
从csv文件读取数据时查找列表的累积和
我想找到cumulative sum of the list
我正在读取位于文件夹deg_pvsyst_runs中的30个类似的csv文件。文件名为:
“能源基准年00_-0.6%mod.csv”,“能源基准年01_-0.3%mod.csv”,.,“能源基准年30_-8.4%moda.csv”
“
我正在读取每个csv文件中的E_Grid列(跳过包含头信息的0-9、11和12行之后)。请建议
( a)如果在跳过行时有一种更短/更简单的读取csv的方法,而不是我所做的(skiprows=[0,1,2,3,4,5,6,7,8,9,11,12])
( b)如果使用itertools方法或cumsum函数可以更好地计算名为Cumulative_Annual_Deg的列表的累积和
代码:
import os, csv, re
import pandas as pd
from itertools import accumulate
Year, Degradation, Mean_EP, Annual_Deg, Cumulative_Annual_Deg =[],[],[],[],[]
cwd = os.getcwd()
csv_files = [f for f in os.listdir(cwd + '\\' + 'deg_pvsyst_runs') if f.endswith('.csv')]
for i,j in enumerate(csv_files):
df = pd.read_csv(os.getcwd() + "\\deg_pvsyst_runs\\" + j, skiprows=[0,1,2,3,4,5,6,7,8,9,11,12])
Mean_EP.append(df['E_Grid'].sum()/10**6)
Annual_Deg.append((Mean_EP[i-1] - Mean_EP[i])/Mean_EP[i-1])
Cumulative_Annual_Deg.append(list(accumulate(Annual_Deg[i])))错误:
Cumulative_Annual_Deg.append(list(accumulate(Annual_Deg[i])))
TypeError: 'numpy.float64' object is not iterable编辑:
Annual_Deg是由计算csv文件之间的增量(% change)组成的列表。我想要计算Cumulative_Annual_Deg来计算累积和。
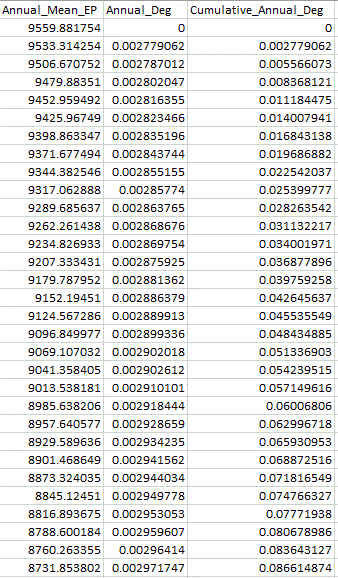
期望输出:
Annual_Mean_EP = [9559.88, 9533.31, 9506.67,...,8731.85]Annual_Deg = [0, 0.00278, 0.00279,...,0.00297]Cumulative_Annual_Deg' = [0, 0.00278, 0.00557, ..., 0.08661]
或截图
回答 1
Stack Overflow用户
发布于 2019-08-19 06:55:24
可以在计算列表后计算累积和。因此,累积行应该放在for循环之外。替换下一行
Cumulative_Annual_Deg.append(list(accumulate(Annual_Deg[i])))使用
Cumulative_Annual_Deg = list(accumulate(Annual_Deg))您可以在https://docs.python.org/3/library/itertools.html#itertool-functions上找到更多关于迭代工具的信息。
https://stackoverflow.com/questions/57551160
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号