安徽大学范存航、吕钊团队提出使用动态图自蒸馏方法实现基于EEG的高性能听觉注意检测

安徽大学范存航、吕钊团队提出使用动态图自蒸馏方法实现基于EEG的高性能听觉注意检测

脑机接口社区
发布于 2023-09-19 15:28:19
发布于 2023-09-19 15:28:19
安徽大学智能信息处理与人机交互实验室(IIP-HCI)的范存航副教授、吕钊教授联合清华大学的陶建华教授、中科院自动化所的易江燕副研究员,提出了一种基于动态图自蒸馏(DGSD)的听觉注意检测模型。

论文地址:
https://arxiv.org/abs/2309.07147
鸡尾酒会是一个有趣的场景,表现为多个说话人的声音混合在一起,就像在一场喧嚣的社交聚会上一样。这个场景的挑战在于,当多个声音源同时存在时,需要找到一种方法来分离和提取听者感兴趣的声音源,即目标说话人的声音。多人说话语音分离技术是解决以上问题的一种方法,该技术旨在将混合的声音信号分解成不同的声音源,使我们能够单独提取每个说话人的声音。然而,这些技术如果在没有目标说话人提前注册先验信息的情况下,无法进行目标说话人提取。
为了解决这个问题,听觉注意检测成为了一种非常有前景的解决方案。听觉注意检测旨在利用大脑信号来模拟人类听觉系统中的“注意力”过程。通过该技术,我们可以识别并定位在多人说话环境(即鸡尾酒会场景)中哪个说话人引起了听者的关注,即哪个说话人是当前的"目标"。

图1. 鸡尾酒会场景示意图(图片来自知乎)
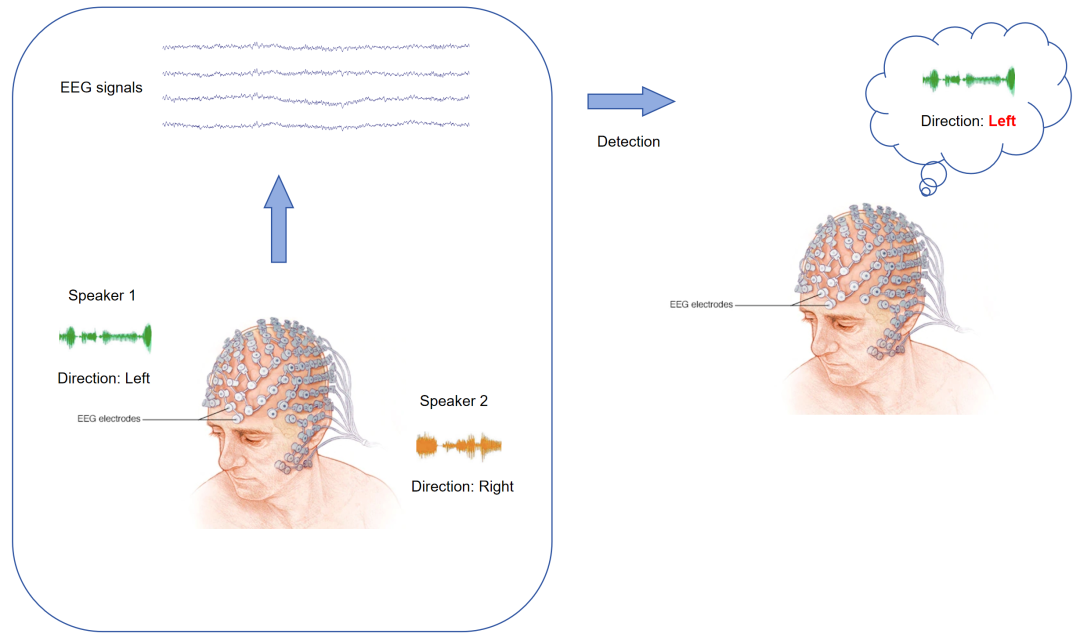
图2 听觉注意检测任务的双说话人范式
近年来,由于神经科学研究表明大脑通过非线性映射处理听觉刺激,传统的线性方法难以处理大脑中的非线性映射,并且随着时间窗口的缩短,解码性能显著下降。因此,研究逐渐转向基于EEG的非线性方法,其中卷积神经网络(Convolutional neural networks, CNN)是最常用的非线性方法。在进行听觉空间注意检测时,选择合适的脑电信号建模方法至关重要。
与欧几里得数据(如图像像素)不同,由于头皮上的测量位置不均匀以及电极之间的距离不同,EEG信号表现出非均匀采样。此外,在数据采集过程中,电极分散分布在头皮上,形成离散的电极网络,而不是连续的欧几里得空间。CNN不适合处理脑电信号的主要原因是,CNN的设计是为了处理欧几里德数据,在卷积核滑动过程中依赖像素之间的空间关系。然而,脑电信号的非均匀采样点和非欧几里得空间特征给有效地建立这种空间关系带来了挑战。
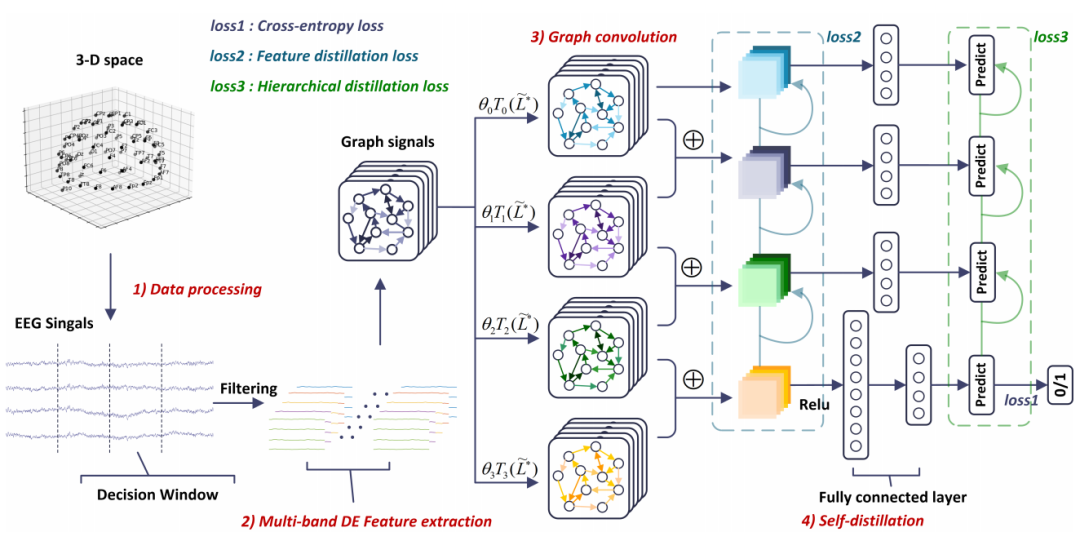
图3. 本文提出的基于EEG的动态图自蒸馏模型架构(简称DGSD)
与之相比,图结构可以自然地表示这些不均匀的连接,从而更好地捕捉不同电极之间的相互作用。它们不受固定网格结构的约束,更能适应脑电信号的特征,从而提供更准确的特征提取。
因此,为了更好地对EEG数据进行表示,研究团队提出了一种动态图自蒸馏模型(Dynamical graph self-distillation, DGSD)来进行高效的听觉注意检测,该模型使用动态图卷积网络(Dynamical graph convolutional networks, DGCN)来表示具有非欧几里得性质的EEG数据并提取有关听觉空间注意力的重要特征。此外,为了进一步提高听觉注意检测性能,研究团队结合了自蒸馏方法,该方法由每个DGCN层后的特征蒸馏和层次蒸馏组成,通过最深层网络所提取的特征和分类结果来指导浅层网络学习,进而提取到更适用于听觉注意检测任务的分类特征。
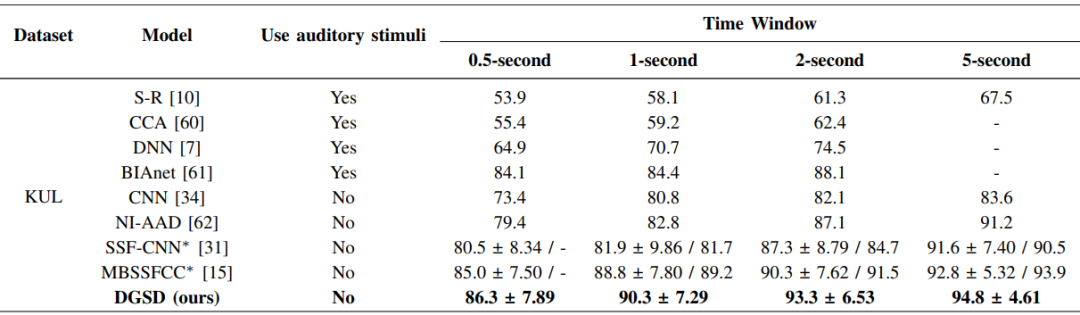
表1. 在KUL数据集上,不同模型在不同时间窗口下的检测精度。
为了评估动态图自蒸馏模型在高检测性能方面的有效性,研究团队进行了广泛的实验比较。该实验在两个公开的听觉注意检测数据集(KUL、DTU)上进行,实验结果表明,文中所提出的DGSD模型的检测精度在4个时间窗口(0.5秒、1秒、2秒、5秒)的检测精度均高于其他开源模型。
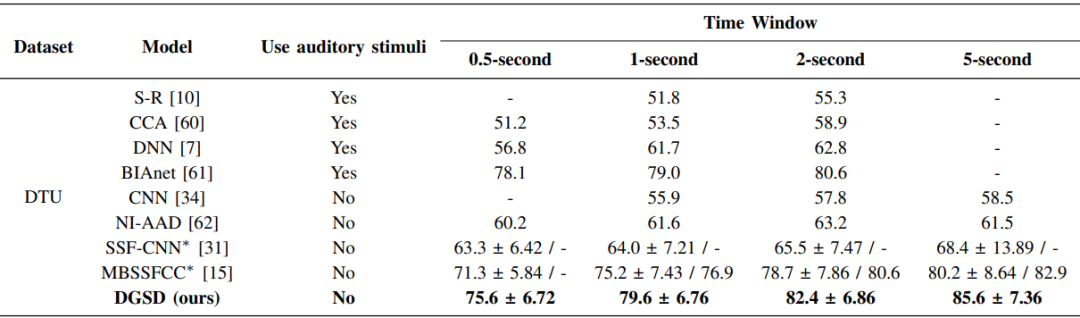
表2. 在DTU数据集上,不同模型在不同时间窗口下的检测精度。
此外,研究团队还在动态图卷积网络的基础上,对损失函数进行了消融研究,即在交叉熵损失作为主损失的条件下,进行了有关自蒸馏所含有的特征蒸馏损失和层次蒸馏损失的消融研究。实验结果表明,在两种损失按不同比例相互组合、相互补充的情况下,自蒸馏的效果达到最好,能够有效提升DGCN的检测精度。
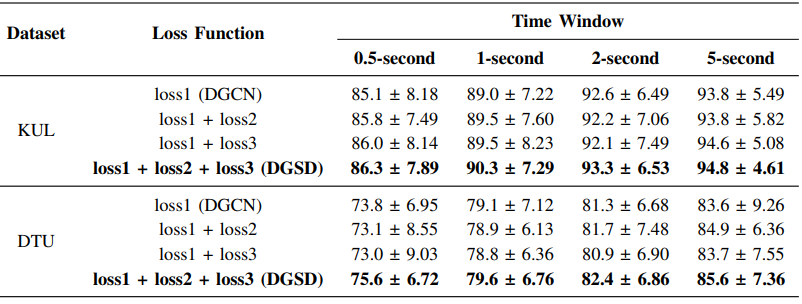
表3. 在KUL和DTU数据集上,不同时间窗口下对损失函数的消融研究获得的检测精度。
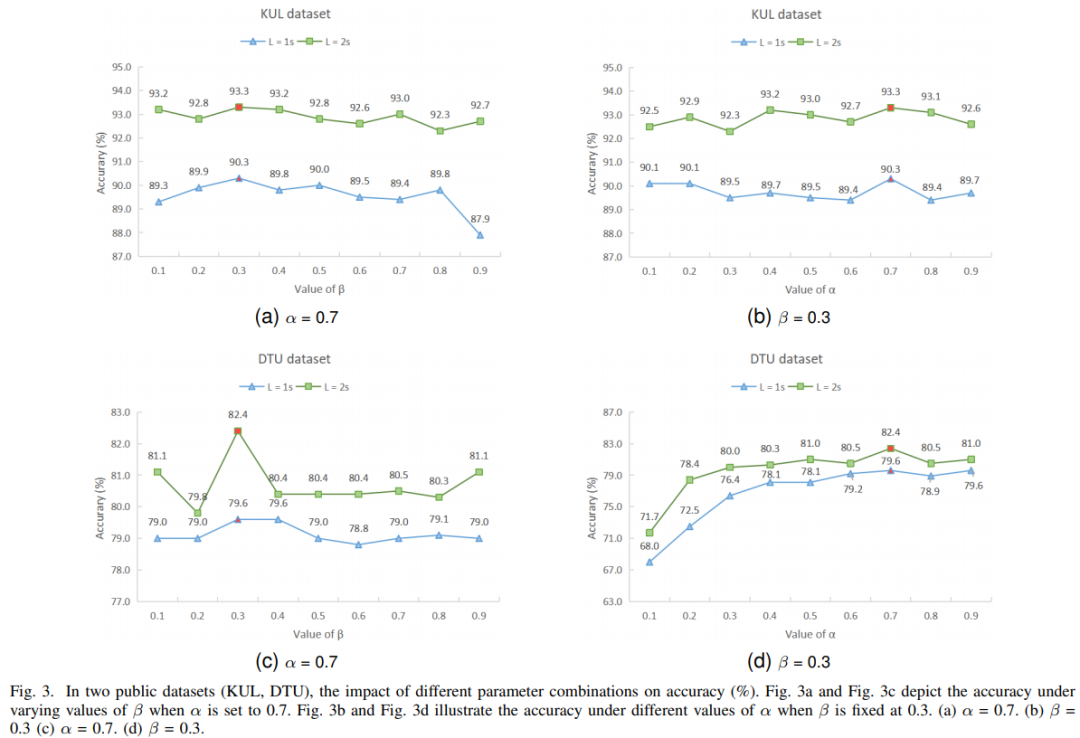
图4. 在两个公开数据集(KUL、DTU)中,不同参数组合对准确率的影响。
随后,研究团队还对所提出的DGSD模型和其他先进模型进行了可训练参数的比较,实验结果表明,所提方法不仅优于最先进可复现的听觉注意检测方法,而且可训练参数量显著减少了约100倍。
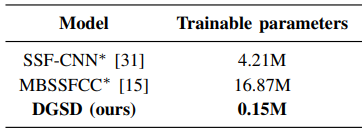
表4. DGSD模型和两个先进基线模型的可训练参数比较。
综上,本文提出了一种使用动态图自蒸馏进行基于EEG的听觉注意检测方法。该方法不需要听觉刺激作为输入,仅依靠脑电图信号进行听觉空间注意检测,使其在现实场景中更加实用。通过利用动态图卷积网络有效地对具有非欧几里得性质的EEG数据进行表示,进而从EEG数据中提取与听觉空间注意相关的关键特征信息。此外,通过与自蒸馏策略相结合,从而提升检测性能。实验结果表明,该方法不仅优于线性模型,而且优于先进可复现的非线性模型,同时可训练参数的数量减少了约100倍。研究团队认为,该方法增强了基于脑电图的听觉注意检测的性能,为未来各种听力设备的开发开辟了无限的可能性。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023/09/19 09:25:42,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号