
Claude-Mem:给 AI 编程助手装上"长期记忆"
## 写在前面 你是不是也遇到过这种情况:昨天用 Claude Code 写了一段复杂业务逻辑,今天重新打开项目,AI 助手却像失忆了一样,完全不记得你们讨论过什么,只能从头再解释一遍? 这个痛点,Claude-Mem 给出了解决方案——一个专为 Claude Code 打造的持久化记忆系统,让 AI 助手真正记住你们的每一次协作。 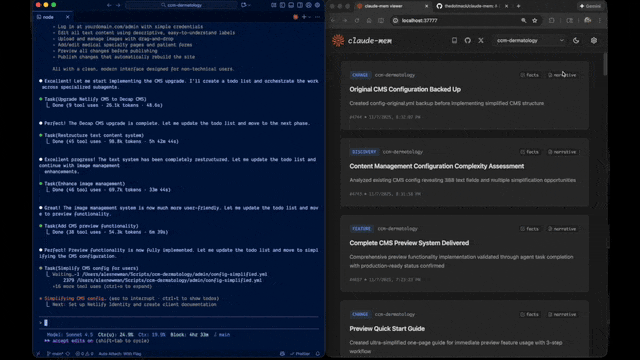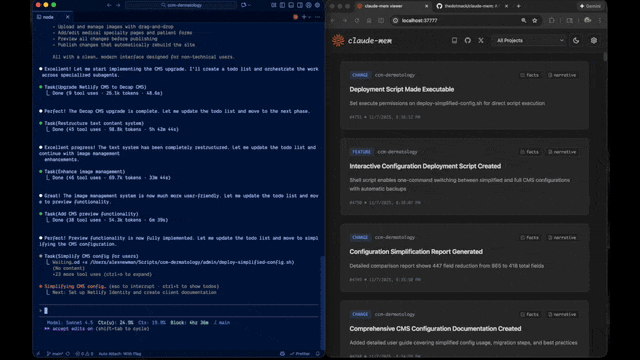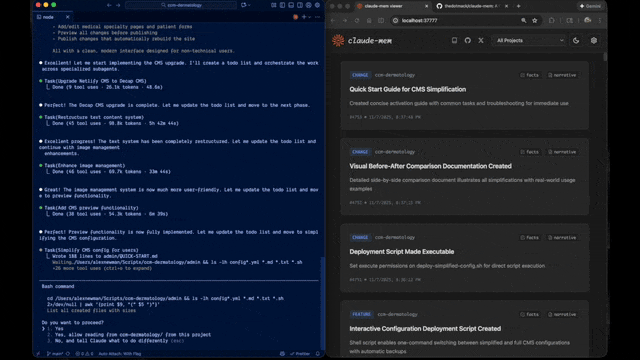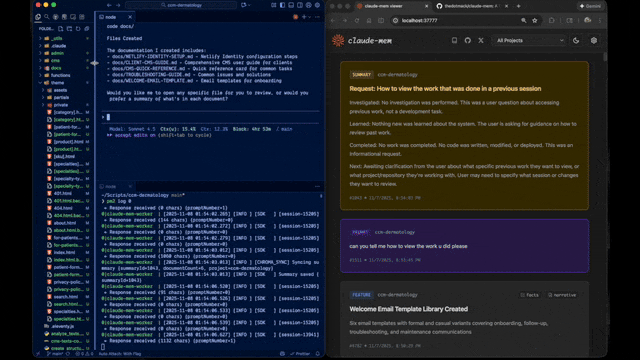 * * * ## 它到底解决了什么问题 传统的 AI 编程助手每次启动都是"全新的大脑",无法跨会话保留项目上下文。Claude-Mem 通过自动捕获、AI 压缩、智能检索三个步骤,实现了: - ✅ **跨会话记忆保持**:自动记录所有工具调用和代码操作 - ✅ **智能内容压缩**:用 Claude Agent SDK 将冗长对话压缩成精炼摘要 - ✅ **按需精准检索**:通过自然语言查询历史记忆,大幅节省 Token 成本 * * * ## 技术架构解析 **核心组件构成** ``` 系统架构: ├── 钩子系统(7 个生命周期钩子) ├── Worker 服务(HTTP API + Web UI) ├── 存储层(SQLite FTS5 + Chroma 向量库) └── PM2 进程管理 ``` **主要技术栈**: - **Node.js + TypeScript**:插件主体实现 - **SQLite FTS5**:全文检索引擎 - **Chroma Vector DB**:语义向量搜索 - **Claude Agent SDK**:AI 压缩核心能力 * * * ## 工作原理拆解 **五大生命周期钩子** Claude-Mem 采用观察者模式,在不干扰主会话的前提下,通过钩子捕获关键事件: | 钩子名称 | 触发时机 | 核心作用 | | ------------ | ----- | -------------- | | context-hook | 会话启动时 | 注入最近记忆作为上下文 | | new-hook | 用户提问时 | 创建新会话并保存提示词 | | save-hook | 工具执行后 | 捕获文件读写等操作记录 | | summary-hook | 会话结束时 | 生成 AI 摘要并持久化存储 | | cleanup-hook | 停止指令时 | 清理临时数据 | **渐进式披露策略** 这是 Claude-Mem 最巧妙的设计——不是一股脑把所有历史记录塞给 AI,而是分层展示: ``` Level 1: 最近 3 条会话摘要(约 500 tokens) Level 2: 相关观察记录(用户主动查询) Level 3: 完整历史检索(mem-search 技能) ``` 这种策略借鉴了前端开发中的懒加载思想,在云栈社区的技术实践中,我们也常强调"按需加载"的性能优化原则。 * * * ## 实际应用场景 **场景一:Bug 修复追溯** ``` 用户:"上周修复的登录超时问题,具体改了哪些文件?" Claude:[自动触发 mem-search] → 检索到 2 条相关观察记录 → 返回:修改了 auth.ts 和 session.middleware.ts ``` **场景二:项目知识库构建** 长期使用后,Claude-Mem 会自动构建项目的"知识图谱": - 架构决策记录 - 常用代码模式 - 踩过的坑和解决方案 **场景三:团队协作可视化** 通过 Web UI(localhost:37777)可以实时查看: - 记忆流动态 - 会话摘要时间线 - Token 消耗统计 * * * ## 快速上手指南 **安装步骤(3 步完成)** ``` # 在 Claude Code 终端执行 > /plugin marketplace add thedotmack/claude-mem > /plugin install claude-mem # 重启 Claude Code 即可使用 ``` **核心技能使用** **mem-search 技能**:自然语言查询历史记忆 ``` 示例:mem-search "关于数据库迁移的讨论" 效果:相比传统 MCP 方式节省约 2,250 tokens ``` * * * ## 架构设计亮点 **混合检索策略** ``` // 结合传统全文检索和现代向量搜索 interface SearchStrategy { fullText: SQLite FTS5, // 关键词精准匹配 semantic: Chroma Vector, // 语义相似度计算 hybrid: RRF 融合排序 // 最佳结果输出 } ``` **隐私控制机制** 使用 `<private>` 标签排除敏感内容: ``` <private> API_KEY=sk-xxx # 不会被系统记录 </private> ``` **双标签系统(v7.0 新特性)** - `<private>`:完全排除观察记录 - `<no-summary>`:记录但不生成摘要 * * * ## 性能表现数据 | 优化指标 | 实际效果 | | -------- | ------------------- | | Token 节省 | 每次启动节省 2,250 tokens | | 查询响应速度 | 向量检索 < 50ms | | 存储压缩效率 | 10GB 代码库压缩至约 200MB | * * * ## 工程实践启示 作为全栈工程师,Claude-Mem 展示了几个值得学习的工程实践: 1. **插件化设计**:标准的生命周期钩子系统 1. **AI 工程化**:将 LLM 能力封装为可复用服务 1. **成本意识**:Token 优化是 AI 原生应用的核心指标 1. **用户体验**:渐进式披露配合可视化 UI 对于想深入学习 Node.js 开发和 人工智能应用的朋友,这个项目提供了很好的参考范例。 * * * ## 写在最后 Claude-Mem 不仅是一个工具,更是 AI 辅助编程的范式探索:如何让 AI 从"一次性对话"进化为"长期协作伙伴"。 如果你正在使用 Claude Code,不妨试试这个插件,让你的 AI 助手真正"记住"你们的每一次协作。更多优质开源项目解析,欢迎关注《云栈开源日记》! * * * ### 项目资源 - **GitHub 仓库**:`thedotmack/claude-mem` - **官方文档**:`docs.claudemem.com` - **AI 学习**:`https://yunpan.plus/f/29` - **TypeScript 学习**:`https://yunpan.plus/f/18` * * * 标签:#Claude #GitHub #AI编程助手 #向量数据库 #TypeScript #持久化存储 #开发工具 原文 `https://yunpan.plus/t/1920-1-1` 版权所有
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号