
如何将可变宽度的空白字符串表读入熊猫数据?
我是熊猫的新手,我试着把复杂的字符串读成数据格式。我遇到的问题是数据被逐字读取。我需要做些什么才能读取这些数据,以便dataframe捕获行和列?非常感谢!
下面是一行内容:
1 85 58 72 6 0 7 0.00 0.0 0 6.7 15 230 M 3 19 240
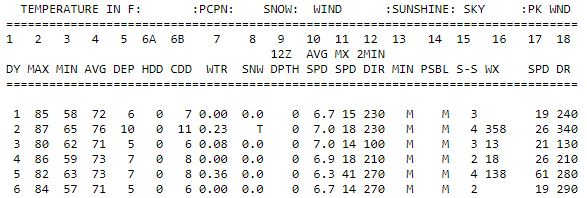
以下是我到目前为止尝试过的:
import urllib2
import math
import json
import pandas as pd
from pandas import Timestamp
import os, sys
import re
import numpy as np
from datetime import datetime, timedelta
import csv
sites = {'dlh':'1'}
prdurl = 'https://api.weather.gov/products/types/cf6/locations/'
cf6url = 'https://api.weather.gov/products/'
current_date = datetime.now()-timedelta(days=1)
current_day = current_date.strftime('%d')
def make_request(url,params):
req = urllib2.Request(url+params)
try:
response = urllib2.urlopen(req)
return json.loads(response.read())
except urllib2.HTTPError as error:
if error.code == 400: print error.msg
def main():
for id in sites:
apijson = make_request(prdurl,id)
for key in apijson:
if key != '@context':
webjson = apijson['@graph']
for x in webjson:
valid = x['issuanceTime']
date_obj = datetime.strptime(valid,'%Y-%m-%dT%H:%M:%S+00:00')
day = date_obj.strftime('%d')
if current_day == day:
newparam = x['id']
cf6json = make_request(cf6url,newparam)
for y in cf6json:
if y == 'productText':
cf6data = cf6json['productText']
for line in cf6data.splitlines():
if line.startswith('==='):
count = count + 1
if count == 2:
df = pd.DataFrame.from_records(line)
print df
main()回答 2
Stack Overflow用户
发布于 2019-08-28 04:14:45
步骤1:获取数据:
import requests
response = requests.get('https://api.weather.gov/products/16a535da-eb2c-4580-9725-b536890e923d')
data = response.json()['productText']步骤2:清理和重塑数据:
将其拆分为list并删除''
data_list = data.split('\n')
data_clean = list(filter(lambda x: x != '', data_list))将相关数据写入csv:
from pathlib import Path
f = Path.cwd() / 'weather.csv'
with f.open(mode='w') as wf:
count = 0
for line in data_clean:
if line.startswith('==='):
count += 1
if (count == 2 and not line.startswith('===')) or (line.startswith('DY MAX')):
wf.write(f'{line}\n')步骤3:创建DataFrame
df = pd.read_csv('weather.csv', sep='\\s+')决赛:
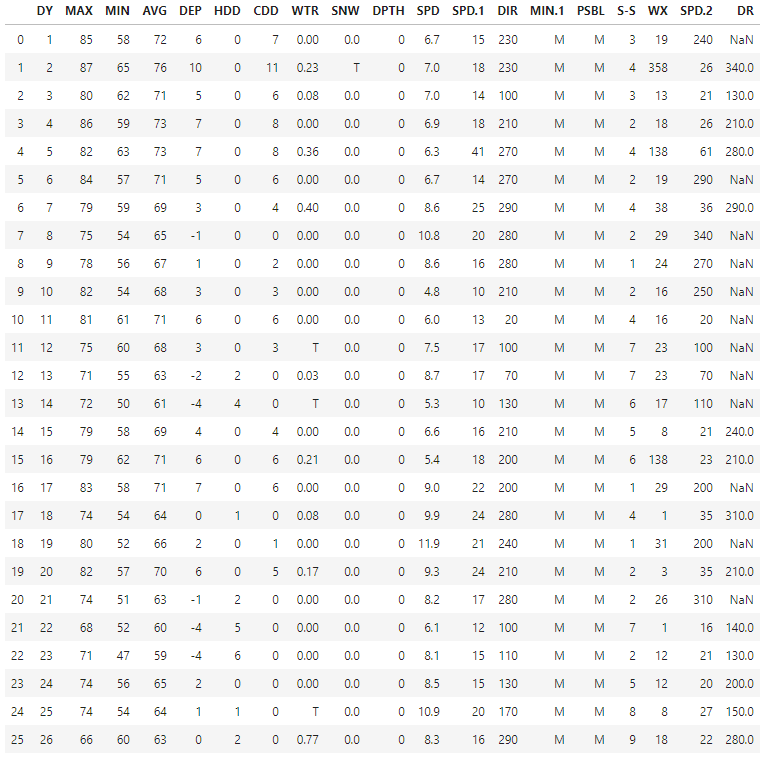
- 总是要把数据转换成正确的形式
Stack Overflow用户
发布于 2019-08-28 02:53:48
您可以从以下代码开始
如果你有这样的data.txt:
col1 col2
===================
aa bb
===================
jjjjjjj kkkkkkkk然后,可以使用skiprows跳过一些行,分隔符是空格( sep=“")。
import pandas as pd
data = pd.read_csv('data.txt', sep=" ", header=None,skiprows=[1,3])
data.columns = ["col1","col2"]
data结果:
col1 col2
0 col1 col2
1 aa bb
2 jjjjjjj kkkkkkkk关于你添加的非常具体的代码。如果你想一个接一个地读行,那么对于每个行,你可以决定忽略什么和什么时候。同时,使用split和expand=True。“当使用expand=True时,拆分元素将展开为单独的列”https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.str.split.html
cf6data = cf6json['productText']
start = False
for line in cf6data.splitlines():
if start or "DY MAX" in line:
start = True
s = pd.Series(line)
line = s.str.split(expand=True)
Results = Results.append(line,ignore_index=True)
print(Results)播放这段代码,清除一些行,它应该可以工作!:)
https://stackoverflow.com/questions/57684391
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号