
两列不同粒度的DAX条件和
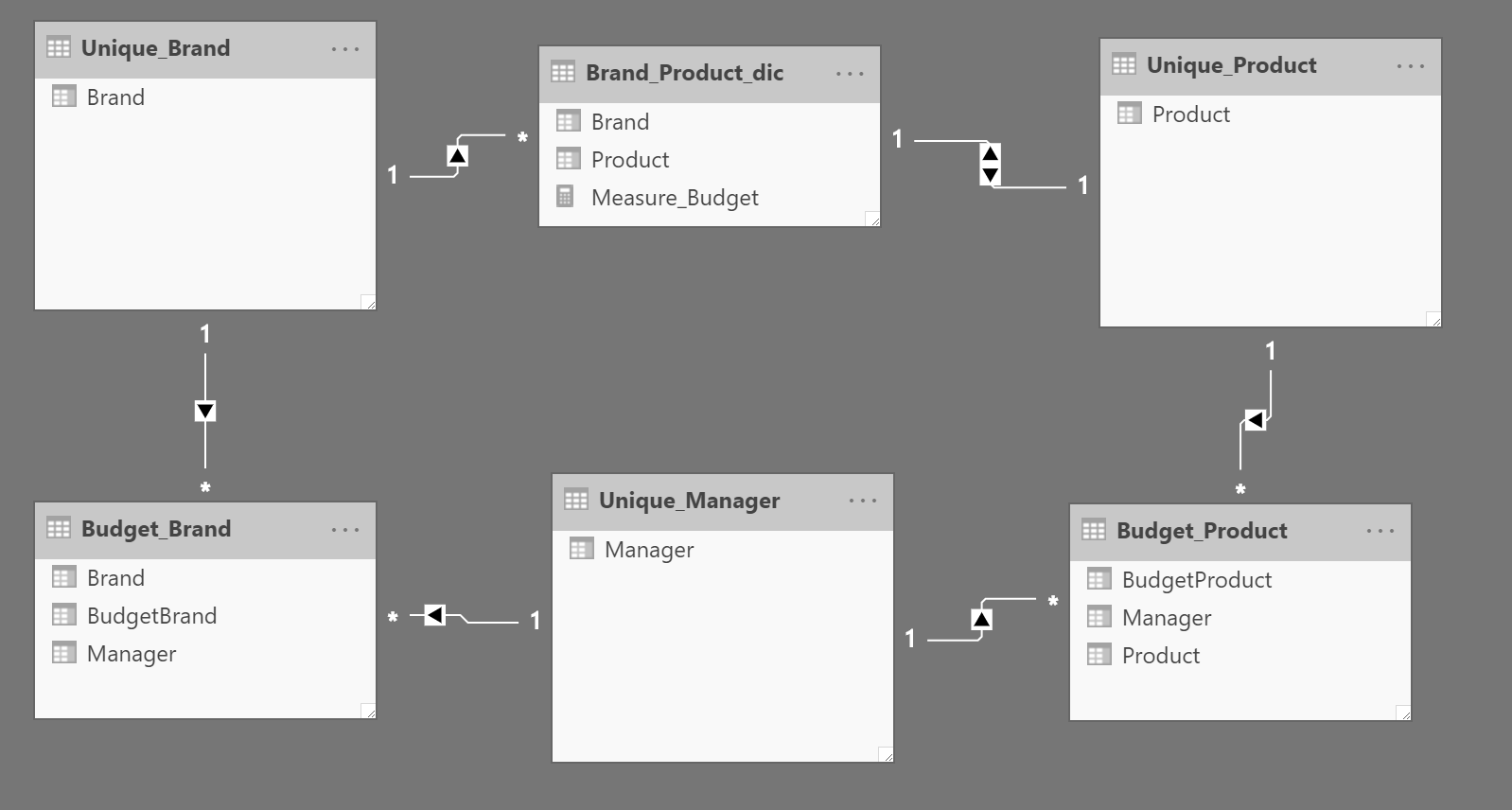
这是一个被问到这里的后续问题。但是,这一次,两列具有不同的粒度,并且位于不同的表中。因此,前面提出的简单SUMX解决方案是不适用的。我附上SumDifferntGranularity.pbix文件。
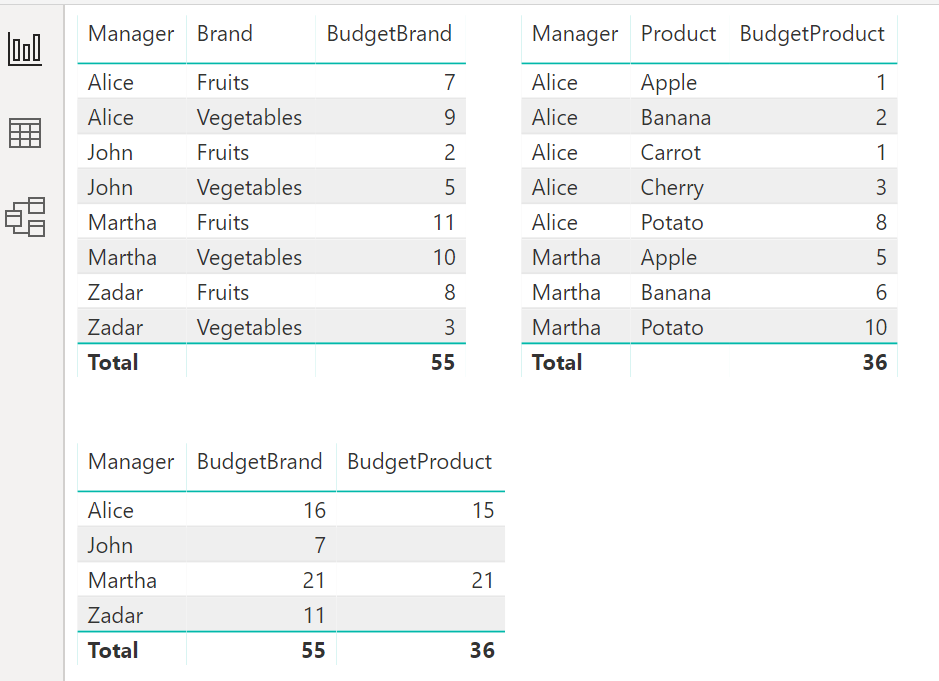
如何构造DAX度量,它返回BudgetProduct (如果可能的话)或BudgetBrand的和。逻辑是,如果产品是空的,就取品牌。因此,预期的结果如下:
+---------+-------------+---------------+-----------------+
| Manager | BudgetBrand | BudgetProduct | Expected result |
+---------+-------------+---------------+-----------------+
| Alice | 16 | 15 | 15 |
| John | 7 | | 7 |
| Martha | 21 | 21 | 21 |
| Zadar | 11 | | 11 |
+---------+-------------+---------------+-----------------+
| Total | 55 | 36 | 54 |
+---------+-------------+---------------+-----------------+在这个例子中,所有的经理都有关于品牌的预算,但是有些经理(爱丽丝和玛莎)有关于产品的预算。如何构建一个衡量标准,如果可能的话,它将采用对产品的预算定义,但如果不可能的话,它将采用对品牌定义的预算。
回答 1
Stack Overflow用户
发布于 2019-08-29 16:00:28
我认为这是可行的:
Expected Result =
VAR Summary =
SUMMARIZE (
Unique_Manager,
Unique_Manager[Manager],
"Budget_Brand", SUM ( Budget_Brand[BudgetBrand] ),
"Budget_Product", SUM ( Budget_Product[BudgetProduct] )
)
RETURN
SUMX (
Summary,
IF ( ISBLANK ( [Budget_Product] ), [Budget_Brand], [Budget_Product] )
)这个组由Manager进行,并计算一个汇总表,其中包含每个BudgetBrand和BudgetProduct的和,并使用指定的逻辑在这个汇总表中使用SUMX进行迭代。
这里有一个更简洁的实现
Expected Result =
SUMX (
VALUES ( Unique_Manager[Manager] ),
VAR SumBrand = CALCULATE ( SUM ( Budget_Brand[BudgetBrand] ) )
VAR SumProduct = CALCULATE ( SUM ( Budget_Product[BudgetProduct] ) )
RETURN
IF ( ISBLANK ( SumProduct ), SumBrand, SumProduct )
)如果是这个,我们不需要一个计算表来迭代。相反,我们在本地过滤器上下文中迭代了Manager的所有不同值,并在该上下文中对BudgetBrand和BudgetProduct进行了求和。请注意,我已经用CALCULATE包装了这些总和。这样做是为了执行从SUMX (特定的Manager)中的行上下文到在BudgetBrand和BudgetProduct上将该Manager作为过滤器上下文的上下文转换。将这些和存储为变量可以使IF行更具可读性,并且只要求计算SumProduct一次而不是两次。
https://stackoverflow.com/questions/57713806
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号