
获取具有if条件的不同列的最大值。
获取具有if条件的不同列的最大值。
提问于 2019-08-30 06:54:25
我希望为每一行获取这些值的最大值<目标值。
例如,从下面的dataframe中,每一列date1、date2、.date6将依次成为target value
对于每一行的每个target value,我希望得到那些小于target value的值。如果target value是最小的,它将返回target value。
我有一个数据框架df如下:
index date1 date2 date3 date4 date5 date6
AA 2019-8-1 2019-1-4 2019-2-3 2019-2-2 2019-5-21 2019-5-14
BB 2019-3-12 2019-10-1 2019-6-1 2019-3-17 2019-7-9 2019-6-12
CC 2019-1-11 2019-3-1 2019-8-1 2019-3-27 2019-1-11 2019-1-7我的尝试是万一target value是date1
date1temp = []
for index, row in df.iterrows():
mylist = ['date2','date3','date4','date5','date6']
max = datetime.datetime(2011,1,1)
for i in mylist:
if row[i] < row['date1']
if row[i] > max:
max = row[i]
else:
max = row['date1']
date1temp.append((index,max,row['date1']))
cols = ['index','max','target']
result = pd.DataFrame(date1temp, columns=cols)但是代码没有给出我想要的result:
index max target
AA 2019-8-1 2019-8-1
BB 2019-3-12 2019-3-12
CC 2019-1-11 2019-1-11预期输出:--我想按以下方式获得result:
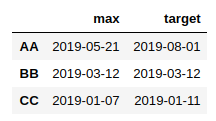
index max target
AA 2019-5-21 2019-8-1
BB 2019-3-12 2019-3-12
CC 2019-1-7 2019-1-11谢谢!
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-08-30 09:56:38
首先,您必须将数据转换为日期时间,以便按您预期的方式进行比较:
df = df.apply(pd.to_datetime)然后,只需用所需的列更改target:
target = 'date1'
target_index = df.columns.tolist().index(target)
def process(row):
target_value = row[target_index]
smaller = row[row < target_value]
# check if there is any smaller
if not smaller.empty:
return smaller.max()
return target_value
pd.concat([df.agg(process, axis=1), df[target]], axis=1).rename(columns={0:'max', target: 'target'})产出:
Stack Overflow用户
发布于 2019-08-30 07:57:41
这个错误出现在本节中:
max = datetime.datetime(2011,1,1)
for i in mylist:
if row[i] < row['date1']
if row[i] > max:
max = row[i]
else:
max = row['date1']首先,将最大max设置为2011-1-1,但是如果列表mylist中的任何值较大或等于date1中的日期,则最大值设置为date1,这是错误的。您希望所有值的最大值是,比date1小!
您只需省略else路径:
max = datetime.datetime(2011,1,1)
for i in mylist:
if row[i] < row['date1']
if row[i] > max:
max = row[i]页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/57721895
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号