
伯特的TokenEmbeddings是如何创建的?
在描述伯特的论文中,有一个关于WordPiece嵌入的段落。
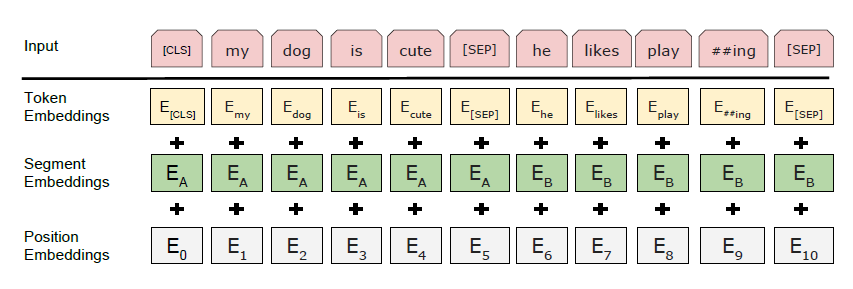
我们使用WordPiece嵌入(Wu等人,2016)和一个30,000个令牌词汇表。每个序列的第一个令牌总是一个特殊的分类令牌(CLS)。与此令牌对应的最后一个隐藏状态用作分类任务的聚合序列表示。句子对被打包成一个序列。我们用两种方式区分句子。首先,我们用一个特殊的令牌(SEP)将它们分开。其次,我们在每个标记中添加一个学习嵌入,表示它是属于句子A还是句子B。如图1所示,我们将输入嵌入表示为E,表示特殊CLS令牌的最终隐藏向量为C2 RH,表示输入标记的最终隐藏向量为Ti2RH。对于给定的令牌,它的输入表示是通过对相应的令牌、段和位置嵌入的求和来构造的。在图2中可以看到这个结构的可视化。
据我所知,WordPiece将单词拆分成像#I #、#游泳#ing这样的词块,但它不会生成嵌入。但是,我在论文和其他来源中没有发现任何东西,这些令牌嵌入是如何生成的。他们在实际的训练前接受过预训练吗?多么?或者它们是随机初始化的?
回答 2
Stack Overflow用户
发布于 2019-09-17 09:14:51
单词是分开训练的,这样最频繁的单词就会在一起,而不太频繁的单词最终会被分解成字符。
嵌入是与BERT的其余部分联合训练的。反向传播是通过所有层进行的,直到嵌入,而嵌入就像网络中的任何其他参数一样被更新。
请注意,只有实际存在于培训批中的令牌的嵌入才会得到更新,其余的则保持不变。这也是为什么您需要相对较少的字段词汇表,以便所有嵌入在培训期间得到足够频繁的更新。
Stack Overflow用户
发布于 2022-07-12 06:28:59
标记嵌入只是在词汇表中获取它们的索引.
一个回答者这里给出了一个例子,但没有清楚地说明这个数字是词汇表的索引:
BERT’s input is essentially subwords.
For example, if I want to feed BERT the sentence
“Welcome to HuggingFace Forums!”, what I actually gets fed in is:
['[CLS]', 'welcome', 'to', 'hugging', '##face', 'forums', '!', '[SEP]'].
Each of these tokens is mapped to an integer:
[101, 6160, 2000, 17662, 12172, 21415, 999, 102].然后我搜索并下载了词汇 (vocab.txt bert-base),并验证了上述数字。
https://stackoverflow.com/questions/57960995
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号