
GCP Kubernetes聚类监测极限图
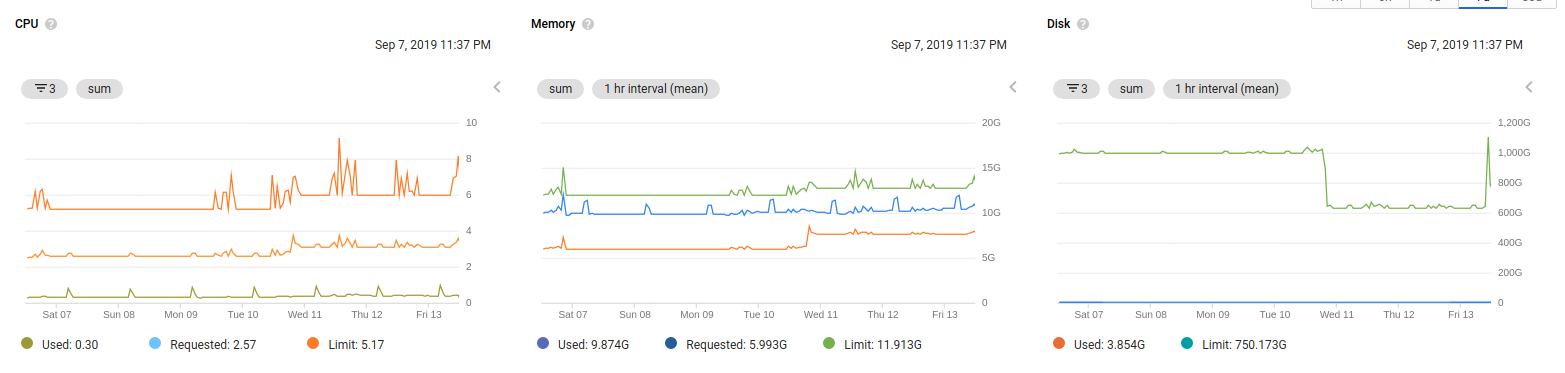
这是我的Kubernetes集群节点监视。K8s集群正在GKE上运行,并使用堆栈驱动程序监视和日志记录。
集群大小为4vCPU和15GB内存。在CPU图中,为什么会有超过CPU极限的峰值?因为我的集群CPU是4vCPU,但是限制尖峰在那里。
没有集群自动定标器,节点自动定标器,垂直自动定标器什么都没有运行。
同样的记忆问题?
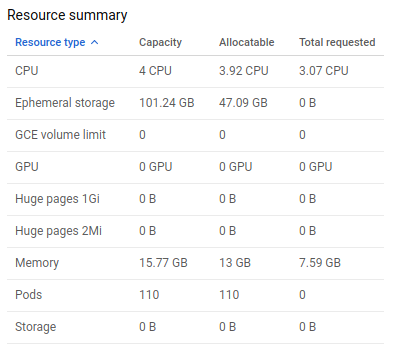
总容量为15 GB,容量为15.77 GB,可分配的13 GB,平均为2 GB用于Kubernetes系统。
为了实现完美的监控,我已经安装了默认的Kubernetes仪表板。

这表明使用量约为10.2GB,所以我仍然有2-3GB的RAM?作为可分配的,13 GB的系统是2GB吗?我说的对吗?
我也安装了Grafana
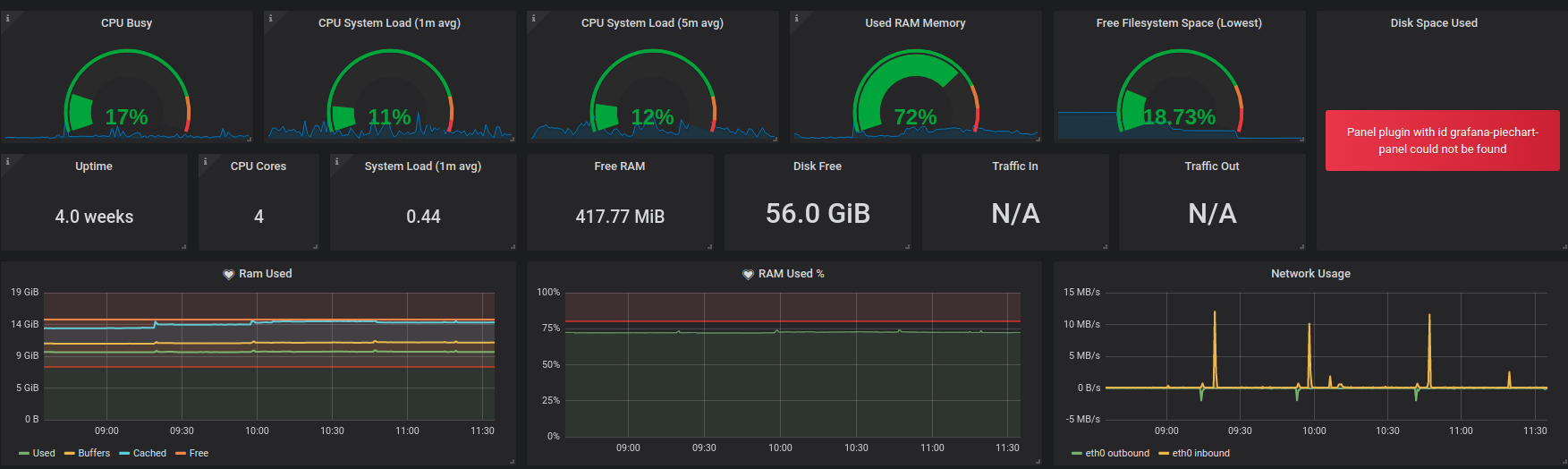
这显示了450 MB的自由内存,我已经导入了这个仪表板。
但是如果它使用10 GB左右的RAM,那么在13 GB的内存中,我应该还有2-3 GB的内存。
更新:
Kubectl describe node <node>
Resource Requests Limits
-------- -------- ------
cpu 3073m (78%) 5990m (152%)
memory 7414160Ki (58%) 12386704Ki (97%)如果您看一下堆栈驱动程序的第一个图表,随着内存使用量的增加,内存限制增加,tp增加了15 is,但是分配或可用内存仅为13 is。怎么做到的?
回答 2
Stack Overflow用户
发布于 2019-09-13 09:55:54
因此,一般来说,我认为机器有能力对指定的CPU进行简短的检查,这就是所谓的突发。
GKE仪表板、Kubernetes仪表板和Grafana可以很好地使用。
- 这些指标的不同来源
- 不同单位
示例:在google摘要中,它显示您有15.77GB。这并不是错的。这台机器可能被指定为15 as。但是在内部,google计算不使用GB,MB,B之类的。它用基字节进行计算。当您运行kubectl describe nodes <node>时。您得到了以kibi字节表示的实际值。
对我来说,是15399364吉,等于15.768948736 GB
最后一件事是,通常Google控制台在显示这些信息时并不十分准确。我总是建议您通过命令行获得度量标准。
Stack Overflow用户
发布于 2019-09-13 10:12:13
在您的示例中,您有两个问题,一个与CPU使用有关,另一个与内存使用有关:
您输入了有限的信息,CPU和内存的使用取决于不同的方面,例如豆荚、节点数量等等。
你说你没有对节点使用自动分词器。
对于堆栈驱动程序监控,您可以看到容器的一部分,而CPU图使用的是“容器/ CPU /use_time”,其中解释了“在所有核上的累积CPU使用率(以秒计)”。此数除以所用时间表示使用为若干核,而不考虑可能设置的任何核心限制。每60秒取样一次“。
在同一页中,谈到内存,您可以阅读这个图使用“容器/内存/字节使用”,其中告诉“内存使用的字节,细分为类型:可驱逐和不可驱逐。每60秒取样一次。memory_type:evictable还是non-evictable。可驱逐内存是内核可以轻松回收的内存,而不可驱逐内存则不能。“,在这种情况下,使用的是不可驱逐内存。
在有关系统在内存情况下可分配的大小的问题中,这取决于您为集群工作而放置的大小。
例如,我继续创建一个具有1 vCPU和4Gb内存的集群,内存可分配为2.77Gb。
https://stackoverflow.com/questions/57918206
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号