
使用日期范围从一行展开为多行
使用日期范围从一行展开为多行
提问于 2019-09-05 03:15:57
第一次数据包含给病人使用的药物以及这些药物的开始和停止日期。我需要获取这个数据,并在每个id中展开每个药物条目,以便每个管理的日期都有一个行条目,也就是说,它符合第二个数据的格式。
Dataframe 1
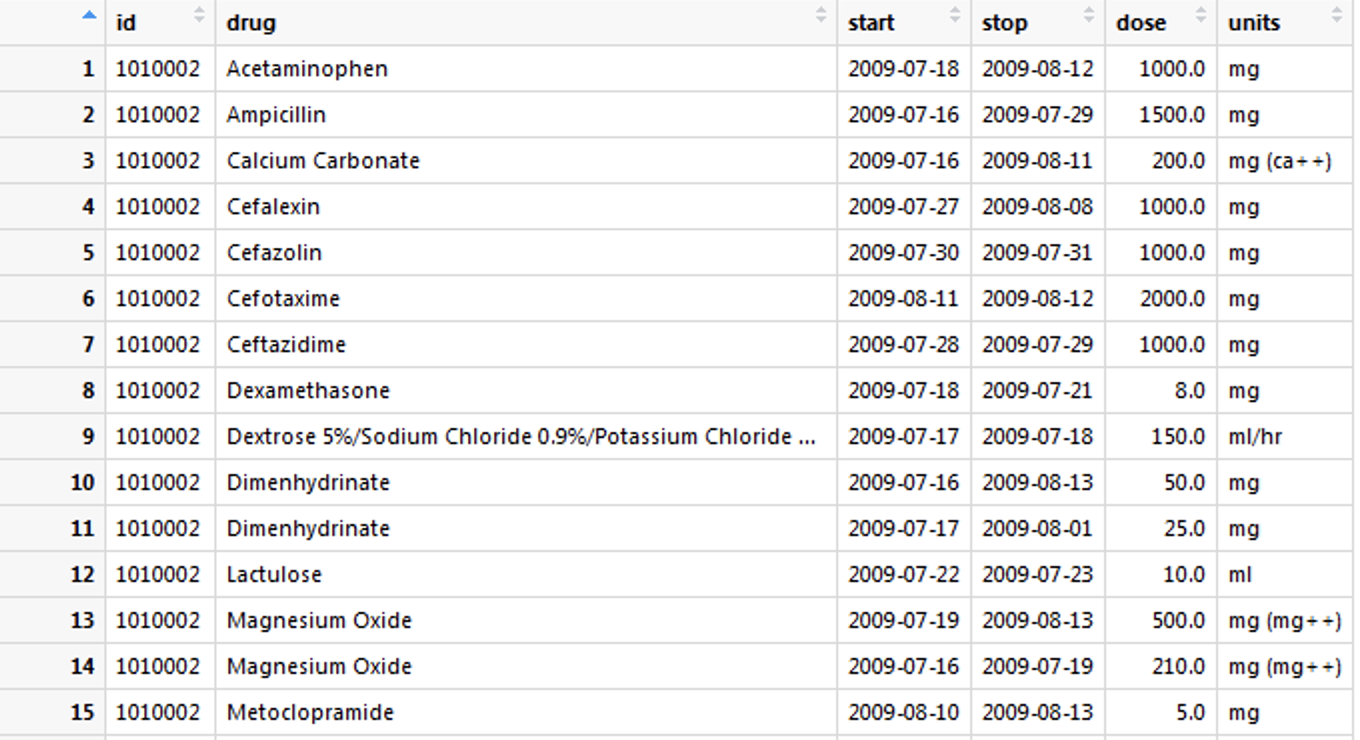
structure(list(id = c(1010002, 1010002, 1010002, 1010002, 1010002,
1010002, 1010002, 1010002, 1010002, 1010002, 1010002, 1010002,
1010002, 1010002, 1010002, 1010002, 1010002, 1010002, 1010002,
1010002, 1010002, 1010002, 1010002, 1010002, 1010002, 1010002,
1010002, 1010002, 1010002, 1010002, 1010002, 1010002, 1010002,
1010002), drug = c("Acetaminophen", "Ampicillin", "Calcium Carbonate",
"Cefalexin", "Cefazolin", "Cefotaxime", "Ceftazidime", "Dexamethasone",
"Dextrose 5%/Sodium Chloride 0.9%/Potassium Chloride 20mmol/L",
"Dimenhydrinate", "Dimenhydrinate", "Lactulose", "Magnesium Oxide",
"Magnesium Oxide", "Metoclopramide", "Metoclopramide", "Morphine",
"Morphine", "Morphine", "Mycophenolate Mofetil", "Nadolol", "Omeprazole",
"Ondansetron", "Ondansetron", "Oxybutynin", "Oxycodone Immediate Release",
"Prednisone", "Sirolimus", "Sirolimus", "Sirolimus", "Tacrolimus",
"Tacrolimus", "Tacrolimus", "Vitamin D3"), start = structure(c(1247875200,
1247702400, 1247702400, 1248652800, 1248912000, 1249948800, 1248739200,
1247875200, 1247788800, 1247702400, 1247788800, 1248220800, 1247961600,
1247702400, 1249862400, 1249430400, 1247788800, 1247961600, 1247961600,
1247702400, 1247702400, 1247702400, 1247875200, 1249084800, 1247702400,
1248134400, 1247788800, 1249603200, 1249862400, 1249430400, 1248652800,
1247875200, 1247702400, 1247875200), class = c("POSIXct", "POSIXt"
), tzone = "UTC"), stop = structure(c(1250035200, 1248825600,
1249948800, 1249689600, 1248998400, 1250035200, 1248825600, 1248134400,
1247875200, 1250121600, 1249084800, 1248307200, 1250121600, 1247961600,
1250121600, 1249862400, 1247875200, 1248048000, 1248048000, 1250121600,
1250121600, 1250121600, 1248998400, 1250121600, 1250121600, 1248998400,
1250121600, 1249776000, 1250121600, 1249516800, 1249430400, 1249171200,
1249171200, 1250121600), class = c("POSIXct", "POSIXt"), tzone = "UTC"),
dose = c(1000, 1500, 200, 1000, 1000, 2000, 1000, 8, 150,
50, 25, 10, 500, 210, 5, 10, 50, 4, 15, 500, 40, 20, 4, 8,
7.5, 5, 10, 4, 3, 6, 3, 3.5, 4, 400), units = c("mg", "mg",
"mg (ca++)", "mg", "mg", "mg", "mg", "mg", "ml/hr", "mg",
"mg", "ml", "mg (mg++)", "mg (mg++)", "mg", "mg", "mg", "mg",
"mg", "mg", "mg", "mg", "mg", "mg", "mg", "mg", "mg", "mg",
"mg", "mg", "mg", "mg", "mg", "IU")), row.names = c(NA, -34L
), class = c("tbl_df", "tbl", "data.frame"))Dataframe 2
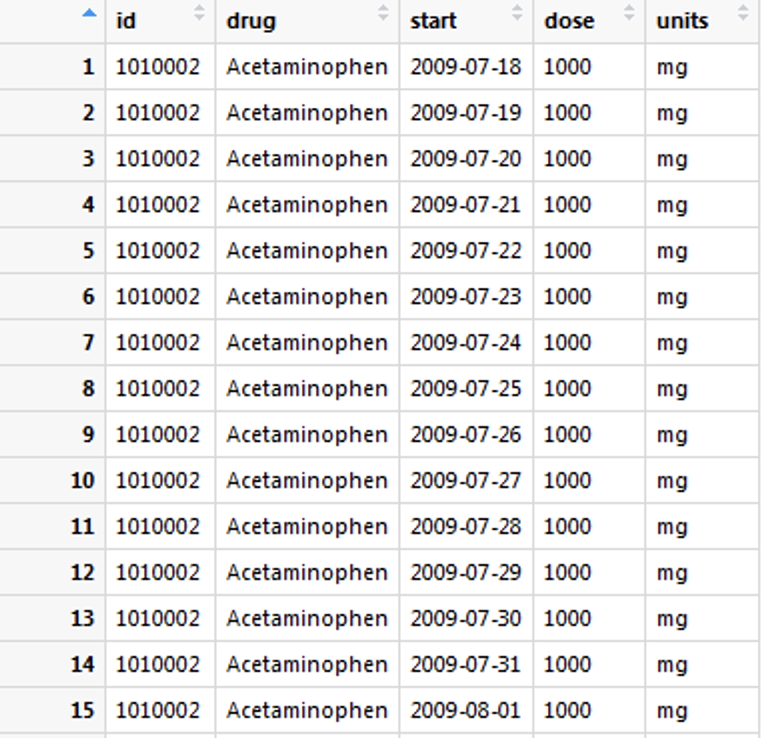
structure(list(id = c(1010002, 1010002, 1010002, 1010002, 1010002,
1010002, 1010002, 1010002, 1010002, 1010002, 1010002, 1010002,
1010002, 1010002, 1010002, 1010002, 1010002, 1010002, 1010002,
1010002, 1010002, 1010002, 1010002, 1010002, 1010002, 1010002
), drug = c("Acetaminophen", "Acetaminophen", "Acetaminophen",
"Acetaminophen", "Acetaminophen", "Acetaminophen", "Acetaminophen",
"Acetaminophen", "Acetaminophen", "Acetaminophen", "Acetaminophen",
"Acetaminophen", "Acetaminophen", "Acetaminophen", "Acetaminophen",
"Acetaminophen", "Acetaminophen", "Acetaminophen", "Acetaminophen",
"Acetaminophen", "Acetaminophen", "Acetaminophen", "Acetaminophen",
"Acetaminophen", "Acetaminophen", "Acetaminophen"), start = structure(c(1247875200,
1247961600, 1248048000, 1248134400, 1248220800, 1248307200, 1248393600,
1248480000, 1248566400, 1248652800, 1248739200, 1248825600, 1248912000,
1248998400, 1249084800, 1249171200, 1249257600, 1249344000, 1249430400,
1249516800, 1249603200, 1249689600, 1249776000, 1249862400, 1249948800,
1250035200), class = c("POSIXct", "POSIXt"), tzone = "UTC"),
dose = c(1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000,
1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000,
1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000), units = c("mg",
"mg", "mg", "mg", "mg", "mg", "mg", "mg", "mg", "mg", "mg",
"mg", "mg", "mg", "mg", "mg", "mg", "mg", "mg", "mg", "mg",
"mg", "mg", "mg", "mg", "mg")), row.names = c(NA, -26L), class = c("tbl_df",
"tbl", "data.frame"))回答 1
Stack Overflow用户
回答已采纳
发布于 2019-09-05 03:18:22
我们可以使用map2从purrr创建一个list列,每个‘开始’到‘停止’by '1天‘,然后unnest list
library(dplyr)
library(purrr)
library(tidyr)
df1 %>%
mutate(start = map2(as.Date(start), as.Date(stop), ~
as.POSIXct(seq(.x, .y, by = '1 day')))) %>%
unnest(start) %>%
select(-stop) 页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/57797972
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号