一种映射,也是计数排序的主要思想。
操作步骤:
- 统计相同元素出现次数
- 根据统计的结果将序列回收到原来的序列中
- 开辟数组空间大小max-min+1
- 将数组所有值减去最小值
- 所以开辟数组下标就是[0,max-min]
- 相当于把数组内数据大小整体往前平移了min个单位当做数组的下标(min可以为负数)
原因如下:
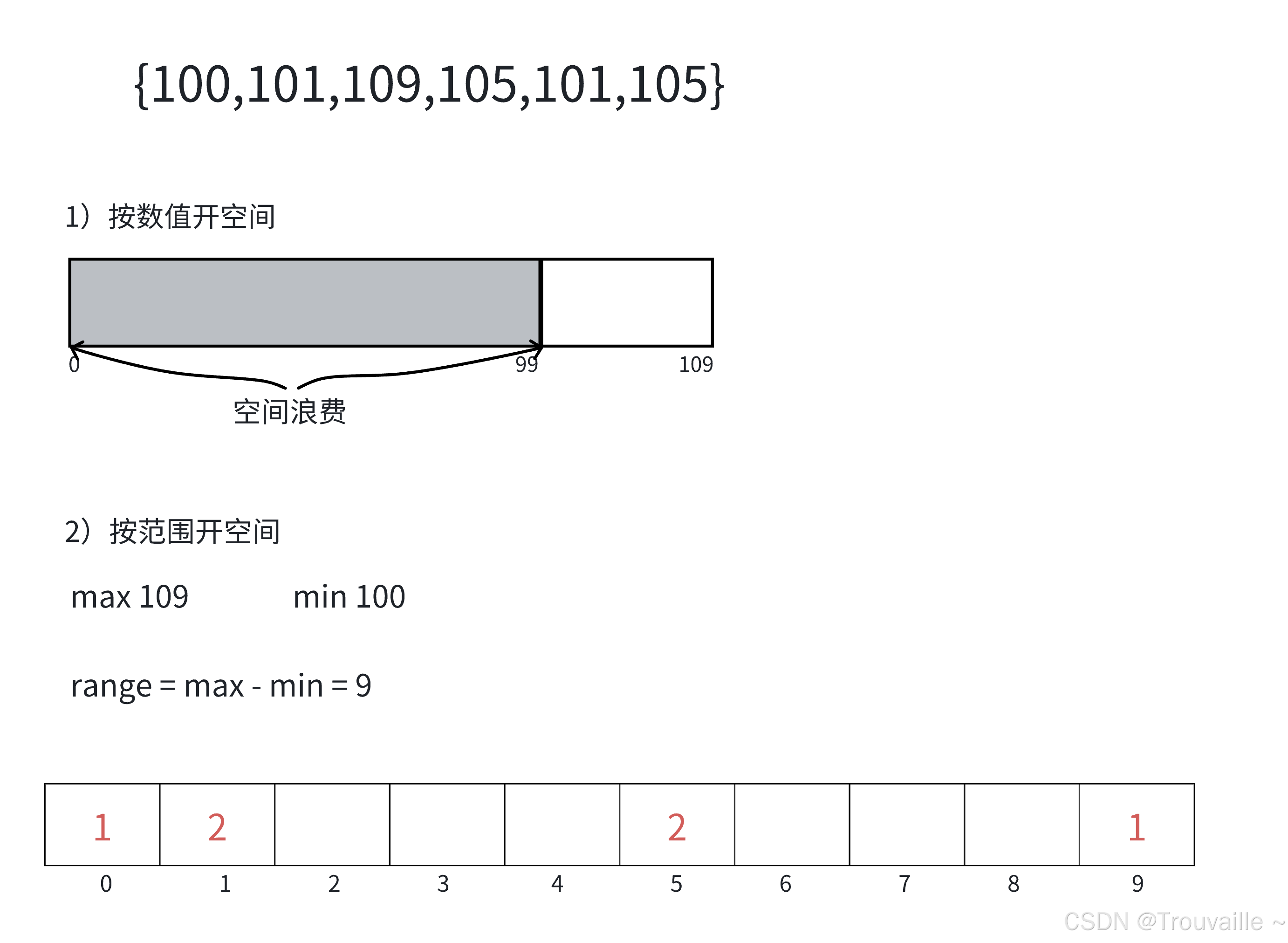
- 第一步,确定数组最大值和最小值,遍历
- 第二步,申请空间并初始化
- 第三步,统计每个数据出现的个数
- 根据申请的数组下标递增依次往原数组放数据
这样我们就把本来乱序的数据通过数组下标依次递增这一特点进行了排序
void CountSort(int* arr, int n)
{
//根据最大值最小值确定数组大小
int max = arr[0], min = arr[0];
for (int i = 1; i < n; i++)
{
if (arr[i] > max)
{
max = arr[i];
}
if (arr[i] < min)
{
min = arr[i];
}
}
int range = max - min + 1;
int* count = (int*)malloc(sizeof(int) * range);
if (count == NULL)
{
perror("malloc fail!");
exit(1);
}
//初始化range数组中所有的数据为0
memset(count, 0, range * sizeof(int));
//统计数组中每个数据出现的次数
for (int i = 0; i < n; i++)
{
count[arr[i] - min]++;
}
//取count中的数据,往arr中放
int index = 0;
for (int i = 0; i < range; i++)
{
while (count[i]--)
{
arr[index++] = i + min;
}
}
}- 复杂度分析
- 时间复杂度:找最大和最小值为N,统计个数也是遍历原数组为N,最后往原数组放数据,相当于遍历一次新数组为range,加上把N个数据放到原数组,所以总时间复杂度O(N+range)
- 空间复杂度:O(range)
特性分析
计数排序在数据范围集中时,效率很⾼,但是适⽤范围及场景有限。
比如只能用来排整数数据。
排序性能比较
- 更加直观的体会到各种排序算法的时间复杂度差异
- 使用随机数函数造数据,然后排序打印不同算法排序时间
// 测试排序的性能对⽐
void TestOP()
{
srand(time(0));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
int* a8 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
a8[i] = a1[i];
}
int begin7 = clock();
BubbleSort(a7, N);
int end7 = clock();
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N - 1);
//QuickSortNonR(a5, 0, N - 1);
int end5 = clock();
int begin6 = clock();
MergeSort(a6, N);
int end6 = clock();
int begin8 = clock();
CountSort(a8, N);
int end8 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
printf("BubbleSort:%d\n", end7 - begin7);
printf("CountSort:%d\n", end8 - begin8);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
free(a7);
free(a8);
}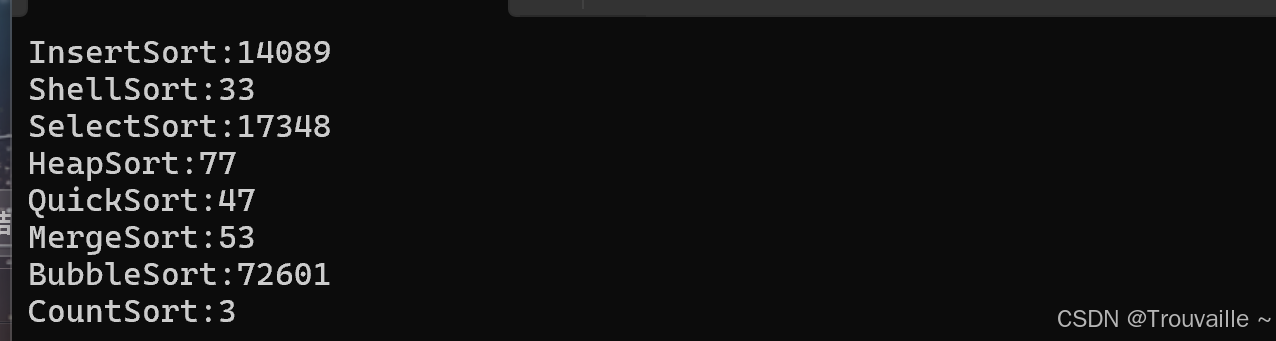
可见希尔排序,堆排序,归并排序以及计数排序的优越性
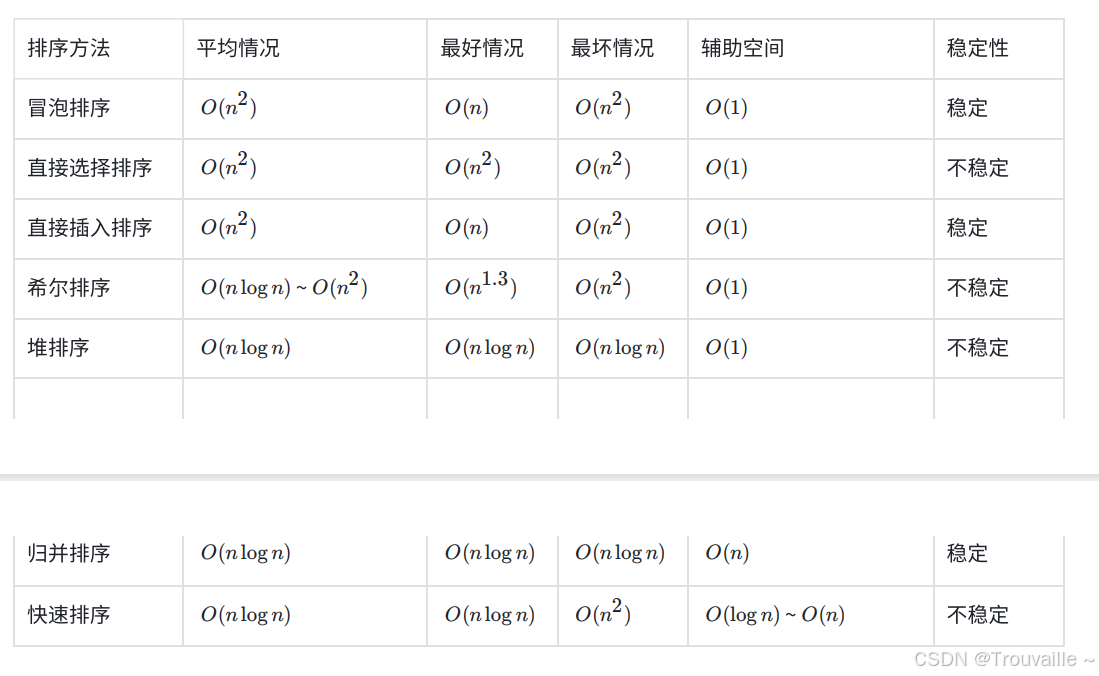
排序算法复杂度及稳定性分析
基本概念
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的 相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,⽽在排序后的序列中,r[i]仍在r[j]之 前,则称这种排序算法是稳定的;否则称为不稳定的。
简单来说就是重复的数据在排序前后相对位置是否发生改变
稳定性验证案例
- 直接选择排序:5 8 5 2 9
- 希尔排序:5 8 2 5 9
- 堆排序:2 2 2 2
- 快速排序:5 3 3 4 3 8 9 10 11
代入排序方法一一验证即可发现这些排序是不稳定的
以上就是归并排序和计数排序方法的介绍啦,同时也对八大排序算法进行了比较总结,各位大佬有什么问题欢迎在评论区指正,您的支持是我创作的最大动力!❤️
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-08-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号