交互式相机标定的高效位姿选择方法


标题:Efficient Pose Selection for Interactive Camera Calibration 作者:P. Rojtberg and A. Kuijper 会议:2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR) 论文:https://arxiv.org/abs/1907.04096 代码:https://github.com/paroj/pose_calib
摘要
平面图案标定姿势的选择很少被考虑——但标定精度很大程度上取决于它。本文提出了一种姿态选择方法,可以找到一个紧凑和鲁棒的标定姿态集,并适合于交互式标定。奇异的姿态会导致解决方案不可靠,而减少姿态的不确定度对标定有利的。为此,我们使用不确定性传播原理。
我们的方法利用了一个自识别的标定图案来实时跟踪相机的姿态。这允许迭代地引导用户到目标姿态,直到达到所需的质量水平。因此,只需要一组稀疏的关键帧来进行标定。
该方法在单独的训练集和测试集以及合成数据上进行了评估。我们的方法比可比较的解决方案性能更好,同时需要更少的30%的标定帧。
关键词:
- I.2.10:[人工智能]:视觉和场景理解——物理属性的建模和恢复;
- I.5.5:[ 模式识别]:部署——交互式系统;
01 引言

图1 使用9个选定的姿势和用户指导覆盖,投影到到右下角的相机。
因此,标定的任务不能由没有经验的用户来完成——即使是在该领域工作的研究人员也经常难以量化什么是良好的标定图像。
有一些研究对CCD成像平面与图案之间的夹角对估计误差的影响进行了研究:
- Triggs[13]将角扩散与焦距误差联系起来。他发现超过5°后误差会扩散。
- Sturm和Maybank[11]进一步区分了估计主点和焦距。更重要的是,他们讨论了在使用一个平面和两个平面进行标定时可能存在的奇点,并将它们与单个针孔参数联系起来;例如,如果图案在每一帧中平行于图像平面,则不能确定焦距。
这些发现在[16]中得到了重复。然而,姿态对失真参数估计或一般相机相对标定板的姿态影响迄今尚未被考虑。
另一个方面是标定数据的质量和数量。
- Sun和库珀斯托克[12]评估了摄像机模型对噪声的灵敏度、训练数据量和在模型复杂性方面的标定精度。然而,他们只测量了各自训练集上的残差,这受过拟合的影响。
- 为了克服这个问题,理查森等人[10]引入了最大期望重投影误差(最大ERE)度量,而不是与测试误差相关,从而允许一个有意义的收敛测试。此外,他们会自动计算一个“最佳的下一个姿势”,并将其作为图案的叠加投影作为用户指导。通过在大约60个候选姿态的固定集合中进行穷举搜索来选择姿态。对于每个姿态,执行一个包括该姿态的假设标定,并选择最大ERE最小的姿态。然而,候选姿态在视场中均匀分布,没有明确考虑角扩散和退化情况[11]。
在辅助用户标定任务[9]的一般情况下,尚未特别考虑相机标定的准确性。
我们提出在解析生成最优模式姿态的同时,明确地避免退化的姿态配置。为此,我们将姿态与单个参数的约束联系起来,这样所产生的姿态序列就可以约束所有的校准参数,并确保准确的校准。与[10]的穷举搜索相比,这将计算时间从秒减少到毫秒。
利用估计解的协方差来评估校准参数的不确定度。然后对姿态序列进行调整,以便为最不确定的参数捕获更多的约束。参数的协方差与检验误差相关,因此也可以作为一个收敛准则。
基于以上几点,我们的主要贡献是:
- 两种不同的姿态选择策略
- 一种有效的姿态选择方案
本文的结构如下:
- 第2节:介绍了所使用的相机模型和不确定度估计方法,并讨论了一个合适的标定图案的选择。
- 第3节:描述了我们的新的姿态选择方法
- 第4节:描述了完整的标定流程。
- 第5节:
- 对该方法在真实数据和合成数据进行了评估,并与OpenCV和AprilCal[10]的标定方法进行了比较[3]。
- 分析了结果标定的紧致性,并进行了一个非正式的用户调查,以显示该方法的可用性。
- 最后,我们以第6节总结了我们的结果,并讨论了其局限性和未来的工作。
02 准备工作
我们将使用针孔相机模型来描述相机,给定相机的旋转为 ,位置 ,参数向量 ,映射一个3D坐标点 到2D坐标像素点 :
其中:
- 是 的仿射变换
- 表示仿射变换之后的深度
- K:相机的标定矩阵包含焦距(和比例) 和主点:。Zhang[16]还包括一个倾斜参数——然而,对于CCD相机,可以安全地假设是零 [12,6]
- 将常用的[12]径向(2a)和切向(2b)透镜畸变(跟随[7])建模为:
其中:。
2.1 估计和误差分析
给定 幅图像,每个图像包含 个点对应,基础标定方法[16]使几何误差最小化:
其中:
- 是图像 中观测到的(噪声)二维点
- 是相应的三维目标点
公式(3)也被称为重投影误差,经常被用来评估标定的质量。然而,它==只测量残差,并且容易发生过拟合==。特别是,如果恰好使用 点对应,则 [文献6,章节7.1]。
然而,标定的实际目标是估计误差,即解与真实标签(未知的)之间的距离。理查森等人[10]提出最大ERE作为与估计误差相关的替代度量,也有相似的值范围(像素)。然而,它需要采样和重新投影当前的解决方案。然而,对于用户的指导和监测收敛性,只需要参数的相对误差。因此,==我们直接使用估计参数的方差 。特别是,我们使用离散指数来确保参数之间的可比性==。
给定图像点 的协方差,利用协方差的反向传输[文献6,章节5.2.3]得到:
其中:
- :雅可比矩阵
- :是未知数的向量
- :表示伪逆
- 由于缺乏先验知识,为了简单起见,我们假设图像点在每个坐标方向上的标准偏差为,因此,即:。
- == 的对角线项包含估计的 的方差。==
- == 已经在[16]的莱文堡-马夸特步中计算出来了。==
2.2 标定图案
我们的方法适用于任何平面标定目标,例如常见的棋盘和圆网格图案。然而,对于交互式用户指导,快速的板检测是至关重要的。因此,我们使用在OpenCV中实现的自识别ChArUco[5]图案。与经典棋盘相比,这节省了检测到的矩形对规范拓扑的耗时顺序。然而,我们也可以在这里使用任何最近开发的自我识别目标[1,2,4]。
图案大小被设置为 个方块,从而在每个捕获帧的棋盘关节上进行多达40次测量。这允许成功地完成初始化,即使没有检测到所有的标记,如第4.3节中所讨论的那样。
03 姿势选择
我们的方法的核心思想是明确地指定使用Zhang[16]的方法进行标定的单个关键帧。
在本节中,首先讨论了内参和标定板姿态的关系,我们将参数向量分为针孔和失真参数。对于每个参数组,我们然后给出我们的规则集,以生成一个最优姿态,同时显式地避免退化配置。
3.1 分离针孔和畸变参数
看公式1,我们可以看到, 和都应用于后投影,描述了二维到二维的映射。因此,我们可以考虑仅从一个均匀采样图像的板姿态来估计 。然而,由于内参和外参同时由[16]估计,不确定性增加。
引用:
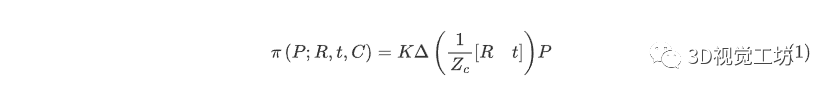
假设 单位矩阵 和失真参数为零,通过乘出(1),我们得到:
对于所有的图案点 。在这种情况下,两者之间有两个不确定的参数:
- 焦距 和 到相机的距离
- 平面内平移: 和主点
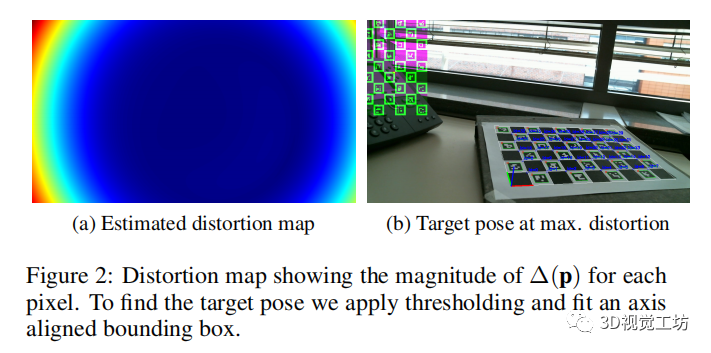
图2 失真图,显示了每个像素的∆(p)的大小。
为了找到目标姿态,我们应用阈值化和拟合一个轴对齐的边界框。
- 这些不确定性可以通过将标定图案 与 成像平面倾斜来解决,只有一个 满足公式1中所有图案点。
- 另一方面,考虑到 的失真参数,由于映射的非线性,不存在类似的不确定性。这些参数是由图像中明显的最大失真强度所决定的。在这里,更重要的是准确地测量相应图像区域的失真(见图 2a)。
于是,我们将参数向量 划分为,,,和、、、、,并分别考虑每一组。
3.2 避免针孔相机的奇异性
在优化中的参数时,必须避免奇异的姿态。除了上面讨论的案例外,我们还纳入了在[11]中确定的方法。特别是,我们限制了标定图案的三维配置如下:
- 标定图案不能平行于成像平面。
- 标定图案不能平行于其中一个图像轴。
- 给定两种模式,“反射约束”必须被充分满足。这意味着两个平面的消失线不是图像中沿水平线和垂直线的反射。
这些限制确保每个姿态都添加了进一步约束针孔相机的参数信息。
3.3 姿势生成
图3 示例性姿态选择状态。顶部:色散指数。
左:经过一个(洋红色)和两个(黄色)细分步骤后的固有标定候选位置。
右:已经访问过的区域的扭曲地图。
对于内参,我们遵循[13,16],其目标是最大化成像平面和标定板之间的角扩散。因此,生成的姿势如下:
- 我们选择一个距离,使整个标定板可见,最大限度地增加观察到的二维点的数量。
- 根据主轴(例如, 表示 ),标定板在围绕该轴的范围内倾斜。
- 实际的角度使用序列、、、、进行插值,它对应于(0;1)范围的二进制细分(见图3)。根据需要,这个策略可以使角度扩散最大化。
- 得到的姿态仍然平行于一个图像轴,这阻止了沿该轴[11]的主点的估计。因此,结果视图被旋转了22.5◦,这在保持主方向的同时实现了这一要求。
- 当确定,时,视图沿着各自的图像轴进一步移动了图像大小的5%。这增加了沿着该轴的扩散,并导致在我们的实验中实现更快的收敛。
对于失真参数 ,目标是提高显示出强畸变的图像区域的采样精度。为此,我们根据当前的标定估计生成一个失真图,以编码每个像素的位移。使用这张地图,我们搜索扭曲的区域如下:
- 设定失真图(图2a),找到失真最强的区域。
- 给定阈值图像,一个轴对齐的边界框(AABB)被拟合到该区域,对应于该模式上的一个平行视图。请注意,的约束在这里并不适用。
- AABB所覆盖的区域被排除在后续搜索之外(见图3)。有效地,扭曲的区域因此按扭曲强度的顺序被访问。
- 该图案与AABB的左上角对齐,并位于一个深度s.t。它的投影覆盖了图像宽度的33%。
我们设置了上述的角范围和宽度限制,以便使用罗技C525相机可以可靠地检测到标定板。
3.4 初始化
底层标定方法[16]需要至少两个初始解决方案的模式视图,我们选择如下:
- 对于参数,选择了一个在x周围倾斜45°的姿态(见第3.3节)。这个特殊的角度是由[16]提出的,它位于焦距不能确定的极值0°和长宽比和主点不能确定的90°之间。
- 在没有任何先验知识的情况下,我们的目标是通过统一抽样来估计。为此,我们计算一个姿态,使图案平行于图像平面,并覆盖整个视图。虽然这违反了姿态的轴对齐要求,但它仍然提供了额外的信息,因为它不是与第一个姿态[16]共面的。进一步满足了反射约束。
为了在不了解使用相机的情况下渲染第一个姿态的精确叠加,我们采用了类似于[10]的引导策略;如果我们可以检测到标定板,我们只进行单帧标定估计焦距—主点固定在中心,设置为零。
04 标定过程
在下面,我们将介绍参数细化和用户指导部分以及任何使用的启发式方法。这就完成了用于真实数据实验的标定流程。
4.1 参数优化
在使用两个关键帧获得一个初始解后,其目标是使估计的参数:累积的方差 最小化,我们通过一次针对单个参数的方差来解决这个问题。这里我们选择离散指数最高(MaxIOD)的参数:当且仅当。根据参数组,然后生成如第3节中所述的姿态。
为了确定收敛性,我们使用参数方差 的比率检验。如果减少的 低于给出的阈值,我们假设该参数是收敛的,并排除了它的进一步细化。在这里,我们只考虑来自同一组的参数,因为在互补组中通常只有很少的减少。一旦所有参数C都收敛了,标定就会终止。
根据初始化方法选择前两个姿态。姿势2-10和11-20是通过互补的策略来选择的。对罗技C525相机周围的20个相机模型的合成图像进行评估。
4.2 用户指导
为了指导用户,目标相机姿态投影使用当前估计的内在参数。然后,这个投影被显示为一个覆盖在直播视频流的顶部(参见图1和补充材料中的视频)。
验证用户是否足够接近目标姿态我们使用Jaccard指数J(A,B)(交集联合)计算的投影模式的目标姿态T和面积的投影从当前姿态估计e我们假设用户已经达到所需的姿态如果J(T,E)>0.8。
比较投影重叠而不是直接使用估计的姿态是更稳健的,因为姿态估计通常是不可靠的——特别是在初始化期间。
4.3 启发法
在整个过程中,我们强制执行通用启发式约束[6,7.2],即约束的数量应该超过未知数的5倍。所使用的校准方法[16]不仅估计了固有参数C,而且还估计了模型平面和图像平面的相对姿态,即参数R、三维旋转和t、三维平移。当使用M校准图像时,我们有d=9+6M未知数,每个点对应提供了两个约束。对于初始化(M=2),我们有21个未知数,这意味着总共需要52.5个点对应或每帧需要27个对应。对于任何后续的帧,只需要15个点。
为了防止由于运动模糊和滚动快门伪影而导致的不准确的测量,图案应该是静止的。为了确保这一点,我们要求在连续的帧中重新检测到所有的点,并且这些点的平均运动要小于1.5px(根据经验确定)。
05 评估
在合成数据和真实数据上对该方法进行了评价。合成实验旨在验证第3节中提出的参数分割和姿态生成规则,并使用真实数据与其他方法进行比较。此外,通过对测试集进行直接优化,估计了结果与真实数据的紧致性。
5.1 合成数据
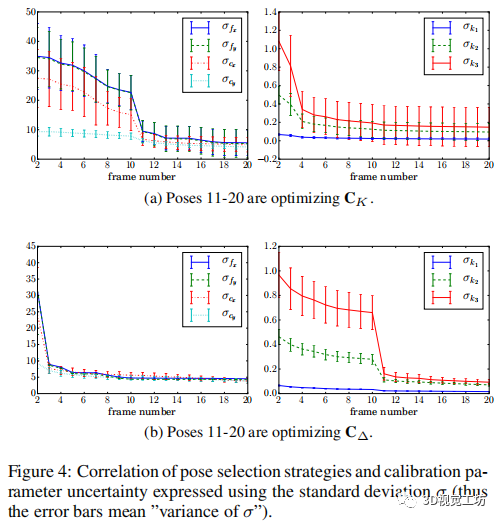
图4 姿态选择策略和校准参数不确定性的相关性(因此误差条意味着“σ的方差”)
相机参数是基于罗技C525相机 的校准参数。然而,实际参数在周围使用协方差矩阵进行抽样,允许每个参数有10%的偏差:
因此,每个合成校准对应于使用一个不同的相机与已知的真实标签参数。为了推广到不同的相机模型,我们保留了上述姿态生成序列,但使用了20个不同的相机C。
图4显示了各参数的平均标准差σC。值得注意的是,如果使用与参数组匹配的姿态,σ值会显著下降。
我们还评估了MaxIOD作为误差度量的使用,通过比较其与MaxERE[10]和已知估计误差的。与MaxERE一样,MaxIOD与集合相关(见图5a)。此外,如图5b所示,IOD的减少适用于平衡校准质量和所需的校准帧的数量。
5.2 真实数据
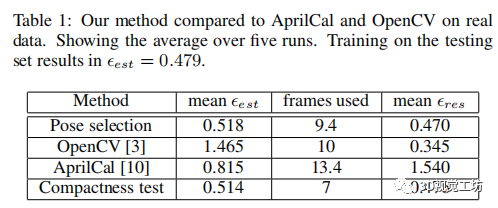

我们使用了第2.2节中描述的模式,该模式为OpenCV和我们的方法提供了每帧40个测量值。在AprilCal中,我们使用了5x7的AprilTag目标,它产生了大致相同的测量量。
我们的方法的收敛阈值设置为10%,AprilCal的停止精度参数设置为2.0。由于OpenCV方法不提供收敛性监测,我们在这里的10帧后停止了校准。
表1显示了每种方法5次校准运行的平均结果,测量所需的帧数和。在这里,我们的方法只需要AprilCal所需要的70%的帧,而达到比值低36% (比OpenCV低64%)。
5.3 标定紧致度的分析
前一节的结果表明,我们的方法能够提供最低的校准误差,同时使用更少的校准帧比可比方法的校准误差。然而,目前还不清楚该解决方案是使用最小的帧量,还是有可能在达到相同的校准错误的同时使用帧的子集。
因此,我们进一步测试了我们的校准结果的紧致性。我们使用了一个贪婪算法,给定由我们的方法捕获的一组帧,试图找到一个更小的子集。它优化了测试集,直接最小化了估计误差。
算法计算如下:给定一组训练图像(校准序列):
- 无条件地添加如第3.4节中所述的初始化帧;
- 现在将剩余的每个帧单独添加到关键帧集中,并计算校准。
- 对于每个校准,使用测试帧计算估计误差。
- 使值最小化的帧被合并到关键帧集中。在步骤2中继续。
- 如果不能进一步减少或所有帧都已被使用,则终止。
在保持相同估计误差的情况下,贪婪最优解需要75%的帧,同时(见表1)。这表明,虽然比[10]有了显著的改进,但我们的方法在紧性意义上还不是最优的。贪心算法需要一个先验记录的测试集,并且只找到现有校准序列的最小子集,但不能生成任何校准姿态。
5.4 用户调查
我们在5名同事中进行了一项非正式的调查,以测量在使用我们的方法时所需的校准时间。该工具是第一次使用,唯一给定的指令是覆盖应该与校准模式匹配。照相机是固定的,标定板必须被移动。用户平均需要1:33分钟才能以最高的捕获8.7帧。
06 结论和未来的工作
我们提出了一种校准方法来生成一组紧凑的校准框架,适合于交互式用户指导。避免了奇异的姿态配置,从而捕获约9个关键帧就足以进行精确的校准。这比可比的解决方案少了30%。所提供的用户指导允许没有经验的用户在2分钟内完成校准。校准精度可以根据收敛阈值与所需的校准时间进行加权。摄像机参数的不确定性在整个过程中都被监测,以确保可以反复达到给定的置信水平。
我们的评估表明,所需的帧的数量仍然可以减少,以进一步加快这个过程。我们只使用一个广泛而简单的失真模型,在未来的工作中需要考虑薄棱镜[15]、径向[8]和倾斜传感器。最终,我们可以加入对未使用的参数的检测。这将允许从最复杂的失真模型开始,它可以在校准过程中逐渐减少。
此外,该方法需要适应特殊情况,如显微镜,其中视野深度限制可能的校准角度或在大距离的校准,因此缩放标定板是不需要的。
该算法的基于OpenCV的实现是开源的:https://github.com/paroj/pose_calib.
07 参考文献


本文仅做学术分享,如有侵权,请联系删文。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-08-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号