
TI-OCR 训练平台
TI-OCR 训练平台有什么产品功能?
数据管理
提供数据导入、数据生成、生成素材管理、数据预览、数据搜索等功能;支持客户依据训练、测试的不同用途细化分组数据;由数据中心统一纳管建模数据集,实现对客户数据全生命周期的管理。
数据标注
提供便捷的标注作业台,支持智能标注和辅助标注提高人工标注效率,支持智能标注检查提高人工标注质量;提供腾讯自研的“描述子”标注语言灵活适配嵌套 key-value、多层级 key、表格等复杂的 OCR 场景。
模型训练
提供不同场景下的内置预训练模型,支持客户通过简易的参数配置一键启动自定义训练任务;提供经过优化的易读的训练报错日志;针对训练完得到的模型,提供性能评测报告以及支持模型的继续迭代优化。
应用编排
提供可自由组合模型 PPL 的应用编排,客户可依据自定义业务场景组装不同模型得到应用工作流;支持一键发布应用为测试服务,通过可视化接口调用模拟服务正式上线的效果;支持应用+后处理规则一起导出镜像给客户去部署正式服务。
应用评测
提供可自由组合模型 PPL 的应用编排,客户可依据自定义业务场景组装不同模型得到应用工作流;支持一键发布应用为测试服务,通过可视化接口调用模拟服务正式上线的效果;支持应用+后处理规则一起导出镜像给客户去部署正式服务。
管理中心
提供平台成员、平台项目、以及项目资源的增/删/改/查等管理功能;平台通过项目的维度隔离数据和资源;支持展示当前平台上运行中、排队中的所有训练/评测/服务测试的任务清单,以及查看平台操作日志等功能。
TI-OCR 训练平台有什么产品优势?
覆盖 100+ 业务场景
一站式 TI-OCR 训练平台能覆盖客户如表单、回单、提单、票据、证件、海运单据、托管对账单等100+的 OCR 业务场景。
解决业务难点痛点
助力客户轻松解决 OCR 领域下的两大核心问题:
图像干扰:如勾选、手写、背景、印章、打印偏移等;
复杂关系,如混合版式、表格结构化、多层级关系、勾选框提取、易混淆字段提取、无Key字段提取等。
算法重磅优势
平台内置训练算法:
大规模多模态预训练模型,涵盖CV 信息、语义信息、布局信息、知识图谱信息;
角度感知文本检测模型:涵盖多角度、多方向、任意文本形状;
语义融合高精度识别模型:结合图像信息及语义信息提供更高精度。
小样本模型训练
针对智能结构化的场景,平台内置模型可达到泛化准确率90%以上的指标(实验数据仅供参考);仅需5张样本再次训练即可达到95%以上的准确率指标(实验数据仅供参考)。
零代码应用编排
客户通过可视化前端页面即可排列组合业务应用所需的不同槽位下的模型;编排完成的应用还支持发布快速测试服务,供客户体验应用效果。
部署运维简单
仅三个核心服务即可运行平台;仅依赖 docker 容器环境,无需 k8s 底座;仅依赖 MySQL 和本地硬盘作为存储,不强制依赖 NAS/CSP 等共享存储组件。
TI-OCR 训练平台有什么应用场景?
智能结构化
业务场景:实现各类表单、票据、证件、单据等的结构化信息提取。
客户价值:帮助客户进行纸质表单关键字段的自动化录入,有效提升流程效率和录入信息准确度。
平台能力:从单一版式或混合版式的图片中提取出Key 字段、Value字段,以及Key-Value的键值对关系。
示例场景1:混合版式

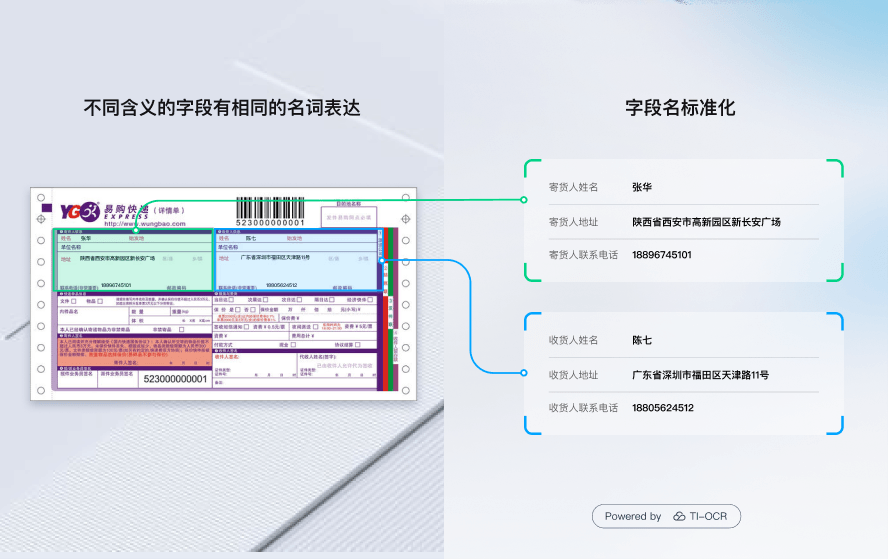
示例场景2:字段名标准化

示例场景3:字段嵌套

示例场景4:表格结构化

固定版式结构化
业务场景:实现如大陆二代身份证、机动车登记证、四六级成绩单等单一固定版式类型的信息提取。
客户价值:帮助客户自动识别出文本的指定字段信息,实现快速提取业务字段便于业务审核。
平台能力:为客户内置了固定版式的字段位置、字段类别提取的预训练模型供客户定制训练。
示例场景1:个人证件

示例场景2:证书执照

检测/识别
业务场景:实现各类表单、票据、证件、单据等的包含手写体、印刷体、中英文的文字提取。
客户价值:帮助客户实现业务信息快速电子录入。
平台能力:为客户内置了框位置检测、信息识别提取模型。
解决常见检测痛点

解决常见识别痛点

智能分拣
业务场景:即通用目标检测,检测出图片中物体所在的框位置及其所属类别。
客户价值:帮助客户公司如报销系统,自动识别混贴的报销单据类别。
平台能力:为客户内置了票据类型检测并分类的预训练模型供客户定制训练。
示例场景:混贴票据

- 腾讯云 TI-OCR 训练平台与 OCR 大模型解决方案概览
- 腾讯云 TI-OCR 训练平台与 OCR 大模型解决方案概要
- 腾讯云 TI-OCR 训练平台:OCR 大模型解决方案核心技术与商业价值解析
- 提效50%!华福证券用上「大模型」,和传统开户模式说拜拜
- 腾讯云智能AI产品概要
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号