知乎SQL优化挑战赛题目3解析 - 性能提升500倍的内幕

知乎SQL优化挑战赛题目3解析 - 性能提升500倍的内幕

PawSQL
发布于 2024-08-20 15:12:52
发布于 2024-08-20 15:12:52
最近木匠在知乎上发起了一个SQL优化挑战赛,其中题目3用到了OR条件转化为UNION、隐式类型转化导致索引失效、LIMIT子句下推优化三个PawSQL的重写优化算法以及索引创建的策略。
下图是优化前后执行计划以及执行时间的对比,可以看到最终执行时间降低为原来的1/500,性能提升了500倍!本文详述其优化过程,同时一探PawSQL引擎内部优化机制。
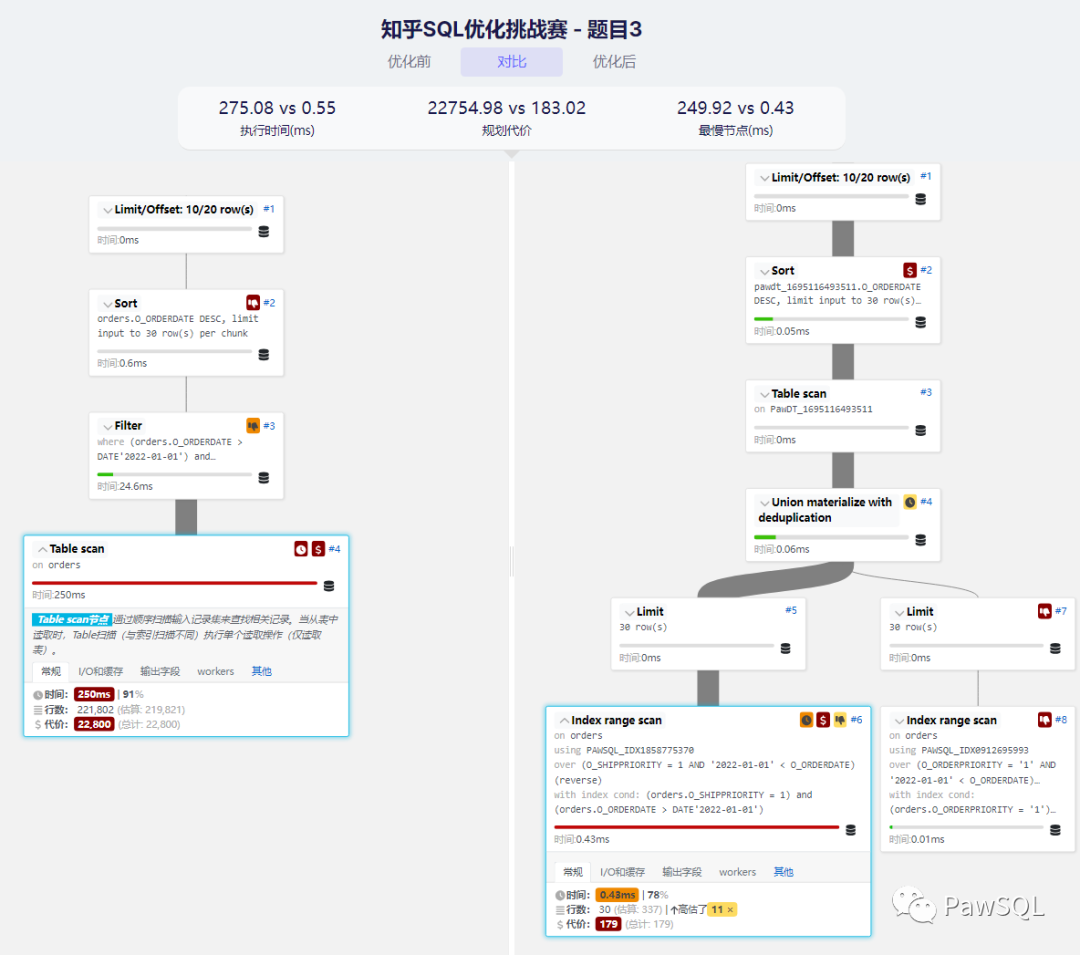
本文所使用的执行计划可视化工具为 PawSQL Explain Visualizer , 支持MySQL、PostgreSQL、openGauss等数据库。
* 更多关于的调优解析请订阅知乎SQL优化挑战赛合集!
问题描述
题目:下面的SQL如何优化性能最佳
select * from orders
where O_ORDERDATE>'2022-01-01' and (O_ORDERPRIORITY = 1 or O_SHIPPRIORITY = 1)
order by O_ORDERDATE desc
limit 20, 10;表定义:
-- tpch.orders definition
create table orders (o_orderkey int,o_custkey int,o_orderstatus char(1),o_totalprice decimal(15,2),o_orderdate date,o_orderpriority char(15),o_clerk char(15),o_shippriority int,o_comment varchar(79), primary key (o_orderkey)
) engine=innodb default charset=utf8mb4 collate=utf8mb4_0900_ai_ci;说明:此表为tpch测试集中的订单(orders)表,数据量及数据分布情况如下,
orders表总共20+w行,- 订单日期(
o_orderdate)在2021-01-01至2023-01-01基本均匀分布 o_orderpriority=1的筛选率在5%左右,O_ORDERDATE>'2022-01-01',筛选率在0.1%左右;o_shippriority=1筛选率0.1%。
优化过程
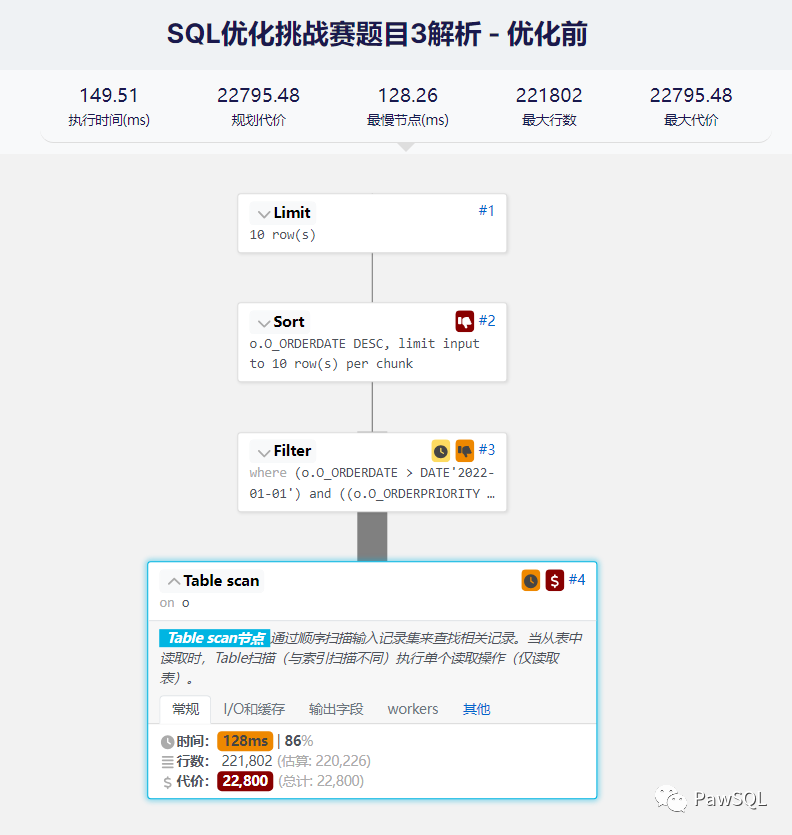
1. 原SQL分析
表orders除了主键,其他列上无索引。从执行计划可以看到,会进行全表扫描,执行时间为149.51ms,其中全表扫描花费了128ms,占总执行时间的84%,需重点优化。
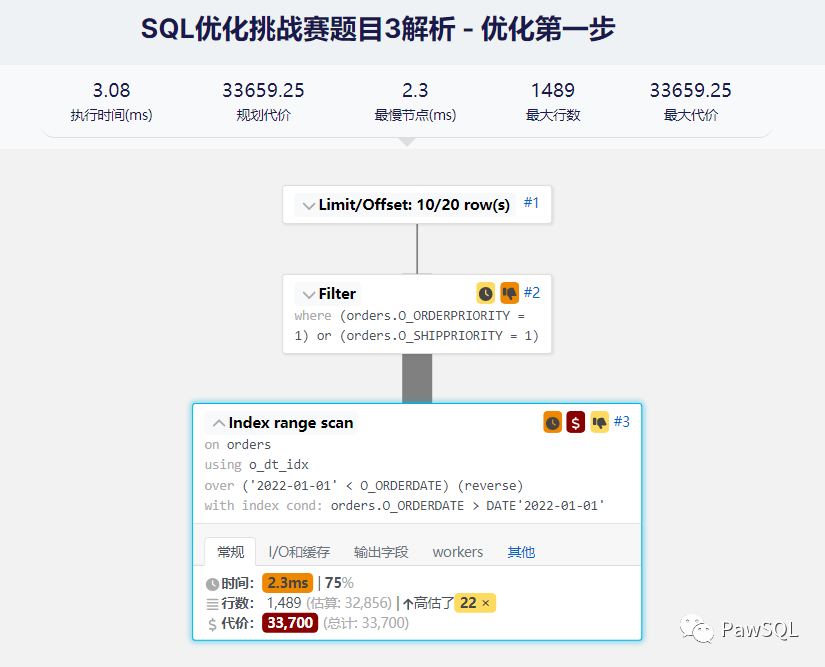
2. 优化第一步
- 目标: 消除全表扫描
- 优化方法:在
orders表的O_ORDERDATE字段上添加一个索引, create index o_custkey_idx on orders(O_ORDERDATE); - 优化效果: 通过下面的执行计划可以看到,通过索引
o_custkey_idx,数据库进行了Index range scan, 从20w的数据中过滤出1489行数据,大大降低的数据量。同时利用o_custkey_idx的有序性,避免了一次排序操作, 执行时间降低为3.08ms。
性能已经非常好了,如果在生产环境,此轮优化到这里就可以结束了。但是作为SQL优化挑战赛,此SQL还有进一步的优化空间吗?我们接着往下看。
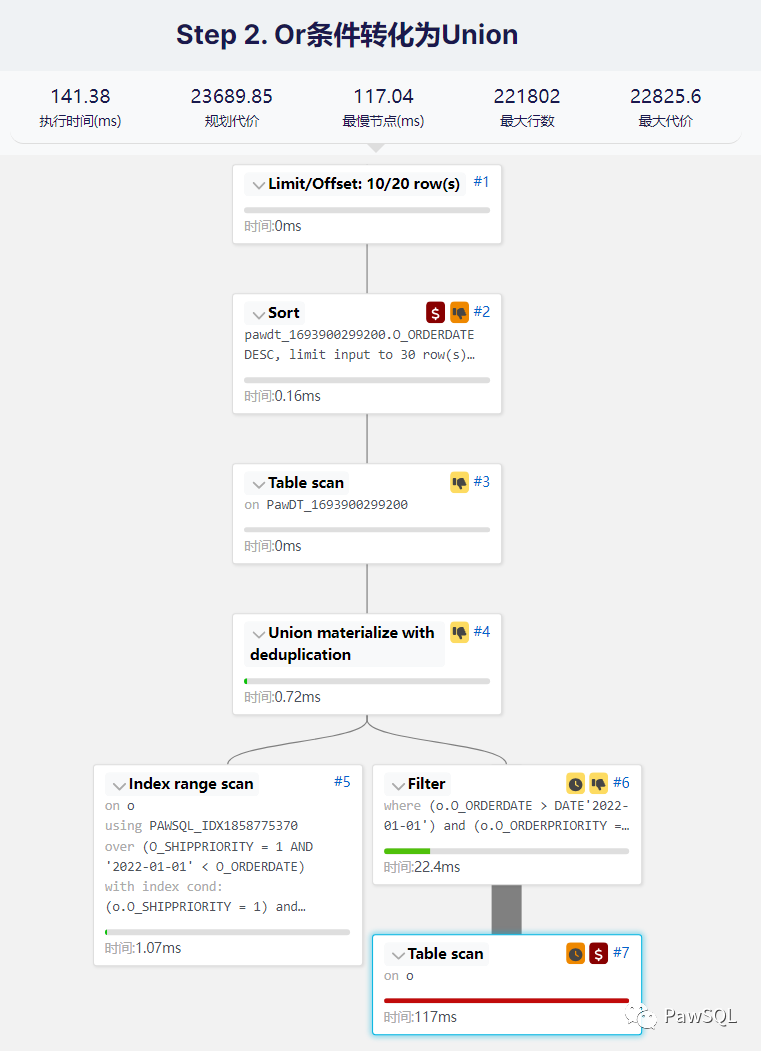
3. 优化第二步
- 目标:
O_SHIPPRIORITY和O_ORDERPRIORITY的筛选率都比较高,考虑利用他们提前过滤数据 - 方法:
- 将子查询的
OR条件重写为UNION - 分别对
UNION分支中的条件创建索引 select * from ( select * from tpch.orders as o where o.O_ORDERDATE > '2022-01-01' and o.O_SHIPPRIORITY = 1) union select * from tpch.orders as o where o.O_ORDERDATE > '2022-01-01' and o.O_ORDERPRIORITY = 1 ) as dt order by dt.O_ORDERDATE desc limit 20, 10; CREATE INDEX PAWSQL_IDX1858775370 ON tpch.orders(O_SHIPPRIORITY,O_ORDERDATE); CREATE INDEX PAWSQL_IDX0912695993 ON tpch.orders(O_ORDERPRIORITY,O_ORDERDATE);
- 将子查询的
优化效果: 我们可以看到SQL并没有按照预期性能提升,反而执行时间更久了,根据下面的执行计划分析我们看到第二个子查询并没有按照预期走索引(PAWSQL_IDX0912695993),反而是进行了全表扫描,执行时间变为141.38ms,性能大大降低。我们需要分析一下为什么没有按照预期走索引。
3. 优化第三步
- 目标:按照预期走
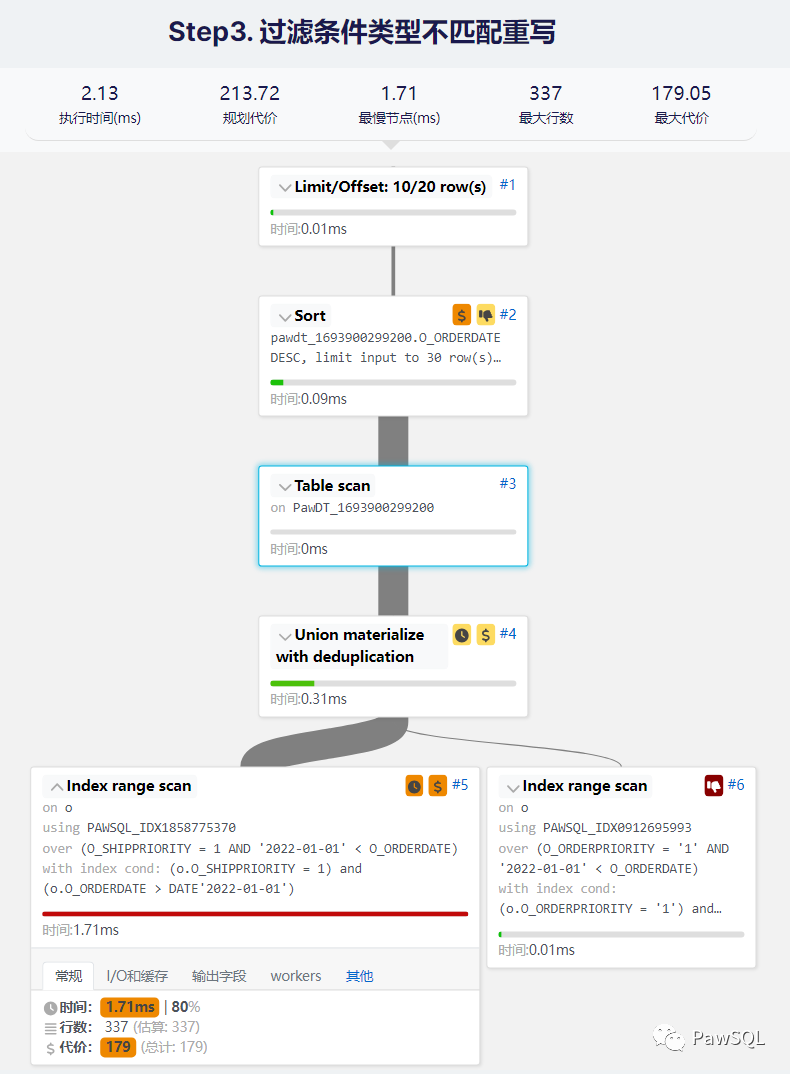
PAWSQL_IDX0912695993 - 方法:人工分析这一步还是比较费时的,首先我们需要分析索引失效可能的原因,并进行验证。索引失效的原因有很多,譬如索引列上有计算、索引列类型不匹配、索引列区分度太低、优化器参数设置不合理(把全表扫描的代价设得太低)等等。结合表定义的DDL,经过分析我们得出结论,是由于索引列类型不匹配导致的。对于条件
o.O_ORDERPRIORITY = 1, 由于列o.O_ORDERPRIORITY是字符型,真实执行的过程中是先把列o.O_ORDERPRIORITY值转化为int型再进行计算,即int(o.O_ORDERPRIORITY) = 1。 分析出这个原因,针对性的优化是把o.O_ORDERPRIORITY = 1重写为o.O_ORDERPRIORITY = '1'。 - 优化效果: 从执行计划我们可以看到SQL按照预期走索引,执行时间变为2.13ms,性能和第一步优化相比提升了一点。还有优化的空间吗?我们接着往下看。
3. 优化第三步
- 目标:减少子查询返回的行数
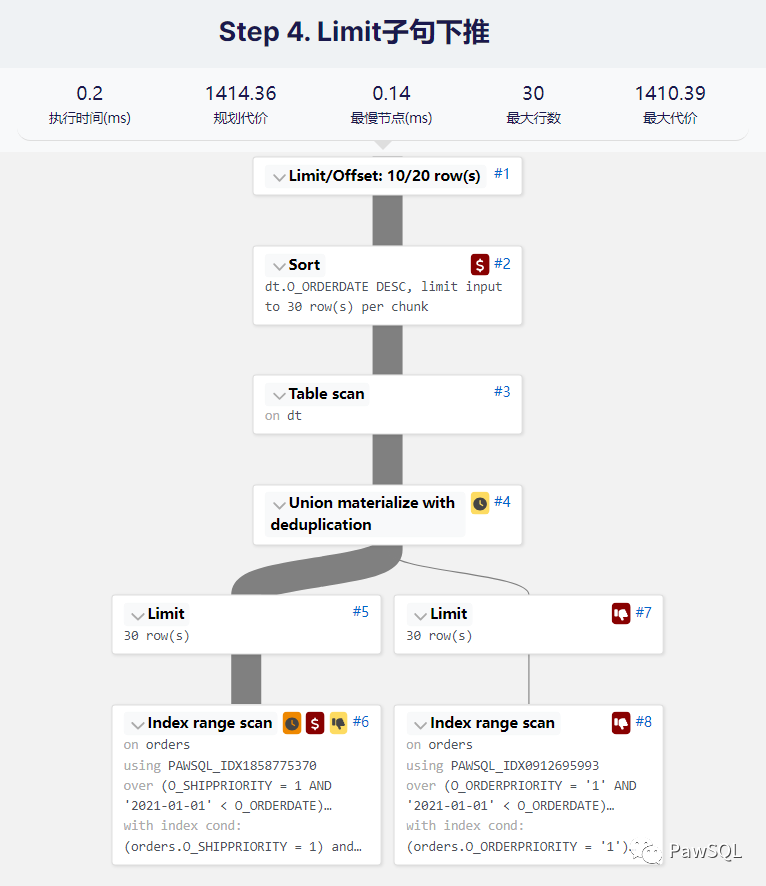
- 方法:从SQL的语义来说,我们只要10行数据,但是第一个子查询返回了337行,我们可以提前过滤吗?答案是可以的,方法就是把Limit子句下压到子查询中。
重写后的SQL如下:
select * from ( (select * from orders where orders.o_orderdate> '2021-01-01' and orders.o_shippriority= 1 order by orders.o_orderdate desc limit 30) union (select * from orders where orders.o_orderdate> '2021-01-01' and orders.o_orderpriority= '1' order by orders.o_orderdate desc limit 30)) as dt order by dt.o_orderdate desc limit 10 offset 20
注意:你不能直接把
limit子句拷贝粘贴到各个SQL的分支,需要将offset转移到limit上。即把limit 20, 10转化为limit 30 - 优化效果: 通过执行计划可以看到,经过
limit子句下推,最终的执行时间降低为0.2ms,相比较第三步提升10倍。整个优化流程走下来,执行时间从149ms降低到0.2ms,性能提升了700多倍。
PawSQL的自动优化
我们将待优化SQL直接提交到PawSQL,让其给我们做自动优化。从输出的优化详情页面我们可以看到,PawSQL自动帮我们进行了以下三个重写优化
OR条件重写为UNION- 隐式类型转化导致索引失效
- Limit子句下推三种重写优化
并且根据重写后的SQL推荐了对应的索引。使用PawSQL,真正做到了一键优化!
关于PawSQL
PawSQL专注数据库性能优化的自动化和智能化,支持MySQL,PostgreSQL,Opengauss等,提供的SQL优化产品包括
- PawSQL Cloud,在线自动化SQL优化工具,支持SQL审查,智能查询重写、基于代价的索引推荐,适用于数据库管理员及数据应用开发人员,
- PawSQL Advisor,IntelliJ 插件, 适用于数据应用开发人员,可以IDEA/DataGrip应用市场通过名称搜索“PawSQL Advisor”安装。
- PawSQL Engine, 是PawSQL系列产品的后端优化引擎,可以以docker镜像的方式独立安装部署,并通过http/json的接口提供SQL优化服务
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-09-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号