ASI 8年计划 paper5 主动推理的离散状态全面概述

ASI 8年计划 paper5 主动推理的离散状态全面概述

CreateAMind
发布于 2024-02-28 13:48:00
发布于 2024-02-28 13:48:00
Active inference on discrete state-spaces A synthesis
以这种方式解释动态具有一定的面向有效性,因为它使我们能够综合一系列生物学上合理的电生理反应;包括重复抑制,不匹配负性,违反响应,位置细胞活动,相位进程,节律序列,节律-γ耦合,证据积累,达到边界的动态和多巴胺反应的转移。
如果使用Bethe近似,则相应的动态与信念传播相吻合,这是另一种广泛使用的近似推断算法。这为主动推理和神经动态的消息传递解释之间提供了正式的联系。
Appendix C. Expected free energy as reaching steady-state
请注意这些贝叶斯模型平均值可能通过神经调节机制来实现
这个参数,调节策略选择的精度,在多巴胺神经元发放中有明确的生物学解释
去除某些状态或参数——在生物学上有一个明确的解释,即突触衰减和关闭某些突触连接,这让人想起睡眠的突触机制


a b s t r a c t摘要
主动推理是一种规范性原则,涵盖生物或人工智能的感知、行动、计划、决策和学习。从一开始,其相关的过程理论已经发展到包含复杂的生成模型,从而能够模拟各种各样的复杂行为。由于主动推理的连续发展,通常很难看出其基本原理如何与过程理论和实际实现相关联。在本文中,我们试图通过提供离散状态空间模型上主动推理的完整数学综述来弥合这一差距。这份技术总结提供了该理论的概述,从第一性原理推导出神经元动力学,并将这种动力学与生物过程联系起来。此外,本文还提供了 理解混合生成模型的主动推理所需的基本构件;允许连续的感觉传达离散的表象。本文可用于以下用途:引导研究应对突出的挑战,关于如何实施主动 模拟实验行为的推论,或指向各种电子神经生理学的指针 可用于进行经验预测的响应。
1. Introduction简介
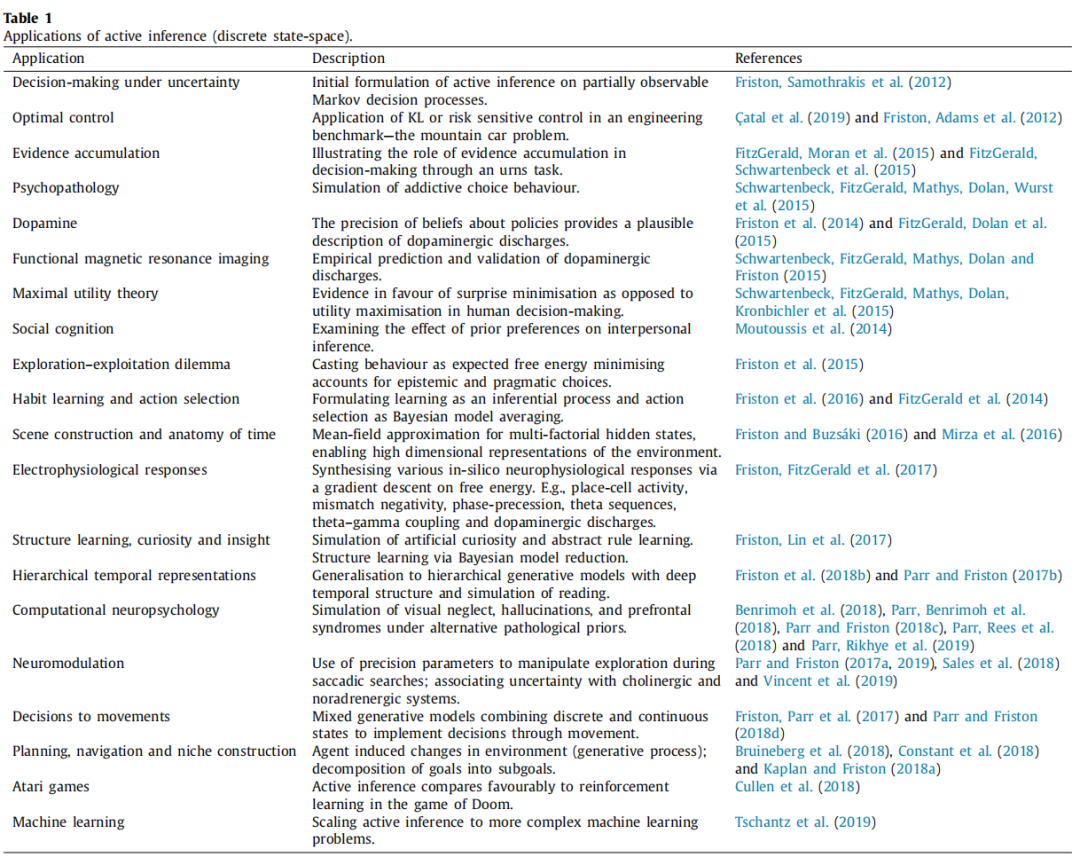
主动推理是一种规范性原则,作为神经科学中自组织理论的一部分,贯穿于生物或人工智能代理的感知、行动、规划、决策和学习过程中(Buckley等,2017; Friston, 2019; Friston等,2006年)。主动推理假设这些过程都可以被看作是优化两个互补的客观函数:一是变分自由能,用于衡量内部模型与过去感知观察结果之间的匹配程度;二是期望自由能,用于评分与先验偏好相关的可能未来行动方案。主动推理已被用于模拟神经心理学和机器学习中的广泛复杂行为,包括规划和导航(Kaplan&Friston,2018a),阅读(Friston等,2018b),好奇心和抽象规则学习(Friston,Lin等,2017),物质使用障碍(Smith,Schwartenbeck等,2020),接近避免冲突(Smith,Kirlic等,2020),眼球快速运动(Parr&Friston,2018a),视觉觅食(Mirza等,2016; Parr&Friston,2017a),视觉忽视(Parr&Friston,2018c),幻觉(Adams等,2013),生态位建构(Bruineberg等,2018; Constant等,2018),社会一致性(Constant等,2019),冲动性(Mirza等,2019),图像识别(Millidge,2019)和山地车问题(Çatal等,2019; Friston,Adams等,2012; Friston等,2009)。支持这些模拟的关键思想是生物利用内部前向(生成)模型来预测他们的感觉输入,然后推断这些数据的原因。除了模拟行为,主动推理还可以通过比较不同机制假设的证据来回答有关个体心理过程的问题,与行为数据相关。
主动推理非常通用,可以以相同的视角看待不同的行为模型。例如,漂移扩散模型现在可以与预测编码联系起来,因为它们都可以解释为通过证据积累过程最小化自由能(Bogacz,2017; Buckley等,2017; Friston&Kiebel,2009)。同样,选择行为的动态规划模型对应于在最大化奖励的先验偏好下最小化期望自由能(Da Costa等,2020)。主动推理的通用性并不意味着取代任何现有模型,而是应将其用作揭示更具体模型的承诺和假设的工具。
早期的主动推理形式采用了在连续空间和时间中表达的生成模型(关于介绍,请参阅Bogacz,2017年,关于综述,请参阅Buckley等,2017年),其中行为被建模为不断演化的随机动态系统。然而,我们知道大脑中的一些过程与离散、分层表示更加符合,相比于连续表示(例如,视觉工作记忆(Luck&Vogel,1997; Zhang&Luck,2008),通过位置细胞进行状态估计(Eichenbaum等人,1999; O'Keefe&Dostrovsky,1971),语言等)。反映这一点,神经科学中研究的许多范例自然地被构建为离散状态空间问题。决策任务是其中一个主要候选对象,因为它们通常涉及一系列代理需要在其中进行选择的离散选择(例如,多臂赌博机任务(Daw等,2006; Reverdy等,2013; Wu等,2018),多步决策任务(Daw等,2011))。这解释了为什么在主动推理中,代理行为通常使用离散状态空间的形式进行建模,其特定应用总结如表1所示。最近,混合生成模型(Friston,Parr等人,2017年)——结合了离散和连续状态——已被用于建模涉及离散和连续表示的行为(例如,决策和运动(Parr&Friston,2018d),语音产生和识别(Friston,Sajid等,2020),药物诱导的眼动控制变化(Parr&Friston,2019)或阅读;涉及连续视觉采样,用于推断离散语义(Friston,Parr等人,2017年))。
由于主动推理在最近的理论进步速度很快,因此往往很难保持对其过程理论和实际实现的全面了解。在本文中,我们希望提供主动推理在离散状态空间模型上的全面(数学)综述。这一技术摘要提供了理论的概述,从第一原理中推导出相关(神经)动态,并将其与已知的生物过程联系起来。此外,本文和Buckley等人(2017)提供了理解混合生成模型上主动推理所需的基本组件。本文可被视为实施主动推理以模拟实验行为的实用指南,或者是指向各种可在体外神经和电生理反应中进行实证测试的方向。
本文结构如下。第2节是对主动推理的高层概述。接下来的章节通过从第一原则出发推导整个过程理论来阐明公式化;涵盖了感知、规划和决策。这正式了行动-感知循环:(1)代理被呈现刺激,(2)它推断其潜在原因,(3)向未来规划,(4)实现其首选行动路线;然后重复。这种行为循环使我们能够探索突触可塑性的动态,它介导学习世界的相关性的慢时间尺度。我们在第9节中总结了主动推理中的结构学习概述。
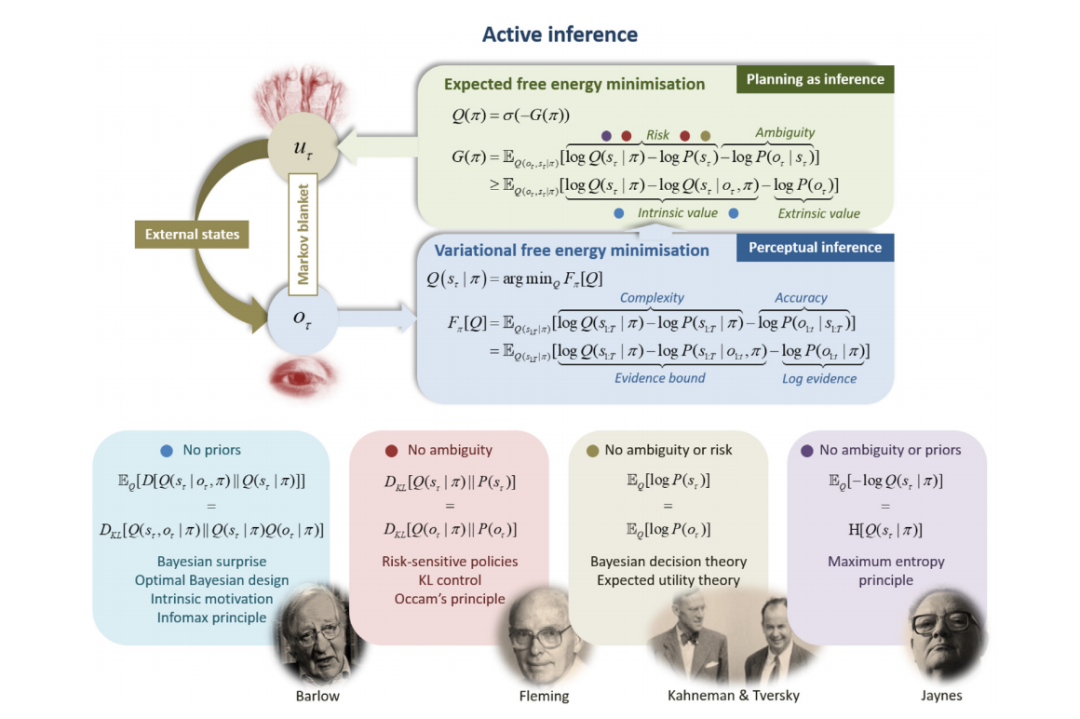
2. Active inference 主动推理
为了在不断变化的环境中生存,生物(和人工)代理必须将它们的感知保持在某种适宜范围内(即通过异稳态维持稳态)。简而言之,主动推理提出,代理通过优化两个互补的客观函数来实现这一点,即变分自由能和期望自由能。简而言之,前者衡量了其感知的内部(生成)模型与感官观察之间的契合程度,而后者根据其能够达到“首选”存在状态的能力评分每个可能的行动路线。
我们的第一个前提是,代理通过内部模型来表示世界。通过最小化变分自由能,该模型变得越来越符合环境。换句话说,这个概率模型及其所编码的概率信念不断更新以反映环境及其动态。这样的世界模型被认为是生成的;因为它能够根据对未来存在状态的信念生成关于感知的预测(例如,在规划或梦中)。如果一个代理通过一些温度受体感知到了热源(例如,另一个代理),那么温暖的感觉代表观察到的结果,热源的温度是一个隐藏状态;然后最小化变分自由能确保对隐藏状态的信念与真实温度紧密匹配。从形式上讲,生成模型是可能的隐藏状态和感知后果的联合概率分布 - 指定前者如何导致后者 - 并且最小化变分自由能使得能够‘‘翻转’’模型;即确定给定感觉的最可能的隐藏状态。变分自由能是在变分贝叶斯中优化的负证据下界(Bishop, 2006; Xitong, 2017)。从技术上讲 - 通过最小化变分自由能 - 代理执行近似贝叶斯推理(Sengupta & Friston, 2016; Sengupta et al., 2016),这使得它们能够推断其感觉的原因(例如,感知)。这是主动推理与贝叶斯大脑之间的接触点(Aitchison & Lengyel, 2017; Friston, 2012; Knill & Pouget, 2004)。关键是,代理可能在其模型中融入一种乐观主义偏差(McKay & Dennett, 2009; Sharot, 2011);从而将某些“首选”感觉评分更高为更可能。换句话说,偏好只是代理(相信它)可能朝向的东西。
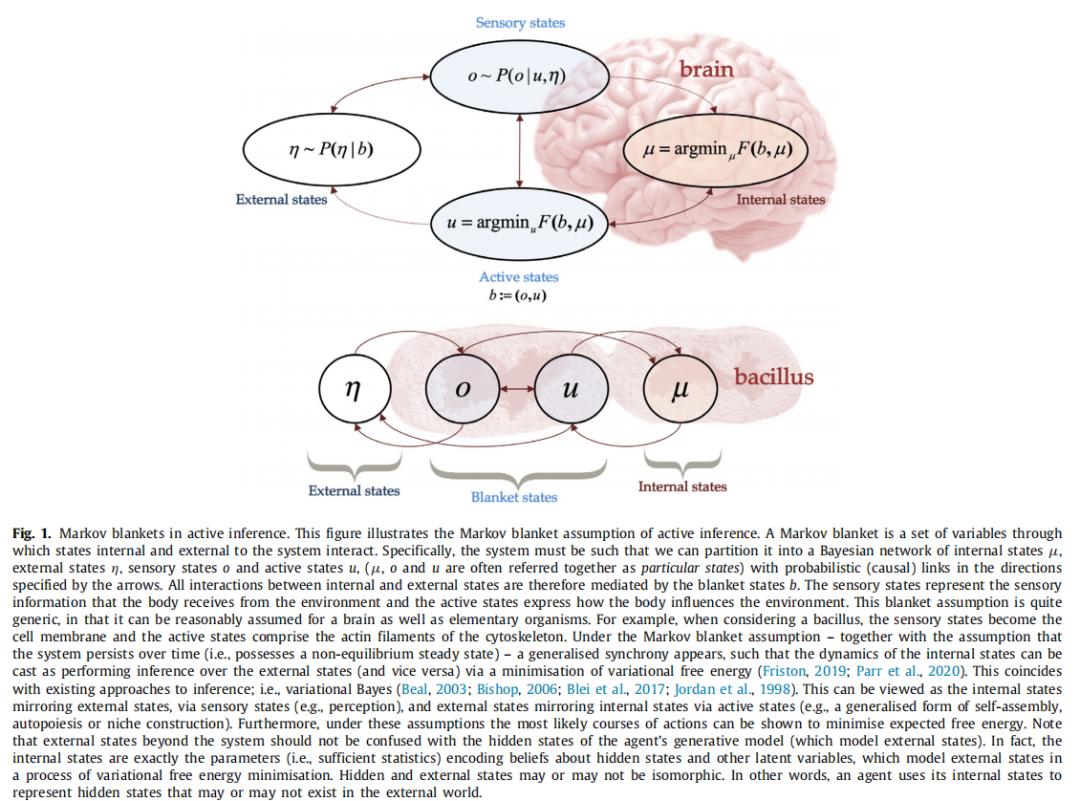
图1. 主动推理中的马尔可夫毯子。本图展示了主动推理中的马尔可夫毯子假设。马尔可夫毯子是通过它们之间的一组变量进行内部和外部状态交互的集合。具体来说,系统必须被分成一个贝叶斯网络,其中包括内部状态μ、外部状态η、感官状态o和主动状态u,(μ、o和u通常一起称为特定状态),并且具有由箭头指定方向的概率(因果)链接。因此,所有内部和外部状态之间的交互都由毯子状态b介导。感官状态代表身体从环境中接收到的感官信息,而主动状态表示身体如何影响环境。这种毯子假设非常通用,因为它可以合理地假设适用于大脑以及初级生物体。例如,当考虑一个杆菌时,感官状态成为细胞膜,而主动状态包括细胞骨架的肌动蛋白丝。在马尔可夫毯子假设下 - 与系统随时间持续存在(即具有非平衡稳定状态)的假设一起 - 出现了一种广义的同步性,使得内部状态的动态可以被视为通过最小化变分自由能对外部状态进行推断(反之亦然)(Friston, 2019; Parr et al., 2020)。这与现有的推理方法相吻合;即,变分贝叶斯(Beal, 2003; Bishop, 2006; Blei et al., 2017; Jordan et al., 1998)。这可以被视为内部状态通过感官状态(例如,感知)反映外部状态,以及外部状态通过主动状态(例如,自我组装、自组织或环境构建的广义形式)反映内部状态。此外,在这些假设下,最可能的行动路线可以被证明是最小化期望自由能。请注意,系统之外的外部状态不应与代理的生成模型的隐藏状态(模拟外部状态的模型)混淆。实际上,内部状态恰好是编码对隐藏状态和其他潜在变量的信念的参数(即,足够的统计量),它们在变分自由能最小化过程中模拟外部状态。隐藏状态和外部状态可能是同构的,也可能不是。换句话说,代理使用其内部状态来表示可能存在也可能不存在于外部世界中的隐藏状态。
为了维持体内平衡并确保生存,特工agent必须尽量减少意外“2”。注释2:在信息理论中,与生成模型下的结果相关联的惊喜(也称为surprisal)由−log p(o)给出。这指定了观察结果的不寻常程度和令代理感到惊讶的程度,但这并不意味着代理有意识地体验到惊喜。在信息理论中,这种惊喜被称为自信息self-information。由于生成模型分数优先结果更有可能,最小化意外对应于最大化模型证据“3”。注释3:在贝叶斯统计中,与生成模型相关联的模型证据(通常称为边际似然)是p(o),即根据模型观察到的结果的概率(有时这被写作p(o|m),明确地对模型进行条件设定)。模型证据评分了模型作为解释被采样数据的好坏,通过奖励准确性并惩罚复杂性,从而避免过拟合。在主动推理中,这是由上述过程保证的;事实上,变化的自由能被证明是惊喜的上限,最小化预期自由能确保实现优选结果,从而平均避免惊喜。
因此,主动推理可以被构建为通过感知和行动来最小化惊喜(Friston,2009,2010;Friston et al.,2006;Friston & Stephan,2007)。在此处讨论的离散状态模型中,这意味着代理人从不同的可能行动方案(即策略)中进行选择,以实现他们的偏好,从而最小化他们未来预期遇到的惊喜。这使得感知-行动循环(Fuster,1990)可以被描述为贝叶斯公式:代理人通过最小化变分自由能来感知世界,确保他们的模型与过去的观察一致,并通过最小化期望自由能来行动,以使未来的感觉与他们的模型一致。这种行为描述可以简洁地被构建为自我证明(Hohwy,2016)。
与其他行为规范模型相比,主动推理是一个基于“第一原则”的解释,其根基在于统计物理学(Friston,2019;Parr et al.,2020)。主动推理描述了在感兴趣的某个时间尺度内持续存在(即不消散)的系统动态,并且可以从统计上与它们的环境分离——生物系统满足这些条件。从数学上讲,第一个条件意味着系统处于非平衡稳态(NESS)。这意味着存在一个稳态概率密度,系统在扰动后自组织并返回到该密度(即代理人的偏好)。统计分离条件是存在一个马尔可夫毯(参见图1)(Kirchhoff等人,2018;Pearl,1998):通过这个毯子,系统内部和外部的状态进行交互(例如,皮肤是人体的马尔可夫毯)。在这些假设下,可以证明系统内部的状态参数化了关于外部状态的贝叶斯信念,并且可以被视为变分自由能最小化的过程(Friston,2019;Parr等人,2020)。这与现有的近似推理方法相一致(Beal,2003;Bishop,2006;Blei等人,2017;Jordan等人,1998)。此外,可以证明这些系统采取的最有可能的行动方案是最小化期望自由能(或其变体,见附录C)- 这一数量包含了科学和工程中许多现有的构造(参见第7节)。
通过认同上述假设,可以将可行的生命系统的行为描述为执行主动推理-其余的挑战是确定它们实施主动推理的计算和生理过程。本文旨在总结对这个问题的可能答案,通过回顾主动推理在离散状态空间生成模型上的过程理论的技术细节,首次出现在Friston,FitzGerald等人(2017)中。需要注意的是,重要的是区分主动推理作为一个原则(如上所述)和主动推理作为一个过程理论。前者是关于生命系统的基本假设的结果,而后者是关于大脑中可能实现主动推理的计算和生物学过程的假设。随后的过程理论可以用来预测在实验中引发的合理神经动态和电生理反应。
3. Discrete state-space generative models离散状态空间生成模型
生成模型(Bishop,2006)表达了代理人对世界的表示方式。这是关于感知数据和这些数据的隐藏(或潜在)原因的联合概率分布。在主动推理中使用的离散状态空间生成模型特别适合表示离散时间序列和决策任务。这些可以被表达为部分可观察的马尔可夫决策过程(POMDPs)的变体(As-tröm,1965):从简单的马尔可夫决策过程(Barto &Sutton,1992;Stone,2019;White,2001)到形式上的深度概率(层次)模型的泛化(Allenby等人,2005;Box &Tiao,1965;Friston等人,2018b)。为了清晰起见,过程理论是针对最简单的模型推导出来的,以便理解随后的泛化;即代理人对初始状态的概率(指定为D),从一个状态到下一个状态的转移概率(定义为矩阵B)和在给定状态下的结果的概率(即可能性矩阵A)的概率;参见图2。
如上所述,大量的工作证实了用离散状态空间生成模型描述某些神经元表示是合理的(例如,Luck & Vogel,1997;Tee & Taylor,2018;Zhang & Luck,2008)。此外,长期以来已经知道-在神经元群的水平上-计算会周期性地发生(即,在不同且有时是嵌套的振荡频带中)。类似地,在许多过程中存在顺序计算的证据(例如,注意力Buschman & Miller,2010;Duncan等人,1994;Landau & Fries,2012,视觉感知Hanslmayr等人,2013;Rolls & Tovee,1994)以及在不同层次的神经层次结构(Friston,2008;Friston等人,2018b),符合层次预测处理的思想(Chao等人,2018;Iglesias等人,2013)。这容纳了观察的视觉扫视样本以大约4 Hz的频率发生的事实(Parr & Friston,2018d)。离散观察序列的相对缓慢呈现使得能够通过(更快的)神经动态在周围时间内进行推断。
主动推理隐含地解释了快速和慢速神经动态。在每个时间步,代理人观察到一个结果,通过感知推断过去,现在和未来(隐藏)状态。这为未来的计划提供了基础,通过评估(期望自由能的)可能策略。推断出的(最佳)策略指定了最可能的行动,然后被执行。在一个较慢的时间尺度上,用于编码世界(例如,A)的参数被推断出来。这被称为学习。更慢地,生成模型的结构被更新以更好地解释可用的观察结果-这被称为结构学习。以下各节阐明了主动推理过程理论的这些方面。
infer learn model
感知推理 参数学习 结构学习
本文主要关注推导并解释代理人可能使用图2中的生成模型实现的推断动态。由于在这些情况下的推导是类似的,我们将更复杂模型的讨论留给附录A。
4. Variational Bayesian inference变分贝叶斯推理
4.1. Free energy and model evidence自由能和模型证据
变分贝叶斯推断基于最小化一个称为(变分)自由能的量,它限制了在生成模型下感知观察的不确定性(即,惊奇)。同时,自由能最小化是一种统计推断技术,它使得在贝叶斯规则中后验分布的近似成为可能。在机器学习中,这被称为变分贝叶斯(Beal,2003;Bishop,2006;Blei等人,2017;Jordan等人,1998)。主动推理代理人最小化变分自由能,从而使他们的模型证据最大化,并推断他们的生成模型的潜在变量。在接下来的内容中,我们考虑特定的时间点为给定的t
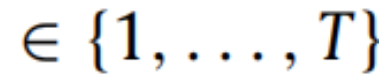
,于是代理人观察到了一系列的结果
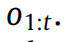
关于感知数据的潜在原因的后验由贝叶斯规则给出:
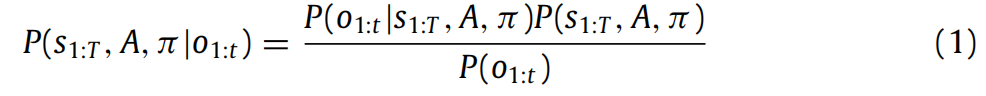
请注意,策略 π 是一个随机变量。这意味着规划是从观察中推断出最佳动作序列(Attias,2003;Botvinick&Toussaint,2012)。计算后验分布需要计算模型证据
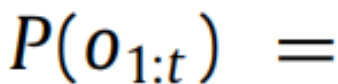
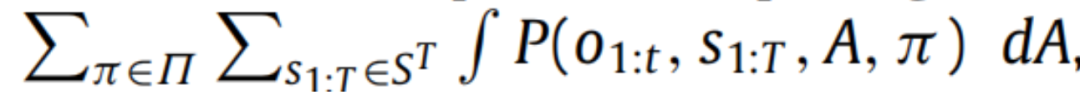
对于生物和人工系统所体现的复杂生成模型来说是不可行的(Friston,2008)—这是贝叶斯统计中一个众所周知的问题。计算精确后验分布的替代方法是通过最小化隐变量
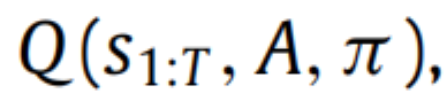
上的 Kullback–Leibler(KL)散度(Kullback&Leibler,1951)DKL一个非负的概率分布之间差异的度量。我们可以使用 KL 散度的定义和贝叶斯规则来得到变分自由能 F,它是近似后验信念的泛函:
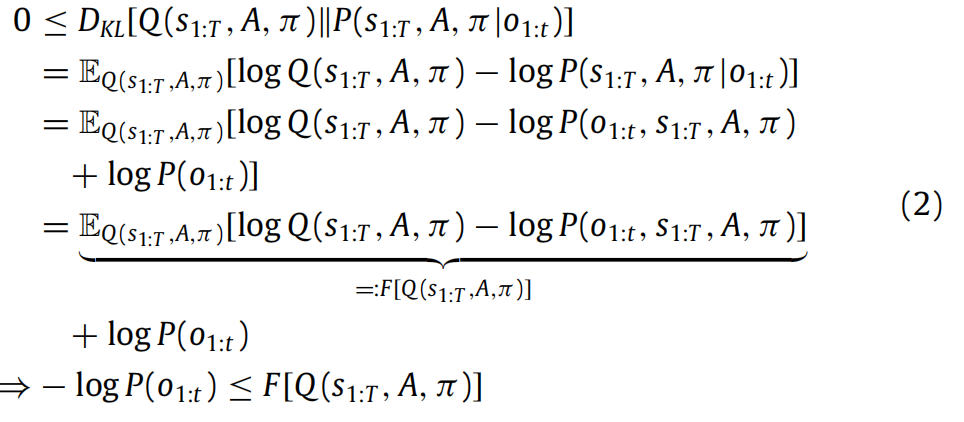
从(2)可以看出,通过变化 Q 来最小化变分自由能,我们可以近似真实的后验分布,同时确保惊讶保持在低水平。前者提供了自由能作为广义预测误差的直观解释,因为最小化自由能对应于抑制预测(即 Q)与实际情况(即后验)之间的差异;事实上,对于一类特定的生成模型,我们恢复了由预测编码方案给出的预测误差(参见 Bogacz,2017;Buckley 等,2017;Friston 等,2007)。总而言之,这意味着最小化变分自由能的代理同时推断观察的潜在原因并最大化其生成模型的证据。应注意,在全局自由能最小值处,自由能等于惊讶的负对数
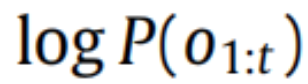
,当近似后验
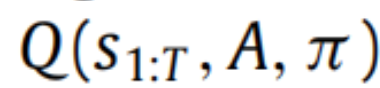
等于真后验
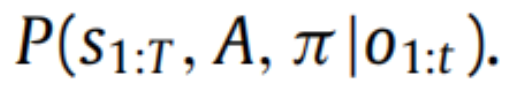
在全局自由能最小值之外,自由能上界了惊讶,换句话说,由于真后验通常是不可计算的,在这种情况下,上界的紧度通常是不可知的。
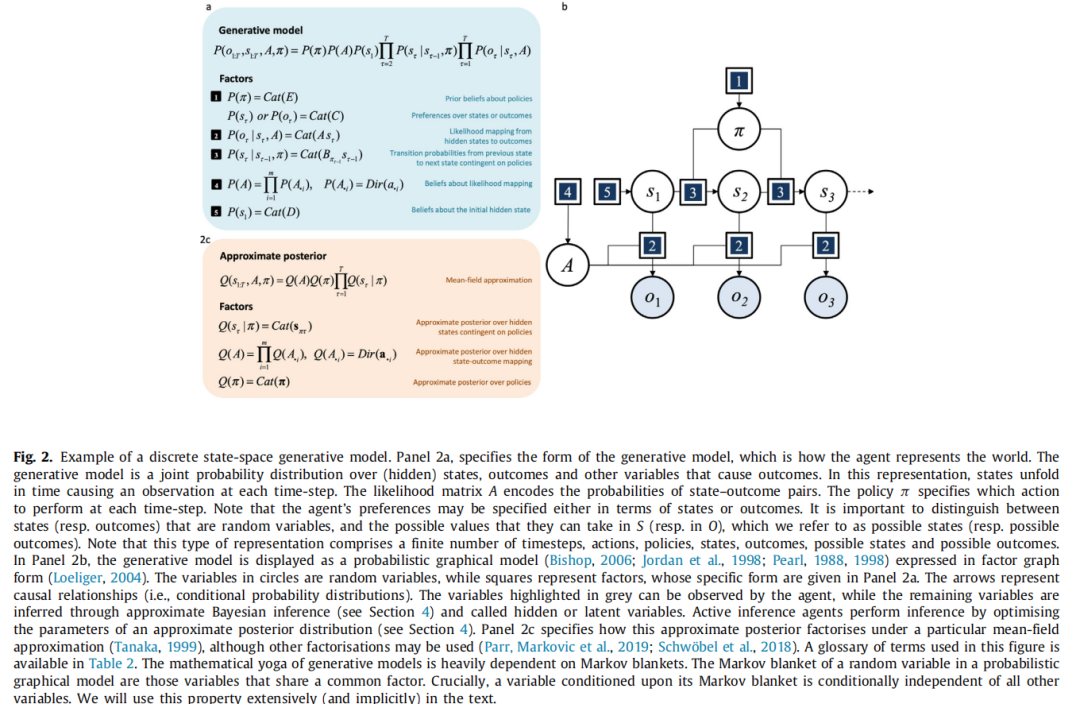
图2. 离散状态空间生成模型示例。面板2a指定了生成模型的形式,即代理如何表示世界。生成模型是关于(隐藏)状态、结果以及导致结果的其他变量的联合概率分布。在这种表示中,状态随时间展开,在每个时间步骤引发一个观察结果。似然矩阵 A 编码了状态-结果对的概率。策略 π 指定了每个时间步骤应执行的动作。请注意,代理的偏好可以根据状态或结果来指定。重要的是要区分随机变量的状态(或结果),以及它们可以在 S(或 O)中取的可能值,我们将其称为可能状态(或可能结果)。请注意,这种表示包括有限数量的时间步骤、动作、策略、状态、结果、可能状态和可能结果。在面板2b中,生成模型以概率图模型(Bishop,2006;Jordan 等,1998;Pearl,1988,1998)的因子图形式显示(Loeliger,2004)。圆圈中的变量是随机变量,而方块表示因子,其具体形式见面板2a。箭头表示因果关系(即条件概率分布)。灰色突出显示的变量可以被代理观察到,而其余变量通过近似贝叶斯推断进行推断(请参见第4节),称为隐藏或潜在变量。主动推断代理通过优化近似后验分布的参数来执行推断(请参见第4节)。面板2c指定了在特定均场近似(Tanaka,1999)下,此近似后验是如何分解的,尽管也可以使用其他分解方法(Parr,Markovic 等,2019;Schwöbel 等,2018)。本图使用的术语表可在表2中找到。生成模型的数学构造严重依赖于马尔科夫毯。在概率图模型中,随机变量的马尔科夫毯是与之共享公共因子的变量。关键是,条件于其马尔科夫毯的变量在条件下独立于所有其他变量。我们将在文本中广泛(并隐含地)使用此属性。
为了帮助直觉理解,变分自由能可以重新排列成复杂性和准确性两部分:
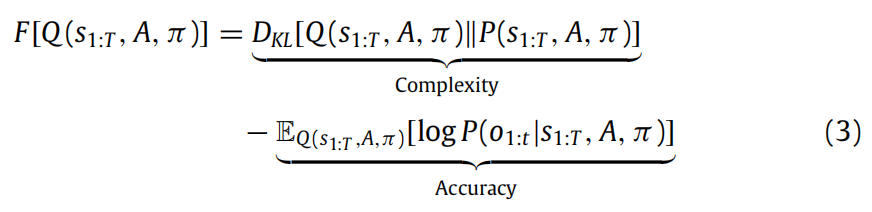
(3)式的第一项可以视为复杂性:对观测数据Q的简单解释,即少数假设(即KL散度接近零)之上的解释,是一个好的解释。换句话说,一个好的解释是对一些数据的准确描述,需要最小的改变来更新先验到后验信念(参见奥卡姆的原理)。第二项是准确性;即,在模型参数Q的后验信念下给出的数据的概率。换句话说,生成模型与观察数据的拟合程度。神经表示权衡复杂性与准确性的理念支持着寻找最准确、最简单的解释来解释感觉观察结果的必要性,这一理念被诸如霍勒斯·巴洛的最小冗余原理以及随后的实证支持所利用(参见Barlow, 2001),如Dan等人(1996年),Lewicki(2002年),Olshausen和Field(2004年),Olshausen和O'Connor(2002年)所述。图3说明了最小化自由能的各种含义。
4.2. On the family of approximate posteriors关于近似后验族
现在的目标是最小化相对于 Q 的变分自由能。为了获得变分自由能的可处理表达式,我们需要假设对近似后验进行某种简化的因子化。有许多可能的形式(例如,均场、边缘、Bethe,参见Heskes, 2006; Parr, Markovic 等人,2019; Yedidia 等人,2005),每种形式都在推理质量和涉及的计算复杂度之间进行权衡。为了本文的目的,我们使用了一种特定的结构化均场近似(请参阅表2,了解参与其中的不同分布和变量的解释):
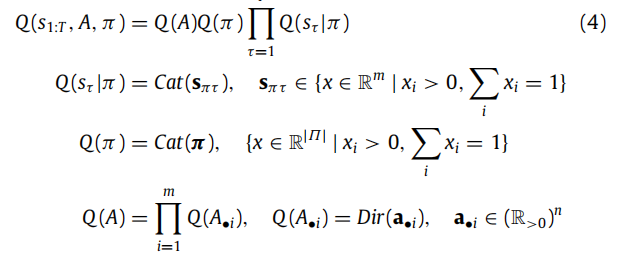

这种选择受到教学目的的驱动,而且这种因子化在活跃推理文献中已被广泛使用(Friston, FitzGerald 等人,2017; Friston, Parr 等人,2017; Friston 等人,2018b)。然而,最新的活跃推理软件实现(在 spm_MDP_VB_X.m 中可用)采用了边缘近似(Parr, 2019; Parr, Markovic 等人,2019),它保留了均场近似所提供的神经动力学的简单性和生物学解释性,同时近似了Bethe近似的更准确的推理。因此,出于这些原因,边缘自由能目前被认为是最具生物学可信度的。
4.3. Computing the variational free energy计算变分自由能
接下来的几节重点介绍基于变分自由能最小化的感知和学习的生物学可信度的神经动力学的产生。为了实现这一点,我们首先使用生成模型和近似后验的因子化来计算变分自由能(参见图2)。
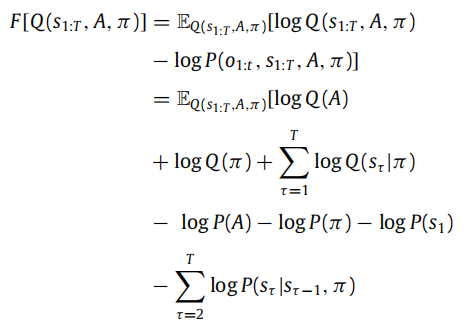
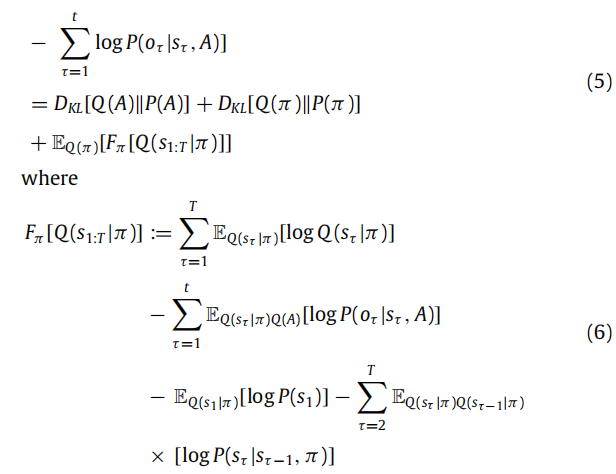

图3. 马尔可夫毯和自我证实。本示意图说明了最小化变分自由能的各种解释。回想一下,马尔可夫毯的存在意味着内部、毯子和外部状态之间缺乏一定的影响。这些独立性具有重要的后果;内部和活动状态是唯一不受外部状态影响的状态,这意味着它们的动态(即感知和行动)是特定状态(即内部、感官和活动状态)的函数,即这里的变分(自由能)约束的惊讶。这种惊讶有许多有趣的解释。考虑到它是找到一个粒子或生物在特定状态下的负对数概率,最小化惊讶相当于最大化粒子状态的价值。这种解释是合理的,因为高概率状态是吸引状态的定义。在这个观点下,可以将其解释为强化学习(Barto&Sutton,1992)、最优控制理论(Todorov&Jordan,2002)以及经济学中的预期效用理论(Bossaerts&Murawski,2015)。实际上,任何基于优化某个目标函数的方案现在都可以用最小化惊讶的术语来表达 - 以感知和行动的方式(即内部和活动状态的动态) - 通过指定这些最优值为代理的偏好。最小化惊讶(即自信息)导致了一系列有影响力的神经动态描述;包括最大互信息原理(Linsker,1990;Optican&Richmond,1987)、最小冗余和最大效率原理(Barlow,1961)以及自由能原理(Friston等,2006)。关键是,平均或预期的惊讶(随时间或特定状态的存在)对应于熵。这意味着行动和感知看起来就像在最小化熵。这使我们得出了自组织理论,例如物理学中的协同理论(Haken,1978;Kauffman,1993;Nicolis&Prigogine,1977)或生理学中的稳态理论(Ashby,1947;Bernard,1974;Conant&Ashby,1970)。最后,从统计观点来看,马尔可夫毯给定马尔可夫毯(m)的任何毯子状态的概率是模型证据(MacKay,1995,2003)。这意味着所有上述的制定都与贝叶斯大脑假设、证据积累和预测编码等内部一致;其中大部分继承自赫尔姆霍兹的无意识推断运动(von Helmholtz&Southall,1962),后来在20世纪心理学(Gregory,1980)和机器学习(Dayan等,1995)中以假设测试的形式加以阐述。
变分自由能是在追求特定策略的条件下的。这与我们通过省略A并将(1)中的所有概率分布在分子中的条件设置为π而获得的相同数量。在下一节中,我们将看到感知如何以最小化变分自由能的形式加以表述。
5. Perception 感知
在主动推断中,感知被等同于状态估计(Friston,FitzGerald等,2017)(例如,从温暖感推断温度),这与感知是假设的概念一致(Gregory,1980)。为了推断环境的(过去,现在和未来)状态,代理必须针对每个策略π最小化相对于
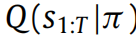
的变分自由能。这为代理提供了关于隐藏状态的推断,取决于追求给定策略。由于自由能的唯一部分取决于
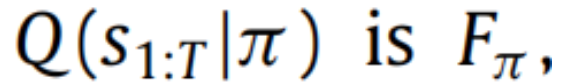
代理只需最小化Fπ。将
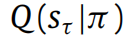
替换为其充分统计量(即参数向量sπτ),Fπ就成为这些参数的函数。这使我们能够方便地以矩阵形式重写(6)(有关详细信息,请参见附录B):
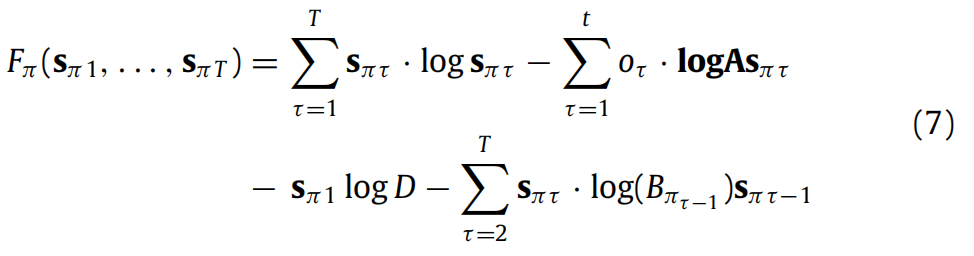
这使得可以计算变分自由能的梯度(Petersen & Pedersen,2012):
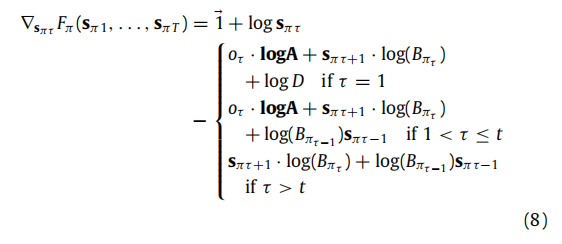

Softmax函数σ是对向量输入的sigmoid函数的一种推广,它是一个自然的选择,因为变分自由能梯度是一个对数,而
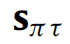
的分量必须求和为一。请注意自由能的连续时间梯度下降(式9);虽然我们专注于具有离散生成模型的主动推理,但这并不意味着信念更新不能在连续时间内发生(当将这些动态与神经生物学过程相关联时,这一点尤为重要,请参见下文)。然而,主动推理的任何数值实现都会实现(9)的离散版本直到收敛,例如
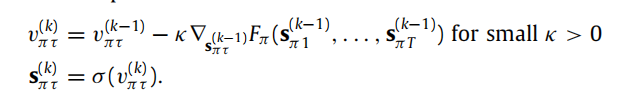
5.1. Plausibility of neuronal dynamics神经元动力学的合理性
在(9)中表达的时间动态在时间步内以更快的时间尺度展开,与采样新观察结果的速率相比要快得多,并对应于感知刺激时间内的快速神经处理。这与频率高于视觉采样速率的行为相关计算一致(例如,工作记忆(Lundqvist等人,2016),人类(Hanslmayr等人,2013)和猕猴(Rolls和Tovee,1994)的视觉刺激感知)。
此外,这些动态(9)与预测处理(Bastos等人,2012;Rao&Ballard,1999)一致-因为主动推理规定了最小化预测错误的动态-尽管它将其推广到广泛的生成模型。请注意,虽然也是变分自由能,但这种预测误差(7)与由预测编码方案给出的预测误差不同(后者依赖于某种连续状态空间生成模型,参见Bogacz,2017;Buckley等人,2017;Friston等人,2007)。
正如神经动态涉及从突触后电位到发放率的转换一样,(9)涉及从一组实数(v)到其元素介于零和一之间的向量(sπτ)的转换;通过softmax函数。因此,自然地将v的分量解释为不同神经群体的平均膜电位,将sπτ解释为这些群体的平均发放率,这要归功于神经的不应期。这与神经群体动态的平均场表述一致,即神经群体的平均发放率遵循平均膜电位的sigmoid函数(Deco等人,2008;Marreiros等人,2008;Moran等人,2013)。利用softmax函数是对向量输入的sigmoid函数的一种推广的事实-这里是耦合神经群体的平均膜电位-可以得出他们的平均发放率遵循他们的平均电位的softmax函数。在这种情况下,softmax函数可以被解释为执行侧抑制,这可以被认为导致个体神经元的调谐曲线更窄,从而进行更尖锐的推断(Von Békésy,1967)。重要的是,这告诉我们状态估计可以由不同的神经群体并行执行,并且简单的神经结构足以实现这些动态(参见Parr,Markovic等人(2019年,图6))。
最后,以这种方式解释动态具有一定的面向有效性,因为它使我们能够综合一系列生物学上合理的电生理反应;包括重复抑制,不匹配负性,违反响应,位置细胞活动,相位进程,节律序列,节律-γ耦合,证据积累,达到边界的动态和多巴胺反应的转移(Friston,FitzGerald等人,2017;Schwartenbeck,FitzGerald,Mathys,Dolan和Friston,2015)
用于状态估计的神经动态与变分消息传递(Dauwels,2007;Winn&Bishop,2005)完全一致,后者是一种用于近似贝叶斯推断的流行算法。这是因为根据特定的均场近似(4)进行自由能最小化,如我们所见。如果使用Bethe近似,则相应的动态与信念传播相吻合(Bishop,2006;Loeliger,2004;Parr,Markovic等人,2019;Schwöbel等人,2018;Yedidia等人,2005),这是另一种广泛使用的近似推断算法。这为主动推理和神经动态的消息传递解释之间提供了正式的联系(Dauwels等人,2007;Friston,Parr等人,2017;George,2005)。在下一节中,我们将探讨规划、决策和行动选择。
6. Planning, decision-making and action selection规划、决策和行动选择
到目前为止,我们已经集中讨论了通过最小化针对每个策略的隐藏状态的近似后验的变分自由能函数来优化对隐藏状态的信念。
在本节中,我们将解释规划和决策是如何作为期望自由能的最小化而产生的,期望自由能是评估每种可能未来行动方案的优劣的函数。我们简要阐述了期望自由能是如何从第一原理产生的。这使我们能够将决策制定和行动选择框架化为期望自由能的最小化。最后,我们讨论了规划未来的计算成本。
6.1. Planning and decision-making 规划与决策

在主动推理的核心是对代理人的描述,他们努力实现目标分布,该分布指定了在足够长的时间内所偏好的存在状态的范围。为了朝着达到这些偏好的目标努力,代理人选择策略Q(π),使得它们在未来某个时间点τ > t(通常是策略T的时间范围)的预测状态Q(sτ , A) 达到由生成模型指定的优选状态P(sτ , A),这些考虑使我们能够在附录C中展示,策略Q(π的必要近似后验是负期望自由能G“4”注释:更完整的处理可能包括政策的先验(通常用 E 表示)以及观察到的结果提供的政策证据(通常用 F 表示)。这些附加项补充了预期的自由能,导致近似后验形式为 σ(− log E−F−G)(Friston 等人,2018b)的softmax函数。
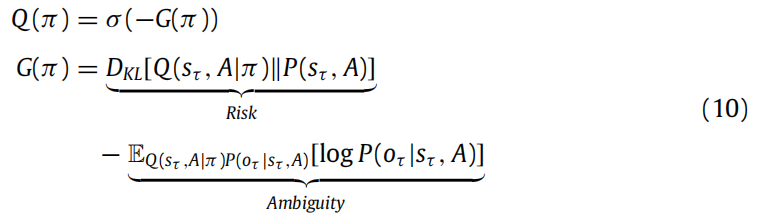
在这里,风险指的是未来预测与先验预测之间的差异(例如,金融风险中的损失量化),而模糊性则是与未来观察相关的不确定性,考虑到当前状态。这意味着最可能(即最佳)的策略将最小化期望自由能。这确保了未来的行动方案既具有开发性(即最小化风险),又具有探索性(即最小化模糊性)。特别地,期望自由能平衡着追求目标和追求新奇行为之间的关系,考虑了一些先验偏好或目标。请注意,模糊性术语基于对未来状态的信念下虚构(即预测)结果的期望。这意味着在感知过程中优化对未来状态的信念对于准确预测规划过程中的未来结果至关重要。总之,规划和决策分别对应于评估不同策略的期望自由能,该自由能评估了它们相对于先前偏好的优劣,并形成了关于策略的近似后验信念。
6.2. Action selection, policy-independent state-estimation
6.2动作选择,与策略无关的状态估计
关于策略的近似后验信念使得我们能够获得最合理的行动,即在所有策略下最有可能的行动,这可以表达为贝叶斯模型平均。
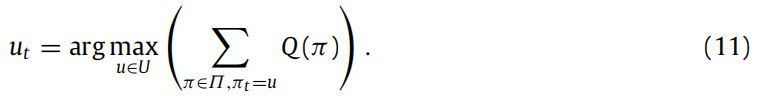
此外,在任何时间点Q(sτ ), τ ∈ {1, . . . , T },我们还可以获得独立于策略的状态估计 Q(sτ),作为对隐藏状态的近似后验信念的贝叶斯模型平均,这可以用分布的参数表示(Q(sτ ) = Cat(sτ ), Q(sτ |π) = Cat(sπτ )):

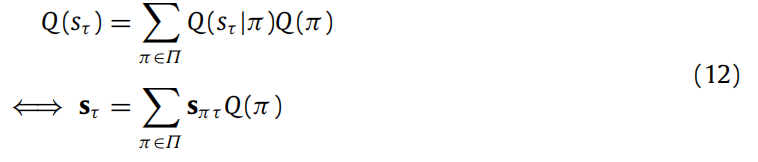
请注意这些贝叶斯模型平均值可能通过神经调节机制来实现(FitzGerald等人,2014)。
6.3. Biological plausibility生物学合理性
决策中的竞争取胜架构已经在计算神经科学中变得司空见惯(例如,选择性注意力和识别模型(Carpenter&Grossberg,1987;Itti等,1998),视觉的分层模型(Riesenhuber&Poggio,1999))。这是很好的,因为(10)中的softmax函数可以被视为提供了一种生物学上合理的(Deco等人,2008;Marreiros等人,2008;Moran等人,2013),对最大操作的平滑近似,这被称为软赢家通吃soft winner take-all(Maass,2000)。事实上,图2中呈现的生成模型可以自然地扩展,使得近似后验包含一个(逆)温度参数γ σ (−γ G(π)),,该参数乘以softmax函数内部的期望自由能(参见附录A.2)。这个温度参数调节了softmax函数近似最大函数的精度,因此对于高参数值恢复了赢家通吃的架构(技术上,这将贝叶斯模型平均转化为贝叶斯模型选择,其中策略对应于代理人正在做的模型)。这个参数,调节策略选择的精度,在多巴胺神经元发放中有明确的生物学解释(FitzGerald,Dolan等人,2015;Friston,FitzGerald等人,2017;Friston等人,2014;Schwartenbeck,FitzGerald,Mathys,多兰和Friston,2015)。有趣的是,Daw等人(Daw等人,2006)发现了支持类似模型的证据,该模型在人类决策中使用softmax函数和温度参数。
6.4. Pruning of policy trees策略树的修剪
从计算的角度来看,对于每种可能的策略进行规划(即计算预期自由能)可能会成本过高,这是由于在深入未来时,动作序列的数量呈指数级增长而导致的。有关大脑如何解决这个问题的研究已经进行了一些工作(Huys等,2012),这表明了一个简单的答案:在心理规划过程中,人类一旦遇到巨大损失(即预期自由能的高值使得策略高度不切实际),就会停止评估该策略。在主动推理中,这对应于使用奥卡姆窗口;也就是说,如果某个策略的预期自由能变得比最佳(最小预期自由能)策略高得多,我们就会停止评估该策略的预期自由能,并相应地将其近似后验概率设置为任意低的值。这种生物学上合理的修剪策略极大地减少了需要全面评估的策略数量。
参考:一个框架整合大脑理论 7 三层智能:有目的的行为,精确同步外部世界
尽管奥卡姆窗口对修剪策略树是有效的和生物学上合理的,但它无法处理伴随着深层策略树和长时间范围的大策略空间。这意味着修剪只能部分解释生物体如何进行深层策略搜索。需要进一步的研究来描述生物体如何将大策略空间减少到可处理的子空间的过程。一个解释 - 关于生物体评估深层策略树的显著能力 - 基于深(分层)生成模型,在这些模型中,策略在每个层级上操作。这些深层模型使得长期策略成为可能,模拟了层级中较高层次的隐藏状态之间的缓慢转换,以便对下属层次中更快状态转换进行情境化(见附录A)。由此产生的(半马尔可夫)过程可以根据在时间尺度上嵌套的有限时间跨度的层次策略来指定;例如,运动分块(Dehaene等人,2015;Fonollosa等人,2015;Haruno等人,2003)。
6.5. Discussion of the action–perception cycle行动-感知周期的讨论
最小化变分自由能和期望自由能是互补且相互有益的过程。最小化变分自由能确保生成模型对其环境的良好预测能力;这使得代理能够通过评估期望自由能来准确地规划未来,从而使其能够实现其偏好。换句话说,最小化变分自由能是有效规划和通过期望自由能达到偏好的工具;反过来,达到偏好最小化了未来状态的预期意外性。
总之,我们已经看到代理如何规划未来并做出关于最佳行动方向的决策。这结束了我们对行动-感知循环的讨论。在接下来的部分,我们将更详细地探讨期望自由能。然后,我们将看到主动代理如何以较慢的时间尺度学习环境的相关性和其生成模型的结构。
7. Properties of the expected free energy预期自由能的性质
期望自由能是一个基本的构想。在本节中,我们解释其主要特征,并强调它与神经科学和工程学中许多现有理论的重要性。
一种解释政策的期望自由能的方法有很多。也许最直观的是以风险和模糊性的角度来看:
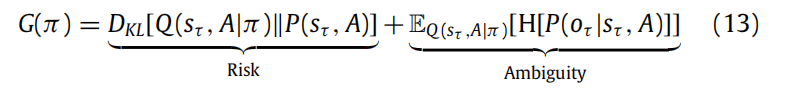
这意味着政策选择最小化了风险和模糊性。在这种情况下,风险简单地是预测和关于最终状态的先验信念之间的差异。换句话说,如果政策导致符合先验偏好的状态,那么它们将被认为更可能。在最优控制文献中,期望自由能的这一部分支持着KL控制(Todorov,2008; van den Broek等人,2010)。在经济学中,它导致了风险敏感的政策(Fleming&Sheu,2002)。模糊性反映了对未来结果的不确定性,考虑到隐藏状态。最小化模糊性因此意味着选择生成明确且具有信息量的结果的未来状态(例如,在黑暗中打开灯)。
我们可以将政策的期望自由能表达为对信息增益和期望log(模型)证据的界限(也称为贝叶斯风险):
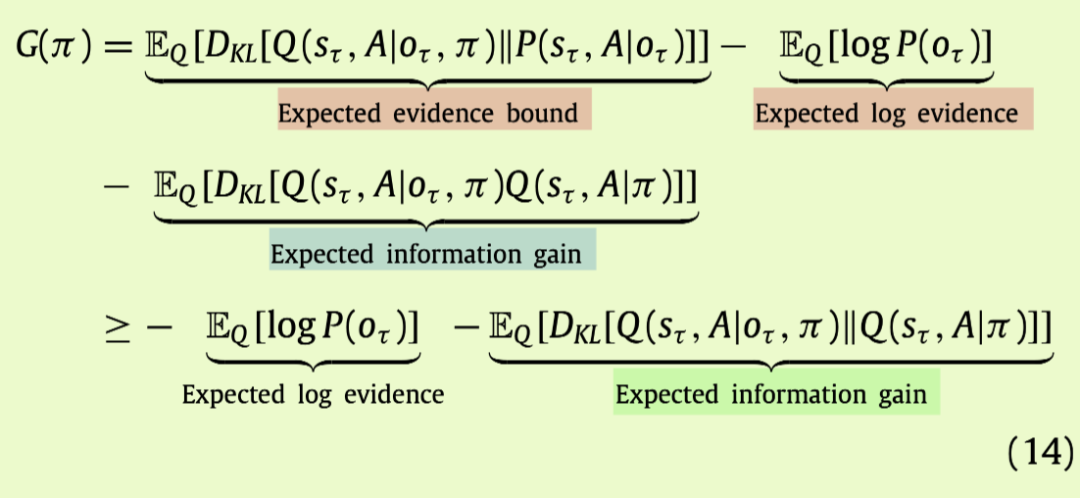
在公式(14)中,第一项是在对未来结果的信念下的对数证据的期望值,而第二项确保在遇到结果时这种期望是最充分的。总的来说,这两项支持解决关于隐藏状态(即信息增益)和结果(即期望意外)的不确定性,与先验信念相关。
当代理的偏好用结果来表达时(参见图2),将风险表达为结果而不是隐藏状态是有用的。当生成模型未知或在结构学习期间状态空间随时间演变时,这种方法最为有效。在这些情况下,通过假设在预期结果下,预测的后验分布与真实后验分布之间的KL散度很小,可以将对隐藏状态的风险替换为对结果的风险:
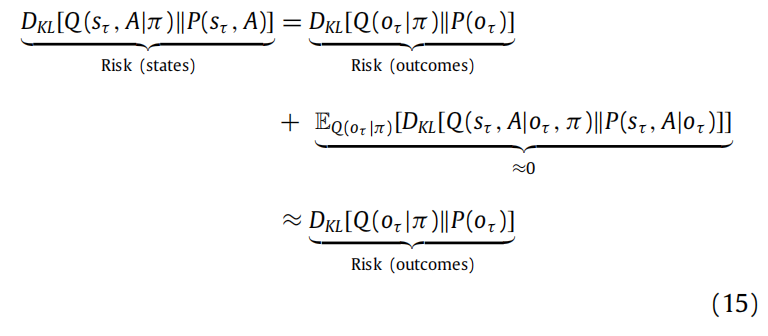
这种差异构成了一个预期证据边界,如果我们用内在价值和外在价值来表达预期自由能,它也会出现:

外在价值只是 log 证据的期望值,可以分别与行为心理学和经济学中的奖励和效用相关联(Barto等,2013; Kauder,1953; Schmidhuber,2010)。在这种情况下,外在价值是贝叶斯风险的负值(Berger,1985),当奖励是 log 证据时。一个策略的内在价值是其认知价值或功能性(Friston等,2015)。这仅仅是特定策略提供的预期信息增益,可以是关于隐藏状态(即显著性)或模型参数(即新颖性)的。正是这个术语支持了人工好奇心(Schmidhuber,2006)。
内在价值对应于关于模型参数的预期信息增益。在神经机器人技术中,这被称为内在动机(Barto等,2013; Deci&Ryan,1985; Oudeyer&Kaplan,2009),在经济学中被称为信息的价值(Howard,1966),在视觉神经科学中被称为显著性,(在视觉搜索文献中)被称为贝叶斯惊讶(Itti&Baldi,2009; Schwartenbeck等,2013; Sun等,2011)。从信息理论的角度来看,内在价值在数学上等同于未来隐藏状态及其后果之间的预期互信息,符合最小冗余或最大效率的原则(Barlow,1961, 1974; Linsker,1990)。最后,从统计学的角度来看,最大化内在价值(即显著性和新颖性)对应于最优贝叶斯设计(Lindley,1956)和机器学习派生物,例如主动学习(MacKay,1992)。在这种观点下,主动学习受到新颖性的驱动;即,鉴于未来状态及其结果,模型参数提供的信息增益。从启发式的角度来看,这种好奇心解决了关于“如果我这样做会发生什么”的不确定性(Schmidhuber,2010)。图 4 说明了预期自由能的范围,即其特殊情况;从最优贝叶斯设计到贝叶斯决策理论。

8. Learning
在主动推断中,学习涉及突触可塑性的动态,这被认为是对环境联系的信念进行编码的(Friston,FitzGerald等人,2017)(例如,在某些情况下,对B的信念被认为是在前额叶皮层的递归兴奋性连接中进行编码的(Parr,Rikhye等人,2019))。关于矩阵(例如A,B)的信念可以被编码在突触权重中符合大脑功能的连接主义模型,因为这提供了一种方便的计算概率的方式,即突触权重可以被解释为执行矩阵乘法,就像在人工神经网络中一样,以预测例如,从关于状态的信念中得出的结果,使用似然矩阵A。
这些突触动态(例如长时程增强和抑制)的演变速度比行动和感知慢,这与这样的推断需要多个状态-结果对的证据累积一致。为简单起见,我们将假设学习的唯一变量是A,但随之而来的推断适用于更复杂的生成模型(参见附录A.1)。学习A意味着对A的近似后验信念遵循对变分自由能的梯度下降。将变分自由能(5)视为a的函数(Q(A)的充分统计量),我们可以写成:
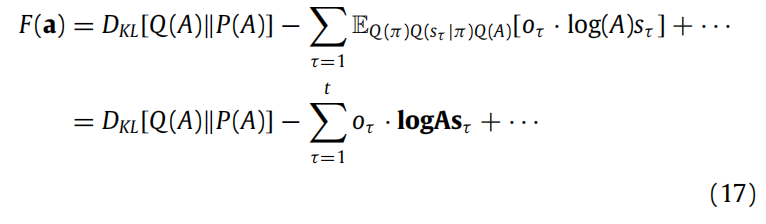
在这里,我们忽略了(5)中不依赖于Q(A)的项,因为当我们取梯度时,这些项将消失。Dirichlet分布之间的KL散度是(Kurt, 2013; Penny, 2001):
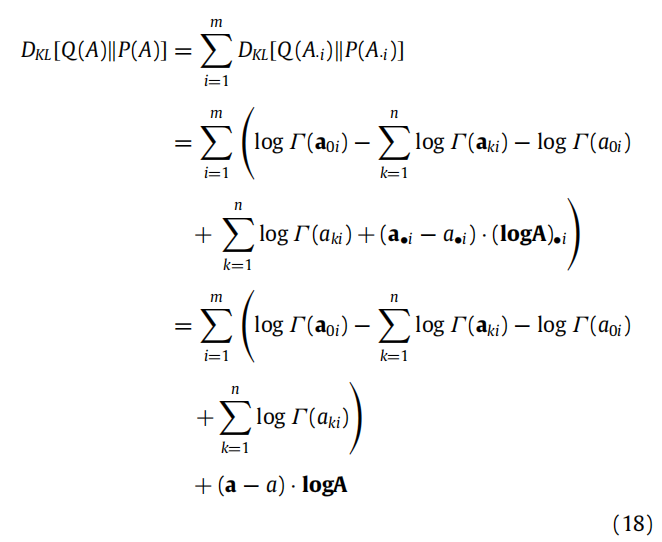

在计算上,这些是时间t的Dirichlet参数的证据累积动态。由于突触可塑性动态的发生速度远远慢于感知推断,因此在数值模拟中,在每个观察时期的试验结束时进行一步信念更新要便宜得多。明确地,在试验结束时将自由能梯度设置为零会给出以下的Dirichlet参数更新:

随后,先验信念P(A)被更新为下一次试验的近似后验信念Q(A)。特别要注意的是,更新计算了特定状态和观察之间的映射被观察到的次数。有趣的是,这在形式上与联想或Hebbian可塑性完全相同。After which, the prior beliefs P(A) are updated to the approximate posterior beliefs Q (A) for the subsequent trial. Note that in particular, the update counts the number of times a specific mapping between states and observations has been observed.Interestingly, this is formally identical to associative or Hebbian plasticity.
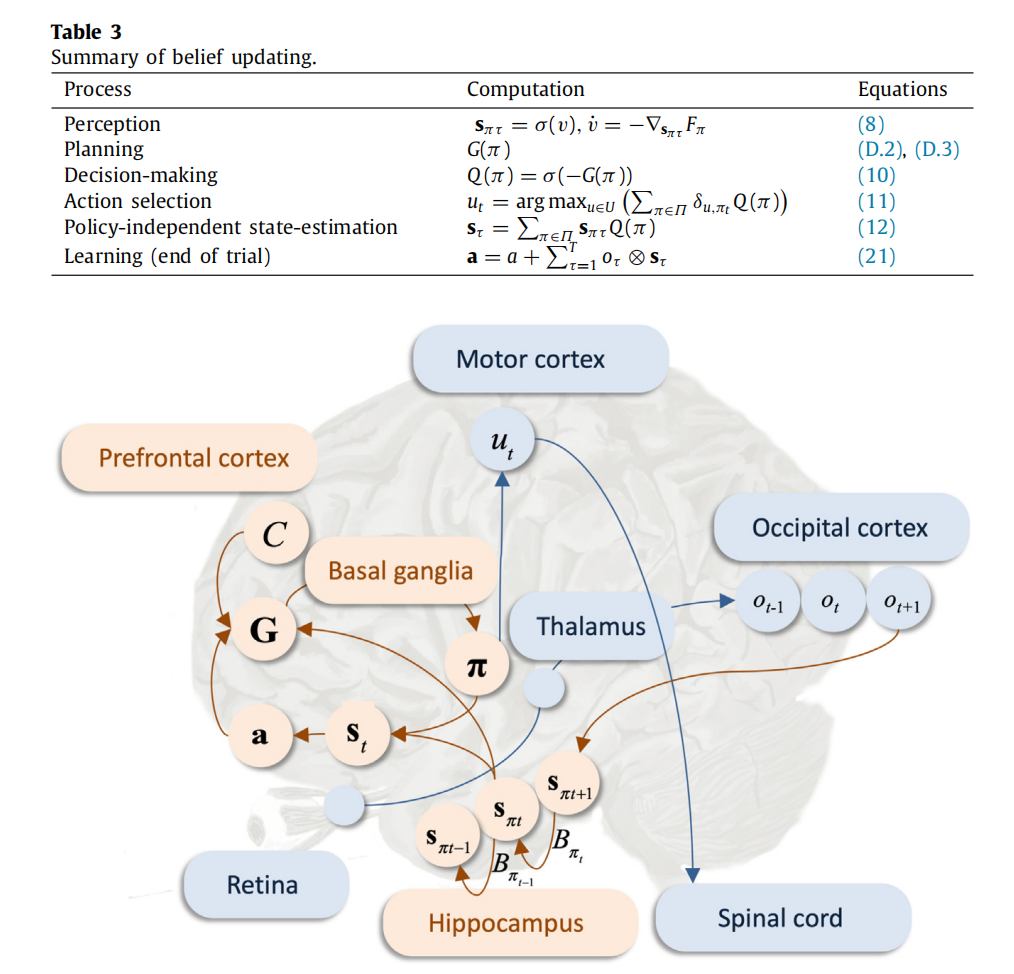
正如人们可以看到的那样,关于Dirichlet参数累积的学习规则(21)意味着在接收新观察时,代理变得对其似然矩阵越来越自信,因为每个时间步添加到a上的矩阵总是正的。只要环境的结构保持相对稳定,这是可以的。在下一节中,我们将看到贝叶斯模型缩减如何扭转这个过程,使代理能够快速适应不断变化的环境。表3总结了主动推断所涉及的信念更新,图5显示了大脑中特定计算可能被实现的位置。
9. Structure learning结构学习
在前面的章节中,我们讨论了一个代理如何以一种生物合理的方式对不同时间尺度上的不同变量进行推断,这被我们等同于感知、规划和决策。在本节中,我们考虑学习生成模型的形式或结构的问题。
这里的想法是,代理装备(例如,出生时)了一个固有的生成模型,其中包含了基本偏好(例如,对生存至关重要的偏好),这些偏好不会被更新。例如,人类对于体温约为 37°C 以及氧气、二氧化碳、葡萄糖等浓度在一定范围内的先验偏好是与生俱来的。从数学上讲,这意味着这些固有先验分布的参数——将代理的期望作为其生成模型的一部分编码——具有无限精确度的超先验(例如,狄拉克 δ 分布),因此无法根据经验进行更新。
代理的生成模型通过最小化变分自由能自然地演化,以成为对代理环境的良好模型,但仍受其内部硬编码的生存偏好的约束。这个学习生成模型的过程(即变量及其功能依赖关系)被称为结构学习。
超越 Sora 自动学习完整的世界模型结构
9.1. Bayesian model reduction贝叶斯模型简化
为了解释他们感觉的原因,代理必须比较关于他们感官数据生成方式的不同假设,并保留与他们观察到的最相关的假设或模型(即具有最大模型证据的模型)。在贝叶斯统计学中,这些过程被称为贝叶斯模型比较和贝叶斯模型选择——这些过程涉及评估与可用数据相关的各种生成模型的证据,并选择具有最高证据的模型(Claeskens & Hjort, 2006;Stephan et al., 2009)。贝叶斯模型简化(BMR)是结构学习的一个特定示例,它正式化事后假设测试以简化生成模型。这排除了关于感官数据的冗余解释,并确保模型适用于新数据。从技术上讲,它涉及估计对潜在原因的简化(减少)先验的证据,并选择具有最高证据的模型。简化生成模型的这一过程——通过去除某些状态或参数——在生物学上有一个明确的解释,即突触衰减和关闭某些突触连接,这让人想起睡眠的突触机制(例如,快速眼动(REM)睡眠(Hobson & Friston, 2012;Hobson et al., 2014)),反思和相关的机器学习算法(例如,唤醒-睡眠算法(Hinton et al., 1995))。
在接下来的内容中,我们展示了用于学习似然矩阵 A 的 BMR。请注意,BMR 是通用的,可以用于在学习过程中优化的任何其他变量(例如,请参阅附录 A.1),只需在下面的代码中将 A 替换为相应的变量即可。

为了保持简洁,我们用o = o1:t 表示可用观察结果的序列。当前模型具有先验概率P(A) ,我们希望测试是否一个简化(即更简单)的先验
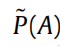
能够为观察到的结果提供更简洁的解释。利用贝叶斯定理,我们有以下等式:

我们可以用相应的近似后验 Q(A) 来近似 (26) 中的后验项,从而简化计算过程。这使我们能够比较两个模型(简化和完整模型)的证据。如果简化模型具有更多的证据,那么意味着当前模型过于复杂——可以通过采用新的先验来移除冗余参数。
总之,BMR 允许进行计算效率高且生物学上合理的假设检验,以找到对手头数据更简单的解释。它已被用于在抽象规则学习中模拟睡眠和反思(Friston, Lin 等人,2017),通过在每次试验结束时简化对 A 的先验——这具有防止代理过于自信的额外好处。
9.2. Bayesian model expansion贝叶斯模型扩展
贝叶斯模型扩展是贝叶斯模型简化的补充。它涉及采用更复杂的生成模型,例如通过添加更多状态,仅当在准确性上的增益足以抵消复杂性的增加时才采用。这种模型扩展允许在主动推理中进行泛化和概念学习(Smith 等人,2019)。需要注意的是,额外的状态并不总是导致更复杂的模型。原则上,可以以一种使复杂性减少的方式扩展模型,因为许多状态估计可能能够保持接近它们的先验,而不是少量的估计发生大量变化。许多参数的“共同工作”可能会导致更简单的模型。
从计算的角度来看,概念获取可以被视为一种结构学习(Gershman & Niv, 2010; Tervo 等人,2016)——可以通过贝叶斯模型比较进行模拟。关于主动推理中的概念学习的最新研究(Smith 等人,2019)显示,一个配备了额外隐藏状态的生成模型可以在学习过程中利用这些“未使用”的隐藏状态,当代理在学习过程中遇到新的刺激时。最初,相应的似然映射(即 A 的相应列)是无信息的,但当代理遇到无法由其当前知识解释的新观察结果时,这些信息将被更新(例如,当它只接触过鸟时观察到猫)。这在学习过程中自然发生,通过自由能量最小化以无监督的方式进行。为了实现有效的泛化,这种方法可以与 BMR 结合使用;其中,任何新概念都可以与类似概念聚合,并且相关的似然映射可以重新设置以进行进一步的概念获取,以支持具有更高模型证据的简化模型。这种方法可以通过贝叶斯模型比较的过程来进一步扩展,从而更新额外隐藏状态的数量。
10. Discussion讨论
由于近期对主动推理的各种理论进展,很容易忽视其基本原理、过程理论和实际实现。我们试图通过清晰简洁地重申主动推理的基本假设、离散状态空间生成模型的过程理论的技术细节,以及伴随的神经动力学的生物学解释来解决这个问题。澄清这些结果是有益的,作为引导朝向杰出的理论研究挑战、实现主动推理以模拟实验行为的实用指南,以及可能被实证测试的各种预测的第一步。
主动推理作为大脑功能的过程理论提供了一定程度的合理性。从理论角度来看,其必需的神经动力学与已知的经验现象相一致,并扩展了早期的预测编码理论。此外,该过程理论与基本的自由能量原理一致,据信生物系统遵循这一原理,即避免出现令人惊讶的状态:这可以基于关于生物系统的基本假设进行正式阐述。最后,该过程理论具有一定的面部效度,因为其预测的电生理反应与实证测量密切相似。
然而,要完全认可本文提出的过程理论,需要对合成电生理反应进行严格的实证验证。为了追求这一目标,需要指定生物代理人为特定任务采用的生成模型。这可以通过对备选生成模型进行贝叶斯模型比较来完成,以便与正在测量的实证(选择)行为相一致。一旦确定了适当的生成模型,就需要比较对主动推理的可信而独特的实现,这些实现来自于自由能量的各种可能近似,每种近似都会产生不同的信念更新和模拟的电生理反应。需要注意的是,目前边际近似于自由能量是最符合生物学的(Parr,Markovic 等人,2019)。通过这一过程,可以评估主动推理在与实证测量相关的解释能力,并与其他现有理论进行对比。
这意味着主动推理的关键挑战——也可以说是一般数据分析的关键——是找到最佳解释可观察数据的生成模型(即最大化证据)。解决这个问题将使我们能够通过观察其行为来找到由代理人所涉及的生成模型。反过来,这将使我们能够在硅中准确地模拟其信念更新和行为。应当指出,可以手动指定这些生成模型,以便重现简单行为(例如,代理人执行简单任务以进行上述实证验证)。然而,解决这个问题的通用解决方案对于解释复杂数据集至关重要,特别是来自真实环境中的代理人的复杂行为数据。此外,对于这个问题的生物学合理解决方案可能对完整的结构学习路线图有所贡献;考虑生物代理人如何演变其生成模型以解释新的观察结果。通过选择具有良好感知数据模型的表型,进化已经解决了这个问题,因此,了解选择适合我们环境的生成模型的过程可能会对结构学习和数据分析产生重要进展。
发现与复杂行为对应的新生成模型将需要将当前的过程理论扩展到这些模型,以提供可测试的预测并在虚拟环境中复制观察到的行为。目前的过程理论无法容纳的学习和决策中使用的生成模型示例包括马尔可夫决策树(Jordan等,1998, 1997)和玻尔兹曼机(Ackley等,1985;Salakhutdinov & Hinton, 2012;Stone,2019)。
超越OpenAI,我们是认真的:几千步就能学习游戏玩法,参数是现有模型1%的新AGI
当将主动推理扩展到具有许多自由度的复杂模型时,可能会面临一个挑战,即考虑到策略树的大小。尽管当前的修剪策略是有效的和符合生物学的,但在这种情况下,减少搜索空间的策略可能不足以实现可行的推理。正如上面所指出的,将主动推理扩展到规模可能会产生变分自由能量公式的第一原则。具体而言,具有高证据的生成模型是最简单的。这表明,“扩展”,本身并不是复制更复杂或更深层次行为的正确策略。一个更有原则的方法是探索解释结构化行为所必需的正确类型的因子分解。这里的一个关键候选者是具有时间分离的深层时态或历时生成模型。这种因子分解(参见,平均场近似)用浅层次的决策树来替换层次组合的深层决策树。
总而言之,我们认为理论神经科学的一些重要挑战包括找到符合主动推理原则(Friston, 2019; Parr et al., 2020)的大脑功能过程理论;即,避免出现意外事件。然后,杰出的挑战是通过贝叶斯模型比较(例如,使用动态因果建模(Friston, 2012; Friston等,2003))来探索和细化这样的过程理论,与实验数据相关。从结构学习和数据分析的角度来看,主要挑战是找到与可用数据相关的具有最高证据的生成模型。这可能通过了解进化过程中选择的生物具有对其环境有良好模型的特征来实现。最后,要将主动推理扩展到具有许多自由度的行为,就需要了解生物在规划未来时如何有效地搜索深度策略树,以便在可分隔的时间尺度上考虑许多可能的策略。
11. Conclusion结论
总结而言,本文旨在概述:活跃推理的基本假设、支撑其过程理论的技术细节,以及相关的神经动力学如何与已知的生物学过程相关联。这些过程支持行动、感知、规划、决策、学习和结构学习;我们在离散状态空间生成模型下进行了阐述。我们讨论了一些重要的尚未解决的挑战:从广义上看,理论神经科学面临的挑战是发展越来越精细的大脑功能机制模型,使其符合活跃推理的核心原则。就过程理论而言,关键挑战涉及实验验证,了解生物体如何演化其生成模型以解释新的感觉观察结果,以及它们如何在规划未来时有效地搜索大型策略空间。
Software availability软件可用性

Appendix A. More complex generative models附录 A. 更复杂的生成模型
在本附录中,我们简要介绍了更复杂的情况离散状态空间生成模型并解释信念如何更新可以扩展到这些情况。
A.1. Learning B and D
在本文中,我们只考虑了 A 被学习的情况,而关于 B(即从一个状态到下一个状态的转移概率)和 D(即关于初始状态的信念)的信念保持不变。一般情况下,B 和 D 也可以随时间而学习。这需要一个新的(扩展的)表达式来描述具有关于 B 和 D 的先验的生成模型:
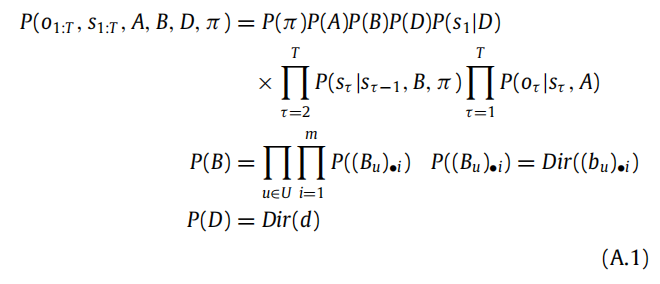
这里, (Bu)•i and (bu)•i ,它编码了从一个状态到下一个状态的转移概率,以及相应的 Dirichlet 参数 bu。此外,还需要定义相应的近似后验,用于学习:
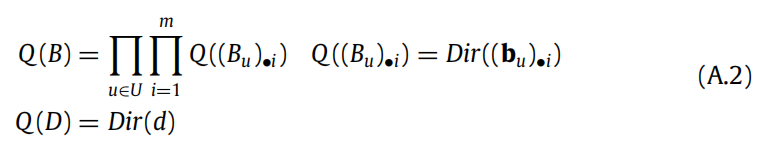
在观察了
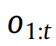
,之后,变分自由能的计算方式类似于方程(5)中的方法。然后,找到信念动态的过程类似于第8节 - 我们在下面重复说明:选取只依赖于 B 和 D 的变分自由能项。
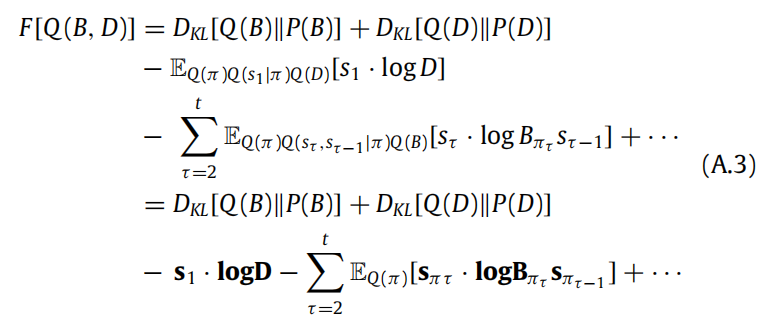
使用狄利克雷分布的 KL 散度形式(18) 并求梯度得到
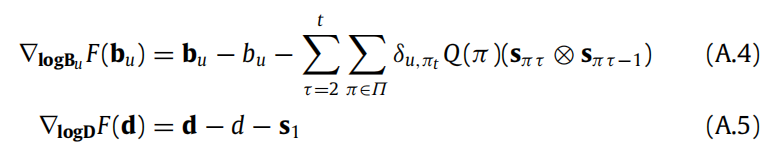
最后,可以指定神经可塑性动态,遵循(A.4)、(A.5)的下降,这对应于生物动态。或者,我们在每次观察周期结束后一次性实现信念更新规则,这适用于硅藻体代理。
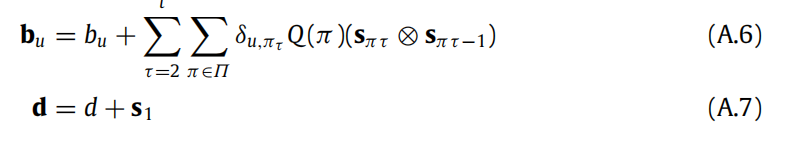
A.2. Complexifying the prior over policies
在本文中,我们考虑了一种简单的先验近似策略;即, σ(−G(π))。这可以扩展为 σ(−γ G(π)),其中γ是一个(逆)温度参数,表示选择特定策略的信心程度。从某种意义上说,这种扩展是很自然的,因为γ可以被解释为多巴胺输入的postsynaptic响应(FitzGerald, Dolan等人,2015;Friston等人,2014)。这种对应关系得到了经验证据的支持(Schwartenbeck,FitzGerald,Mathys,Dolan和Friston,2015),并使得能够模拟生物学上合理的多巴胺放电(参见附录E(Friston,FitzGerald等人,2017))。在解剖学上,这个参数可能被编码在黑质内,在黑质-纹状体多巴胺投射神经元中(Schwartenbeck,FitzGerald,Mathys,Dolan和Friston,2015),这与我们提出的功能解剖学相吻合(参见图5),因为黑质与纹状体相连。我们建议读者参考(Friston, FitzGerald等人,2017)以讨论相关的信念更新方案。
A.3. Multiple state and outcome modalities 多状态和结果模态
一般来说,我们不仅需要一个隐藏状态和结果因子来表示环境,而是需要多个。直观地说,这在人类大脑中发生,因为我们整合来自五个(或更多)不同感觉的感官刺激。从数学上讲,我们可以通过不同流的隐藏状态(通常称为隐藏因子)来表达这一点,这些隐藏状态相互独立地演变,相互作用以在每个时间步生成结果;例如,参见Jordan等人(1998年,图9)的一个多因素隐藏马尔可夫模型的图形表示。这意味着 A 变成了一个多维张量,集成了关于不同隐藏因子的信息以导致结果。在这种情况下,信念更新是类似的,取决于是否假设对不同隐藏状态因子的近似后验采用均场因子分解(参见,例如,Friston和Buzsáki,2016;Mirza等人,2016)。这意味着关于状态的信念可以以类似于图5的方式进行处理,调用更多的神经群体。
A.4. Deep temporal models深度时间模型
深度时间模型是具有许多层的生成模型,这些层嵌套层次结构,并在不同的时间尺度上起作用。这些模型最早在 Friston, Lin等人(2017年)的活跃推理中首次引入。我们可以将它们图形化地想象成一个POMDP(参见图2),在更高层次,每个结果都被一个POMDP所替代,并且依此类推。
有一个有用的隐喻可以帮助理解深度时间模型的概念:模型的每一层对应于时钟的一只指针。在一个两层的分层模型中,较快指针的滴答声(或旋转)对应于较低层次的一个时间步骤(或观察时期的试验)。在较低层次的每个试验结束时,较慢的指针会滴答一次,这对应于较高层次的一个时间步骤,然后该过程再次展开。可以简洁地总结说,较高层次的状态对应于较低层次的一个观察时期的试验。当然,在分层模型中堆叠层数没有限制。
为了获得相关的信念更新,我们通过使用来自更高层次的变量来条件化贝叶斯规则中的概率分布,计算较低层次的自由能。这意味着我们在较低层次独立于较高层次进行信念更新。然后,我们通过将较低层次视为结果来计算较高层次的变分自由能。有关该方案的具体细节,请参阅 Friston, Lin等人(2017年)。
附录 B. 感知背后的动态计算
在这里,我们详细说明了主文中感知动态的计算,特别是如何从(6)中获得(7)、(8)。在接下来的内容中,我们用 S = {σ1, . . . , σm} 表示状态空间。
B.1. 条件政策下的变分自由能(6):
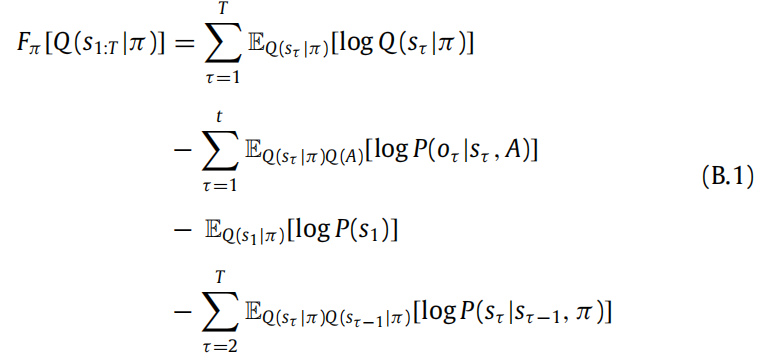



B.2. Free energy gradients
现在我们可以计算Fπ关于其任意参数sπ1, . . . , sπT . 的梯度。我们以sπt, t > 1,为例进行说明,其他情况类似。当计算梯度∇sπt Fπ ,在(B.4)中唯一不消失的项是那些依赖于 sπt 的项。利用矩阵和向量的微分规则(Petersen & Pedersen, 2012),我们得到(8)。
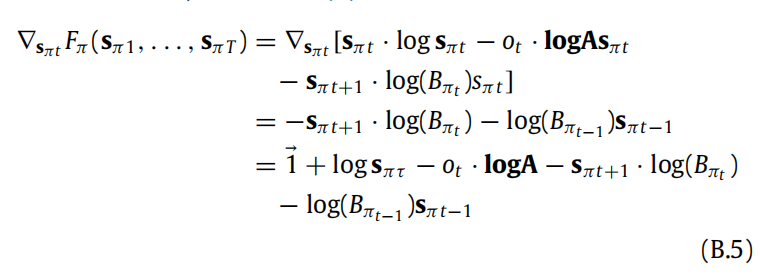
Appendix C. Expected free energy as reaching steady-state
在主动推理的核心是对一类在非平衡稳态下自组织的系统的描述(Friston, 2019; Parr et al., 2020)。这意味着存在一个稳态概率分布 P(sτ , A),只要给定足够的时间,代理就会达到这个稳态。直观地说,这个分布对应于代理对状态和模型参数的偏好。实际上,这意味着代理选择策略,使得其在未来某个时间点τ > t(通常是策略T的时间范围)的预测状态 Q(sτ , A) 与其由生成模型指定的偏好 P(sτ , A) 相匹配。
本附录的目的是从达到稳态的角度来解释预期自由能的定义。具体地,我们将展示一个分布族 Q(π),其中包括(负的softmax)预期自由能,可以保证达到稳态。
目标:我们寻找关于策略的分布,这些分布意味着稳态解;即,当最终分布不依赖于初始观察时。这些解确保,平均而言,随机策略导致稳态或由生成模型指定的目标分布。这些解存在于条件独立性之中,其中隐藏状态提供一个马尔可夫毯,将策略与结果分开。换句话说,策略导致最终状态,最终状态导致结果。

在这里,β ≥ 0 表征了稳态,其相对精度(即,负熵)由策略和最终结果给出的相对精度确定。生成模型规定了稳态,即最终状态(和结果)的分布不依赖于初始观察。在这里,生成和预测分布简单地表达了在给定最终状态的情况下策略和最终结果之间的条件独立性。注意,当β = 1 时,Gibbs 能量变成了期望自由能。
引理1的一个重要结论是,当(C.1)成立时,我们要么有DKL[Q(sτ , A)∥P(sτ , A)] = +∞ or DKL[Q(sτ ,A)∥P(sτ , A)] = 0,直观地说,
y, DKL[Q(sτ , A)∥P(sτ , A)] 无穷大意味着 Q(sτ , A) 相对于 P(sτ , A) 是奇异的。例如,当稳态密度位于无法通过的深渊的另一侧时,或者当Q(sτ , A) 和P(sτ , A). 不重叠时,就会出现这种情况。相反,要求DKL[Q(sτ , A)∥P(sτ , A)] 是有限的意味着
Q(sτ , A) 是绝对连续的相对于P(sτ , A),即在Q(sτ , A) > 0.时,P(sτ , A) > 0
引理1的证明。让我们解开在 Q 下的 Gibbs 能量的预期:


我们将推迟 Corollary 2 的证明到本附录的最后。分布族Q(π; β) h具有有趣的解释。例如,当β = 0 时对应于标准的随机控制,也称为 KL 控制或风险敏感控制(van den Broek 等,2010年):
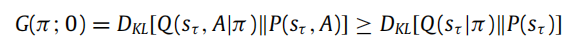
换句话说,最可能的策略使得预测分布和目标分布之间的 KL 散度最小化。更一般地,当 β > 0 时,策略更可能在同时最小化给定状态的结果熵。换句话说,β > 0 确保系统表现出漂泊行为。可以看出,在这种情况下,如果似然映射的熵相对于策略保持恒定,那么 KL 控制可能会出现。在主动推理中,我们目前假设 β = 1 以简化问题,然而,不同 β 值对行为的影响是有趣的,将在未来的研究中加以考察。
关于简单和一般稳态之间的区别,有一种观点是从对策略的不确定性角度来看待,策略可以被认为是系统采取的轨迹。例如,在简单稳态中,关于哪个策略导致了最终状态是没有不确定性的。例如,这对应于描述经典系统(遵循唯一最小作用路径的系统),在这种情况下,可以推断出采取了哪个策略,考虑到了初始和最终结果。相反,在一般稳态系统中(例如,老鼠、智人),仅仅知道“你在这里”并不告诉我“你是如何到达这里的”,即使我知道你今天早上在哪里。换句话说,对于实现一般稳态的系统来说,有许多路径或策略是开放的。
在主动推理中,我们对一类自组织到一般稳态的系统感兴趣;也就是说,那些从初始状态到最终稳态经历了大量概率配置的系统。Parr 等人(2020)和 Friston(2019)的论述有效地将稳态引理颠倒过来,假定稳态是约定性的真理,然后用贝叶斯最优策略来描述随后的自组织过程:如果一个系统达到了一般稳态,那么它看起来会以最佳的贝叶斯方式行动 - 在最佳的贝叶斯设计(即,探索)和贝叶斯决策理论(即,利用)方面。定义贝叶斯风险的损失函数是与代理所涉及的生成模型的负对数证据。简而言之,实现一般稳态的系统看起来就像是在响应认知机会。(Parr & Friston, 2017b).
备注 3. 通过考虑在未来一系列时间步骤(例如, τ1, . . . , τn > t.)中达到其偏好的系统,可以很容易地扩展这个附录。在这种情况下,可以调整引理 1 的证明来得到:
在(C.2)中将τ替换为τi i,其中G(π , τi; β)是 Gibbs 自由能。在这种情况下,关于策略的近似后验的规范选择将是:
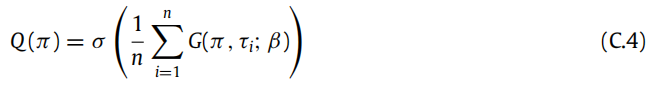
我们用 Corollary 2 的证明结束这个附录。



Appendix D. Computing expected free energy
在本附录中,我们呈现了用于spm_MDP_VB_X.m.中的预期自由能的解析表达式的推导过程。根据 Parr (2019),我们可以将预期自由能重新表达如下:
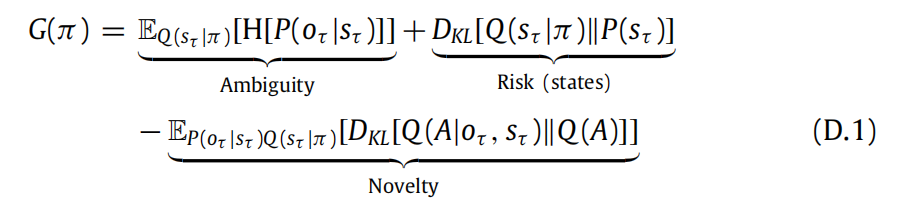
这里,Q(A|oτ , sτ ) 表示关于A的近似后验信念,如果我们知道状态-结果对(oτ , sτ ).的发生。接下来,我们将展示我们可以通过以下方式计算预期自由能:
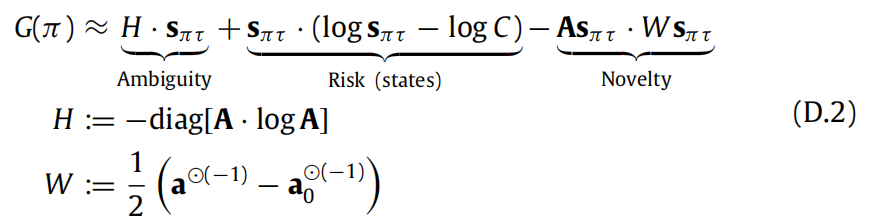
当代理人的偏好C用于对状态的偏好进行表达时。当偏好用于对结果进行表达时(如目前在spm_MDP_VB_X.m),中实现的),风险项会改变

D.1. Ambiguity
(D.1)中的歧义项是EQ(sτ |π)[H[P(oτ |sτ )]].根据定义,期望中的熵是:
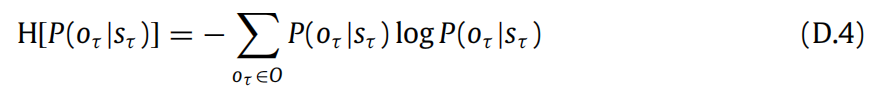
求和式中的第一个因子对应着:

在这里,我们已经将模型参数A的先验替换为近似后验Q(A)。这并不是必要的,但在数值模拟中,由于学习是在试验结束时进行的,这两者可以互换使用。此外,这样做还使我们可以重用先前引入的符号。无论如何,这告诉我们熵可以重新表达为:
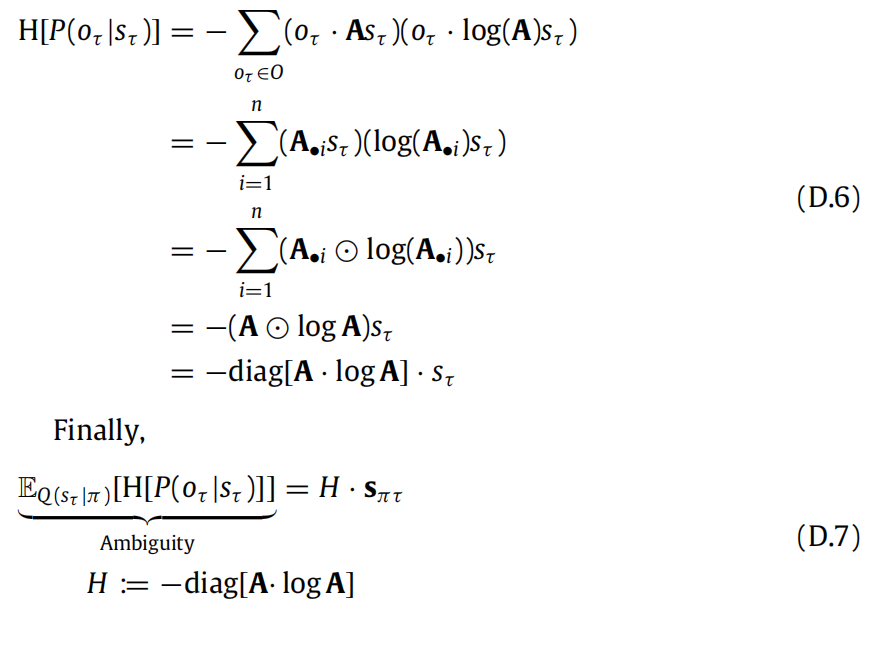
D.2. Risk
(D.1)中的风险项是跟随特定策略的预测状态与首选状态之间的KL散度。这可以表示为:
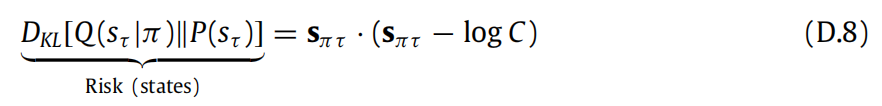

D.3. Novelty
(D.1)中的新颖性项是 EP(oτ |sτ )Q(sτ |π)[DKL[Q(A|oτ , sτ )∥Q(A)]],其中
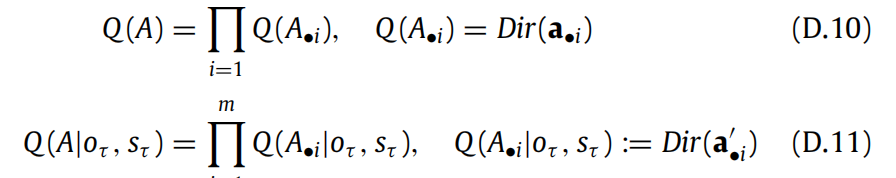
这两个分布之间的KL散度(见(18)式)可以表示为:
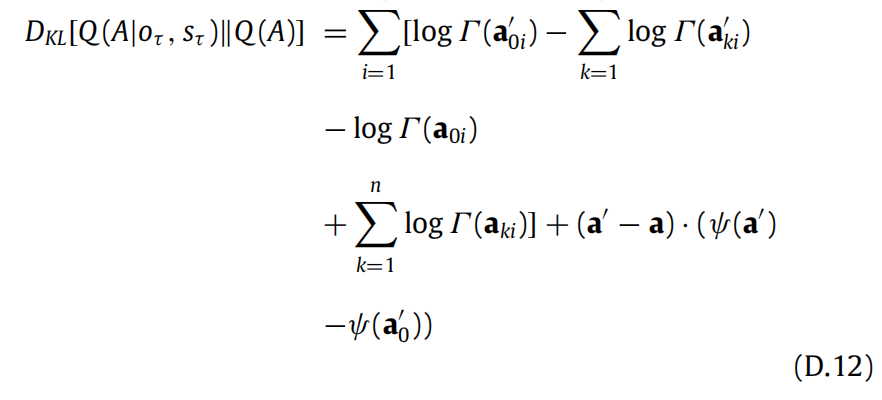


我们可以使用digamma函数的渐近展开来简化表达式:
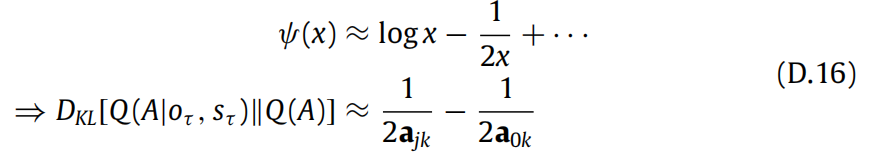
最后,新颖性项的解析表达式为:
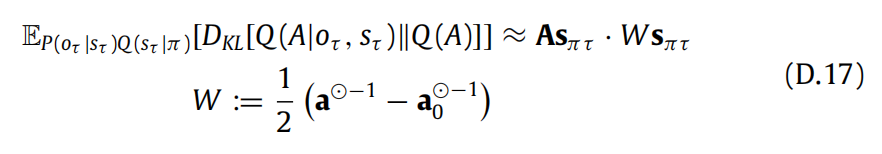
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-02-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号