
从主文件夹中的子文件夹中随机提取文件
mat`文件来自主文件夹,其中包含七个子文件夹。每个文件夹都使用类号命名。
import glob
import os
import hdf5storage
import numpy as np
DATASET_PATH = "D:/Dataset/Multi-resolution_data/Visual/High/"
files = glob.glob(DATASET_PATH + "**/*.mat", recursive= True)
class_labels = [i.split(os.sep)[-2] for i in files]
for label in range(0, len(class_labels)):
class_labels [label] = int(class_labels[label])files变量包含以下内容:
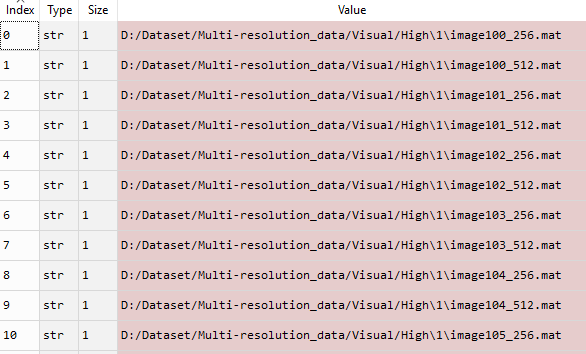
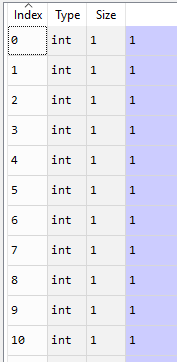
类标签包含以下内容:
我想问几个问题: 1)当我读取.mat文件时,如果dict和每个dict包含不同的变量名,就会出现这种情况。我想知道如何读取key并分配给数组?
array_store=[]
for f in files:
mat = hdf5storage.loadmat(f)
arrays = np.array(mat.keys())
array_store.append(arrays)

2) files = glob.glob(DATASET_PATH + "**/*.mat", recursive= True)是否可以从主文件夹中的每个文件夹随机读取特定数量的文件?比如60%的培训和40%的测试?更新,我尝试过@vopsea的回答。输出与train变量类似。
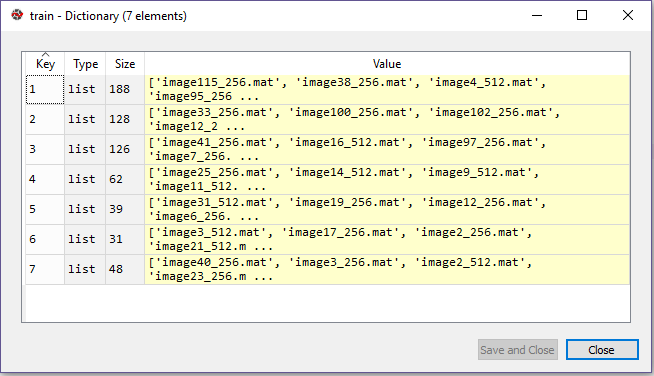
我如何制作每个文件的最终图像数组foy键1-7(数组(256 x 256 x 11 x图像总数)和标签(图像总数x1 )?标签将与键值相同,例如,与键1 (188文件)相关联的所有文件都具有标签1 (188 X 1)。
更新
解决没有密钥名的标签和访问密钥的问题。
import os
import random
import hdf5storage
import numpy as np
DATASET_PATH = "D:/Dataset/Multi-resolution_data/Visual/High/"
train_images = []
test_images = []
train_label = list()
test_label = list()
percent_train = 0.4
class_folders = next(os.walk(DATASET_PATH))[1]
for x in class_folders:
files = os.listdir(os.path.join(DATASET_PATH,x))
random.shuffle(files)
n = int(len(files) * percent_train)
train_i = []
test_i = []
for i,f in enumerate(files):
abs_path= os.path.join(DATASET_PATH,x,f)
mat = hdf5storage.loadmat(abs_path)
if(i < n):
train_i.append(mat.values())
train_label.append(x)
else:
test_i.append(mat.values())
test_label.append(x)
train_images.append(train_i)
test_images.append(test_i)回答 1
Stack Overflow用户
发布于 2019-09-17 06:03:41
( 1)你能在问题1中更详细地解释一下你想要什么吗?附加的是什么?我可能是误会了,但是很容易读懂未知的键,值对
for key, value in mat.items():
print(key, value)( 2)我做这件事时没有沾沾自喜。根据培训百分比,对类文件进行洗牌,并将其分成两个列表。可能最好是为每个类(或关闭)设置相同数量的文件,这样培训就不会特别有利于每个类。
import os
import random
DATASET_PATH = "D:/Dataset/Multi-resolution_data/Visual/High/"
train = {}
test = {}
percent_train = 0.4
class_folders = next(os.walk(DATASET_PATH))[1]
for x in class_folders:
files = os.listdir(os.path.join(DATASET_PATH,x))
random.shuffle(files)
n = int(len(files) * percent_train)
train[x] = files[:n]
test[x] = files[n:]编辑2:是你的意思吗?
import os
import random
import hdf5storage
import numpy as np
DATASET_PATH = "D:/Dataset/Multi-resolution_data/Visual/High/"
train_images = []
test_images = []
train_label = []
test_label = []
percent_train = 0.4
class_folders = next(os.walk(DATASET_PATH))[1]
for x in class_folders:
files = os.listdir(os.path.join(DATASET_PATH,x))
random.shuffle(files)
n = int(len(files) * percent_train)
for i,f in enumerate(files):
abs_path= os.path.join(DATASET_PATH,x,f)
mat = hdf5storage.loadmat(abs_path)
if(i < n):
train_images.append(mat.values())
train_label.append(x)
else:
test_images.append(mat.values())
test_label.append(x)编辑3:为简单起见使用dict的
注意,在最后运行图像是多么简单。另一种方法是存储两个列表(数据和标签),其中一个将有许多重复的项。然后你必须同时通过它们。
尽管这取决于您以后要做什么,但是两个列表可能是正确的选择。
import os
import random
import hdf5storage
import numpy as np
DATASET_PATH = "D:/Dataset/Multi-resolution_data/Visual/High/"
train_images = {}
test_images = {}
percent_train = 0.4
class_folders = next(os.walk(DATASET_PATH))[1]
for x in class_folders:
files = os.listdir(os.path.join(DATASET_PATH,x))
random.shuffle(files)
n = int(len(files) * percent_train)
for i,f in enumerate(files):
abs_path= os.path.join(DATASET_PATH,x,f)
mat = hdf5storage.loadmat(abs_path)
if(i < n):
train_images[x] = mat.values()
else:
test_images[x] = mat.values()
for img_class,img_data in train_images.items():
print( img_class, img_data )https://stackoverflow.com/questions/57967261
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号