手把手教学小型金融知识图谱构建:量化分析、图数据库neo4j、图算法、关系预测、命名实体识别、Cypher Cheetsheet详细教学等
原创
手把手教学小型金融知识图谱构建:量化分析、图数据库neo4j、图算法、关系预测、命名实体识别、Cypher Cheetsheet详细教学等
原创
汀丶人工智能
发布于 2023-07-08 11:05:42
发布于 2023-07-08 11:05:42
手把手教学小型金融知识图谱构建:量化分析、图数据库neo4j、图算法、关系预测、命名实体识别、Cypher Cheetsheet详细教学等
效果预览:
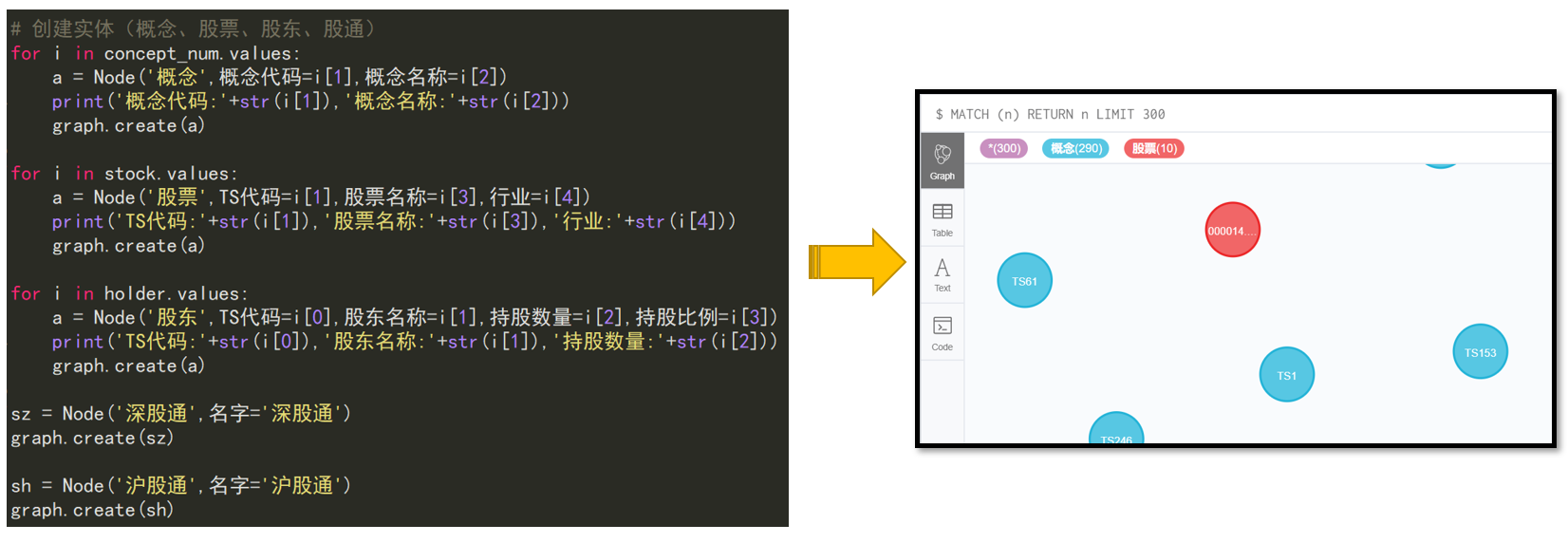
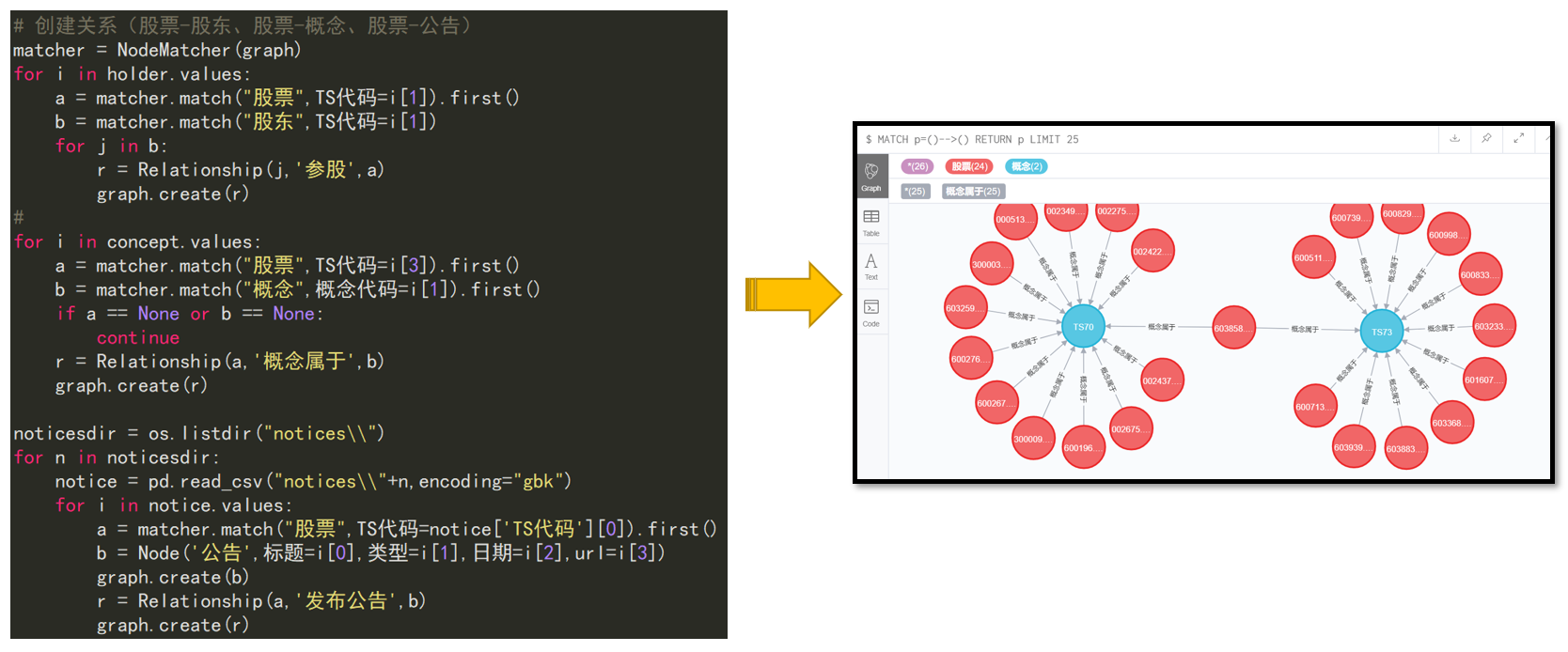

1. 知识图谱存储方式
知识图谱存储方式主要包含资源描述框架(Resource Description Framework,RDF)和图数据库(Graph Database)。
1.1 资源描述框架特性
- 存储为三元组(Triple)
- 标准的推理引擎
- W3C标准
- 易于发布数据
- 多数为学术界场景
1.2 图数据库特性
- 节点和关系均可以包含属性
- 没有标准的推理引擎
- 图的遍历效率高
- 事务管理
- 多数为工业界场景
码源链接见文末跳转
2. 图数据库neo4j
neo4j是一款NoSQL图数据库,具备高性能的读写可扩展性,基于高效的图形查询语言Cypher,更多介绍可访问neo4j官网,官网还提供了Online Sandbox实现快速上手体验。
2.1 软件下载
下载链接:https://neo4j.com/download-center/
2.2 启动登录
2.2.1 Windows
- 进入
neo4j目录
cd neo4j/bin
./neo4j start- 启动成功,终端出现如下提示即为启动成功
Starting Neo4j.Started neo4j (pid 30914). It is available at http://localhost:7474/ There may be a short delay until the server is ready.(1)访问页面:http://localhost:7474
(2)初始账户和密码均为neo4j(host类型选择bolt)
(3)输入旧密码并输入新密码:启动前注意本地已安装jdk(建议安装jdk version 11):https://www.oracle.com/java/technologies/javase-downloads.html
2.2.2 MacOS
执行 Add Local DBMS 后,再打开 Neo4j Browser即可
2.3 储备知识
在 neo4j 上执行 CRUD 时需要使用 Cypher 查询语言。
2.4 Windows安装时可能遇到问题及解决方法
- 问题:完成安装JDK1.8.0_261后,在启动
neo4j过程中出现了以下问题:
Unable to find any JVMs matching version "11"- 解决方案:提示安装
jdk 11 version,于是下载了jdk-11.0.8,Mac OS可通过ls -la /Library/Java/JavaVirtualMachines/查看已安装的jdk及版本信息。
3. 知识图谱数据准备
3.1 免费开源金融数据接口
Tushare免费账号可能无法拉取数据,可参考issues提供的股票数据获取方法:
3.1.1 Tushare
3.1.2 JointQuant
官网链接:https://www.joinquant.com/
3.1.3 导入模块
import tushare as ts # 参考Tushare官网提供的安装方式
import csv
import time
import pandas as pd
# 以下pro_api token可能已过期,可自行前往申请或者使用免费版本
pro = ts.pro_api('4340a981b3102106757287c11833fc14e310c4bacf8275f067c9b82d')3.2 数据预处理
3.2.1 股票基本信息
stock_basic = pro.stock_basic(list_status='L', fields='ts_code, symbol, name, industry')
# 重命名行,便于后面导入neo4j
basic_rename = {'ts_code': 'TS代码', 'symbol': '股票代码', 'name': '股票名称', 'industry': '行业'}
stock_basic.rename(columns=basic_rename, inplace=True)
# 保存为stock_basic.csv
stock_basic.to_csv('financial_data\\stock_basic.csv', encoding='gbk')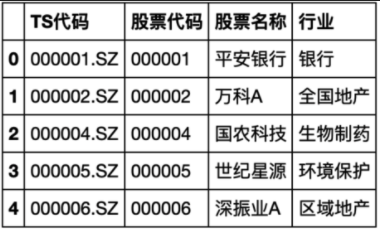
3.2.2 股票持有股东信息
holders = pd.DataFrame(columns=('ts_code', 'ann_date', 'end_date', 'holder_name', 'hold_amount', 'hold_ratio'))
# 获取一年内所有上市股票股东信息(可以获取一个报告期的)
for i in range(3610):
code = stock_basic['TS代码'].values[i]
holders = pro.top10_holders(ts_code=code, start_date='20180101', end_date='20181231')
holders = holders.append(holders)
if i % 600 == 0:
print(i)
time.sleep(0.4)# 数据接口限制
# 保存为stock_holders.csv
holders.to_csv('financial_data\\stock_holders.csv', encoding='gbk')
holders = pro.holders(ts_code='000001.SZ', start_date='20180101', end_date='20181231')
3.2.3 股票概念信息
concept_details = pd.DataFrame(columns=('id', 'concept_name', 'ts_code', 'name'))
for i in range(358):
id = 'TS' + str(i)
concept_detail = pro.concept_detail(id=id)
concept_details = concept_details.append(concept_detail)
time.sleep(0.4)
# 保存为concept_detail.csv
concept_details.to_csv('financial_data\\stock_concept.csv', encoding='gbk')
3.2.4 股票公告信息
for i in range(3610):
code = stock_basic['TS代码'].values[i]
notices = pro.anns(ts_code=code, start_date='20180101', end_date='20181231', year='2018')
notices.to_csv("financial_data\\notices\\"+str(code)+".csv",encoding='utf_8_sig',index=False)
notices = pro.anns(ts_code='000001.SZ', start_date='20180101', end_date='20181231', year='2018')
3.2.5 财经新闻信息
news = pro.news(src='sina', start_date='20180101', end_date='20181231')
news.to_csv("financial_data\\news.csv",encoding='utf_8_sig')
3.2.6 概念信息
concept = pro.concept()
concept.to_csv('financial_data\\concept.csv', encoding='gbk')
3.2.7 沪股通和深股通成分信息
#获取沪股通成分
sh = pro.hs_const(hs_type='SH')
sh.to_csv("financial_data\\sh.csv",index=False)
#获取深股通成分
sz = pro.hs_const(hs_type='SZ')
sz.to_csv("financial_data\\sz.csv",index=False)
3.2.8 股票价格信息
for i in range(3610):
code = stock_basic['TS代码'].values[i]
price = pro.query('daily', ts_code=code, start_date='20180101', end_date='20181231')
price.to_csv("financial_data\\price\\"+str(code)+".csv",index=False)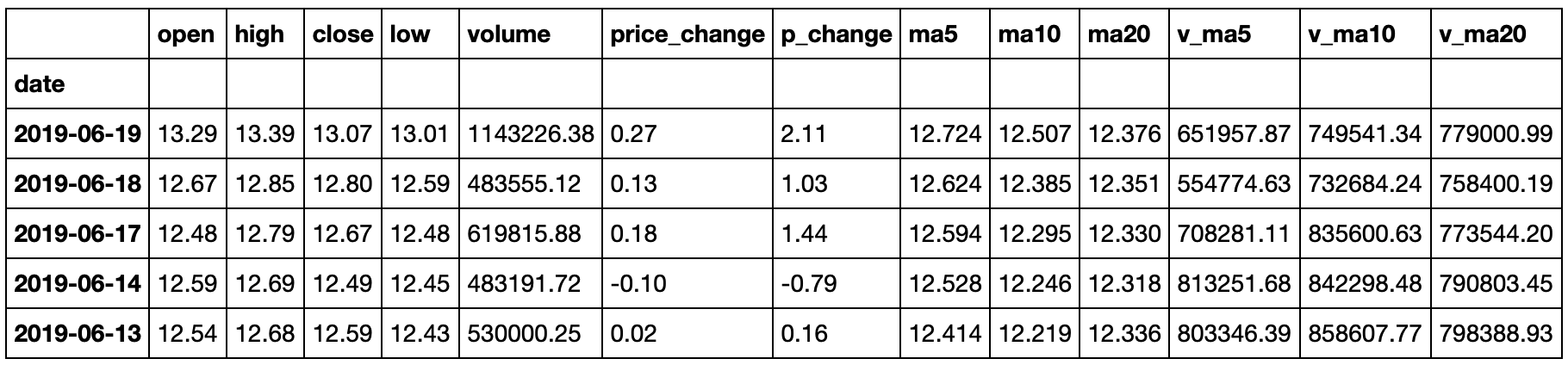
3.2.9 使用免费接口获取股票数据
import tushare as ts
# 基本面信息
df = ts.get_stock_basics()
# 公告信息
ts.get_notices("000001")
# 新浪股吧
ts.guba_sina()
# 历史价格数据
ts.get_hist_data("000001")
# 历史价格数据(周粒度)
ts.get_hist_data("000001",ktype="w")
# 历史价格数据(1分钟粒度)
ts.get_hist_data("000001",ktype="m")
# 历史价格数据(5分钟粒度)
ts.get_hist_data("000001",ktype="5")
# 指数数据(sh上证指数;sz深圳成指;hs300沪深300;sz50上证50;zxb中小板指数;cyb创业板指数)
ts.get_hist_data("cyb")
# 宏观数据(居民消费指数)
ts.get_cpi()
# 获取分笔数据
ts.get_tick_data('000001', date='2018-10-08', src='tt')3.3 数据预处理
3.3.1 统计股票的交易日量众数
import numpy as np
yaxis = list()
for i in listdir:
stock = pd.read_csv("financial_data\\price_logreturn\\"+i)
yaxis.append(len(stock['logreturn']))
counts = np.bincount(yaxis)
np.argmax(counts)3.3.2 计算股票对数收益
股票对数收益及皮尔逊相关系数的计算公式:
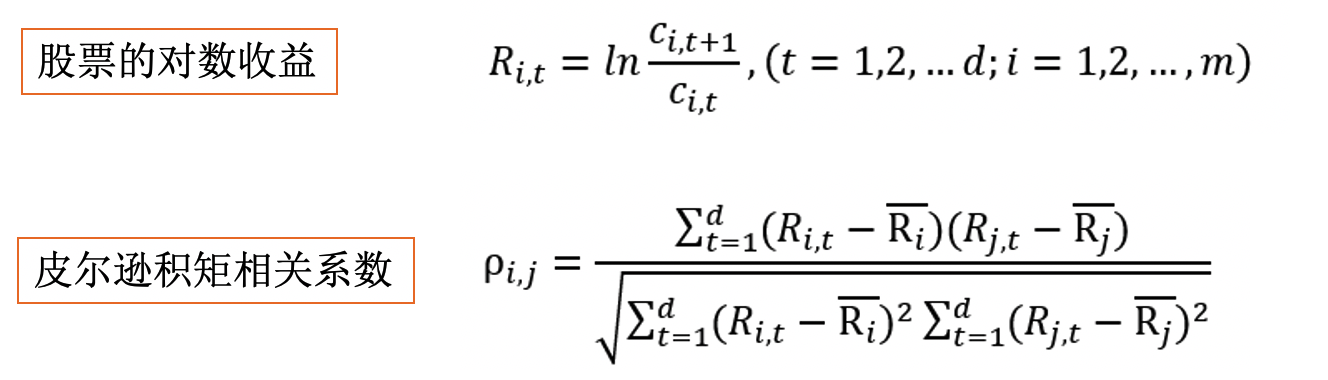
import pandas as pd
import numpy as np
import os
import math
listdir = os.listdir("financial_data\\price")
for l in listdir:
stock = pd.read_csv('financial_data\\price\\'+l)
stock['index'] = [1]* len(stock['close'])
stock['next_close'] = stock.groupby('index')['close'].shift(-1)
stock = stock.drop(index=stock.index[-1])
logreturn = list()
for i in stock.index:
logreturn.append(math.log(stock['next_close'][i]/stock['close'][i]))
stock['logreturn'] = logreturn
stock.to_csv("financial_data\\price_logreturn\\"+l,index=False)3.3.3 股票间对数收益率相关系数
from math import sqrt
def multipl(a,b):
sumofab=0.0
for i in range(len(a)):
temp=a[i]*b[i]
sumofab+=temp
return sumofab
def corrcoef(x,y):
n=len(x)
#求和
sum1=sum(x)
sum2=sum(y)
#求乘积之和
sumofxy=multipl(x,y)
#求平方和
sumofx2 = sum([pow(i,2) for i in x])
sumofy2 = sum([pow(j,2) for j in y])
num=sumofxy-(float(sum1)*float(sum2)/n)
#计算皮尔逊相关系数
den=sqrt((sumofx2-float(sum1**2)/n)*(sumofy2-float(sum2**2)/n))
return num/den由于原始数据达百万条,为节省计算量仅选取前300个股票进行关联性分析
listdir = os.listdir("financial_data\\300stock_logreturn")
s1 = list()
s2 = list()
corr = list()
for i in listdir:
for j in listdir:
stocka = pd.read_csv("financial_data\\300stock_logreturn\\"+i)
stockb = pd.read_csv("financial_data\\300stock_logreturn\\"+j)
if len(stocka['logreturn']) == 242 and len(stockb['logreturn']) == 242:
s1.append(str(i)[:10])
s2.append(str(j)[:10])
corr.append(corrcoef(stocka['logreturn'],stockb['logreturn']))
print(str(i)[:10],str(j)[:10],corrcoef(stocka['logreturn'],stockb['logreturn']))
corrdf = pd.DataFrame()
corrdf['s1'] = s1
corrdf['s2'] = s2
corrdf['corr'] = corr
corrdf.to_csv("financial_data\\corr.csv")4 搭建金融知识图谱
安装第三方库
pip install py2neo4.1 基于python连接
具体代码可参考3.1 python操作neo4j-连接
from pandas import DataFrame
from py2neo import Graph,Node,Relationship,NodeMatcher
import pandas as pd
import numpy as np
import os
# 连接Neo4j数据库
graph = Graph('http://localhost:7474/db/data/',username='neo4j',password='neo4j')4.2 读取数据
stock = pd.read_csv('stock_basic.csv',encoding="gbk")
holder = pd.read_csv('holders.csv')
concept_num = pd.read_csv('concept.csv')
concept = pd.read_csv('stock_concept.csv')
sh = pd.read_csv('sh.csv')
sz = pd.read_csv('sz.csv')
corr = pd.read_csv('corr.csv')4.3 填充和去重
stock['行业'] = stock['行业'].fillna('未知')
holder = holder.drop_duplicates(subset=None, keep='first', inplace=False)4.4 创建实体
概念、股票、股东、股通
sz = Node('深股通',名字='深股通')
graph.create(sz)
sh = Node('沪股通',名字='沪股通')
graph.create(sh)
for i in concept_num.values:
a = Node('概念',概念代码=i[1],概念名称=i[2])
print('概念代码:'+str(i[1]),'概念名称:'+str(i[2]))
graph.create(a)
for i in stock.values:
a = Node('股票',TS代码=i[1],股票名称=i[3],行业=i[4])
print('TS代码:'+str(i[1]),'股票名称:'+str(i[3]),'行业:'+str(i[4]))
graph.create(a)
for i in holder.values:
a = Node('股东',TS代码=i[0],股东名称=i[1],持股数量=i[2],持股比例=i[3])
print('TS代码:'+str(i[0]),'股东名称:'+str(i[1]),'持股数量:'+str(i[2]))
graph.create(a)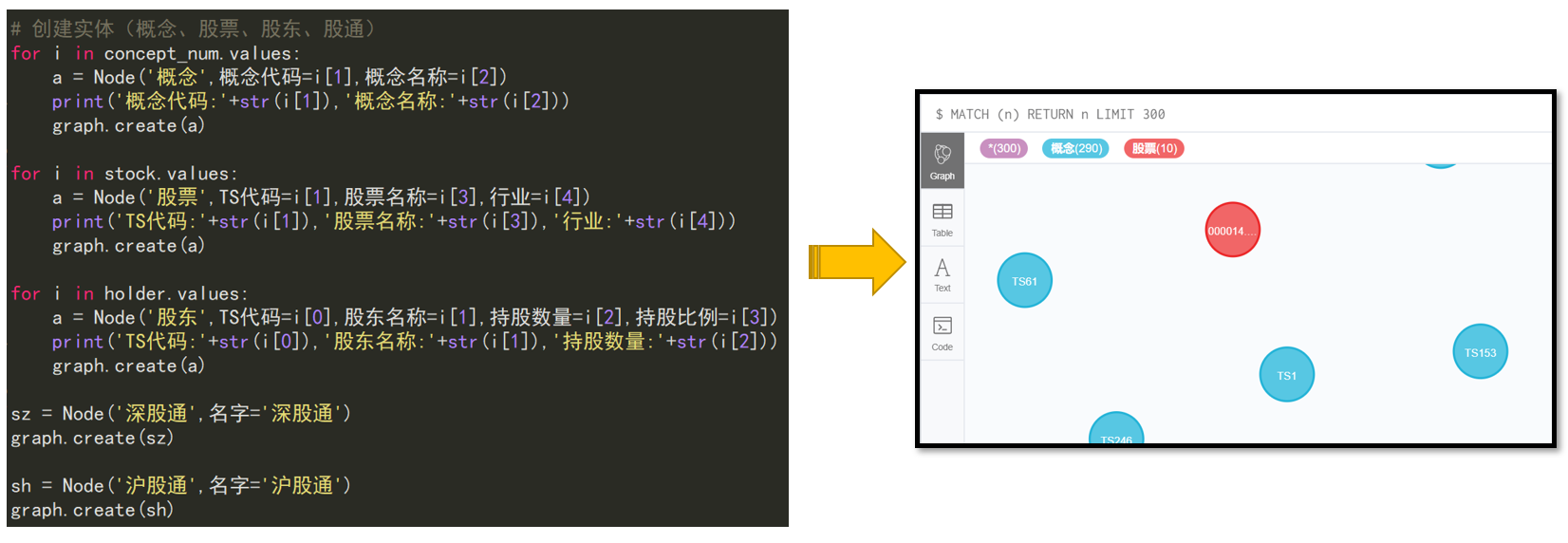
4.5 创建关系
股票-股东、股票-概念、股票-公告、股票-股通
matcher = NodeMatcher(graph)
for i in holder.values:
a = matcher.match("股票",TS代码=i[0]).first()
b = matcher.match("股东",TS代码=i[0])
for j in b:
r = Relationship(j,'参股',a)
graph.create(r)
print('TS',str(i[0]))
for i in concept.values:
a = matcher.match("股票",TS代码=i[3]).first()
b = matcher.match("概念",概念代码=i[1]).first()
if a == None or b == None:
continue
r = Relationship(a,'概念属于',b)
graph.create(r)
noticesdir = os.listdir("notices\\")
for n in noticesdir:
notice = pd.read_csv("notices\\"+n,encoding="utf_8_sig")
notice['content'] = notice['content'].fillna('空白')
for i in notice.values:
a = matcher.match("股票",TS代码=i[0]).first()
b = Node('公告',日期=i[1],标题=i[2],内容=i[3])
graph.create(b)
r = Relationship(a,'发布公告',b)
graph.create(r)
print(str(i[0]))
for i in sz.values:
a = matcher.match("股票",TS代码=i[0]).first()
b = matcher.match("深股通").first()
r = Relationship(a,'成分股属于',b)
graph.create(r)
print('TS代码:'+str(i[1]),'--深股通')
for i in sh.values:
a = matcher.match("股票",TS代码=i[0]).first()
b = matcher.match("沪股通").first()
r = Relationship(a,'成分股属于',b)
graph.create(r)
print('TS代码:'+str(i[1]),'--沪股通')
# 构建股票间关联
corr = pd.read_csv("corr.csv")
for i in corr.values:
a = matcher.match("股票",TS代码=i[1][:-1]).first()
b = matcher.match("股票",TS代码=i[2][:-1]).first()
r = Relationship(a,str(i[3]),b)
graph.create(r)
print(i)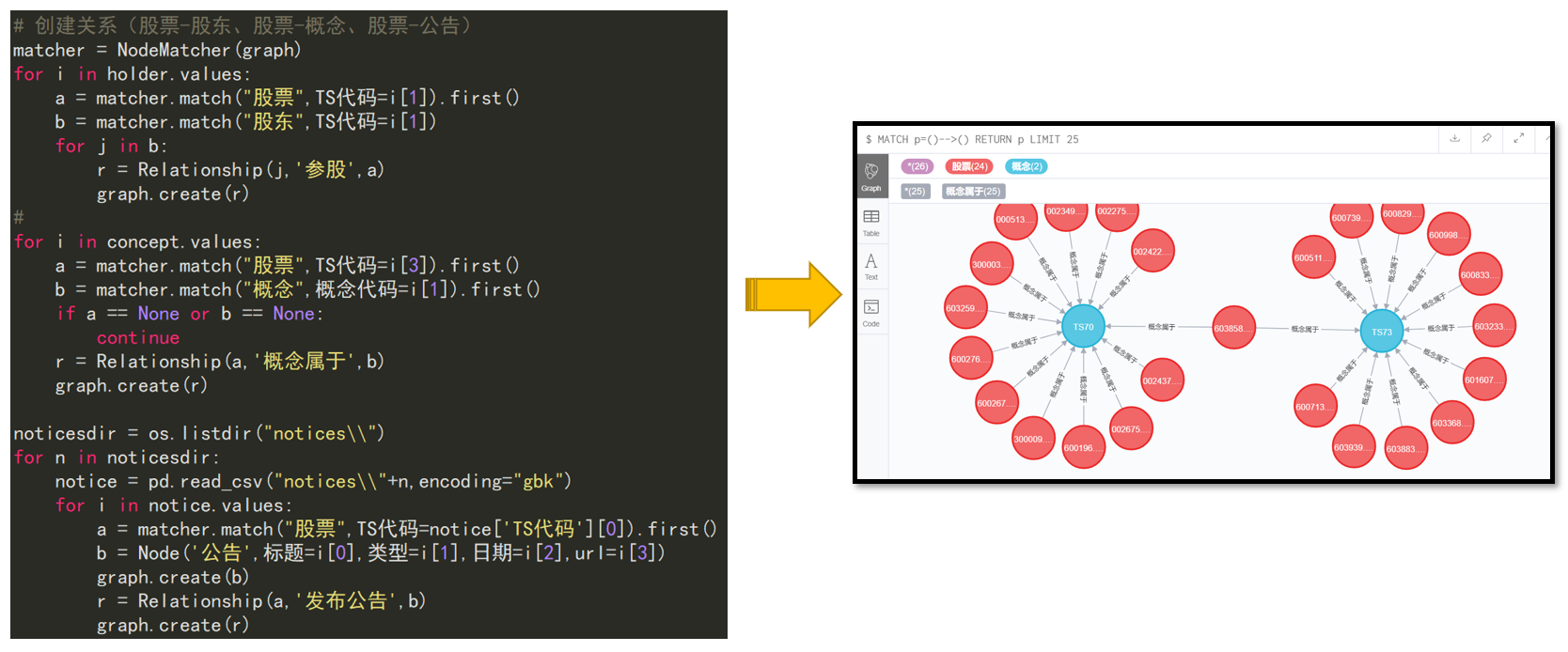
5 数据可视化查询
基于Crypher语言,以平安银行为例进行可视化查询。
5.1 查看所有关联实体
match p=(m)-[]->(n) where m.股票名称="平安银行" or n.股票名称="平安银行" return p;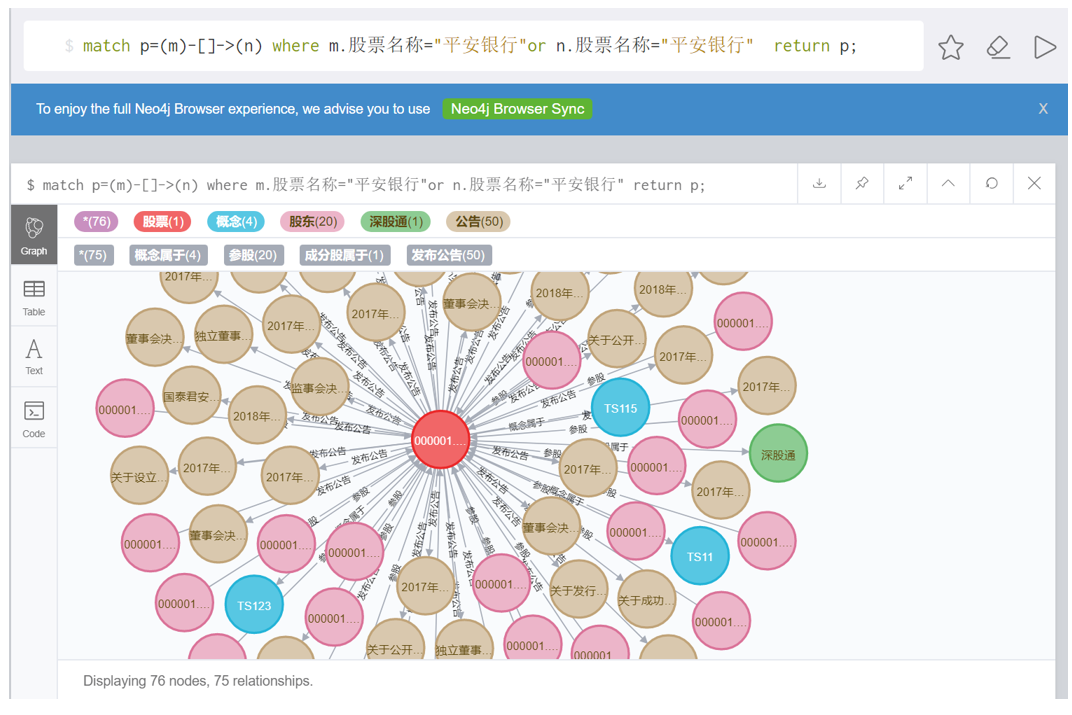
5.2 限制显示数量
计算股票间对数收益率的相关系数后,查看与平安银行股票相关联的实体
match p=(m)-[]->(n) where m.股票名称="平安银行" or n.股票名称="平安银行" return p limit 300;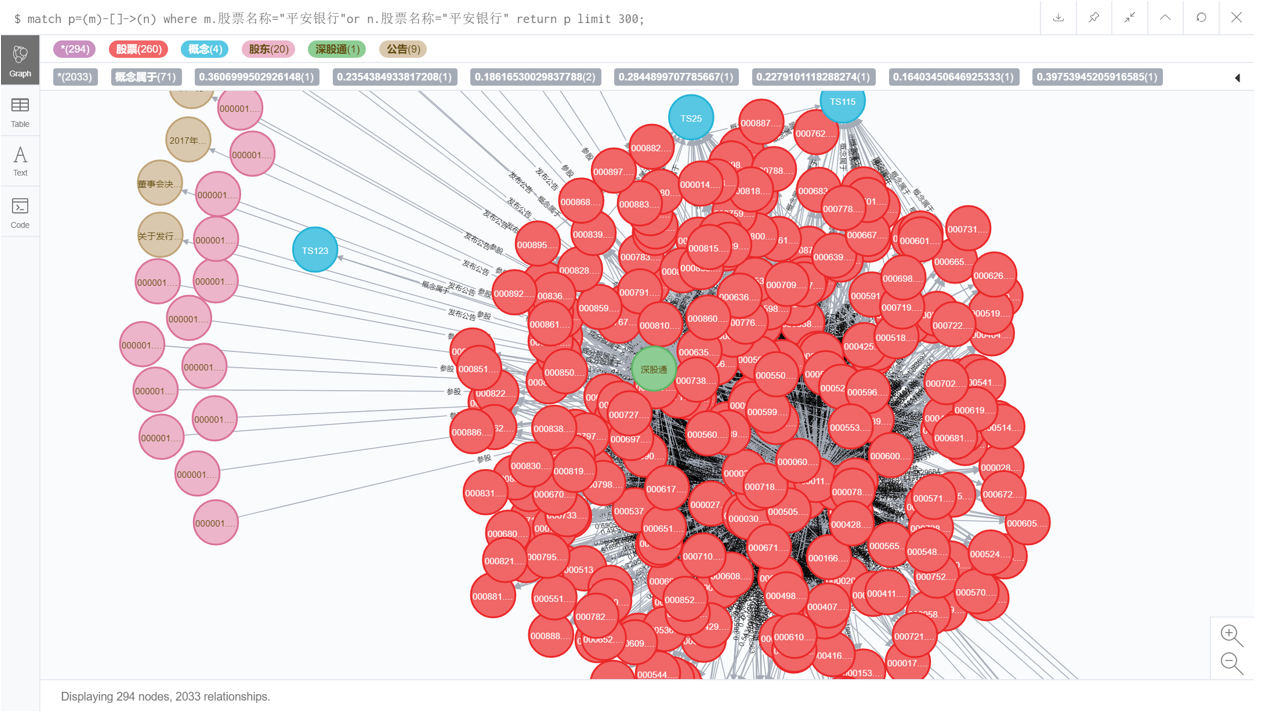
5.3 指定股票间对数收益率相关系数
match p=(m)-[]->(n) where m.股票名称="平安银行" and n.股票名称="万科A" return p;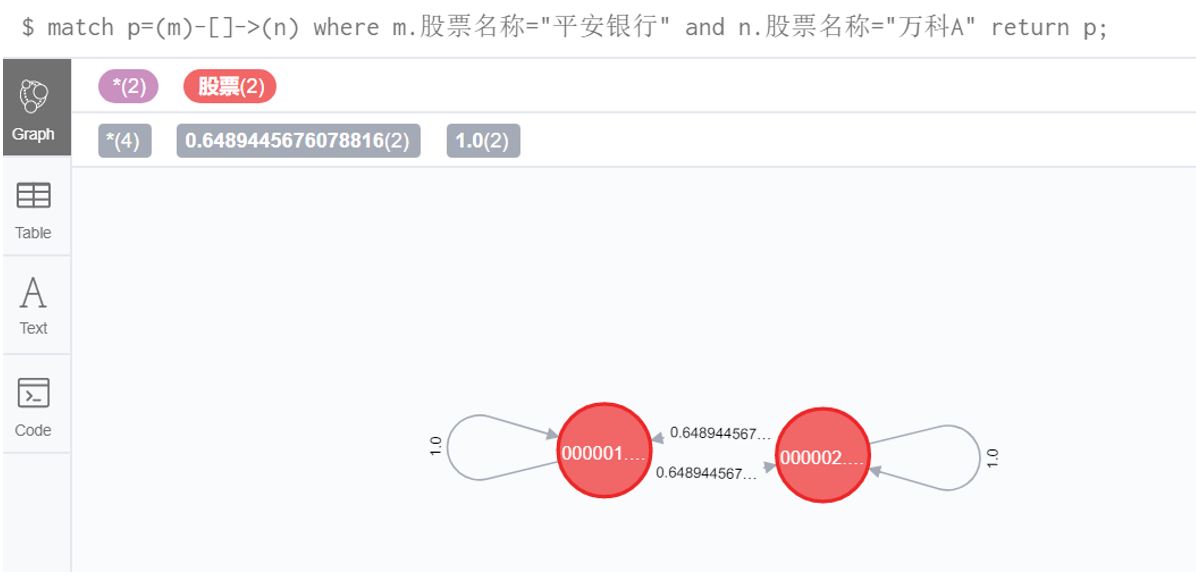
6 neo4j 图算法
6.1.中心度算法(Centralities)
- PageRank(页面排名)
- ArticleRank(文章排名)
- Betweenness Centrality (中介中心度)
- Closeness Centrality (接近中心度)
- Harmonic Centrality(谐波中心度)
6.2 社区检测算法(Community detection)
- Louvain (鲁汶算法)
- Label Propagation (标签传播)
- Connected Components (连通组件)
- Strongly Connected Components (强连通组件)((https://neo4j.com/docs/graph-algorithms/current/algorithms/strongly-connected-components/)
- Triangle Counting / Clustering Coefficient (三角计数/聚类系数)
6.3 路径搜索算法(Path finding)
- Minimum Weight Spanning Tree (最小权重生成树)
- Shortest Path (最短路径)
- Single Source Shortest Path (单源最短路径)
- All Pairs Shortest Path (全顶点对最短路径)
- A*(A星)
- Yen’s K-shortest Paths(Yen-K最短路径)
- Random Walk (随机游走)
6.4 相似性算法(Similarity)
- Jaccard Similarity (Jaccard相似度)
- Cosine Similarity (余弦相似度)
- Pearson Similarity (Pearson相似度)
- Euclidean Distance (欧氏距离)
- Overlap Similarity (重叠相似度)
6.5 链接预测(Link Prediction)
- Adamic Adar(AA)
- Common Neighbors(共同近邻)
- Preferential Attachment(优先连接)
- Resource Allocation(资源分配)
- Same Community(共同社区)
- Total Neighbors(近邻总数)
6.6 预处理算法(Preprocessing)
6.7 算法库安装及导入方法
以Windows OS为例,neo4j的算法库并非在安装包中提供,而需要下载算法包:
(1)下载graph-algorithms-algo-3.5.4.0.jar
(2)将graph-algorithms-algo-3.5.4.0.jar移动至neo4j数据库根目录下的plugin中
(3)修改neo4j数据库目录的conf中neo4j.conf,添加以下配置
dbms.security.procedures.unrestricted=algo.*(4)使用以下命令查看所有算法列表
CALL algo.list()6.8 算法实践——链路预测
6.8.1 Aaamic Adar algorithm
主要基于判断相邻的两个节点之间的亲密程度作为评判标准,2003年由Lada Adamic 和 Eytan Adar在 Friends and neighbors on the Web 提出,其中节点亲密度的计算公式如下:
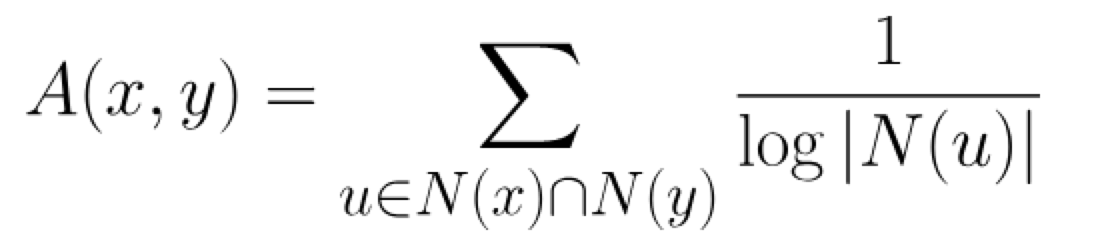
其中N(u)表示与节点u相邻的节点集合,若A(x,y)表示节点x和节点y不相邻,而该值若越大则紧密度为高。
AAA 算法 cypher 代码参考:
MERGE (zhen:Person {name: "Zhen"})
MERGE (praveena:Person {name: "Praveena"})
MERGE (michael:Person {name: "Michael"})
MERGE (arya:Person {name: "Arya"})
MERGE (karin:Person {name: "Karin"})
MERGE (zhen)-[:FRIENDS]-(arya)
MERGE (zhen)-[:FRIENDS]-(praveena)
MERGE (praveena)-[:WORKS_WITH]-(karin)
MERGE (praveena)-[:FRIENDS]-(michael)
MERGE (michael)-[:WORKS_WITH]-(karin)
MERGE (arya)-[:FRIENDS]-(karin)
// 计算 Michael 和 Karin 之间的亲密度
MATCH (p1:Person {name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.adamicAdar(p1, p2) AS score
// score: 0.910349
// 基于好友关系计算 Michael 和 Karin 之间的亲密度
MATCH (p1:Person {name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.adamicAdar(p1, p2, {relationshipQuery: "FRIENDS"}) AS score
// score: 0.0 6.8.2 Common Neighbors
基于节点之间共同近邻数量计算,计算公式如下:
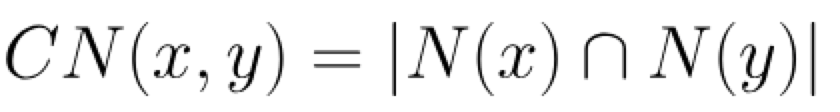
其中N(x)表示与节点x相邻的节点集合,共同近邻表示两个集合的交集,若CN(x,y)值越高,表示节点x和节点y的亲密度越高。
Common Neighbors算法 cypher 代码参考:
MATCH (p1:Person {name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.commonNeighbors(p1, p2) AS score6.8.3 Resource Allocation
资源分配算法,计算公式如下:
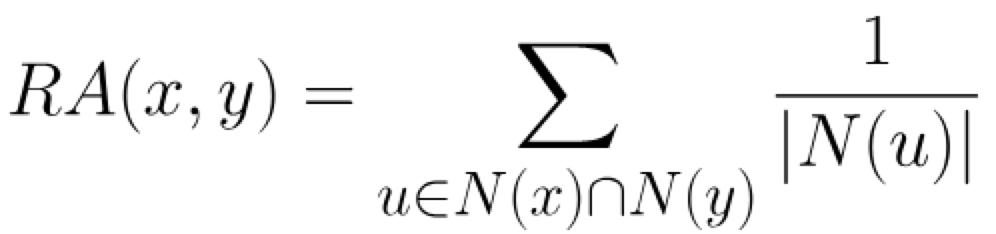
其中N(u)是与节点u相邻的节点集合,RA(x,y)越高表明节点x和节点y的亲密度越大。
Resource Allocation算法 cypher 代码参考:
MATCH (p1:Person {name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.resourceAllocation(p1, p2) AS score6.8.4 Total Neighbors
指的是相邻节点之间的邻居总数,计算公式如下:
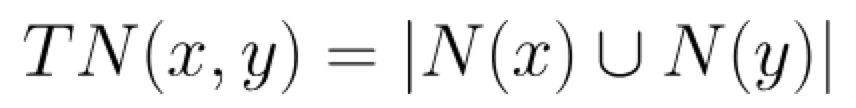
其中N(u)是与节点u相邻的节点集合。
Total Neighbors算法 cypher 代码参考:
MATCH (p1:Person {name: 'Michael'})
MATCH (p2:Person {name: 'Karin'})
RETURN algo.linkprediction.totalNeighbors(p1, p2) AS score官网文档>链路算法>介绍:https://neo4j.com/docs/graph-algorithms/3.5/labs-algorithms/linkprediction/
7.Cypher Cheetsheet基础语法
7.1 创建节点
类型为Person(属性:姓名、年龄及性别)
create (:Person{name:"Tom",age:18,sex:"male"})
create (:Person{name:"Jimmy",age:20,sex:"male"})7.2 创建关系
寻找2个Person类型节点分别姓名为Tom和Jimmy,创建两节点之间的关系:类型为Friend,关系值为best
match(p1:Person),(p2:Person)
where p1.name="Tom" and p2.name = "Jimmy"
create(p1) -[:Friend{relation:"best"}] ->(p2);7.3 创建索引
create index on :Person(name)
// 创建唯一索引(属性值唯一)
create constraint on (n:Person) assert n.name is unique7.4 删除节点
// 普通删除
match(p:Person_{name:"Jiimmy"}) delete p
match (a)-[r:knows]->(b) delete r,b
// 级联删除(即删除某个节点时会同时删除该节点的关系)
match (n{name: "Mary"}) detach delete n
// 删除所有节点
match (m) delete m7.5 删除关系
// 普通删除
match(p1:Person)-[r:Friend]-(p2:Person)
where p1.name="Jimmy" and p2.name="Tom"
delete r
// 删除所有关系
match p=()-[]-() delete p7.6 merge关键字
存在直接返回;不存在则新建并返回(通常实际用途于在对节点添加属性时避免报错)
// 创建/获取对象
merge (p:Person { name: "Jim1" }) return p;
// 创建/获取对象 + 设置属性值 + 返回属性值
merge (p:Person { name: "Koko" })
on create set p.time = timestamp()
return p.name, p.time
// 创建关系
match (a:Person {name: "Jim"}),(b:Person {name: "Tom"})
merge (a)-[r:friends]->(b)7.7 更新节点
7.7.1 更新属性值
match (n {name:'Jim'})
set n.name='Tom'
set n.age=20
return n7.7.2 新增属性和属性值
match (n {name:'Mary'}) set n += {age:20} return n7.7.3 删除属性值
match(n{name:'Tom'}) remove n.age return n7.7.4 更新节点类型(允许有多个标签)
①match (n{name:'Jim'}) set n:Person return n
②match (n{name:'Jim'}) set n:Person:Student return n7.8 匹配
7.8.1 限制节点类型和属性匹配
match (n:Person{name:"Jim"}) return n
match (n) where n.name = "Jim" return n
match (n:Person)-[:Realation]->(m:Person) where n.name = 'Mary'7.8.2 可选匹配(对于缺失部分使用Null代替)
optional match (n)-[r]->(m) return m7.8.3 字符串开头匹配
match (n) where n.name starts with 'J' return n7.8.4 字符串结尾匹配
match (n) where n.name ends with 'J' return n7.8.5 字符串包含匹配
match (n) where n.name contains with 'g' return n7.8.6 字符串排除匹配
match (n) where not n.name starts with 'J' return n7.8.7 正则匹配 =~(模糊匹配)
match (n) where n.name =~ '.*J.*' return n (等价) like '%J%'7.8.8 正则匹配 =~(不区分大小写)
match (n) where n.name =~ '(?i)b.*' return n (等价) like 'B/b%'7.8.9 属性值包含(IN)
match (n { name: 'Jim' }),(m) where m.name in ['Tom', 'Koo'] and (n)<--(m) return m7.8.10 "或"匹配(|)
match p=(n)-[:knows|:likes]->(m) return p7.8.11 任意节点和指定范围深度关系
match p=(n)-[*1..3]->(m) return p7.8.12 任意节点和指任意深度关系
match p=(n)-[*]->(m) return p7.8.13 去重返回
match (n) where n.ptype='book' return distinct n7.8.14 排序返回(desc降序;asc升序)
match (n) where n.ptype='book' return n order by n.price desc7.8.15 重命名返回
match (n) where n.ptype='book' return n.pname as name7.8.16 多重条件限制(with),即返回认识10人以上的张%
match (a)-[:knows]-(b)
where a.name =~ '张.*'
with a, count(b) as friends
where friends > 10
return a7.8.17 并集去重(union)
match (a)-[:knows]->(b) return b.name
union
match (a)-[:likes]->(b) eturn b.name7.8.18 并集不去重(union all)
match (a)-[:knows]->(b) return b.name
union all
match (a)-[:likes]->(b) eturn b.name7.8.19 查看节点属性/ID
match (p) where p.name = 'Jim'
return keys(p)/properties(p)/id(p)7.8.20 匹配分页返回
match (n) where n.name='John' return n skip 10 limit 107.9 读取文件
7.9.1 读取网络资源csv文件
load csv with header from 'url:[www.download.com/abc.csv](http://www.download.com/abc.csv)' as line
create (:Track{trackId:line.id,name:line.name,length:line.length})7.9.2 分批读取网络资源
例如 csv文件(default=1000)
using periodic commit (800)
load csv with header from 'url:[www.download.com/abc.csv](http://www.download.com/abc.csv)' as line
create (:Track{trackId:line.id,name:line.name,length:line.length})7.9.3 读取本地文件
load csv with headers from 'file:///00000.csv' as line
create (:Data{date:line['date'],open:line['open']})
(fieldterminator ';') //自定义分隔符7.9.4 注意事项
※ 本地csv文件必须是utf-8格式
※ 需要导入neo4j数据库目录的import目录下
※ 本地csv包含column必须添加with headers7.10 foreach关键字
- 个人小结
1.节点属性使用()
2.关系属性使用[]
3.where中使用"="
4.{}中使用":"
5.关系建立使用(m)-[:r]->(n)
6.正则使用"=~"
7.节点或者关系(/变量名:类型{属性名:属性值}/)
8.匹配关系时需要基于p=(m)-r->(n)返回p,而不是返回r(显示空)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号