
Chrome预览与下载不同
我查看以下页面:customfield2=
或
据我所知,数据可以是通过get/post (在“原始”html源中)获取,也可以是执行某些JavaScript代码。
但在那一页上,我不知何故找不到来源。
Chrome上的数据表明,数据(这里是页面上的职务数据)在一个文档(纪念碑)中,请参见屏幕快照- Tab Doc,当我查看预览选项卡时,它是空的。但是如果我查看"Response“选项卡,就可以看到数据。
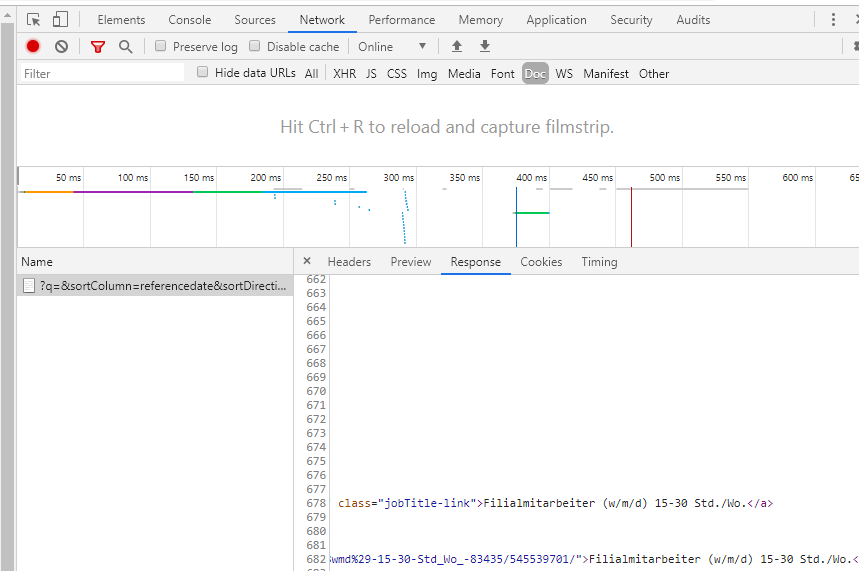
期望输出:
目标语言是R,但实际上这里没有那么相关。我很乐意了解这些数据是如何生成的。因此,某些硒方法或类似的方法是不需要的。但是,更多地了解数据是如何生成的,以及如何通过post/get、JS或原始源提取数据。
我尝试了什么:
library(httr)
library(rvest)
url <- "https://www.dm-jobs.com/Germany/search/?searchby=location&createNewAlert=false&q=&locationsearch=&geolocation=&optionsFacetsDD_customfield4=&optionsFacetsDD_customfield3=&optionsFacetsDD_customfield2="
src <- read_html(url)
src %>% html_nodes(xpath = "//*[contains(text(), 'Filialmitarbeiter')]")
as.character(src) %>% grep(pattern = "Filialmitarbeiter")
get <- GET(url)
content(get)
content(get$content)目标输出:
例如:
Filialmitarbeiter (w/m/d) 15-30 Std./Wo. Bad Reichenhall, DE, 83435 30.08.2019
Filialmitarbeiter (w/m/d) 6-8 Std./Wo. Neuenburg am Rhein, DE, 79395 30.08.2019
Führungsnachwuchs Filialleitung (w/m/d) Vechta, DE, 49377 30.08.2019 回答 1
Stack Overflow用户
发布于 2019-09-10 19:18:45
有两个曲奇是重要的,必须从初始登陆页上捡起。您可以使用html_session动态捕获这些信息,然后在随后的请求中将它们传递给您希望得到的结果(至少对我是这样)。我写了一些关于会话对象这里的东西。
所见的3种曲奇是:
cookies = c(
'rmk12' = '1',
'JSESSIONID' = 'some_value',
'cookie_j2w' = 'some_other_value'
)在试图查看职务列表时,可以使用“网络”选项卡监视网络流量,从而找到这些附加的标题。
您可以尝试删除标题和cookie,您将发现只需要第二个和第三个cookie,而不需要头。但是,所传递的cookie必须在对url的先前请求中捕获,如下所示。会话是执行此操作的传统方法。
R
library(rvest)
library(magrittr)
start_link = 'https://www.dm-jobs.com/Germany/?locale=de_DE'
next_link <- 'https://www.dm-jobs.com/Germany/search/?searchby=location&createNewAlert=false&q=&locationsearch=&geolocation=&optionsFacetsDD_customfield4=&optionsFacetsDD_customfield3=&optionsFacetsDD_customfield2='
jobs <- html_session(start_link) %>%
jump_to(.,next_link) %>%
html_nodes('.jobTitle-link') %>%
html_text()
print(jobs)Py
import requests
from bs4 import BeautifulSoup as bs
with requests.Session() as s:
r = s.get('https://www.dm-jobs.com/Germany/?locale=de_DE')
cookies = s.cookies.get_dict() # just to demo which cookies are captured
print(cookies) # just to demo which cookies are captured
r = s.get('https://www.dm-jobs.com/Germany/search/?searchby=location&createNewAlert=false&q=&locationsearch=&geolocation=&optionsFacetsDD_customfield4=&optionsFacetsDD_customfield3=&optionsFacetsDD_customfield2=')
soup = bs(r.content, 'lxml')
print(len(soup.select('.jobTitle-link')))阅读:
https://stackoverflow.com/questions/57730571
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号